Downloaded 303 times


















![[nod to Matt Jones, for many conversations we had about cities while working together at
Dopplr]](https://image.slidesharecdn.com/cityanalytics-110228102823-phpapp01/75/Cognitive-Cities-City-analytics-26-2048.jpg)




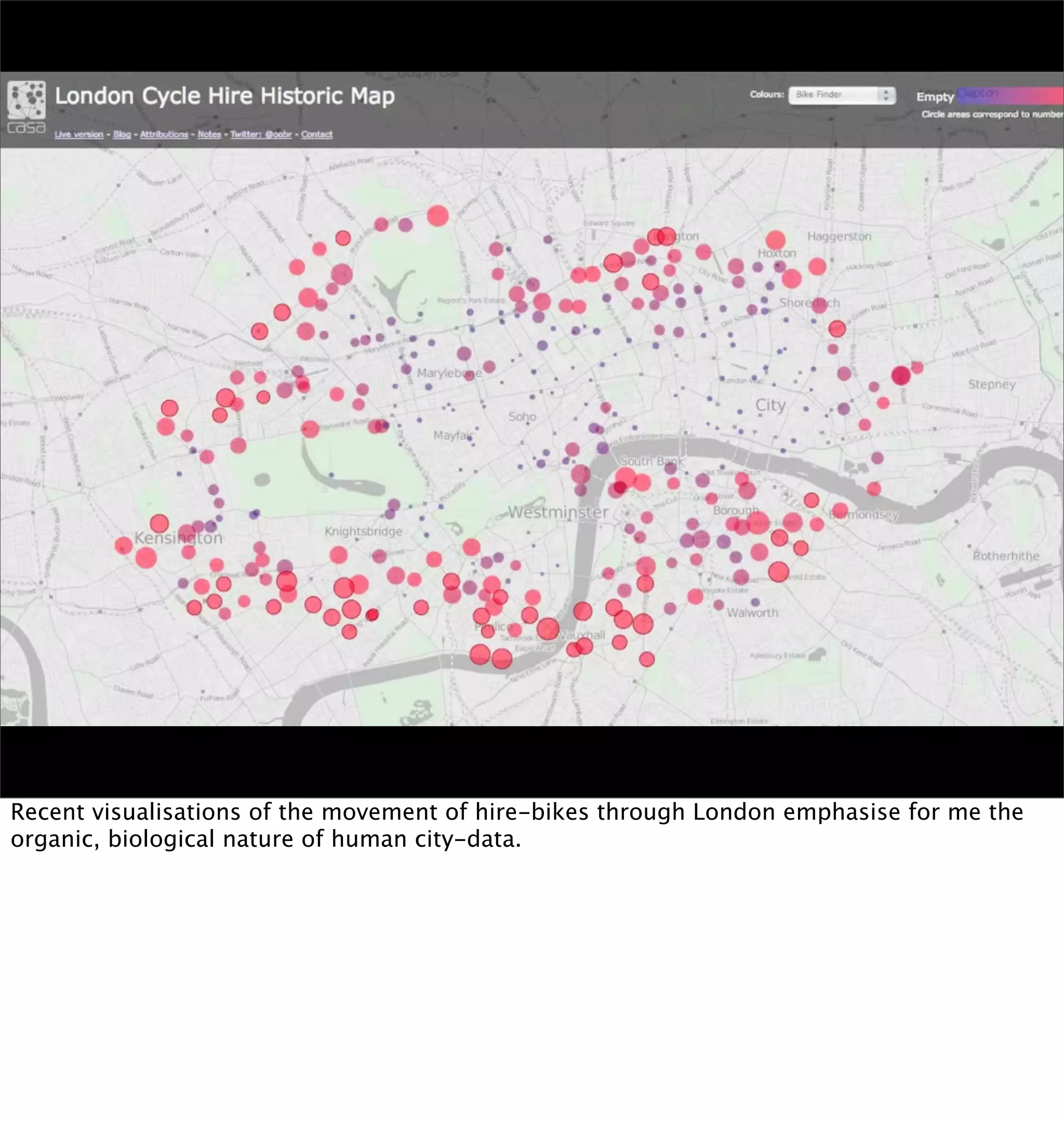
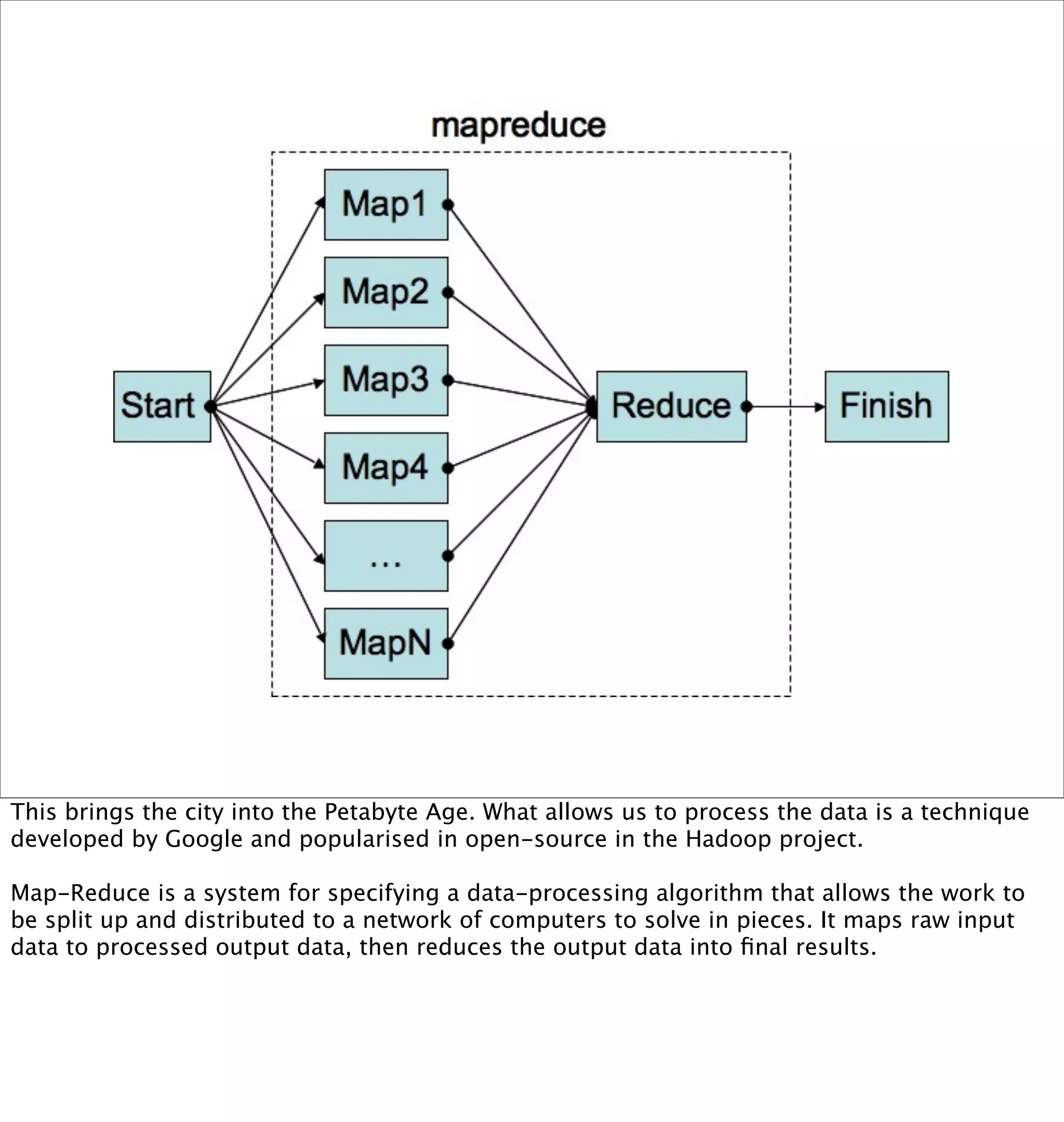
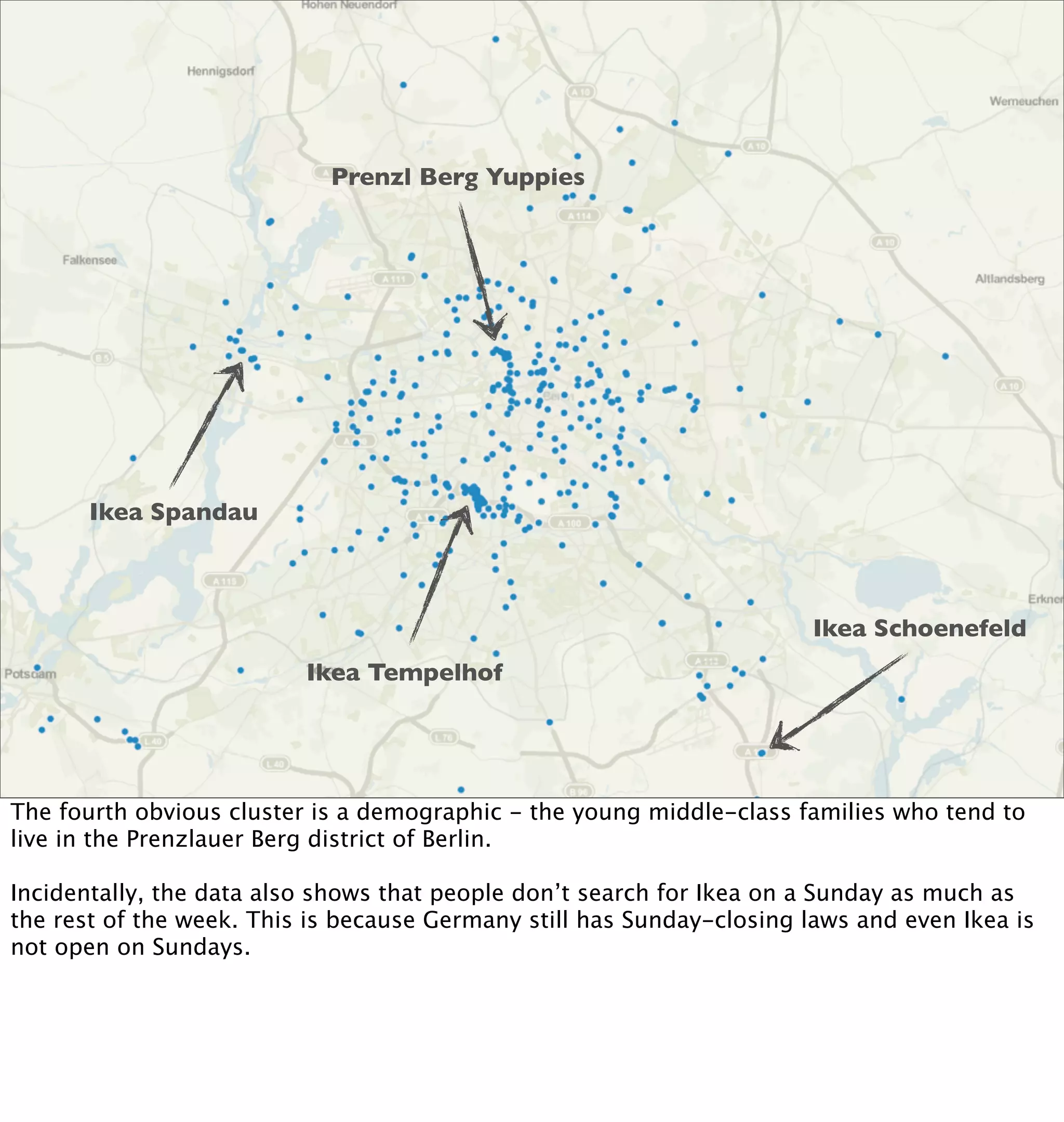
