Download as PDF, PPTX



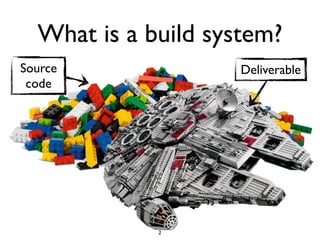
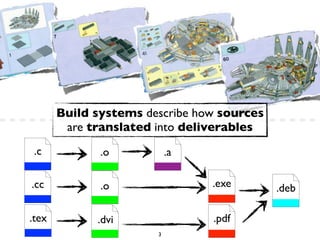
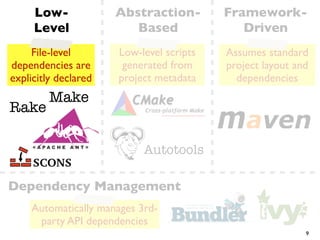
![The Build “Tax”
“...nothing can be said
to be certain, except
death and taxes”
- Benjamin Franklin
Up to 27% of source
changes require build
changes, too!
An Empirical Study of
Build Maintenance Effort
S. McIntosh, B. Adams, T. H. D.
Nguyen,Y. Kamei, A. E. Hassan
[ICSE 2011]
5](https://image.slidesharecdn.com/buildtechs-130312105613-phpapp02/85/Buildtechs-6-320.jpg)


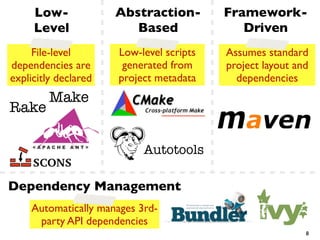

![Mining a Large-
Scale Corpus
Amassing and indexing a
large sample of version
control systems
Towards the census of public
source code history
A. Mockus [MSR 2009]
843,976 source
code repositories!
13](https://image.slidesharecdn.com/buildtechs-130312105613-phpapp02/85/Buildtechs-14-320.jpg)
![Software Forges
Mining a Large-
Scale Corpus
repo.or.cz
Amassing and indexing a
large sample of version
control systems
Towards the census of public
source code history
A. Mockus [MSR 2009]
843,976 source
code repositories!
13](https://image.slidesharecdn.com/buildtechs-130312105613-phpapp02/85/Buildtechs-15-320.jpg)
![Software Forges
Mining a Large-
Scale Corpus
repo.or.cz
Amassing and indexing a
large sample of version
control systems
Towards the census of public Software Ecosystems
source code history
A. Mockus [MSR 2009]
843,976 source
code repositories!
13](https://image.slidesharecdn.com/buildtechs-130312105613-phpapp02/85/Buildtechs-16-320.jpg)
![Software Forges
Mining a Large-
Scale Corpus
repo.or.cz
Amassing and indexing a
large sample of version
control systems
Towards the census of public Software Ecosystems
source code history
A. Mockus [MSR 2009]
843,976 source
Large Projects
code repositories!
13](https://image.slidesharecdn.com/buildtechs-130312105613-phpapp02/85/Buildtechs-17-320.jpg)
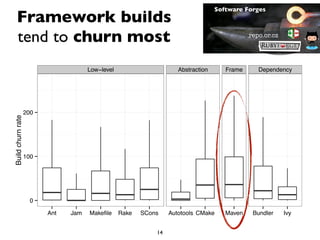
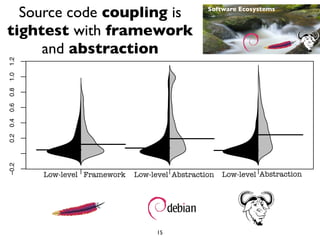
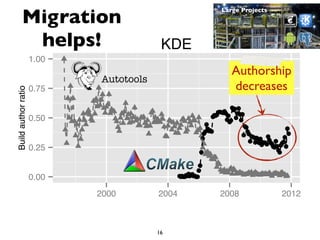



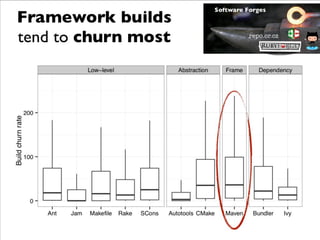



This document summarizes the results of a large-scale empirical study on the relationship between build systems and build maintenance activity. The study analyzed over 800,000 open source projects to compare how different build technologies (e.g. Make, Autotools, Maven) affect build churn, source code coupling, and authorship over time. The key findings are that framework-based build systems tend to have higher build churn, tighter source code coupling, and decreasing authorship as projects migrate to more advanced technologies.

























































