2
TOPICS
Language Processors
Structure of a Compiler
Evolution of Programming Languages
Science of Building a Compiler
Applications of Compiler Technology
Programming Language Basics
3.
3
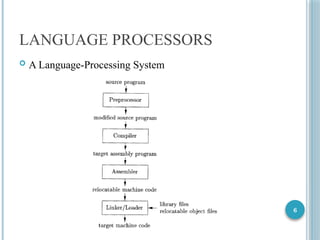
LANGUAGE PROCESSORS
COMPILER
Read a program in source language and translate into the
target language
Source language – High-level language like C, C++
Target language – object code of the target machine
Report any errors detected in the source program during
translation
4.
4
LANGUAGE PROCESSORS
INTERPRETER
Directly executes the operations specified in the source
program on inputs supplied by the user
Target program is not produced as output of translation
Gives better error-diagnostics than a compiler
Executes source program statement by statement
Target program produced by compiler is much faster at
mapping inputs to outputs
5.
5
LANGUAGE PROCESSORS
EXAMPLE
Java language processors combine compilation and
interpretation
Source program is first compiled into bytecodes
Bytecodes are then interpreted by a virtual machine
Just-in-time compilers
Translate bytecodes into machine language before they run the
intermediate program to process input
7
LANGUAGE PROCESSORS
Preprocessor
Source program may be divided into modules in separate files
Accomplishes the task of collecting the source program
Can delete comments, include other files, expand macros
Assembler
Compiler produces an assembly-language program
Symbolic form of the machine language
Produces relocatable machine code as output
8.
8
LANGUAGE PROCESSORS
Linker/Loader
Relocatable Code
Not ready to execute
Memory references are made relative to an undetermined starting
address in memory
Relocatable machine code may have to be linked with other
object files
Linker
Resolves external memory addresses
Code in file referring to a location in another file
Loader
Resolve all relocatable addresses relative to a given starting address
Puts together all the executable object files into memory for
execution
9.
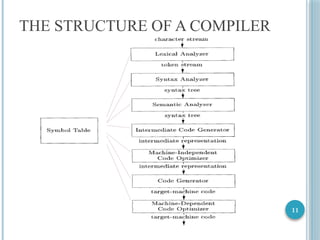
9
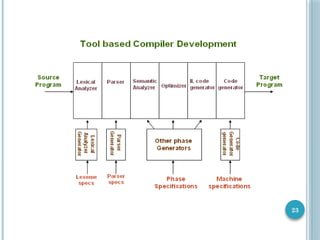
THE STRUCTURE OFA COMPILER
Analysis Phase
Break up source program into token or constituent pieces
Impose a grammatical structure
Create an intermediate representation of the source program
If source program is syntactically incorrect or semantically
wrong
Provide informative messages to the user
Symbol Table
Stores the information collected about the source program
Given to the synthesis phase along with the intermediate
representation
10.
10
THE STRUCTURE OFA COMPILER
Synthesis Phase
Constructs the desired target program from
Intermediate representation
Information in symbol table
Back end of the compiler
Analysis phase is called front end of the compiler
Compilation process is a sequence of phases
Each phase transforms one representation of source program
into another
Several phases may be grouped together
Symbol table is used by all the phases of the compiler
12
LEXICAL ANALYSIS
LexicalAnalyzer
Reads stream of characters in the source program
Groups the characters into meaningful sequences – lexemes
For each lexeme, a token is produced as output
<token-name , attribute-value>
Token-name : symbol used during syntax analysis
Attribute-value : an entry in the symbol table for this token
Information from symbol table is needed for syntax analysis
and code generation
Consider the following assignment statement
13.
13
SYNTAX ANALYSIS
Parsing
Parser uses the tokens to create a tree-like intermediate
representation
Depicts the grammatical structure of the token stream
Syntax tree is one such representation
Interior node – operation
Children - arguments of the operation
Other phases use this syntax tree to help analyze source
program and generate target program
14.
14
SEMANTIC ANALYSIS
SemanticAnalyzer
Checks semantic consistency with language using:
Syntax tree
Information in symbol table
Gathers type information and save in syntax tree or symbol
table
Type Checking
Checks each operator for matching operands
Ex: Report error if floating point number is used as index of an array
Coercions or type conversions
Binary arithmetic operator applied to a pair of integers or floating point
numbers
If applied to floating point and integer, compiler may convert integer to
floating-point number
15.