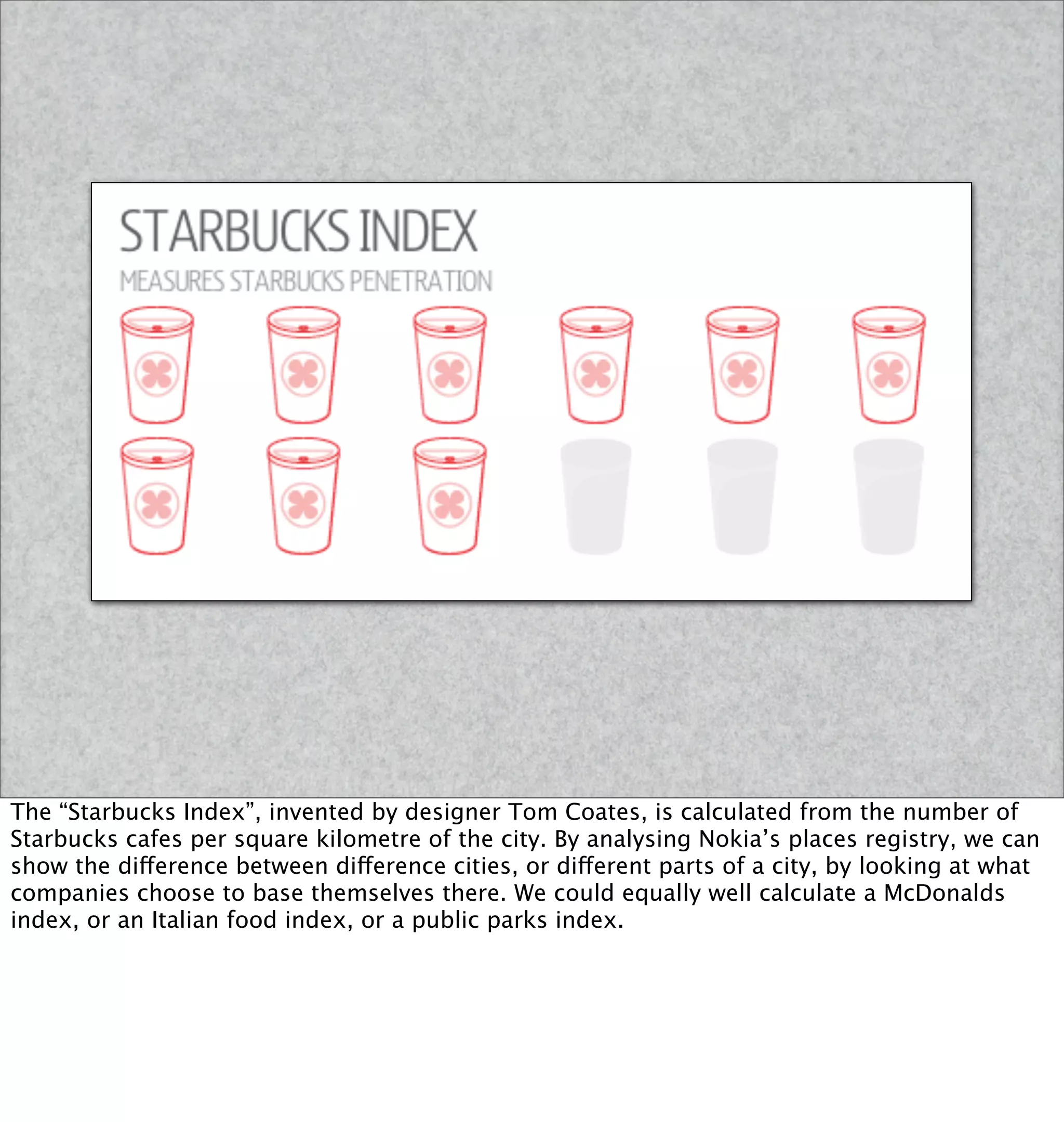
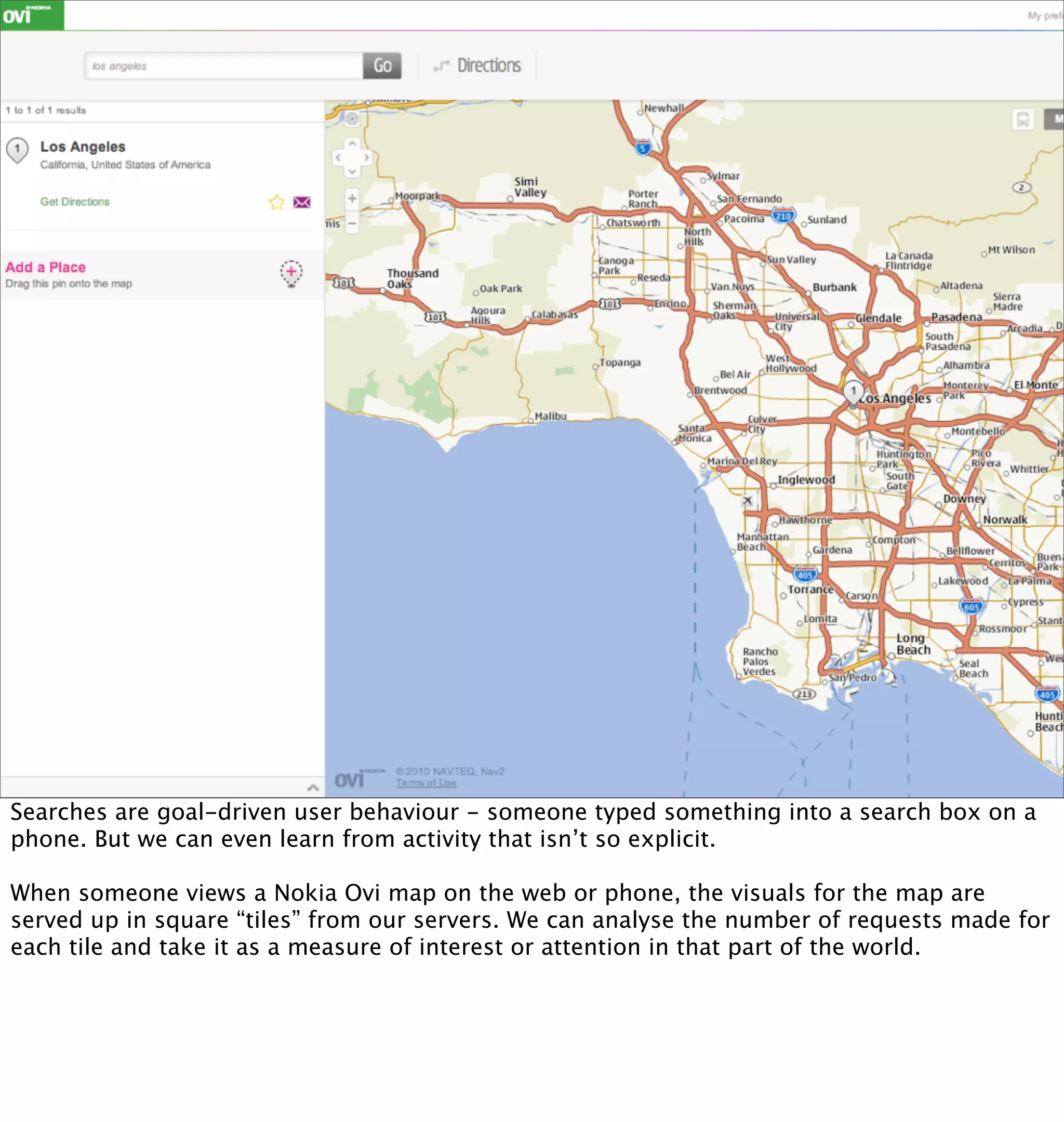
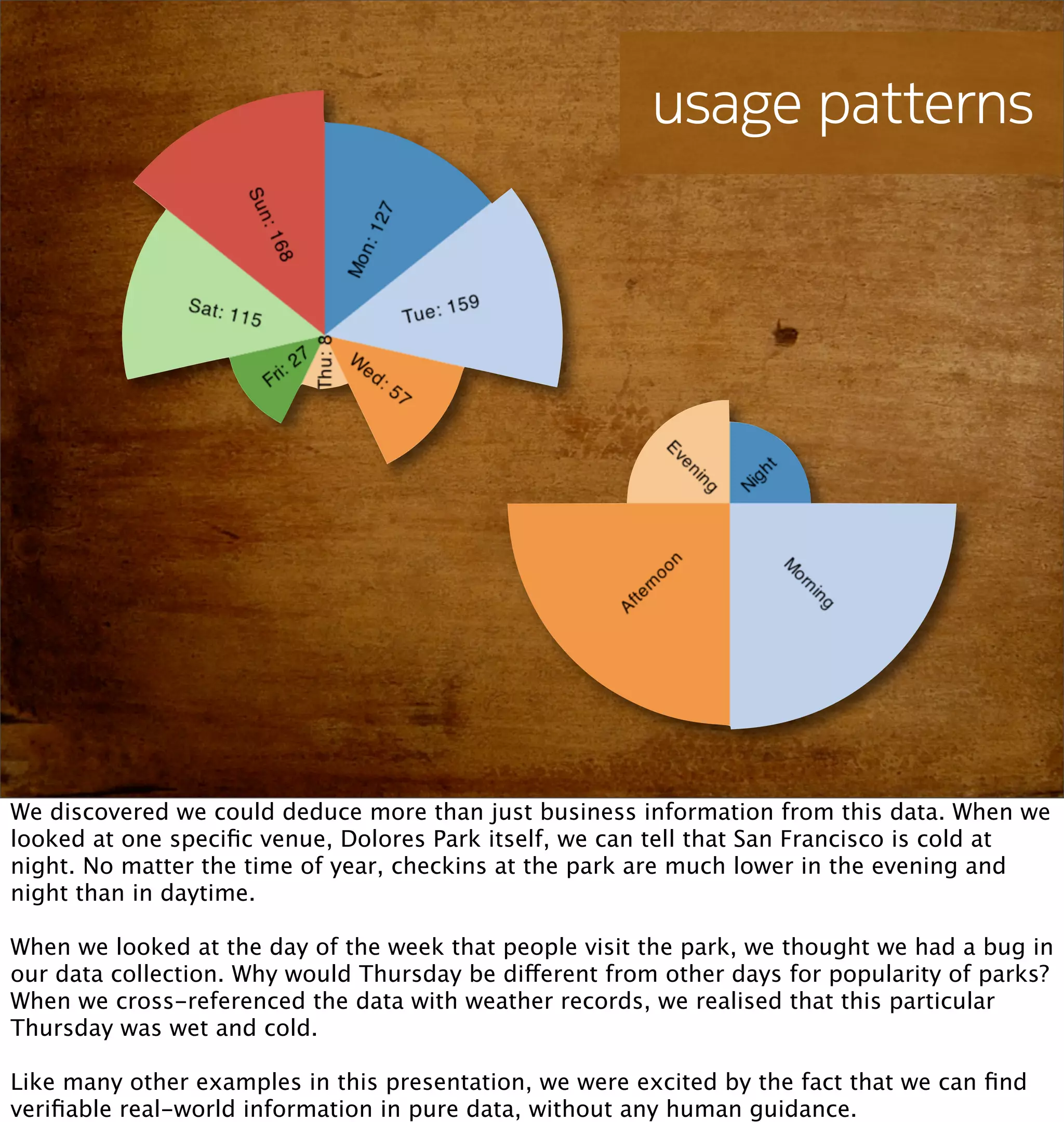
This document discusses how mobile phone data can be used to understand and model cities. It provides examples of analyzing aggregated and anonymized data from mobile phones to understand search patterns, map views, check-ins, and other data to learn about a city's businesses, transportation patterns, and usage over time. The document argues that with the vast amount of sensor and usage data collected from phones, they can act as "city samplers" and allow analysis of a city's "biology" without traditional surveys or models.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







