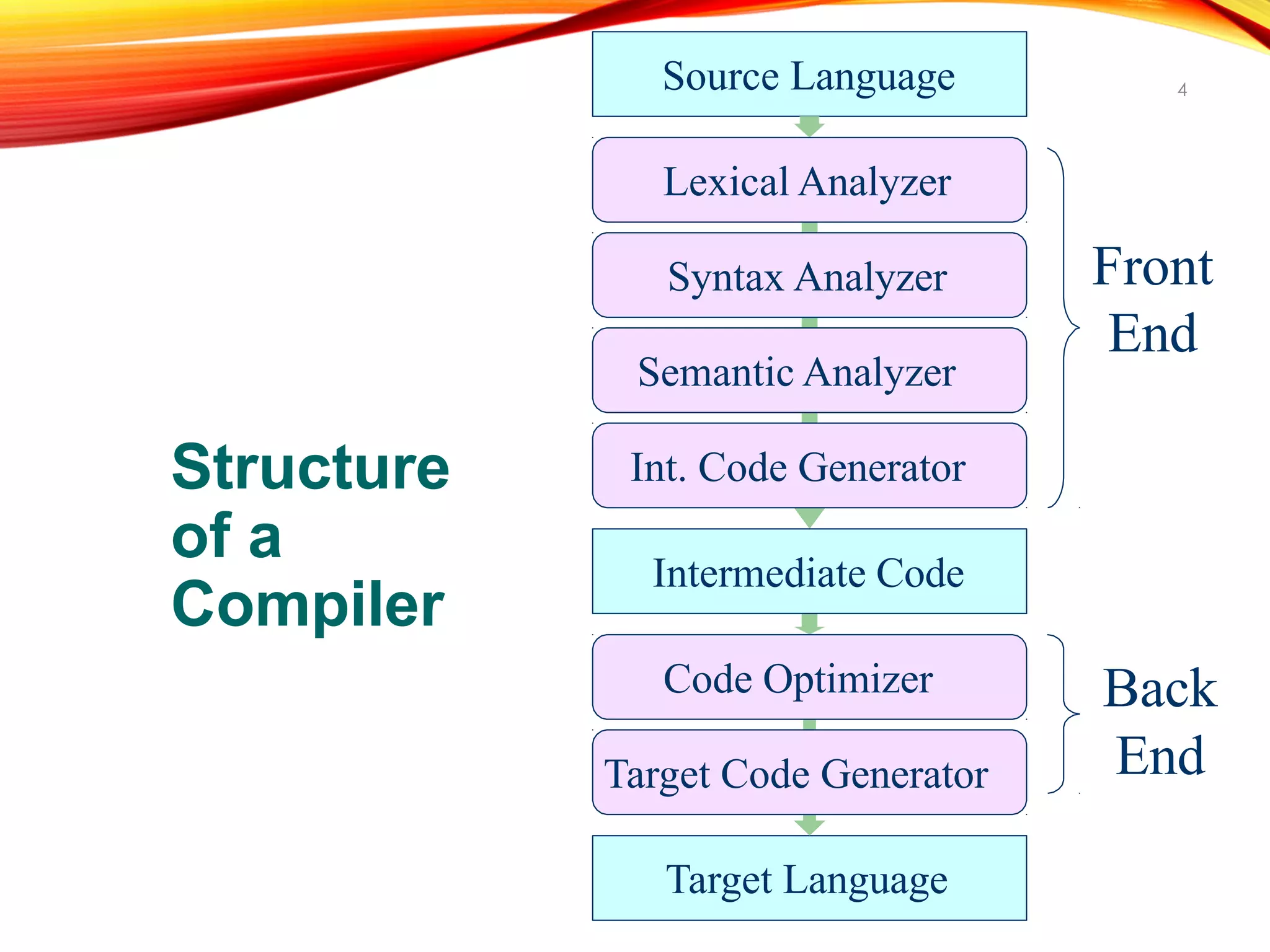
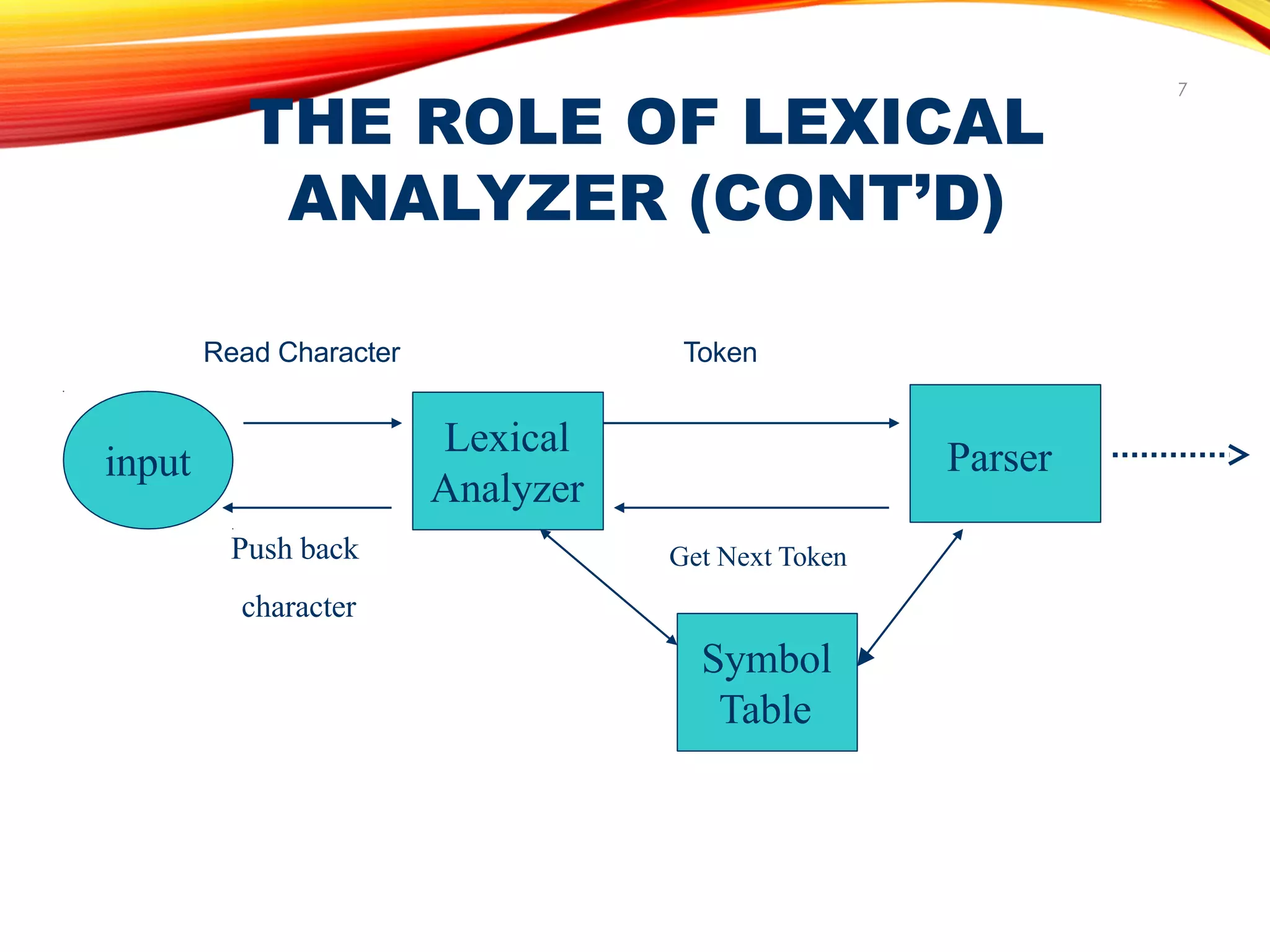
The document discusses the role of a lexical analyzer in a compiler. It states that the lexical analyzer is the first phase of a compiler. Its main task is to read characters as input and produce a sequence of tokens that the parser uses for syntax analysis. It groups character sequences into lexemes and passes the resulting tokens to the parser along with any attribute values. The lexical analyzer and parser form a producer-consumer relationship, with the lexical analyzer producing tokens for the parser to consume.





















![TOKENS (CONT’D)
26
As an example,consider the following line of
code,which could be part of a “ C ” program.
a [index] = 4 + 2](https://image.slidesharecdn.com/compilerdesign-230809185752-6a2ca3fe/75/COMPILER-DESIGN-pdf-26-2048.jpg)
![TOKENS (CONT’D)
27
a ID
[ Left bracket
index ID
] Right bracket
= Assign
4 Num
+ plus sign
2 Num](https://image.slidesharecdn.com/compilerdesign-230809185752-6a2ca3fe/75/COMPILER-DESIGN-pdf-27-2048.jpg)



























