15
SEMANTIC ANALYSIS
SemanticAnalyzer
For our assignment statement
Position, rate and initial are floating-point numbers
Lexeme 60 is an integer
Type checker finds that * is applied to floating-point ‘rate’ and
integer ‘60’
Integer is converted to floating-point
16.
16
INTERMEDIATE CODE
GENERATION
Aftersyntax and semantic analysis
Compilers generate machine-like intermediate representation
This intermediate representation should have the two properties:
Should be easy to produce
Should be easy to translate into target machine
Three-address code
Sequence of assembly-like instructions with three operands per
instruction
Each operand acts like a register
17.
17
INTERMEDIATE CODE
GENERATION
Pointsto be noted about three-address instructions are:
Each assignment instruction has at most one operator on the right
side
Compiler must generate a temporary name to hold the value
computed by a three-address instruction
Some instructions have fewer than three operands
18.
18
CODE OPTIMIZATION
Attemptto improve the target code
Faster code, shorter code or target code that consumes less power
Optimizer can deduce that
Conversion of 60 from int to float can be done once at compile
time
So, the inttofloat can be eliminated by replacing 60 with 60.0
t3 is used only once to transmit its value to id1
19.
19
CODE GENERATION
CodeGenerator
Takes intermediate representation as input
Maps it into target language
If target language is machine code
Registers or memory locations are selected for each of the variables used
Intermediate instructions are translated into sequences of machine
instructions performing the same task
Assignment of registers to hold variables is a crucial aspect
First operand of each instruction specifies a destination
21
SYMBOL-TABLE MANAGEMENT
Essentialfunction of Compiler
Record variable names used in source program
Collect information about storage allocated for a name
Type
Scope – where in the program the value may be used
In case of procedure names,
Number and type of its argument
Method of passing each argument
Type returned
Symbol Table
Data structure containing a record for each variable name with
fields for attributes
24
EVOLUTION OF PROGRAMMING
LANGUAGES
Move to Higher-Level Languages
Development of mnemonic assembly languages in 1950’s
Classification of Languages
Generation
First-generation : machine languages
Second-generation : assembly languages
Third-generation : C, C++, C#, Java
Fourth-generation : SQL, Postscript
Fifth-generation : Prolog
Imperative and Declarative
Imperative : how a computation is to be done
Declarative : what computation is to be done
Object-oriented Language
Scripting Languages
25.
25
EVOLUTION OF PROGRAMMING
LANGUAGES
Impact on Compilers
Advances in PL’s placed new demands on compiler writers
Devise algorithms and representations to support new features
Performance of a computer is dependent on compiler technology
Good software-engineering techniques are essential for creating
and evolving modern language processors
Compiler writers must evaluate tradeoffs about
What problems to deal with
What heuristics to use to approach the problem of generating efficient
code
26.
26
SCIENCE OF BUILDINGA COMPILER
Modeling in Compiler Design and Implementation
Study of compilers is a study of how
To design the right mathematical models and
Choose the right algorithms
Finite-state machines and regular expressions
Useful for describing the lexical units of a program (keywords,
identifiers)
Used to describe the algorithms used to recognize those units
Context-free Grammars
Describe syntactic structure of PL
Nesting of parentheses, control constructs
27.
27
SCIENCE OF BUILDINGA COMPILER
Science of Code Optimization
“Optimization” – an attempt to produce code that is more efficient
Processor architectures have become more complex
Important to formulate the right problem to solve
Need a good understanding of the programs
Compiler design must meet the following design objectives
Optimization must be correct, i.e., preserve the meaning of compiled
program
Optimization must improve the performance of many programs
Compilation time must be kept reasonable
Engineering effort required must be manageable
28.
28
APPLICATIONS OF COMPILER
TECHNOLOGY
Implementation of high-level programming languages
High-level programming language defines a programming
abstraction
Low-level language have more control over computation and
produce efficient code
Hard to write, less portable, prone to errors and harder to maintain
Example : register keyword
Common programming languages (C, Fortran, Cobol) support
User-defined aggregate data types (arrays, structures, control flow )
Data-flow optimizations
Analyze flow of data through the program and remove redundancies
Key ideas behind object oriented languages are
Data Abstraction
Inheritance of properties
29.
