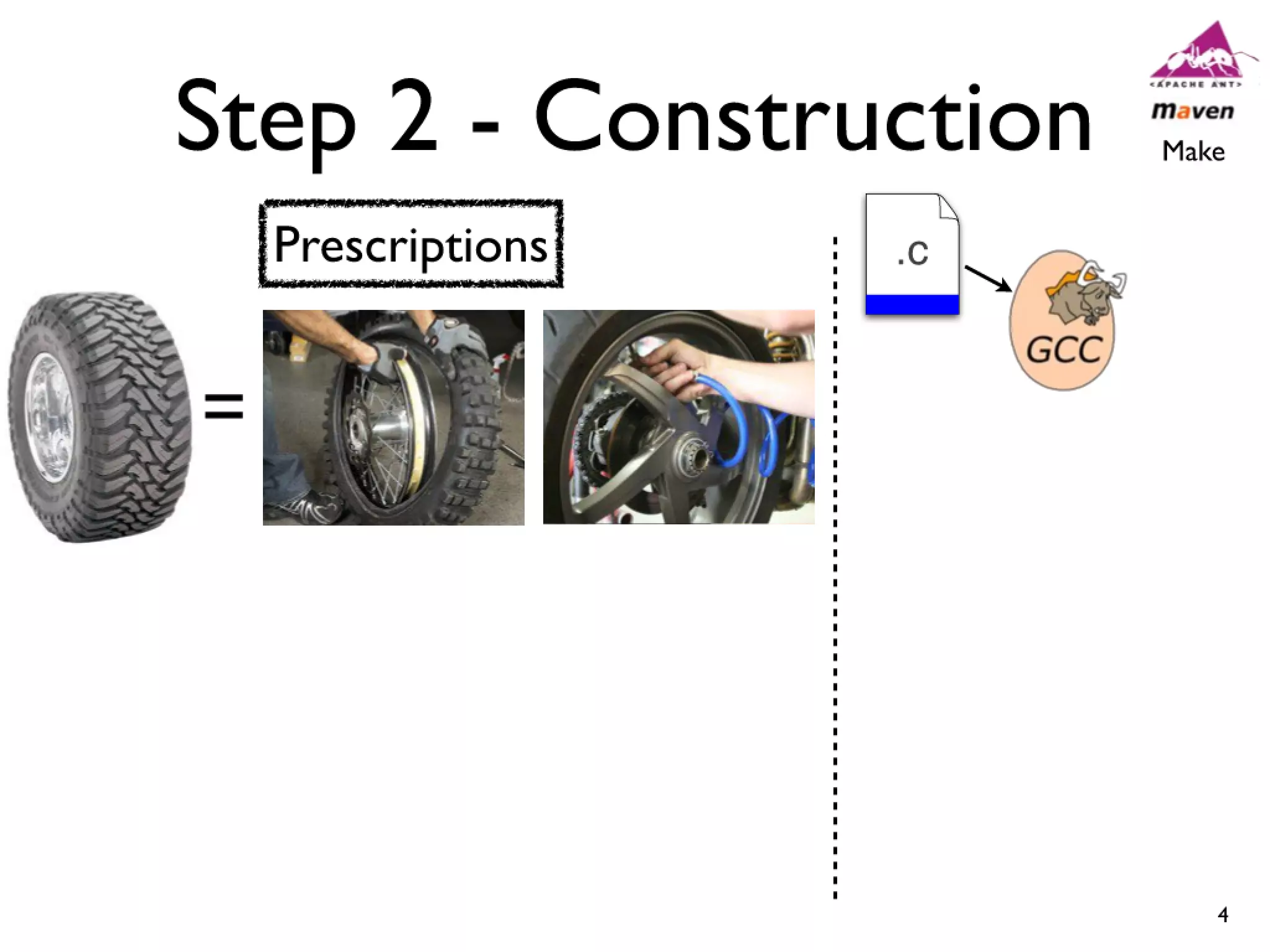
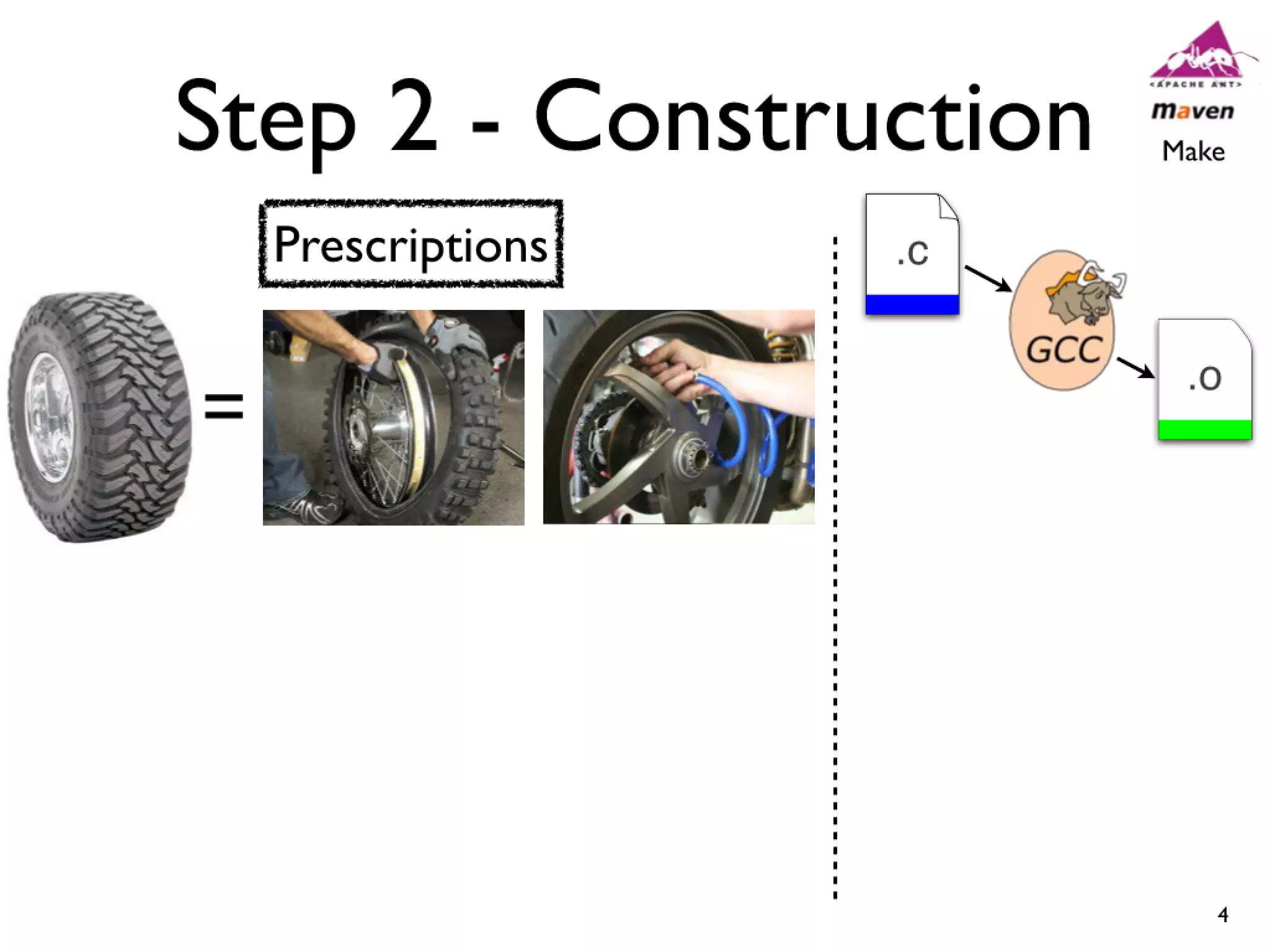
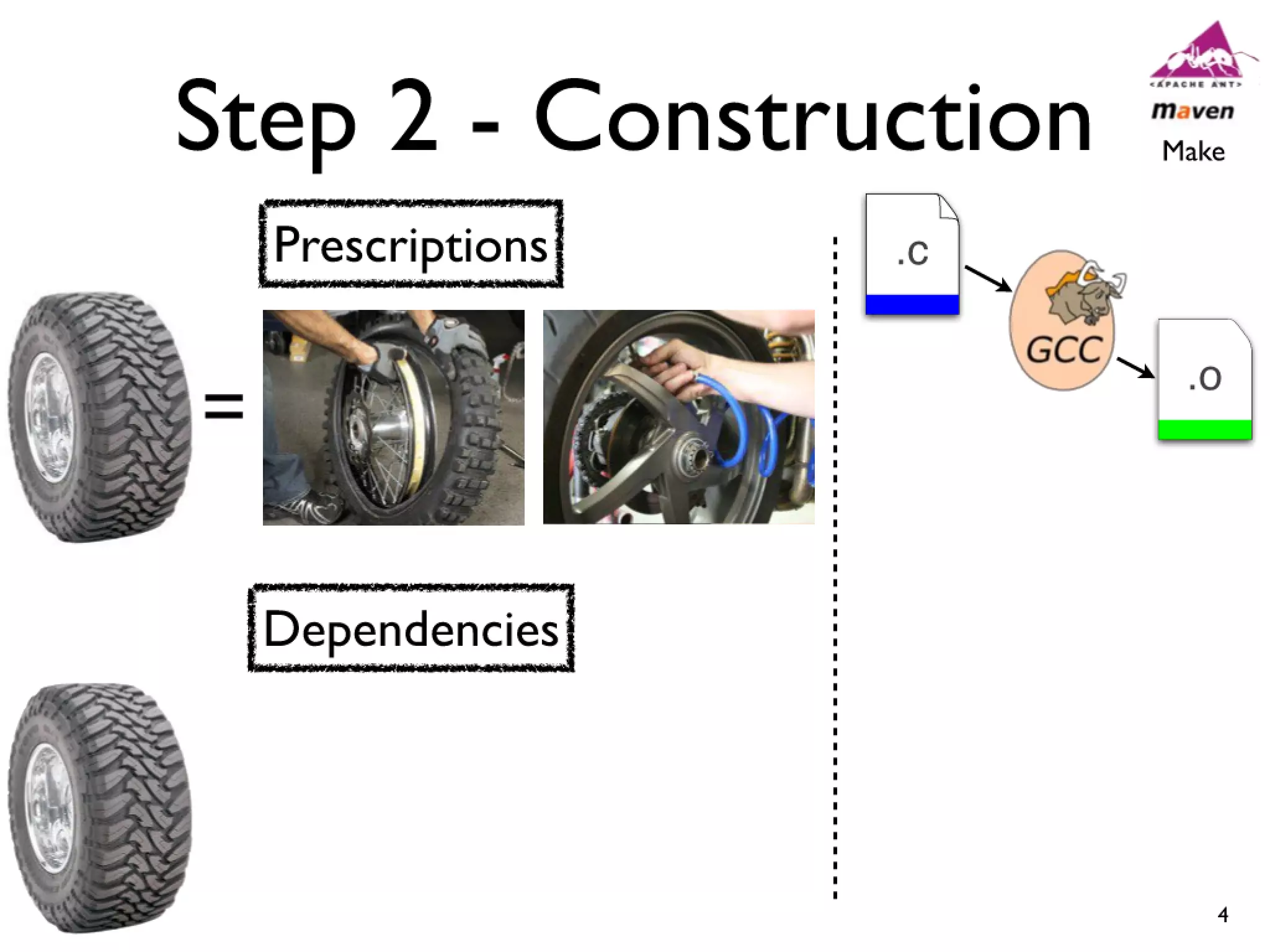
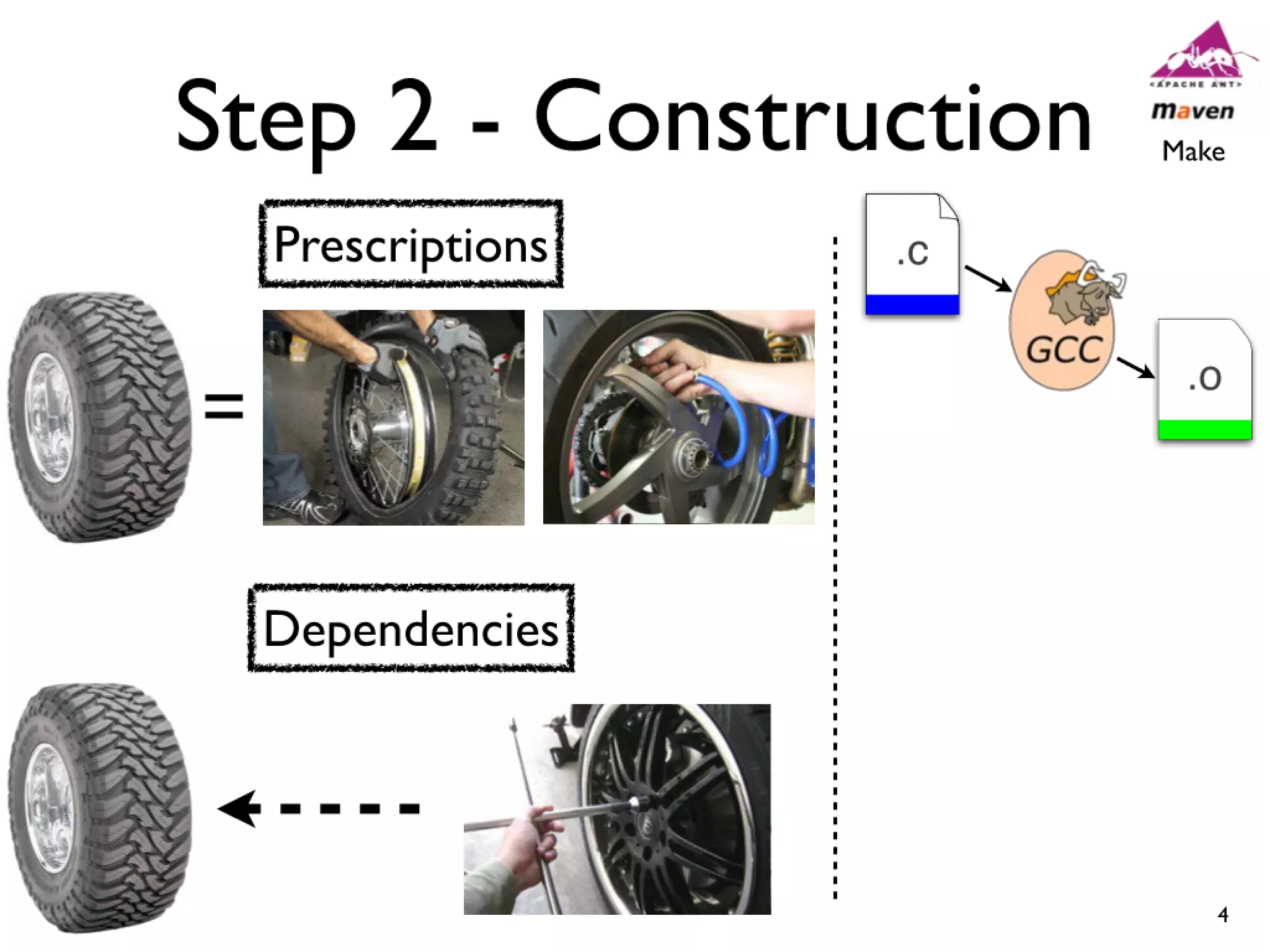
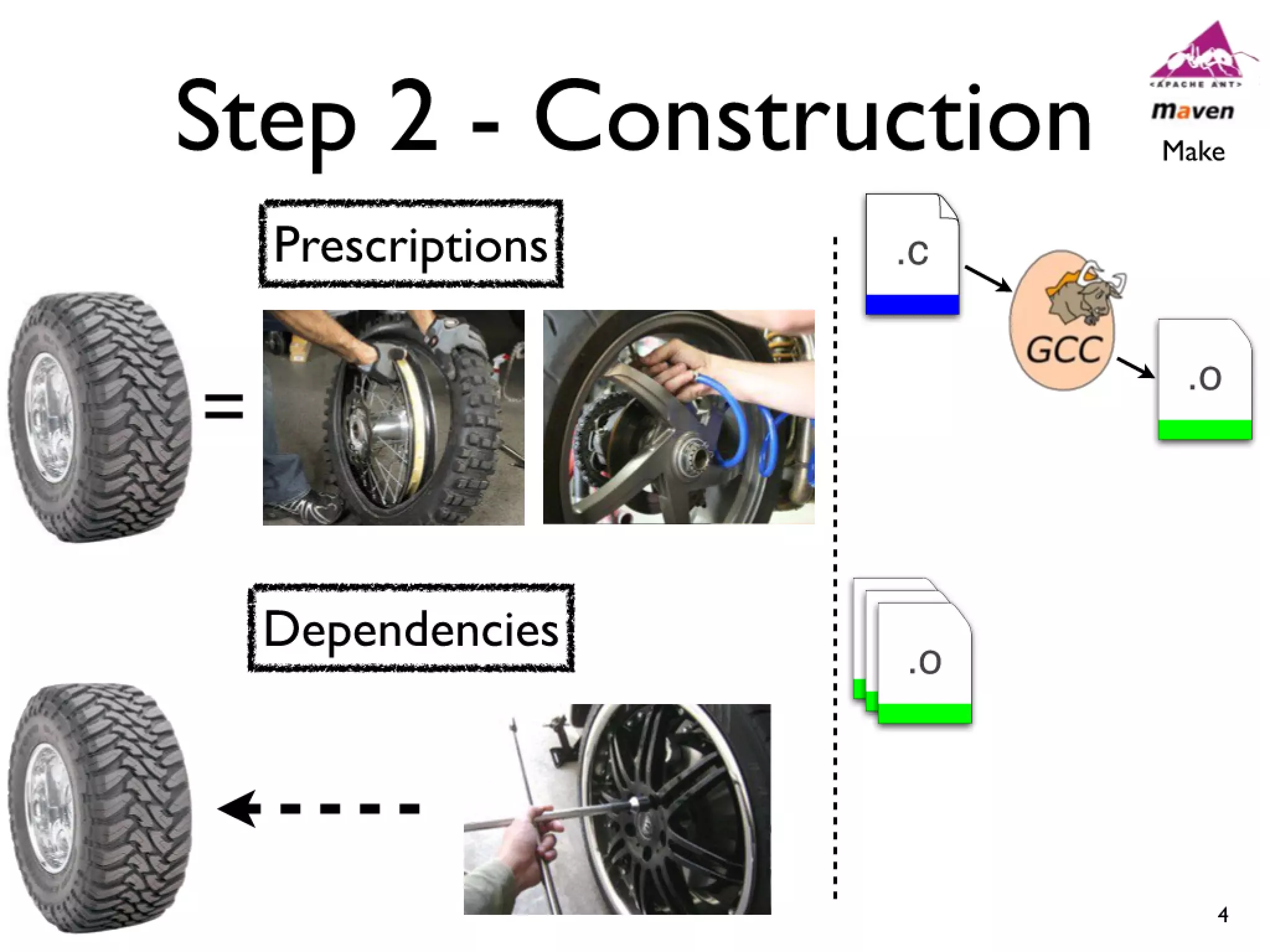
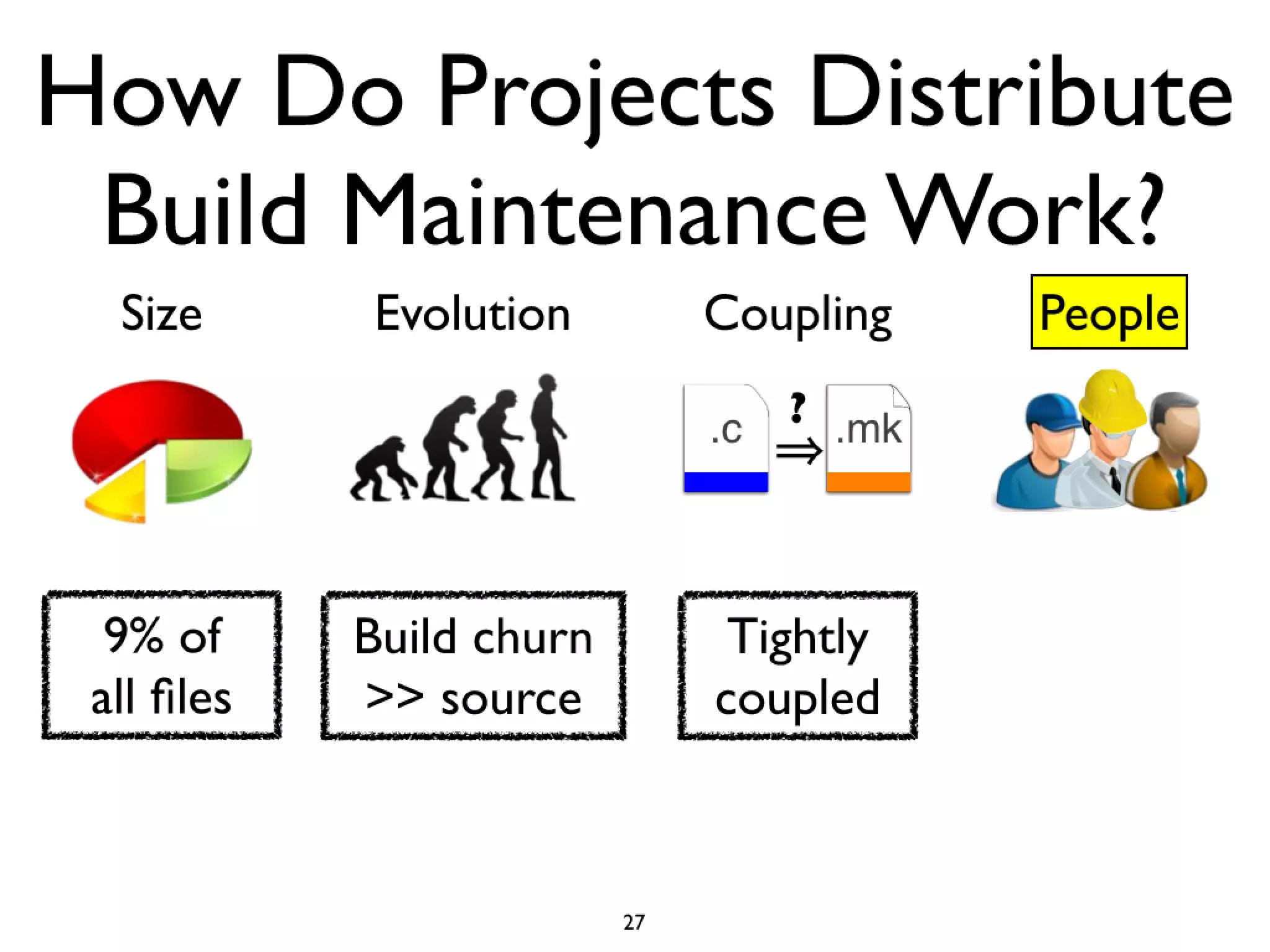
#14 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
