Downloaded 108 times






























![[13930, 29011, 39291, ...] # 50000
1000
{
‘139’ => [13930, 13989, 13991, ...], # 50
‘290’ => [29011, 29098, 29076, ...], # 50
‘392’ => [39291, 39244, 39251, ...], # 50
}](https://image.slidesharecdn.com/20100716cookpadhadoop-100716104052-phpapp01/85/COOKPAD-Hadoop-35-320.jpg)
![50
hash = Hash.new {|h,k| h[k] = []}
target_ids.each do |id|
hash[ id.to_s[0,3] ] << id
end
ARGF.each do |log|
log.chomp!
id, type, ... = log.split(/,/)
next if hash[ id[0,3] ].include?(id)
end](https://image.slidesharecdn.com/20100716cookpadhadoop-100716104052-phpapp01/85/COOKPAD-Hadoop-36-320.jpg)








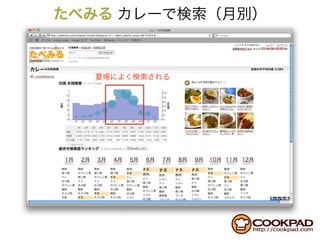
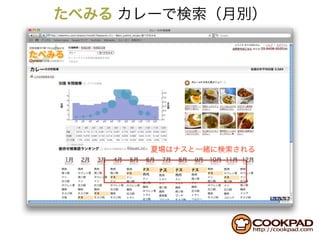
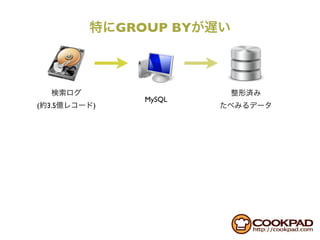
This document discusses Hadoop and its usage at Cookpad. It covers topics like Hadoop architecture with MapReduce and HDFS, using Hadoop on Amazon EC2 with S3 storage, and common issues encountered with the S3 Native FileSystem in Hadoop. Code examples are provided for filtering log data using target IDs in Hadoop.








































