29
APPLICATIONS OF COMPILER
TECHNOLOGY
Implementation of high-level programming languages
Java has features that make programming easier
Type-safe – an object cannot be used as an object of an unrelated type
Array accesses are checked to ensure that they lie within the bounds
Built in garbage-collection facility
Optimizations developed to overcome the overhead by eliminating
unnecessary range checks
30.
30
APPLICATIONS OF COMPILER
TECHNOLOGY
Optimizations for Computer Architectures
Parallelism
Instruction level : multiple operations are executed simultaneously
Processor level : different threads of the same application run on different
processors
Memory hierarchies
Consists of several levels of storage with different speeds and sizes
Average memory access time is reduces
Using registers effectively is the most important problem in optimizing a
program
Caches and physical memories are managed by the hardware
Improve effectiveness by changing the layout of data or order of
instructions accessing the data
31.
31
APPLICATIONS OF COMPILER
TECHNOLOGY
Design of new Computer Architectures
RISC (Reduced Instruction-Set Computer)
CISC (Complex Instruction-Set Computer) –
Make assembly programming easier
Include complex memory addressing modes
Optimizations reduce these instructions to a small number of simpler
operations
PowerPC, SPARC, MIPS, Alpha and PA-RISC
Specialized Architectures
Data flow machines, vector machines, VLIW, SIMD, systolic arrays
Made way into the designs of embedded machines
Entire systems can fit on a single chip
Compiler technology helps to evaluate architectural designs
32.
32
APPLICATIONS OF COMPILER
TECHNOLOGY
Program Translations
Binary Translation
Translate binary code of one machine to that of another
Allow machine to run programs compiled for another instruction set
Used to increase the availability of software for their machines
Can provide backward compatibility
Hardware synthesis
Hardware designs are described in high-level hardware description
languages like Verilog and VHDL
Described at register transfer level (RTL)
Variables represent registers
Expressions represent combinational logic
Tools translate RTL descriptions into gates, which are then mapped to
transistors and eventually to physical layout
33.
33
APPLICATIONS OF COMPILER
TECHNOLOGY
Program Translations
Database Query Interpreters
Languages are useful in other applications
Query languages like SQL are used to search databases
Queries consist of predicates containing relational and boolean operators
Can be interpreted or compiled into commands to search a database
Compiled Simulation
Simulation
Technique used in scientific and engg disciplines
Understand a phenomenon or validate a design
Inputs include description of the design and specific input parameters for
that run
34.
34
APPLICATIONS OF COMPILER
TECHNOLOGY
Software Productivity Tools
Testing is a primary technique for locating errors in a program
Use data flow analysis to locate errors statically
Problem of finding all program errors is undecidable
Ways in which program analysis has improved software productivity
Type Checking
Catch inconsistencies in the program
Operation applied to wrong type of object
Parameters to a procedure do not match the signature
Go beyond finding type errors by analyzing flow of data
If pointer is assigned null and then dereferenced, the program is clearly in error
35.
35
APPLICATIONS OF COMPILER
TECHNOLOGY
Software Productivity Tools
Bounds Checking
Security breaches are caused by buffer overflows in programs written in C
Data-flow analysis can be used to locate buffer overflows
Failing to identify a buffer overflow may compromise the security of the
system
Memory-management tools
Automatic memory management removes all memory-management errors
like memory leaks
Tools developed to help programmers find memory management errors
Purify - dynamically catches memory management errors as they occur
36.
36
PROGRAMMING LANGUAGE BASICS
The Static/Dynamic Distinction
What decision can the compiler make about a program
Static Policy - Language uses a policy that allows compiler to decide
an issue, i.e., at compile time
Dynamic Policy – Policy that allows a decision to be made when we
execute the program, i.e. at run time
Scope of Declarations
Scope declaration of x is the region of the program in which uses of x refer to
this declaration
Static or Lexical scope : Used if it is possible to determine the scope of a
declaration by looking only at the program
Dynamic Scope : As the program runs, the same use of x could refer to any
several different declaration of x
Example : public static int x;
37.
37
PROGRAMMING LANGUAGE BASICS
Environments and States
Whether the changes that occur as the program is run
Affects the values of the data elements
Affect interpretation of names for that data
Association of names with locations on memory (store) and then with
values is described as a two-stage mapping
Environment – Mapping from names to locations in the store
State – Mapping from locations in store to their values. It maps l-values to
their corresponding r-values
38.