#15 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
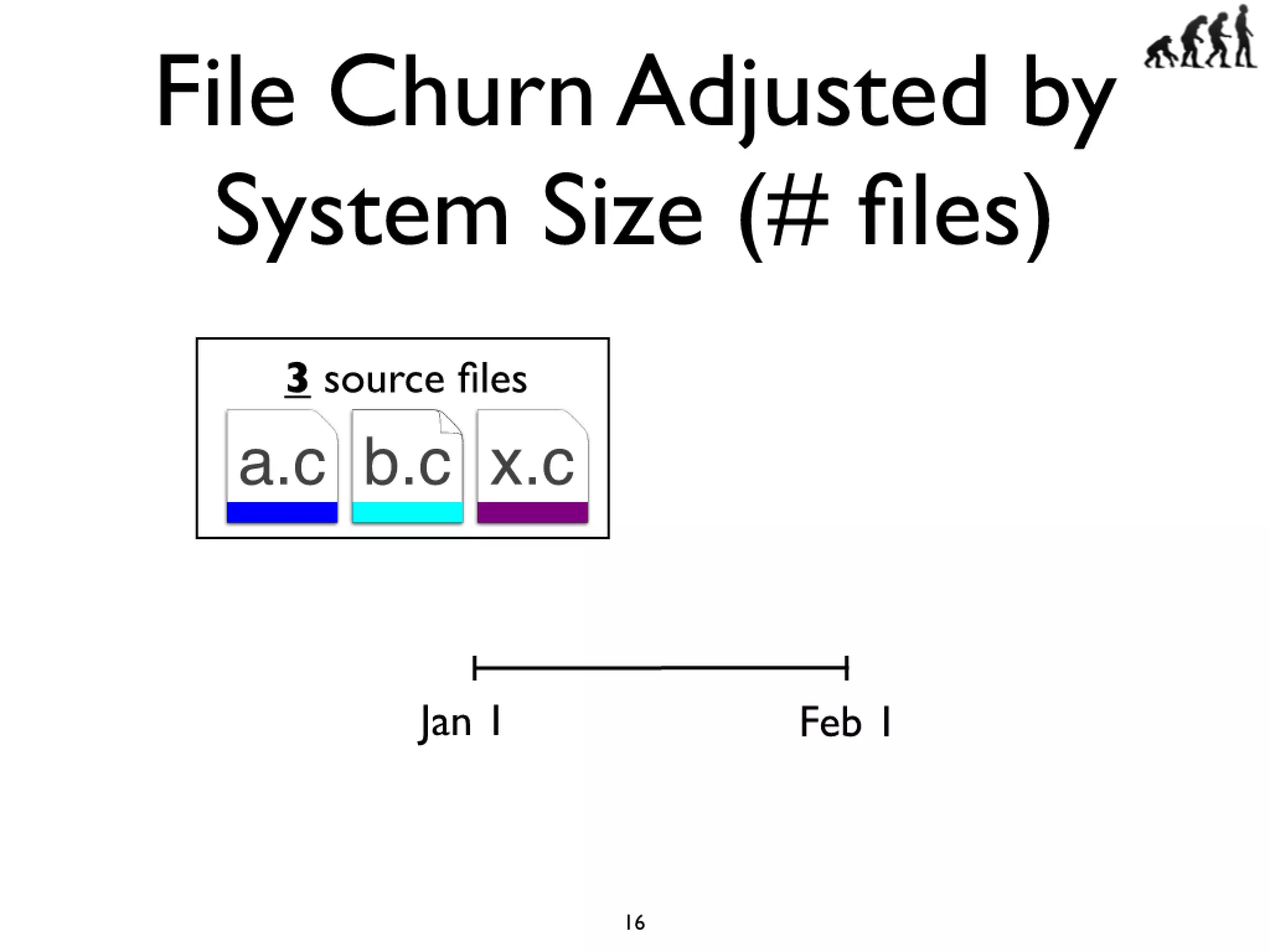
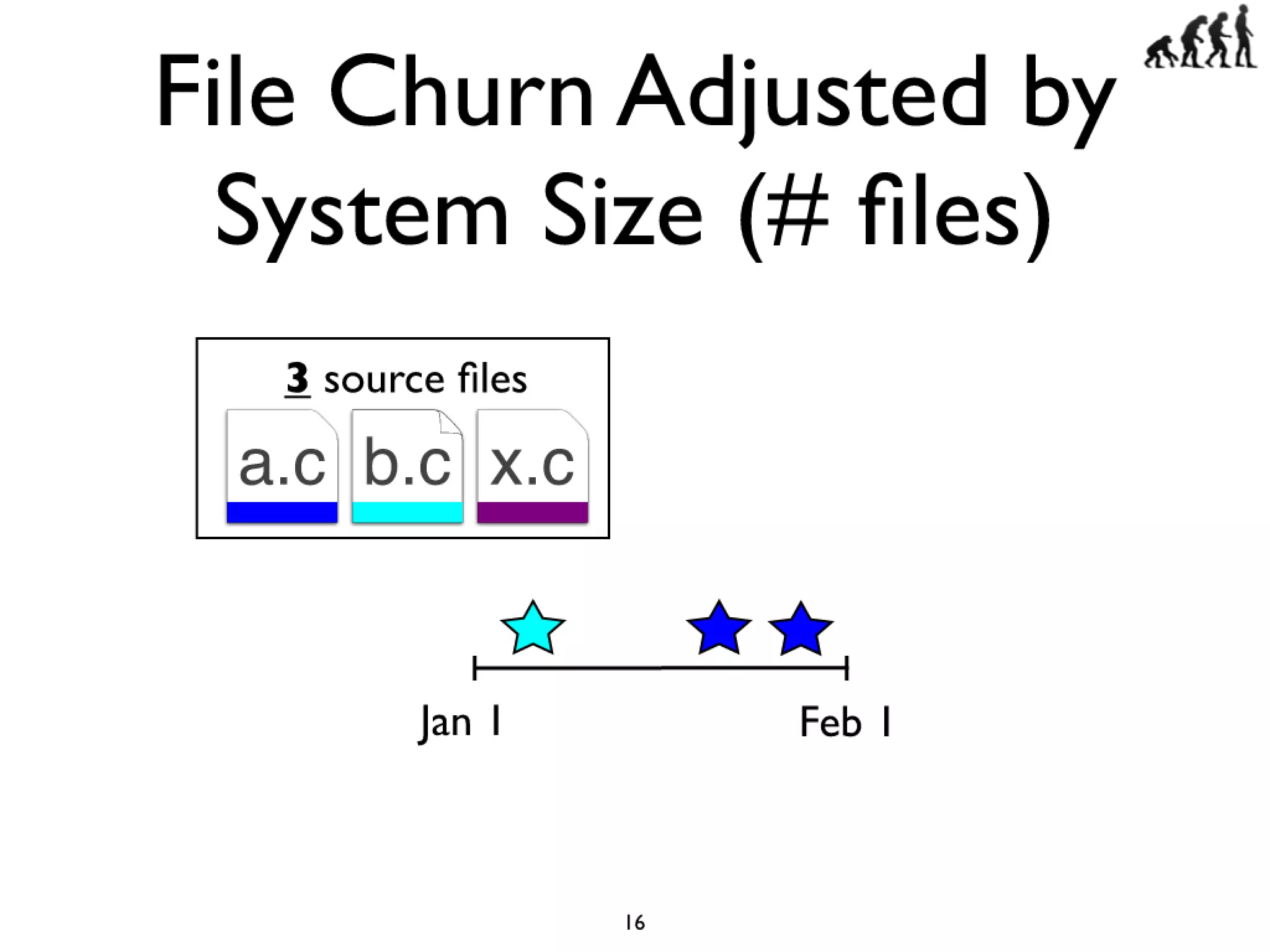
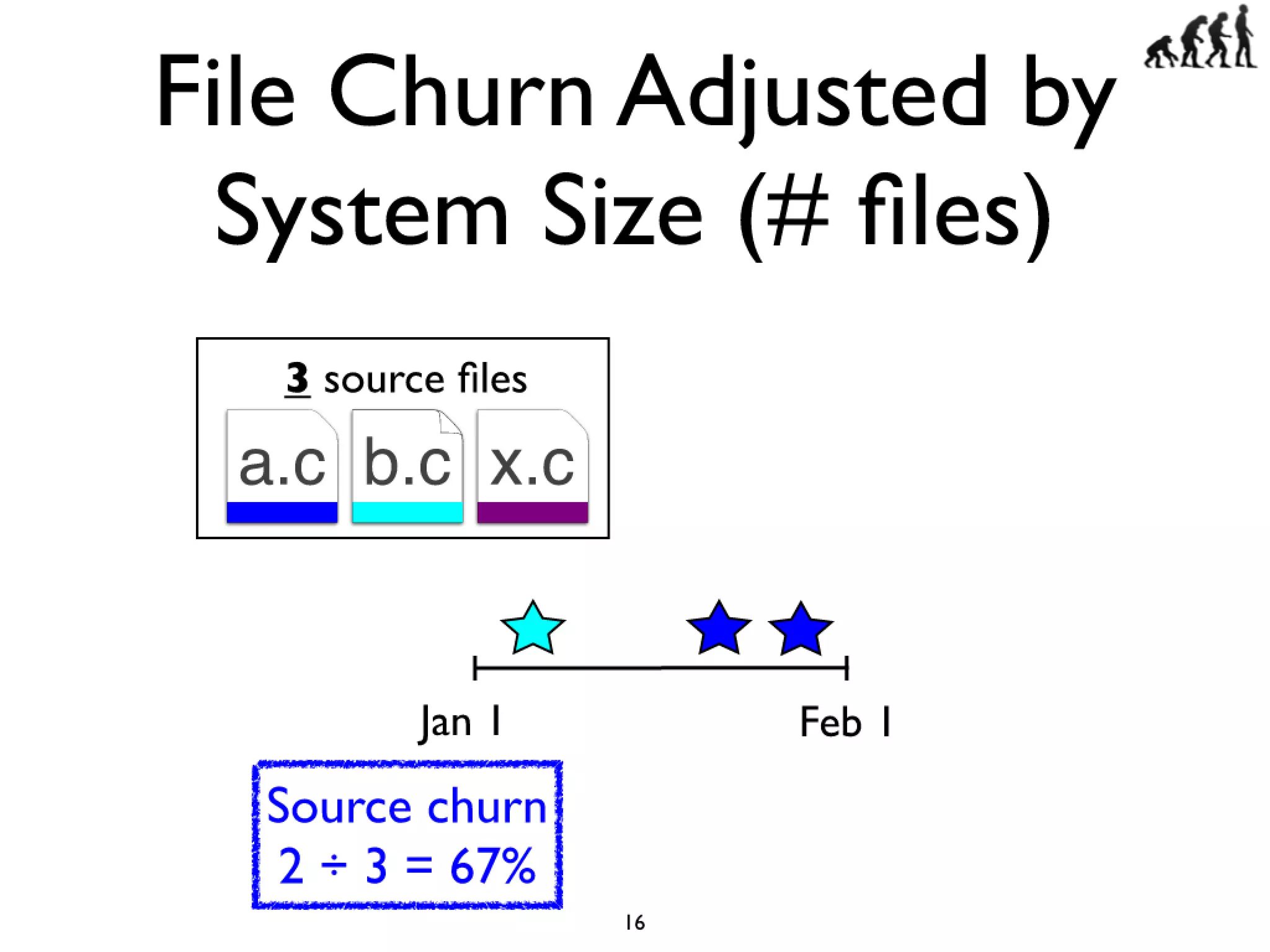
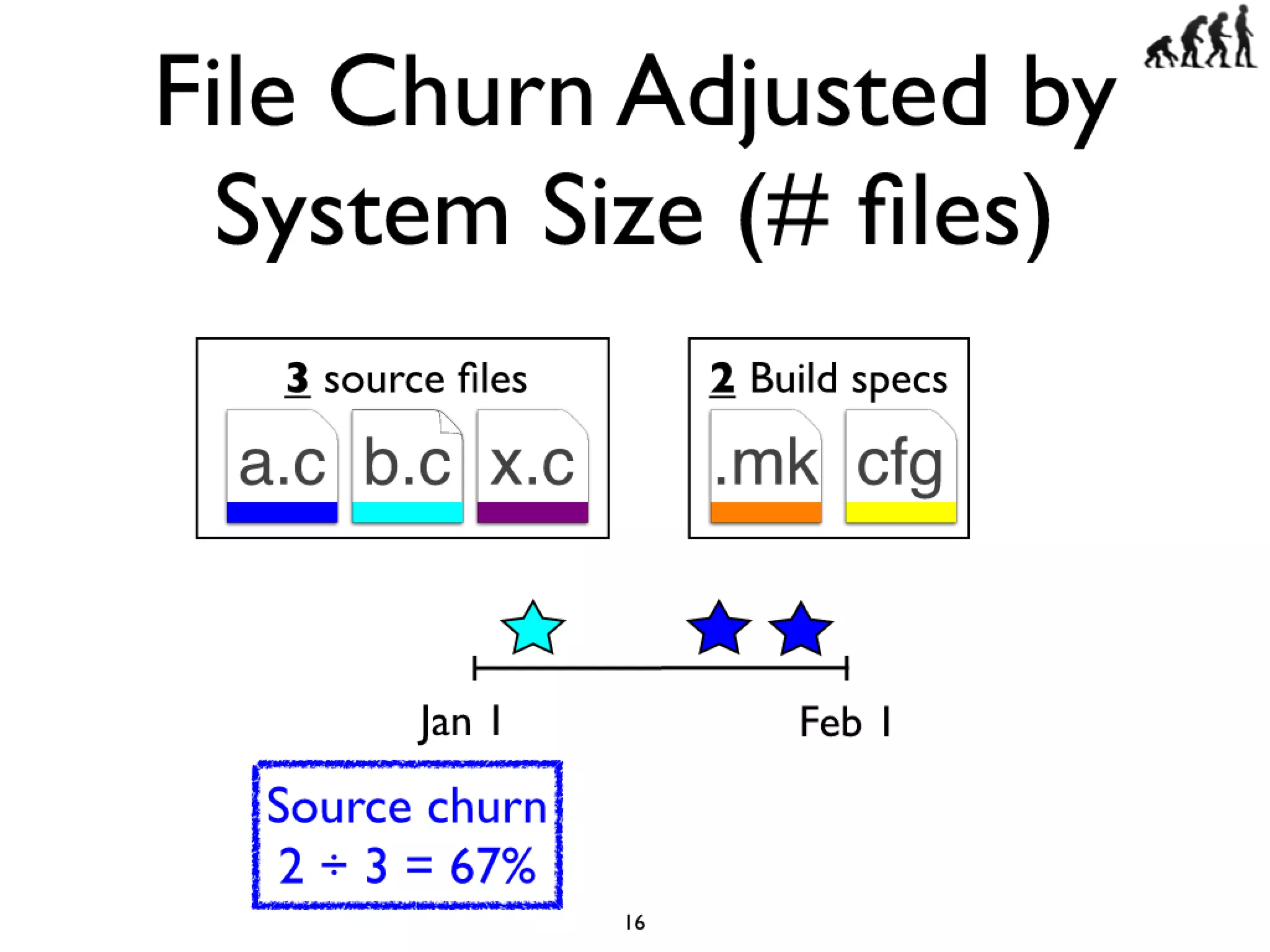
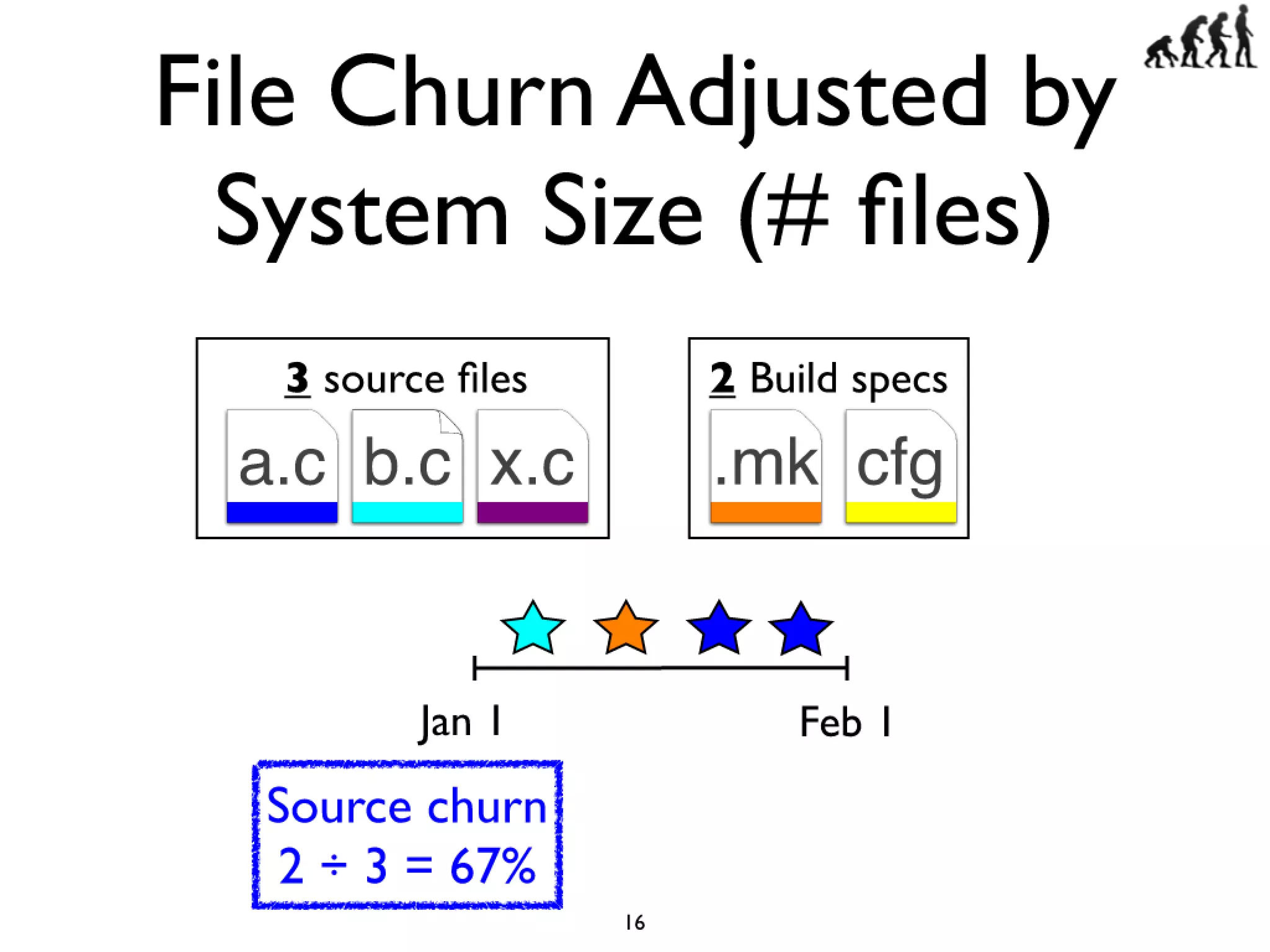
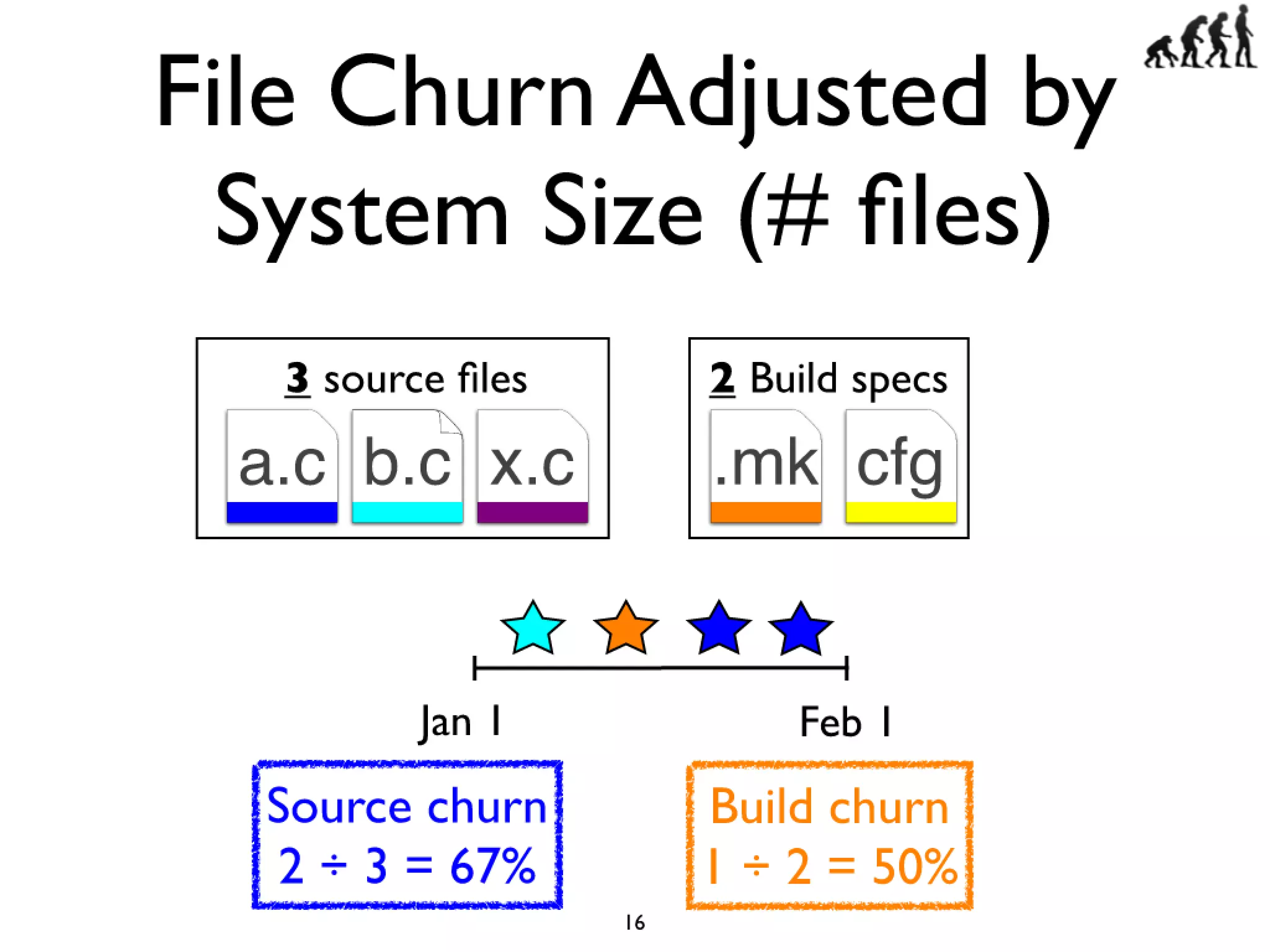
