Download to read offline




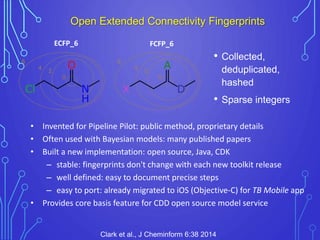

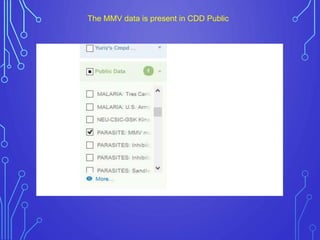
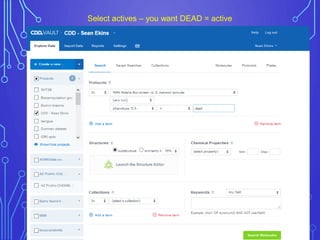
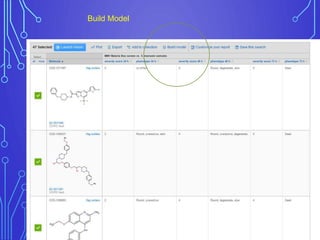
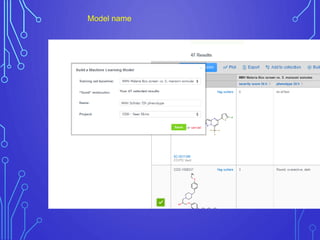
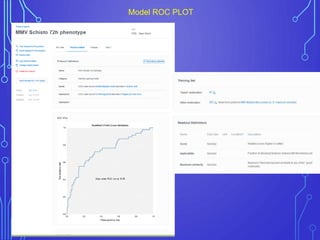
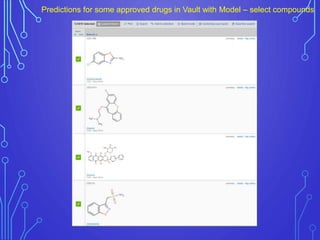
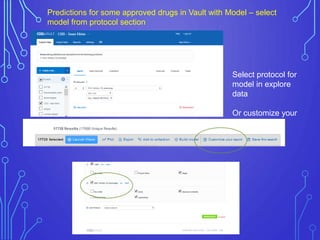
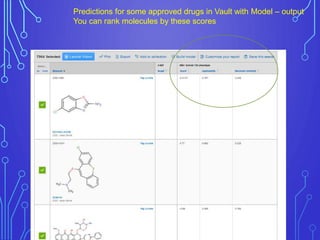
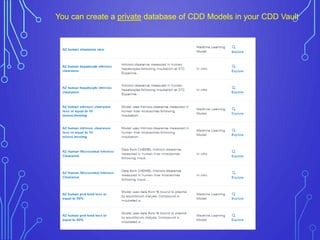
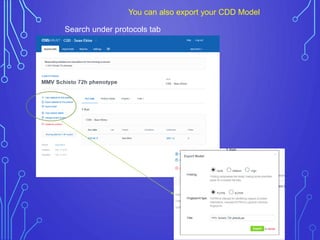




The case study outlines methods for building machine learning models using the Collaborative Drug Discovery (CDD) vault and public datasets. It discusses techniques for exporting models for internal use or sharing, and includes examples of utilizing specific datasets like MMV for predictions on drug compounds. The document emphasizes the benefits of open-source implementations and collaboration in drug discovery research.
















![C D D Mind The Health Gap 2010 Talk.Ppt [ Autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cdd-mind-the-health-gap-2010-talkppt-autosaved-1300341777-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Cdd mind the health gap 2010 talk.ppt [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cddmindthehealthgap2010talk-pptautosaved-110317011336-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)