38
PROGRAMMING LANGUAGE BASICS
Environments and States
Example
Exceptions to environment and state mappings
Static versus dynamic binding of names to locations
Static versus dynamic binding of locations to values
39.
39
PROGRAMMING LANGUAGE BASICS
Static Scope and Block Structure
Scope rules for C – based on program structure
Scope of a declaration – determined by the location of its appearance
Languages like C++,C# and Java provide explicit control over scopes
– public, private and protected
Static scope rules for a language with blocks – a grouping of
declarations and statements
C static scope policy is as follows:
C program is a sequence of top-level declarations of variables & functions
Functions may have variable declarations within them, scope of which is
restricted to the function in which it appears
Scope of a top-level declaration of a name x consists of the entire program that
follows
40.
40
PROGRAMMING LANGUAGE BASICS
Static Scope and Block Structure
The syntax of blocks in C is given by
It is a type of statement and can appear anywhere that other statements can
appear
Is a sequence of declarations followed by a sequence of statements, all
surrounded by braces
Block structure – nesting property of blocks
Static scope rule for variable declaration is as follows:
If declaration D of name x belongs to block B,
Then scope of D is all of B, except for any blocks B’ nested to any depth
within B in which x is redeclared
42
PROGRAMMING LANGUAGE BASICS
Explicit Access Control
Classes and structures introduce new scope for their members
If p is an object of a class with a field x, then use of x in p.x refers to field x in
the class definition
The scope of declaration x in a class C extends to any subclass C’, except if C’
has a local declaration of the same name x
Public, private and protected – provide explicit control over access to
member names in a super class
In C++, class definition may be separated from the definition of some
or all of its methods
A name x associated with the class C may have a region of code that is outside
its scope followed by another region within its scope
43.
43
PROGRAMMING LANGUAGE BASICS
Dynamic Scope
Based on factors that can be known only when the program executes
A use of a name x refers to the declaration of x in the most recently
called procedure with such a declaration
Macro expansion in the C preprocessor
Dynamic scope resolution is essential for polymorphic procedures
44.
44
PROGRAMMING LANGUAGE BASICS
Dynamic Scope
Method resolution in OOP
The procedure called when x.m() is executed depends on the class of the
object denoted by x at that time
Example:
Class C with a method named m()
D is a subclass of C , and D has its own method named m()
There is a use of m of the form x.m(), where x is an object of class C
Impossible to tell at compile time whether x will be of class C or of the
subclass D
Cannot be decided until runtime which definition of m is the right one
Code generated by compiler must determine the class of the object x, and call
one or the other method named m
45.
45
PROGRAMMING LANGUAGE BASICS
Parameter Passing Mechanisms
How actual parameters are associated with formal parameters
Actual parameters – used in the call of a procedure
Formal parameters – used in the procedure definition
Call-by-Value
The actual parameter is evaluated or copied
Value is placed in the location belonging to the corresponding formal
parameter of the called procedure
Computation involving formal parameters done by the called procedure is
local to that procedure and actual parameters cannot be changed
In C, we can pass a pointer to a variable to allow that variable to be changed
by the callee
Array names passed as parameters in C,C++ or Java give the called procedure
what is in effect a pointer or reference to the array itself
46.
46
PROGRAMMING LANGUAGE BASICS
Parameter Passing Mechanisms
Call-by-Reference
Address of actual parameter is passed to the callee as the value of the
corresponding formal parameter
Changes to formal parameter appear as changes to the actual parameter
Essential when the formal parameter is a large object, array or a structure
Strict call-by-value requires that the caller copy the entire actual parameter
into the space of the corresponding formal parameter
Copying is expensive when the parameter is large
Call-by-Name
The callee executes as if the actual parameter were substituted literally for the
formal parameter in the code of the callee
47.
47
PROGRAMMING LANGUAGE BASICS
Aliasing
Consequence of call-by-reference parameter passing
Possible that two formal parameters can refer to the same location
Such variables are said to be aliases of one another
Example:
a is an array belonging to procedure p, and p calls another procedure q(x,y)
with a call q(a,a)
Parameters are passed by value but the array names are references to the
location where the array is stored
So, x and y become aliases of each other
Understanding aliasing is essential for a compiler that optimizes a program
49
OBJECTIVES
Role ofLexical analyzer
Lexical analysis using formal language definitions with
Finite Automata
Specification of Tokens
Recognition of Tokens
50.