#16 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
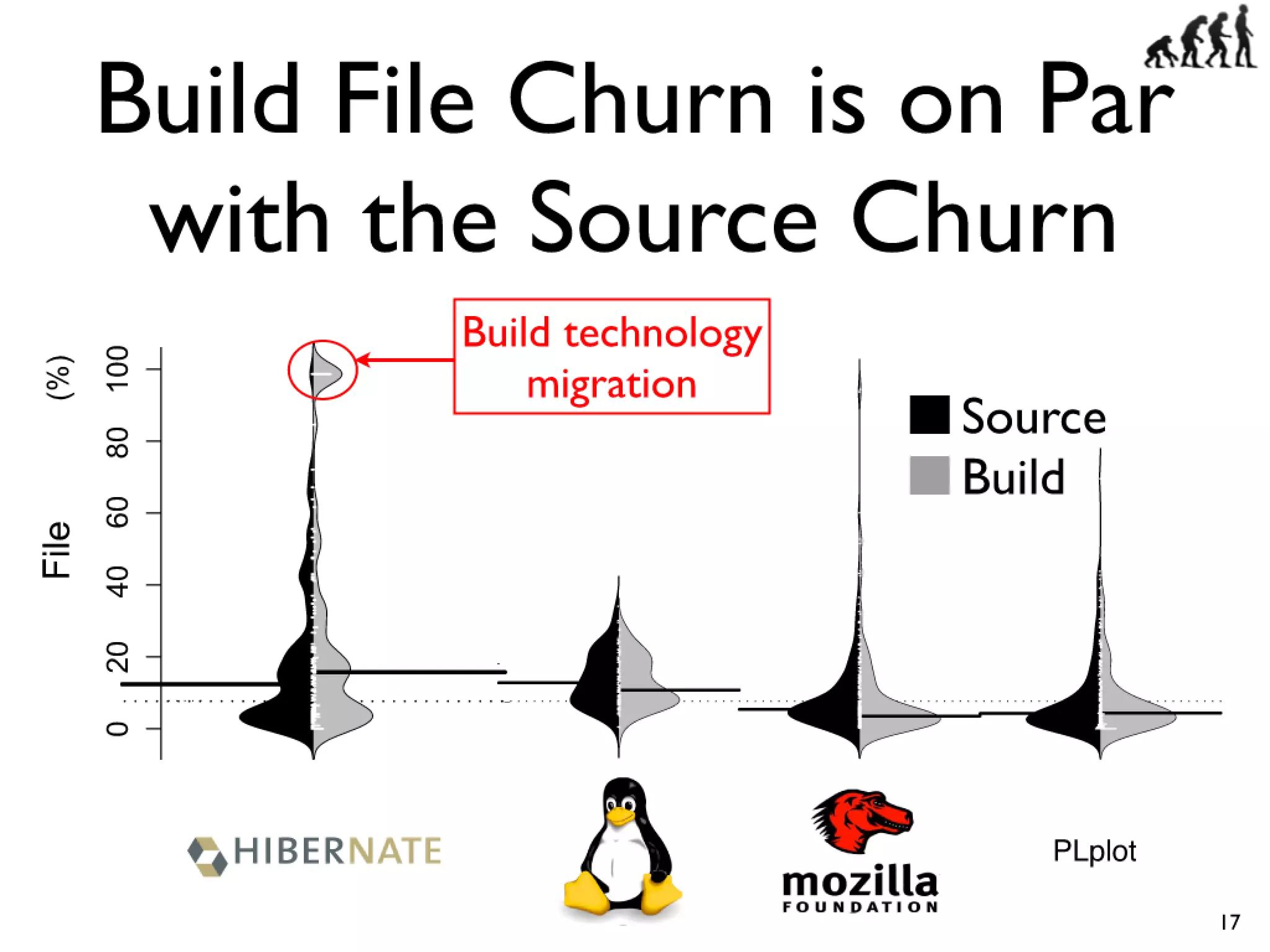
#17 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
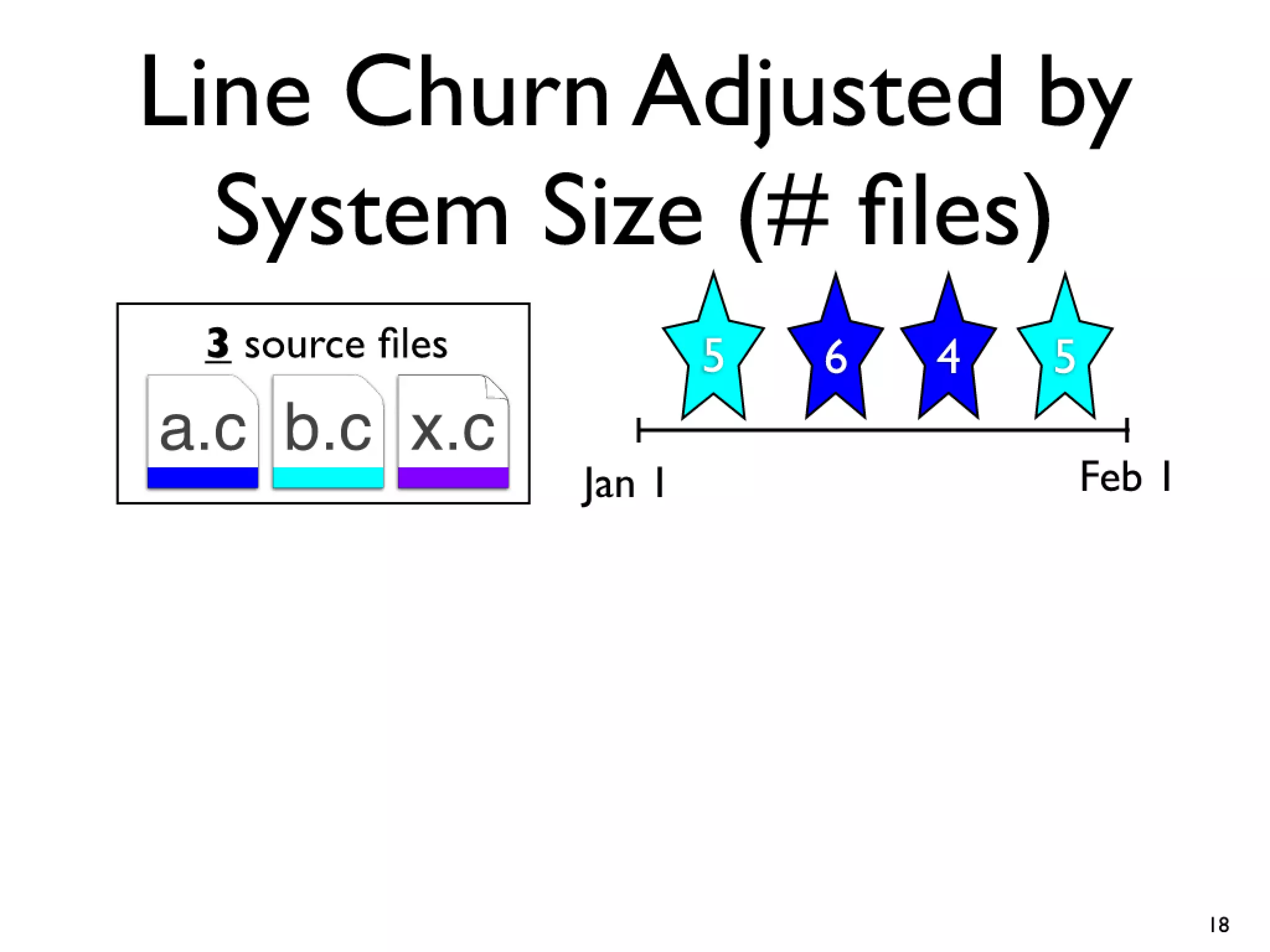
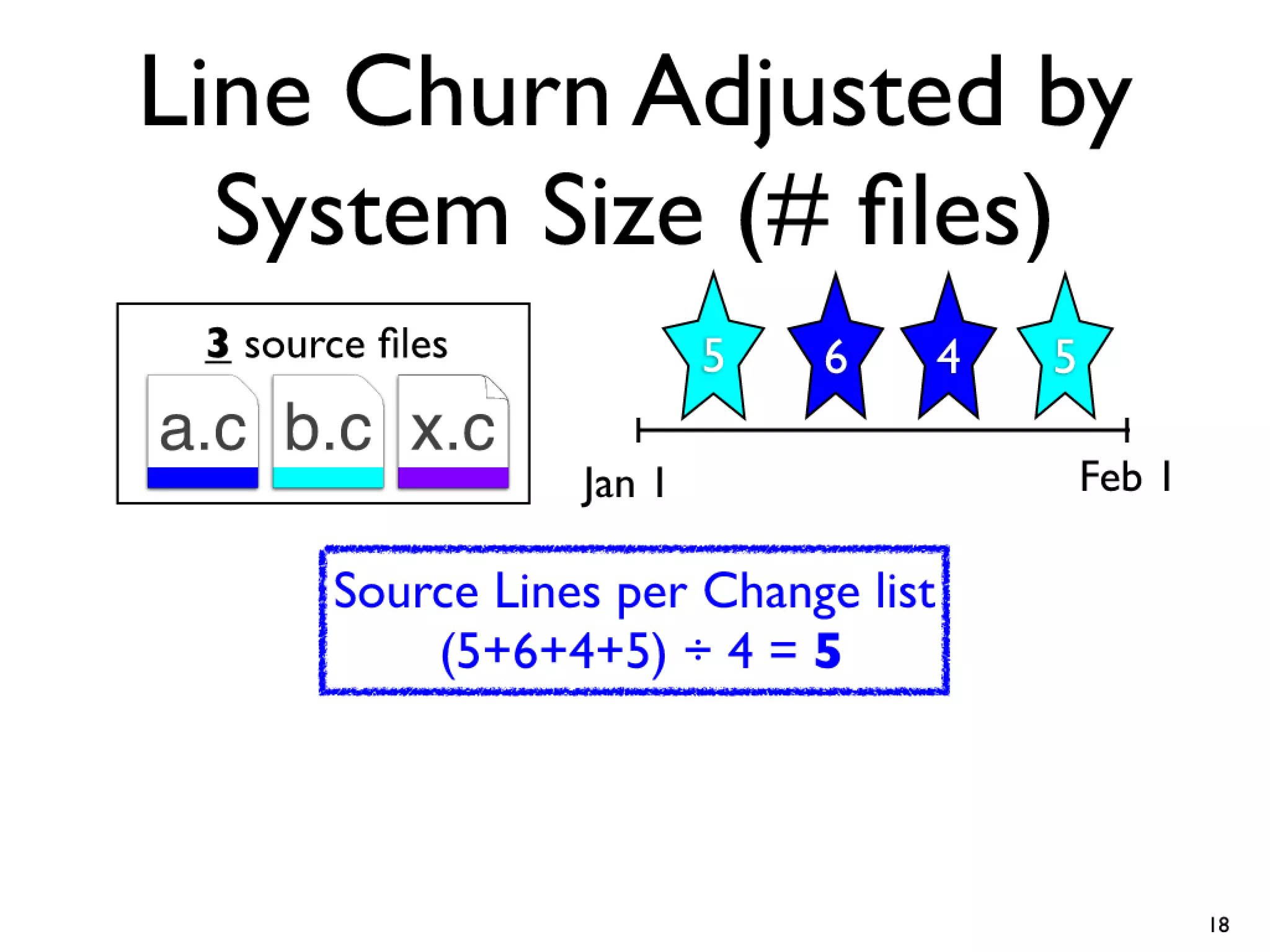
#18 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
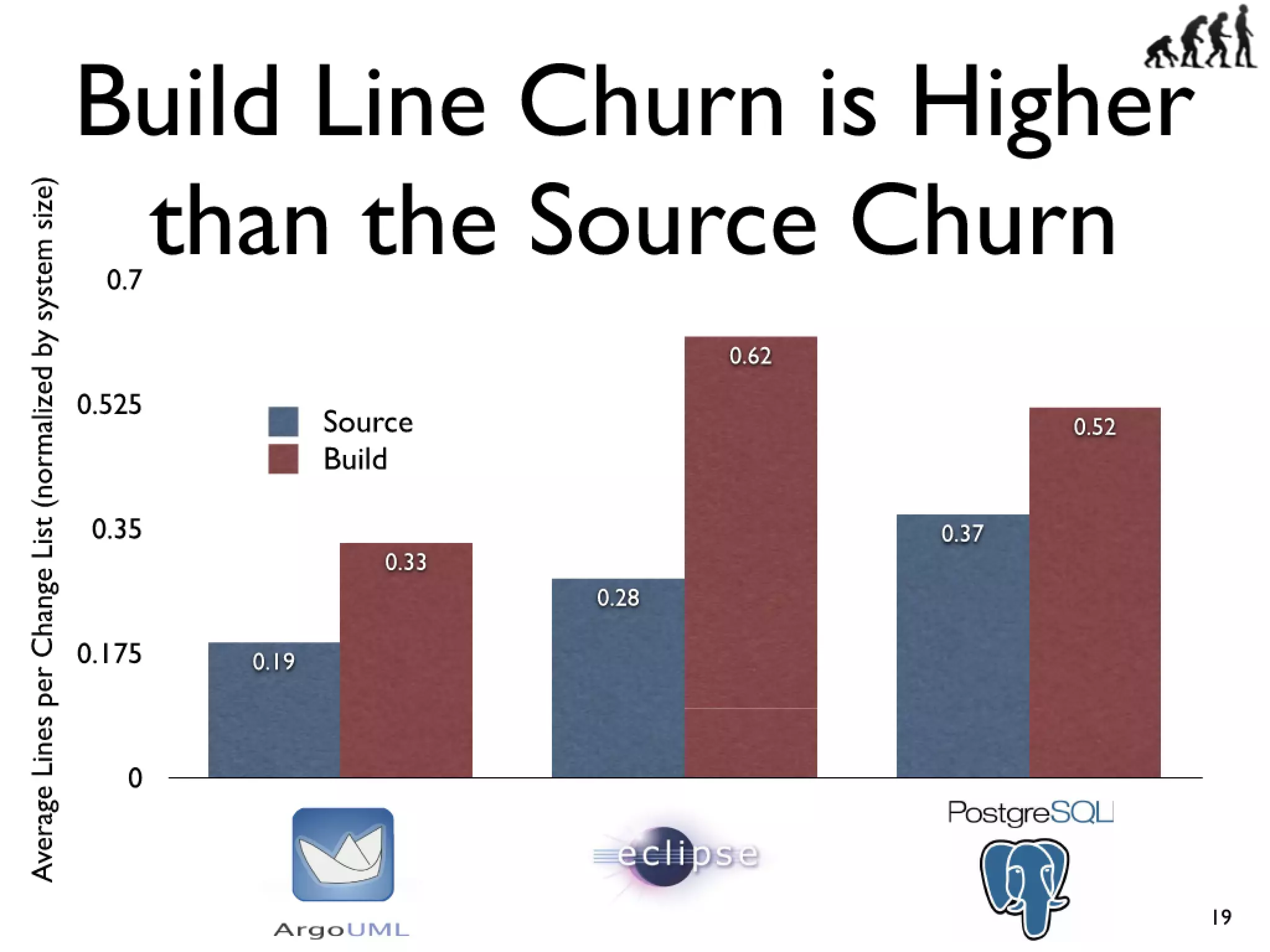
