Part 3. 두달 안에 실시간 데이터 파이프라인 Test부터 Production까지
Confluent Startup Webinar Series
간종석
Account Executive
for Startups, Confluent
안성현
CTO, Payhere
배성환
Data Engineer, Payhere
김지영
AWS Marketplace 한국사업 총괄
Amazon Web Services
2.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
Agenda
1. Confluent Cloud on AWS 소개
2
2. 패널 토크: 두 달 안에 실시간 데이터
파이프라인 구축
- With CTO & Data Engineer. Payhere
3. AWS Marketplace에서 Confluent Cloud
이용 시작하기
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
Event는 무엇일까요?
4
주문 인보이스
거래 고객 경험
5.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
...many more
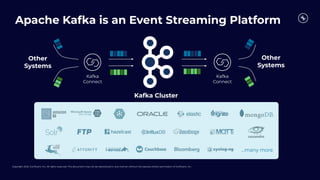
Other
Systems
Other
Systems
Kafka
Connect
Kafka Cluster
Kafka
Connect
Apache Kafka is an Event Streaming Platform
6.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
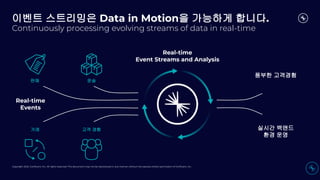
이벤트 스트리밍은 Data in Motion을 가능하게 합니다.
Continuously processing evolving streams of data in real-time
풍부한 고객경험
Real-time
Events
Real-time
Event Streams and Analysis
판매 운송
거래 고객 경험 실시간 백앤드
환경 운영
7.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
Committer-driven
Expertise
Confluent Cloud
Apache Kafka®
오리지날 크리에이터가 만든 Cloud-native 데이터 스트리밍 플랫폼
Enterprise-grade Security
Highly Available
Infinite
Elastic
Deployment Flexibility
Public and Multi Cloud
Event Streaming Database
Stream Governance
190+ Connectors
Management and Monitoring
Cluster Linking
클라우드의 장점을 활용하도록 설계된 완전
관리형 Apache Kafka
Kafka를 넘어 실시간 앱을 빠르고
안정적이며 안전하게 구축
클라우드와 온프레미스에 걸쳐 배포 및
실시간 데이터를 싱크할 수 있는 유연성 제공
Cloud Native Complete Everywhere
Built by the founders of Apache Kafka®
Training Partners
Professional
Services
Enterprise
Support
7
8.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
Confluent Cloud on AWS - 더 확장된 데이터 활용도 &
자율성 에서 원 클릭으로 구독시작
Real-time
데이터 분석
실시간 분석을 위한 모든
이벤트 스트림 수집 및 처리
서버리스 애플리케이션
통합
이벤트 기반 애플리케이션
구동을 위한 어플리케이션과의
데이터 통합 단순화
On premises to AWS
modernization
하이브리드 이벤트 스트리밍을
구성하여 데이터 아키택쳐
현대화
Stream to Amazon Redshift
AWS Service Delivery designation
Serverless Kafka
Confluent Connector to AWS Lambda
Hybrid Kafka
Multi-cloud | Hybrid | AWS Outposts
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
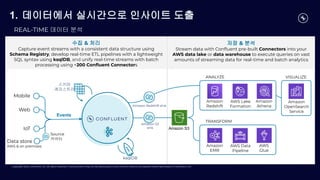
1. 데이터에서 실시간으로 인사이트 도출
REAL-TIME 데이터 분석
Data store
AWS & on premises
수집 & 처리
Capture event streams with a consistent data structure using
Schema Registry, develop real-time ETL pipelines with a lightweight
SQL syntax using ksqlDB, and unify real-time streams with batch
processing using +200 Confluent Connectors
Mobile
Web
IoT
Amazon S3
sink Amazon S3
ANALYZE
Amazon
Redshift
AWS Lake
Formation
Amazon
Athena
Amazon Redshift sink
TRANSFORM
Amazon
EMR
AWS Data
Pipeline
AWS
Glue
Source
커넥터
저장 & 분석
Stream data with Confluent pre-built Connectors into your
AWS data lake or data warehouse to execute queries on vast
amounts of streaming data for real-time and batch analytics
VISUALIZE
Amazon
OpenSearch
Service
스키마
레지스트리
ksqlDB
Events
11.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
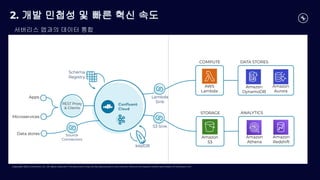
2. 개발 민첩성 및 빠른 혁신 속도
서버리스 앱과의 데이터 통합
Apps
Microservices
ksqlDB
Schema
Registry
COMPUTE
AWS
Lambda
Data stores
REST Proxy
& Clients
Source
Connectors
Lambda
Sink
DATA STORES
Amazon
DynamoDB
Amazon
Aurora
STORAGE
Amazon
S3
S3 Sink
ANALYTICS
Amazon
Athena
Amazon
Redshift
12.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
패널토크 - Payhere (페이히어)
“두 달 안에 실시간 데이터 파이프라인 Test부터 Production까지”
간종석
Account Executive
for Startups, Confluent
안성현
CTO, Payhere
배성환
Data Engineer, Payhere
13.
Copyright 2022, Confluent,Inc. All rights reserved. This document may not be reproduced in any manner without the express written permission of Confluent, Inc.
AWS Marketplace에서
Confluent Cloud 이용 시작하기
김지영
AWS Marketplace 한국사업 총괄
Amazon Web Services
14.
Special Promotion: Win$250 AWS Credits
본 웨비나 참가자 대상으로 $250 상당의 AWS credits를 제공합니다
• 자격 요건:
• 웨비나 이후 AWS Marketplace에서 Confluent Cloud - Pay As You Go / Commit
구독을 시작하시는 참여자
• 2022년 8월 30일까지 프로모션 유효
*문의 이메일: jkan@confluent.io
15.
지금 바로 시작하세요!
Confluent Cloud 신규계정 생성 -
$400 크레딧 제공
(AWS 마켓플레이스)
https://www.confluent.io/ko-kr/get-started/
1:1 솔루션 디자인
Office Hour 진행
설문지에 표기 필요
설문지 피드백
추첨을 통해 Confluent
SWAG제공

















































![[Confluent] 실시간 하이브리드, 멀티 클라우드 데이터 아키텍처로 빠르게 혀...](https://cdn.slidesharecdn.com/ss_thumbnails/confluent-220504043130-thumbnail.jpg?width=640&height=640&fit=bounds)






