50
PROGRAMMING LANGUAGE
STRUCTURE
AProgramming Language is defined by:
SYNTAX
Decides whether a sentence in a language is well-formed
SEMANTICS
Determines the meaning , if any, of a syntactically well-formed sentence
GRAMMAR
Provides a generative finite description of the language
Well developed tools (regular, context-free and attribute
grammars) are available for the description of syntax
Lexical analyzer and the Parser handle the syntax of the
programming language
51.
51
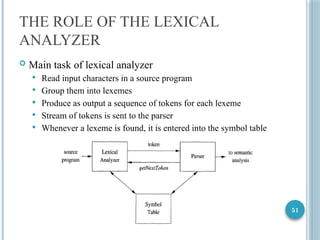
THE ROLE OFTHE LEXICAL
ANALYZER
Main task of lexical analyzer
Read input characters in a source program
Group them into lexemes
Produce as output a sequence of tokens for each lexeme
Stream of tokens is sent to the parser
Whenever a lexeme is found, it is entered into the symbol table
52.
52
THE ROLE OFTHE LEXICAL
ANALYZER
Other tasks performed by the lexical analyzer
Removing comments and whitespace
Correlating error messages generated by compiler with source program
Associates a line number with each error message
Makes a copy of the source program with error messages
Cascade of two processes
Scanning
Processes that do not require the tokenization of input, like, deletion of
comments and compaction of whitespaces
Lexical analysis
Scanner produces the sequence of tokens as output
53.
53
THE ROLE OFTHE LEXICAL
ANALYZER
Lexical Analysis versus Parsing
Simplicity of design
Separation of lexical and syntactic analysis allows to simplify one of these tasks
A parser that has to deal with comments and whitespace is more complex
Compiler efficiency is improved
Allows to apply specialized techniques that serve only the lexical task
Specialized buffering techniques for reading input
Compiler portability is enhanced
Input device specific peculiarities can be restricted to lexical analyzer
54.
54
TOKENS, PATTERNS, ANDLEXEMES
Token
Pair consisting of a token name and an optional attribute value
Token name – abstract symbol for a lexical unit, like keyword
Pattern
Description of the form that the lexemes of a token may take
If keyword is a token, pattern is a sequence of characters that form the
keyword
Lexeme
Sequence of characters in the source program that matches the pattern for a
token
Identified by the lexical analyzer as an instance of that token
55.
55
TOKENS, PATTERNS, ANDLEXEMES
Typical tokens in a Programming Language
One token for each keyword
Tokens for the operators
Token representing all identifiers
One or more tokens representing constants, such as numbers and literal
strings
Tokens for each punctuation symbol, such as comma, semicolon, left and
right parentheses
56.
56
ATTRIBUTES FOR TOKENS
When more than one lexeme matches a pattern, additional
information about the lexeme must be passed
Example : Pattern for token number matches both 0 and 1
So, lexical analyzer returns to the parser both the token name and attribute
value describing the lexeme
Token name influences parsing decisions
Attribute value influences translation of tokens after the parse
Appropriate attribute value for an identifier is a pointer to the symbol-table
entry for that entry
57.
57
LEXICAL ERRORS
Lexicalanalyzer is unable to proceed because none of the
patterns for tokens matches any prefix of the remaining input
Error recovery strategy
“Panic mode” recovery
Delete successive characters from the remaining input, until the lexical analyzer
can find a well-formed token at the beginning of the input left
Delete one character from the remaining input
Insert a missing character into the remaining input
Replace a character by another character
Transpose two adjacent characters
See whether a prefix of the remaining input can be transformed into a valid
lexeme by a single transformation
58.
58
INPUT BUFFERING
BufferPairs
Specialized buffering techniques to reduce the amount of overhead to
process a single input character
Scheme involving two buffers that are alternately reloaded
eof – marks the end of the source file
Two pointers to the input
lexemeBegin – marks beginning of the current lexeme
forward – scans ahead until a pattern match is found
59.
59
INPUT BUFFERING
BufferPairs
Once the next lexeme is determined, forward is set to the character at
its right end
After lexeme is recorded as an attribute value, lexemeBegin is set to
the character immediately after the lexeme just found
To advance forward pointer,
Test whether the end of one of the buffers has been reached
If so, then reload the other buffer from the input
Move forward to the beginning of the newly loaded buffer
60.