#19 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
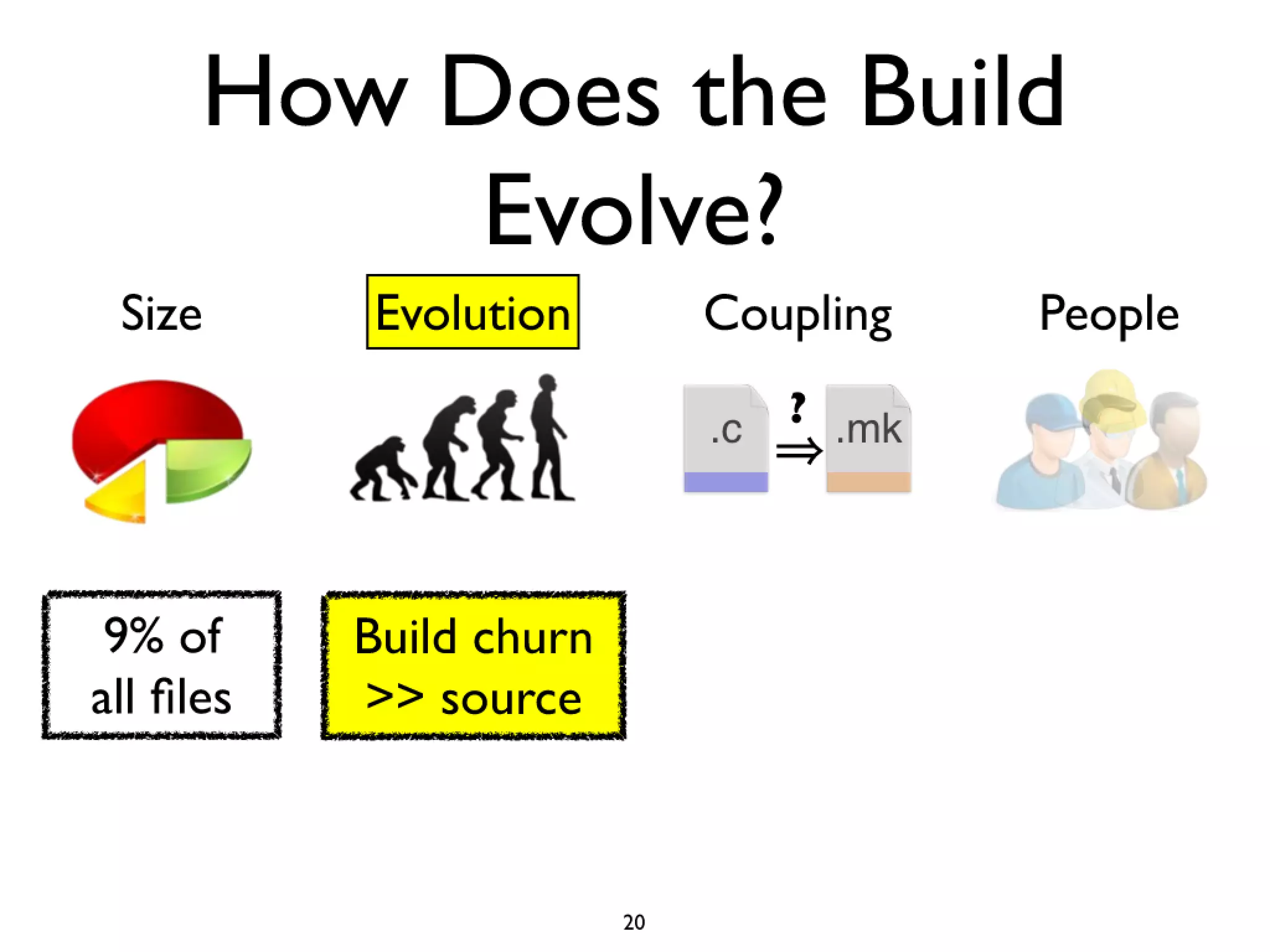
#20 Cars have features like AC and Power windows...\nSoftware has features... Linux -> CPU freq scaling, pluggable module support\nYou need tools to build a car, and you also need tools...compilers and linkers...\n
