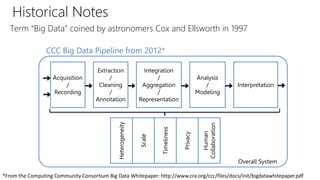
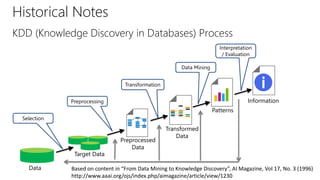
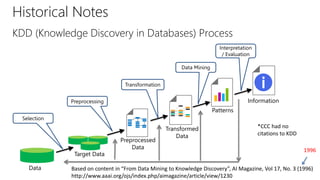
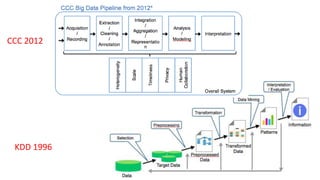
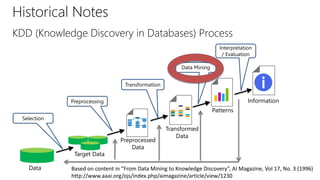
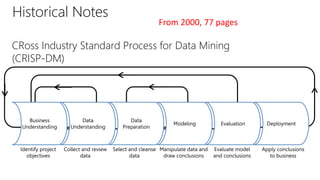
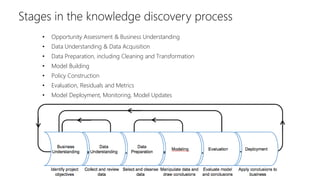
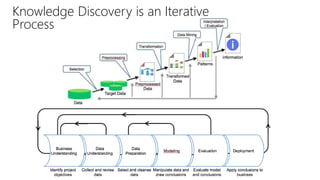
The document provides an overview of the data science process, highlighting historical notes on concepts like KDD, CRISP-DM, and their relevance to big data and machine learning. It illustrates the knowledge discovery process through a case study on predicting power failures in Manhattan, detailing stages such as data understanding, model building, and policy construction. The iterative nature of data science is emphasized, along with the importance of model deployment and evaluation.