60
INPUT BUFFERING
Sentinels
In previous scheme, each time the forward pointer is advanced,
Must check that we have not moved off one of the buffers
If we do, then reload the other buffer
For each character read, make two tests
End of buffer
Determine what character is read
Combine the buffer-end test with the test for current character, if we
extend each buffer to hold a sentinel character at the end
Sentinel is a special character that is not a part of the source program
61.
61
SPECIFICATION OF TOKENS
Strings and Languages
Alphabet
Finite set of symbols, e.g., letters, digits and punctuation
Binary alphabet – {0,1}
String over an alphabet
Finite sequence of symbols drawn from that alphabet
Length of string s (|s|) – number of occurrences of symbols in s
Empty string (ε) –string of length zero
Language
Set of strings over some fixed alphabet
Ex :
{ε}, set containing only the empty string
Set of all syntactically well-formed C programs
62.
62
SPECIFICATION OF TOKENS
Strings and Languages
Prefix of a string s
String obtained by removing zero or more symbols from the end of s
Suffix of string s
String obtained by removing zero or more symbols from the beginning if s
Substring of s
String obtained by deleting any prefix and any suffix from s
Proper prefixes, suffixes and substrings of a string s :
Prefixes, suffixes and substrings of s that are not or not equal to s itself
Subsequence of s
Any string formed by deleting zero or more not necessarily consecutive positions
of s
Concatenation of x and y (xy)
String formed by appending y to x
63.
63
SPECIFICATION OF TOKENS
Operations on Languages
Kleene Closure (L*
)
Set of strings obtained by concatenating L zero or more times
L0
- concatenation of L zero times, that is ,{ }
Positive Closure (L+
)
Same as Kleene closure but without the term L0
ε
64.
64
SPECIFICATION OF TOKENS
Regular Expressions
Notation used for describing all languages that can be built from these
operators applied to the symbols of some alphabet
Ex: Language of C identifiers letter (letter | digit)*
Each regular expression r denotes a language L(r), defined recursively
from the languages denoted by r’s sub expressions
Rules that define the RE’s over some alphabet
ε is a regular expression and L(ε ) is {ε }
If a is a symbol in alphabet, then a is a regular expression and L(a) = {a}
r and s are RE’s denoting languages L(r) and L(s), then
(r)|(s) is a RE denoting the language L(r) U L(s)
(r)(s) is a RE denoting the language L(r)L(s)
(r)*
is a RE denoting (L(r))*
(r) is a RE denoting L(r)
65.
65
SPECIFICATION OF TOKENS
Regular Expressions
Parentheses in RE’s may be dropped if we adopt the following
Unary operator * has highest precedence and is left associative
Concatenation has second highest precedence and is left associative
| has lowest precedence and is left associative
Example: (a) | ((b)*
(c) a | b*
c
Regular set : Language defined by a RE
Two RE’s are equivalent if they denote the same regular set
Ex: (a|b) = (b|a)
66.
66
SPECIFICATION OF TOKENS
Regular Definitions
If is an alphabet of symbols, then a regular definition is a sequence
of definitions of the form
d1 r1
d2 r2
........
dn rn
Each di is a new symbol, not in and not the same as any other of the d’s
Each ri is a RE over the alphabet U {d1, d2,... ,di-1}
Avoid recursive definition by restricting ri to and the previously
defined d’s
Construct a RE over alone for each ri
67.
67
SPECIFICATION OF TOKENS
Extensions of Regular Expressions
One or more instances
Unary operator +
, represents positive closure of a RE and its language
r*
= r+
| ε and r+
= rr*
= r*
r
Zero or one instance
Unary operator ? Means “zero or one occurence”
r? = r|ε or L(r?) = L(r) U {ε}
Character classes
Regular expression, a1| a2|....| an can be replaced by [a1 a2... an ]
[abc] is short form for a|b|c
68.
68
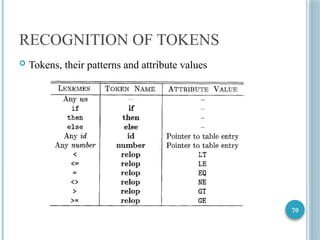
RECOGNITION OF TOKENS
Study how to take patterns for all the needed tokens
Build a piece of code that examines the input string
Find a prefix that is a lexeme matching one of the patterns
Simple form of branching statements and conditional expressions
Terminals of the grammar : if, then, else, relop, id, number
69.