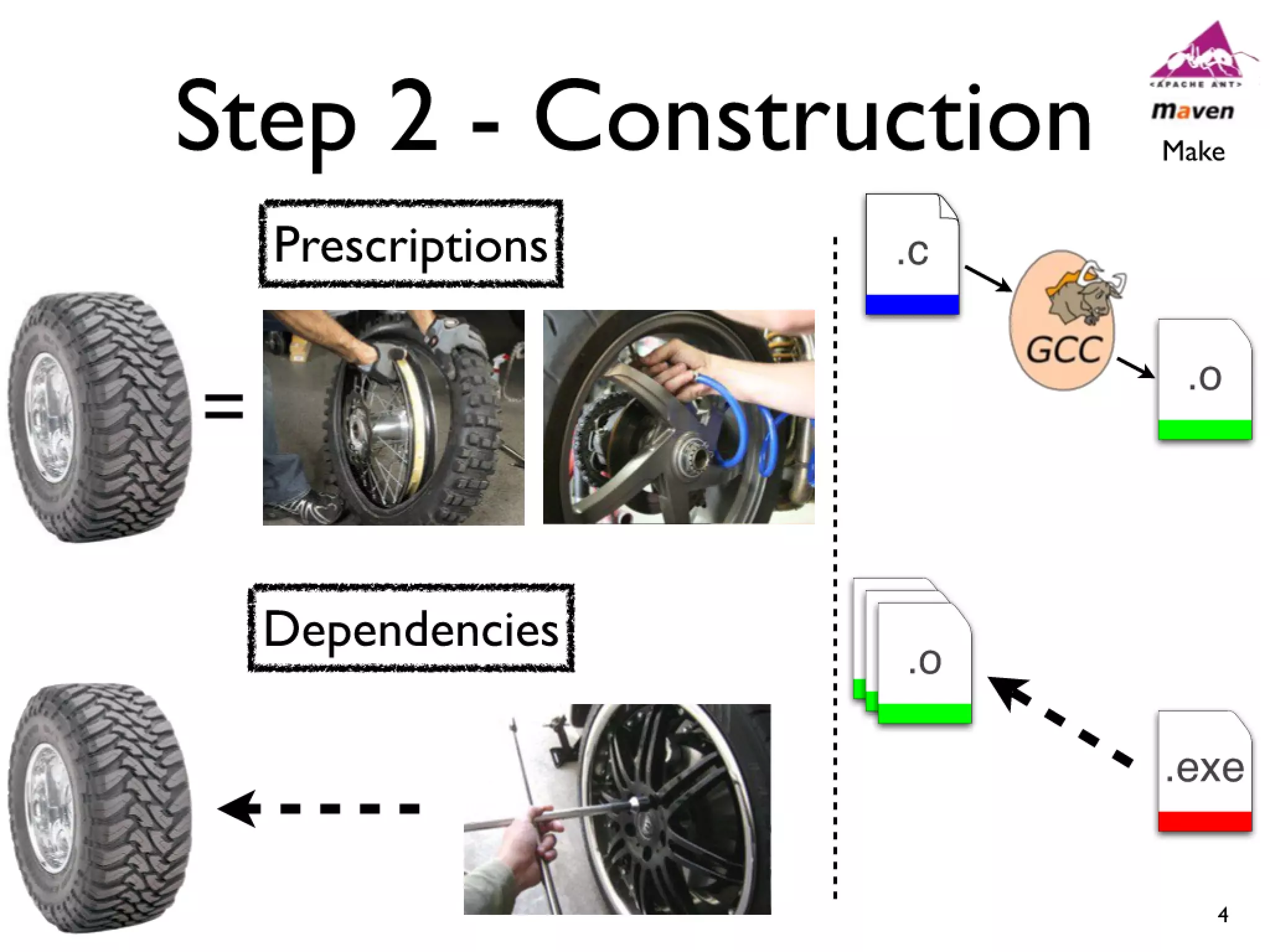
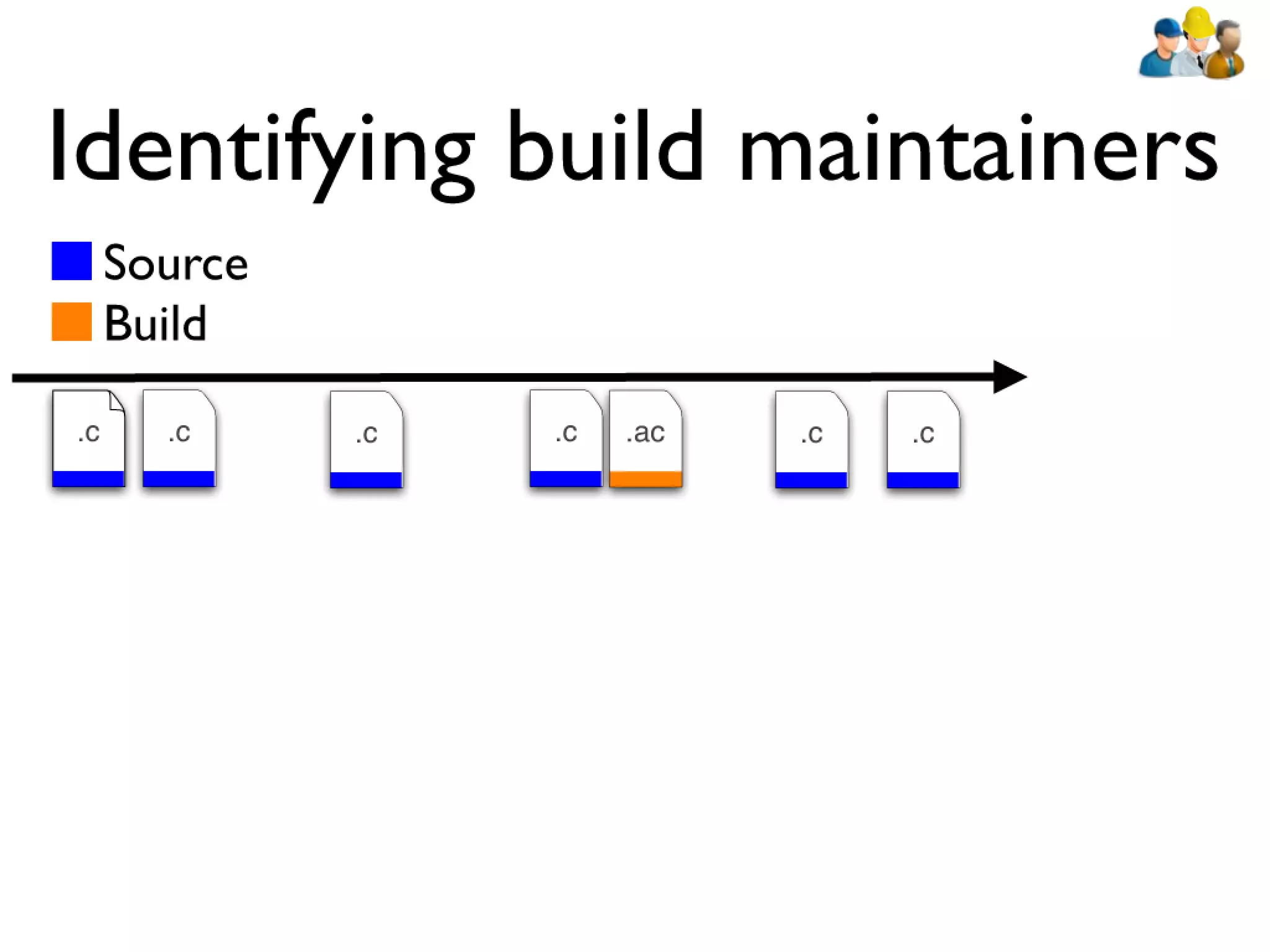
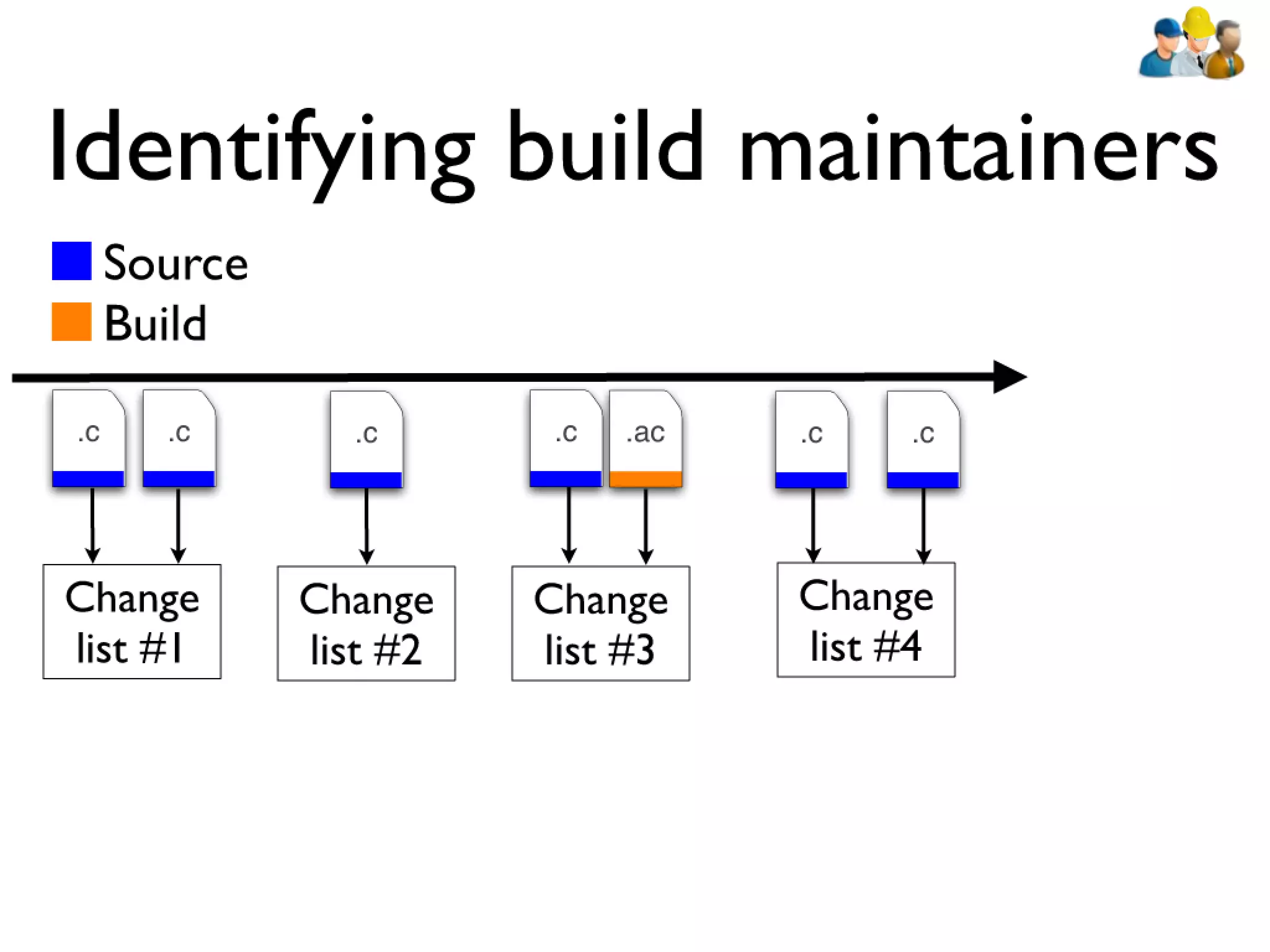
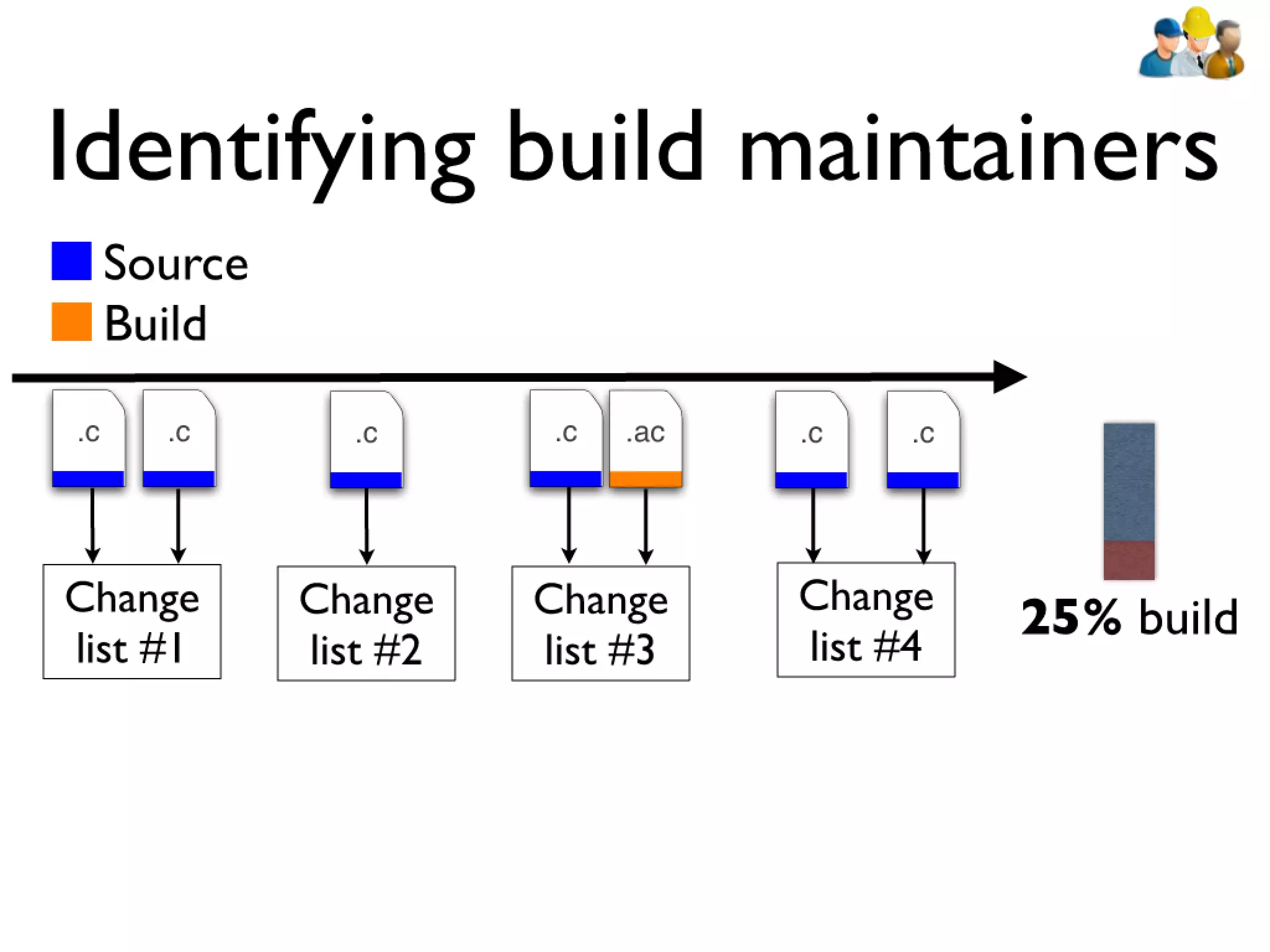
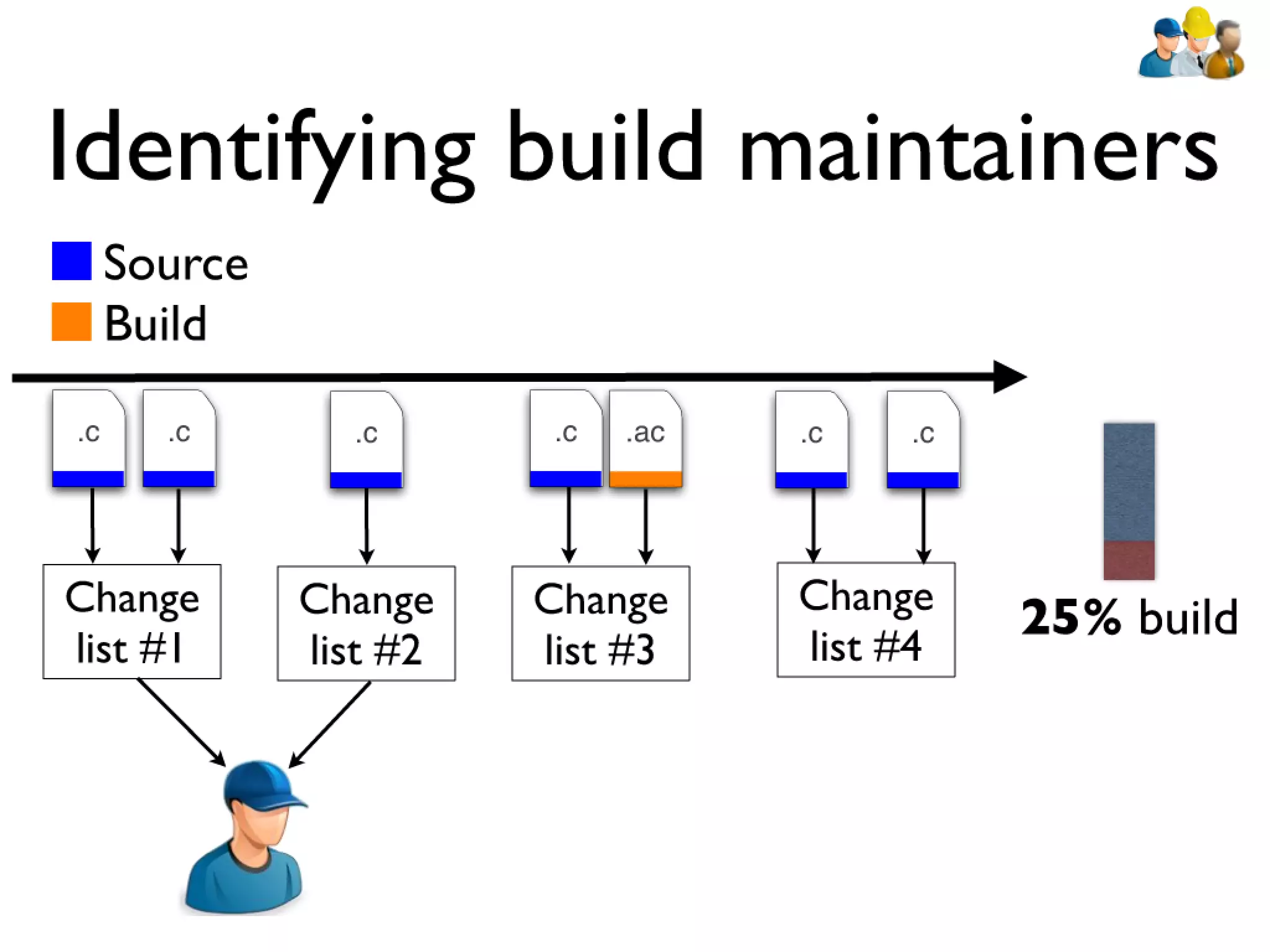
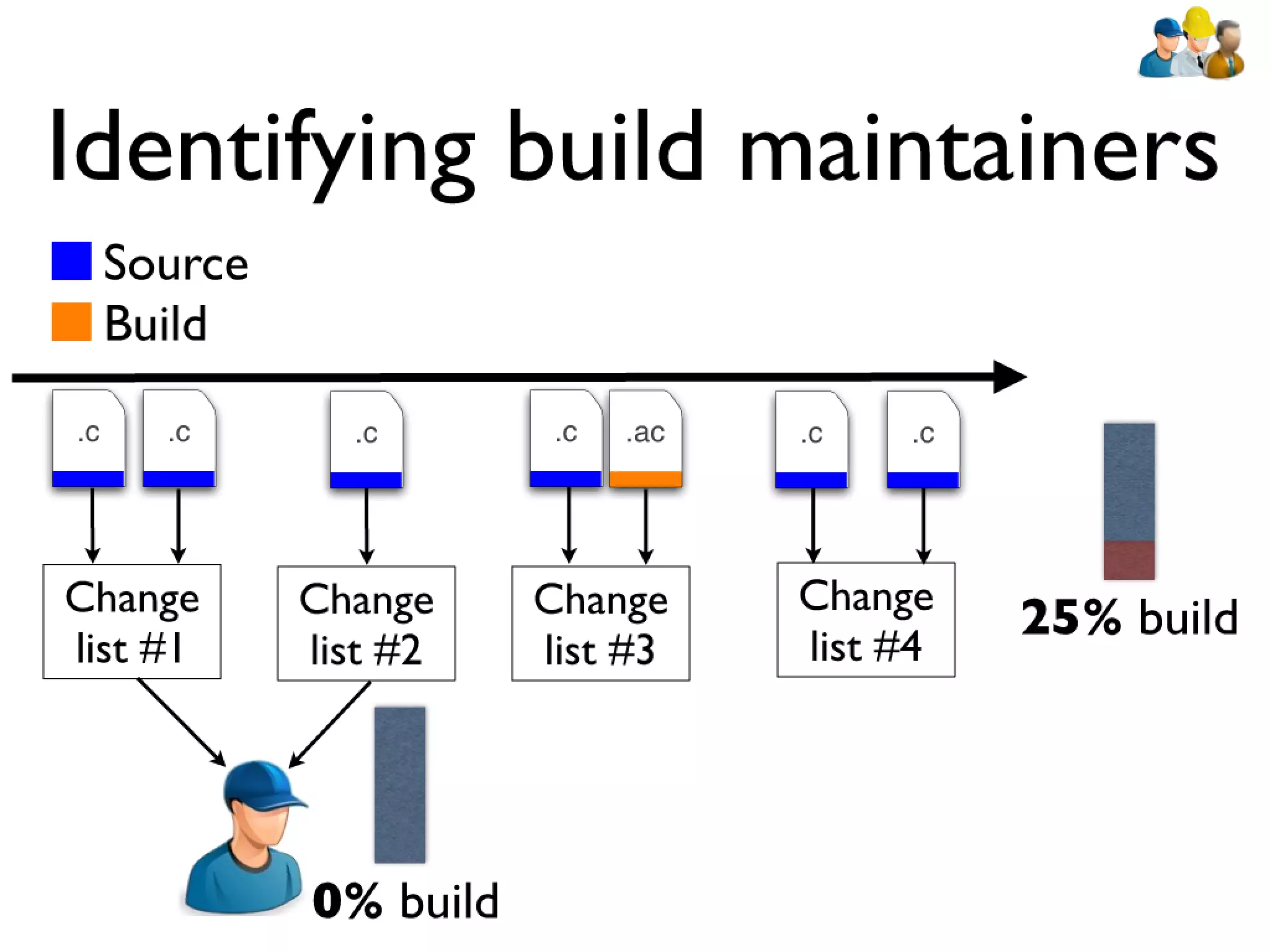
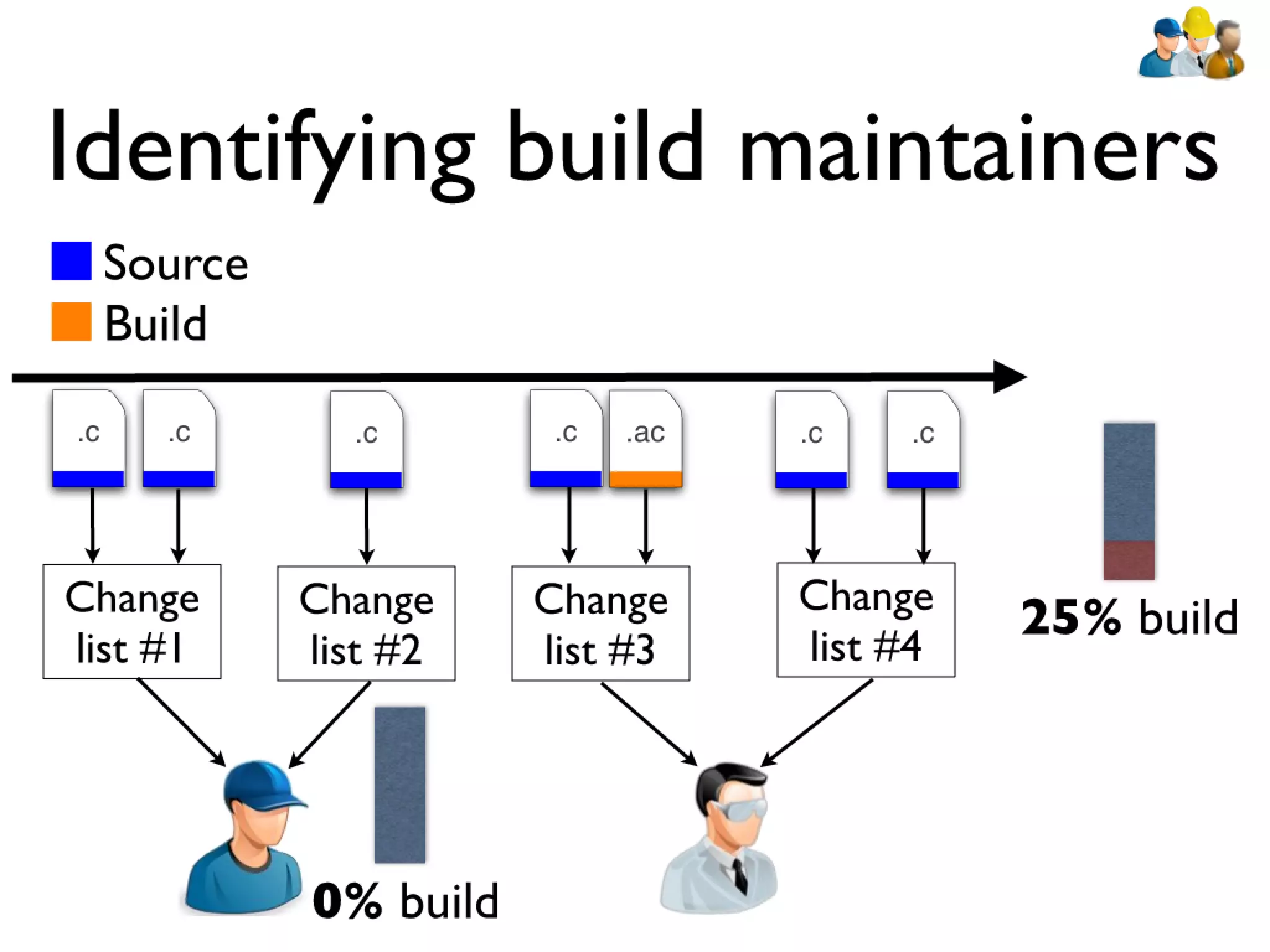
