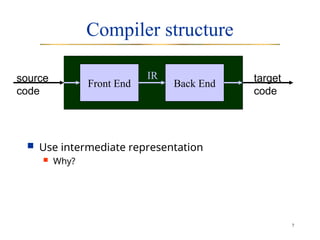
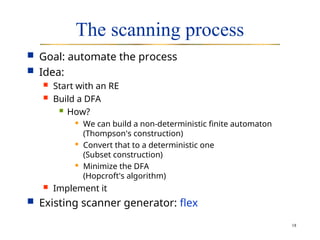
The document outlines a course on compiler construction by instructor Vana Doufexi, detailing course administration, objectives, and the fundamental concepts of compilers. It explores the compiler structure, including front-end processes like lexical analysis and parsing, as well as back-end tasks like instruction selection and optimization. The document also explains the scanning process, including the use of regular expressions and deterministic finite automata for automating token recognition.