69
RECOGNITION OF TOKENS
Patterns for the tokens are described using regular definitions
Recognize the token ws, to remove whitespaces
71
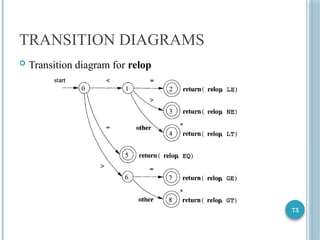
TRANSITION DIAGRAMS
Convertpatterns into flowcharts called transition diagrams
States
Represents a condition that could occur during the scanning of input
that matches a pattern
Edges
Directed from one state to another
Labelled by a symbol or set of symbols
If in some state s, and next input symbol is a,
Look for an edge out of state s labelled by a
If such an edge is found, advance the forward pointer and enter the
state to which that edge leads
72.
72
TRANSITION DIAGRAMS
Importantconventions about transition diagrams
Certain states are said to be final or accepting
Indicate that a lexeme has been found
If there is an action to be taken – returning a token an attribute value to the
parser – attach that action tot he accepting state
If it is necessary to retract the forward pointer one position, then
place a * near the accepting state
One state is the start state or initial state
Transition diagram always begins in the start state before any input symbols
have been read
74
RECOGNITION OF RESERVEDWORDS
AND IDENTIFIERS
Keywords like if or then are reserved, even though they look
like identifiers they are not identifiers
Two ways to handle reserved words that look like identifiers
1. Install the reserved words in the symbol table initially
When an identifier is found, call to installID places it in the symbol table and
returns a pointer to the symbol-table entry
Any identifier not in the symbol table during lexical analysis has a token id
getToken examines the symbol table entry for the lexeme found and returns
the token name
75.
75
RECOGNITION OF RESERVEDWORDS
AND IDENTIFIERS
Two ways to handle reserved words that look like identifiers
2. Create separate transition diagrams for each keyword
Such a diagram consists of states representing the situation after each
successive letter of keyword is seen , followed by a test for “nonletter-or-
digit”
Necessary to check that the identifier has ended, or else would return
token then in situations where correct token was id
76.
76
ARCHITECTURE OF ATRANSITION-
DIAGRAM-BASED LEXICAL ANALYZER
Collection of transition diagrams can be used to build a lexical
analyzer
Each state is represented by a piece of code
Variable state holding the number of the current state
A switch based on the value of state takes us to the code for each of
the possible states, where action of that state is found
Code for a state is itself a switch statement or multiway branch that
determines the next state
77.
77
ARCHITECTURE OF ATRANSITION-
DIAGRAM-BASED LEXICAL ANALYZER
Fig : Implementation of relop transition diagram
78.
78
ARCHITECTURE OF ATRANSITION-
DIAGRAM-BASED LEXICAL ANALYZER
Ways in which the code could fit into the entire lexical analyzer
Arrange the transition diagrams for each token to be tried sequentially
Function fail() resets the forward pointer and starts next transition diagram
Allows to use transition diagrams for the individual keywords
Run various transition diagrams “in parallel”
Feed the next input character to all of them an allow each one to make the
transitions required
Must be careful to resolve the case where
One diagram finds a lexeme that matches the pattern
While one or more other diagrams are still able to process the input
Combine all transition diagrams into one
Allow to read input until there is no possible next state
Take the longest lexeme that matched any pattern






























































![67
SPECIFICATION OF TOKENS
Extensions of Regular Expressions
One or more instances
Unary operator +
, represents positive closure of a RE and its language
r*
= r+
| ε and r+
= rr*
= r*
r
Zero or one instance
Unary operator ? Means “zero or one occurence”
r? = r|ε or L(r?) = L(r) U {ε}
Character classes
Regular expression, a1| a2|....| an can be replaced by [a1 a2... an ]
[abc] is short form for a|b|c](https://image.slidesharecdn.com/unit1cd1-250725194046-757fa34b/85/unit1_cd-unit1_cd-unit1_cd-unit1_cd-unit1_cd-1-pptx-67-320.jpg)