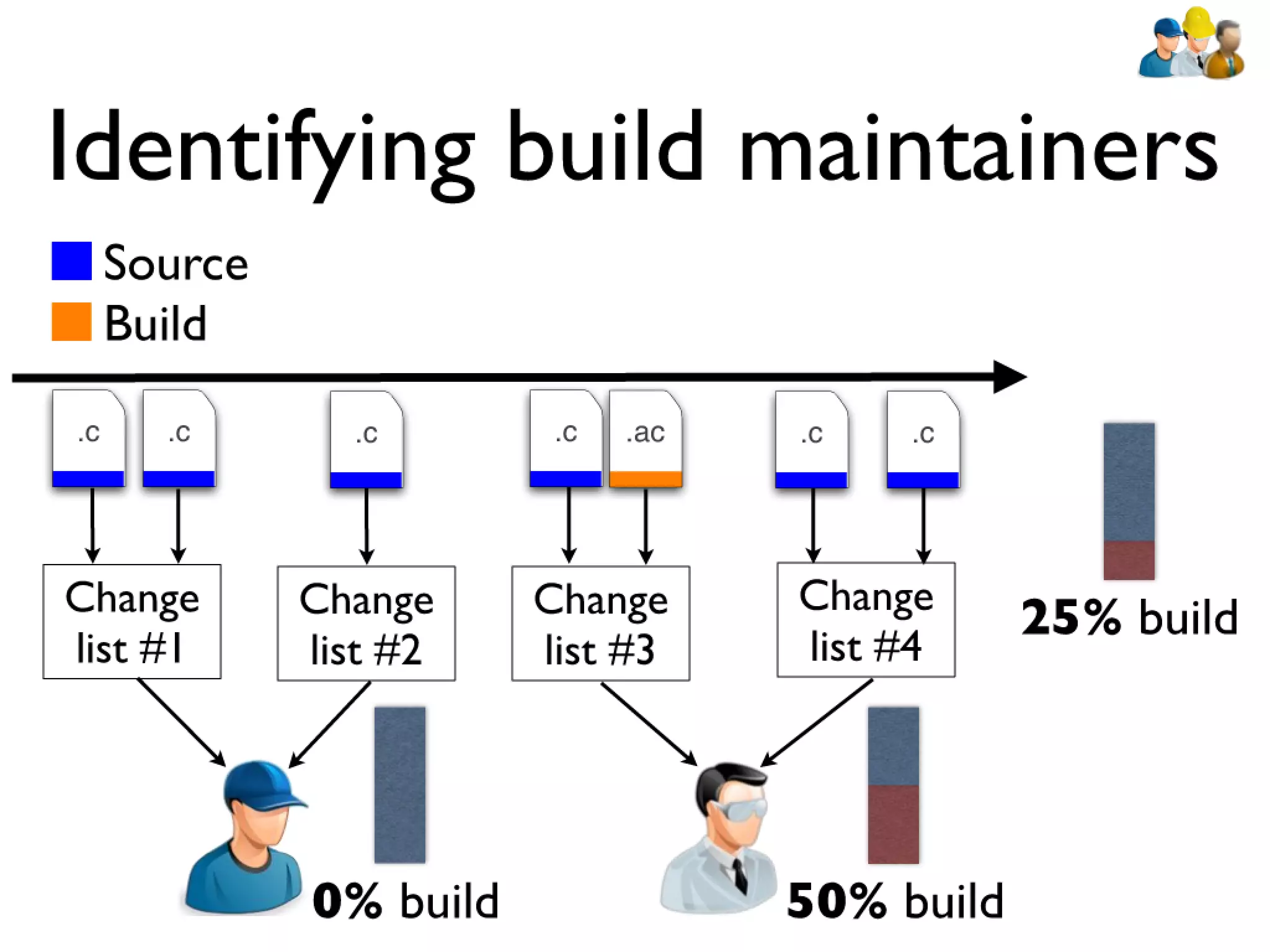
#39 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#40 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#41 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#42 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#43 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#44 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#45 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#46 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#47 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#48 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#49 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#50 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
#51 devs: constantly have to rebuilt artifacts to test changes... bld sys incrementally updates builds\n\n\n
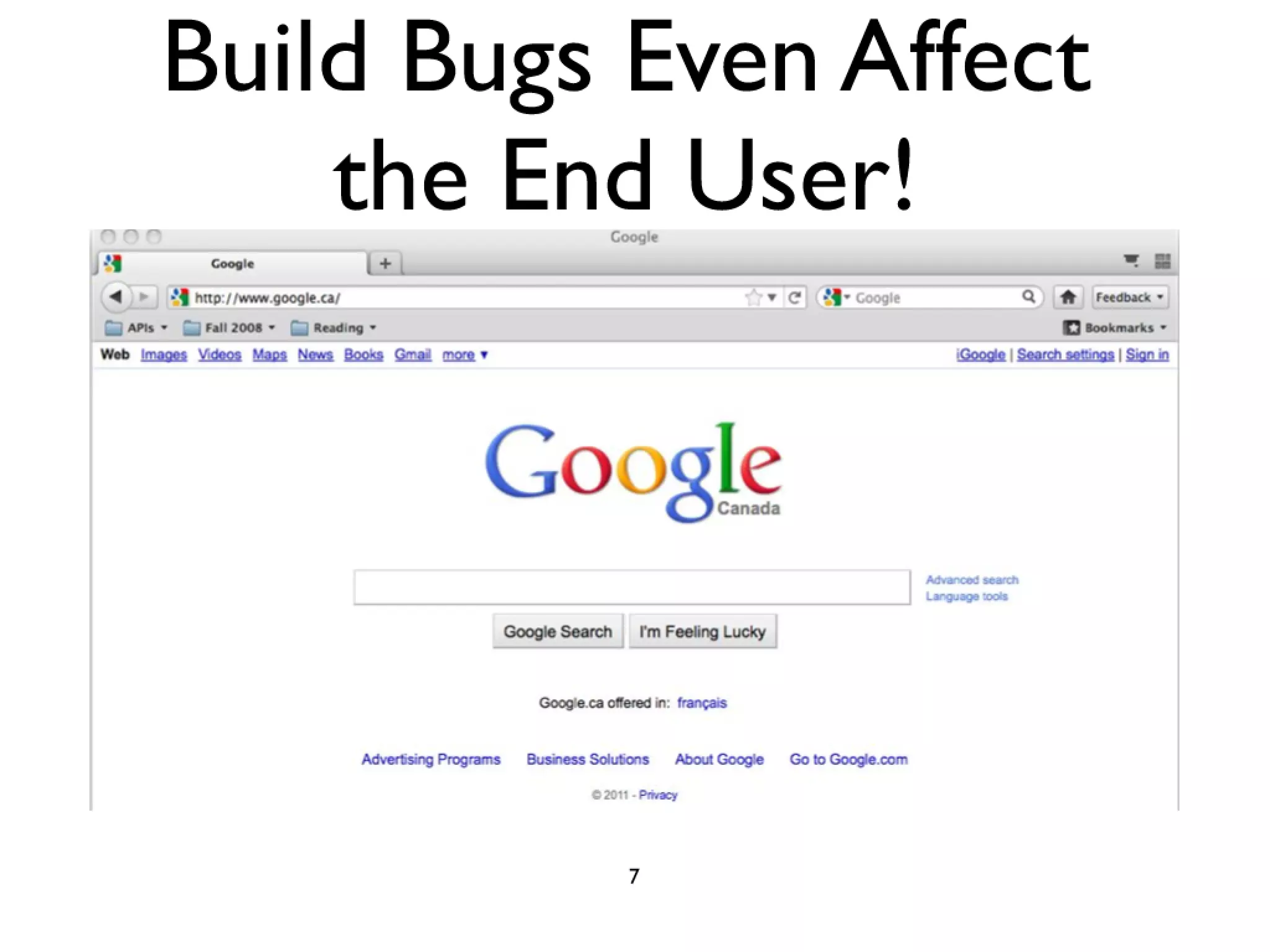
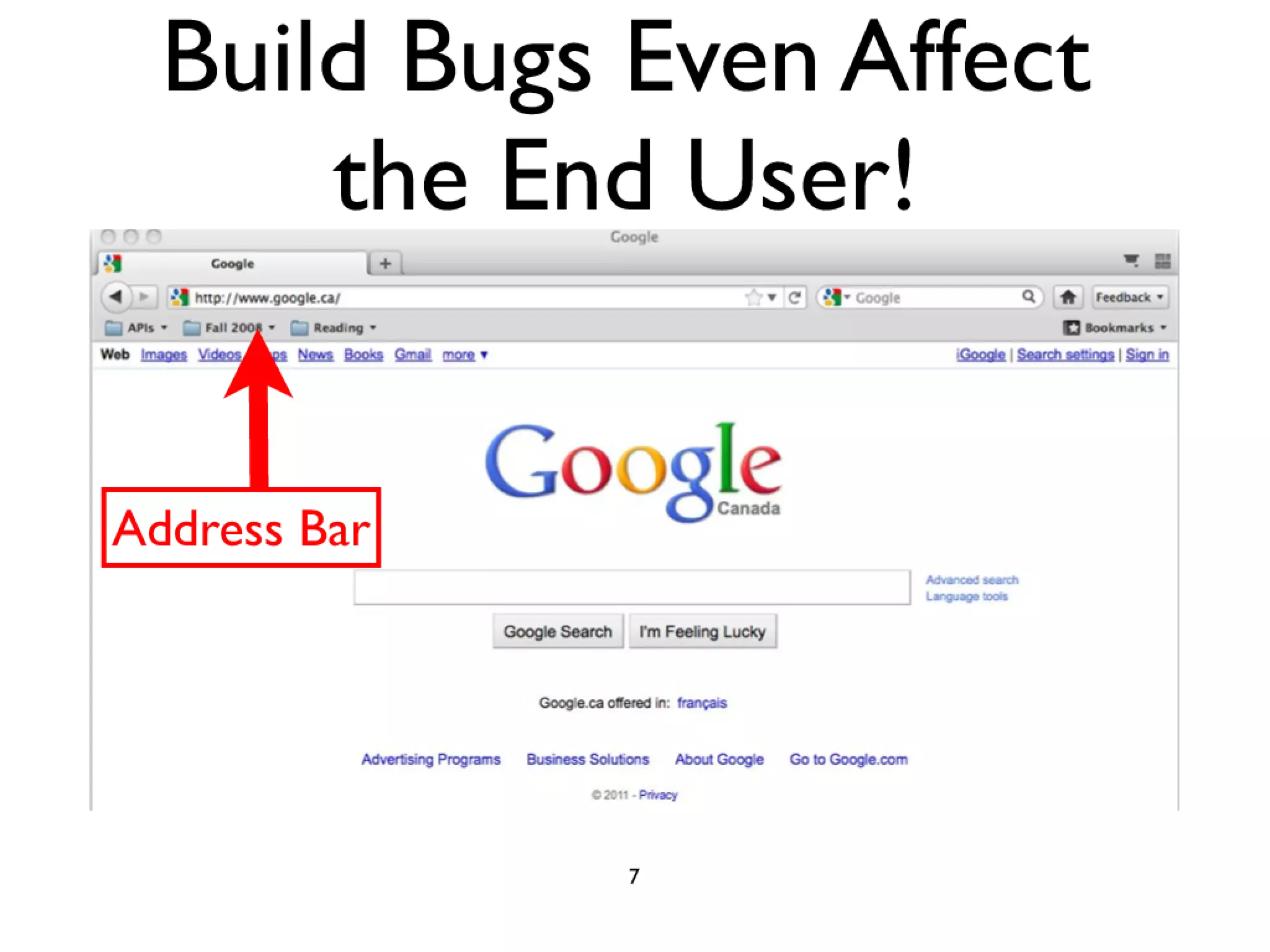
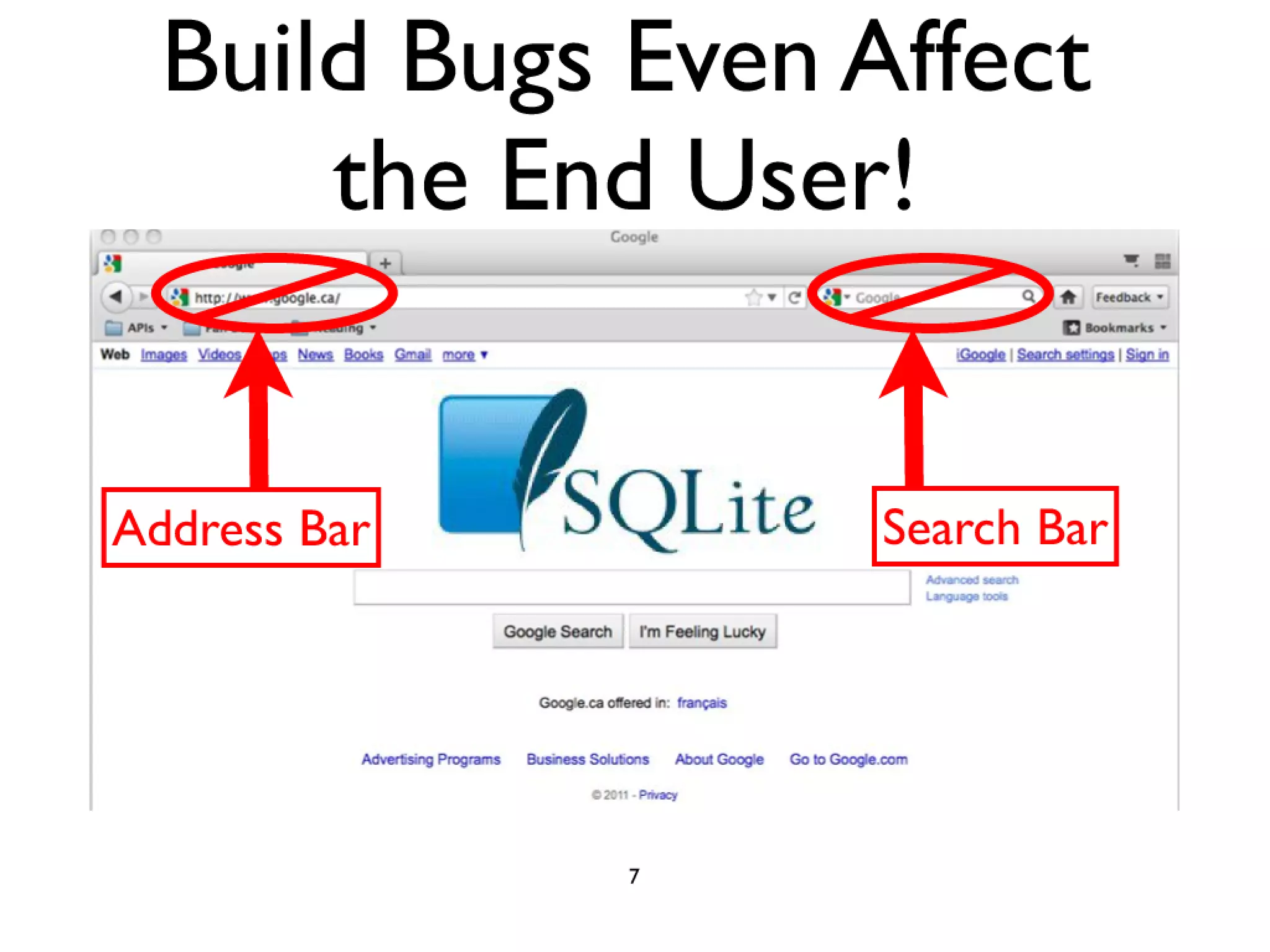
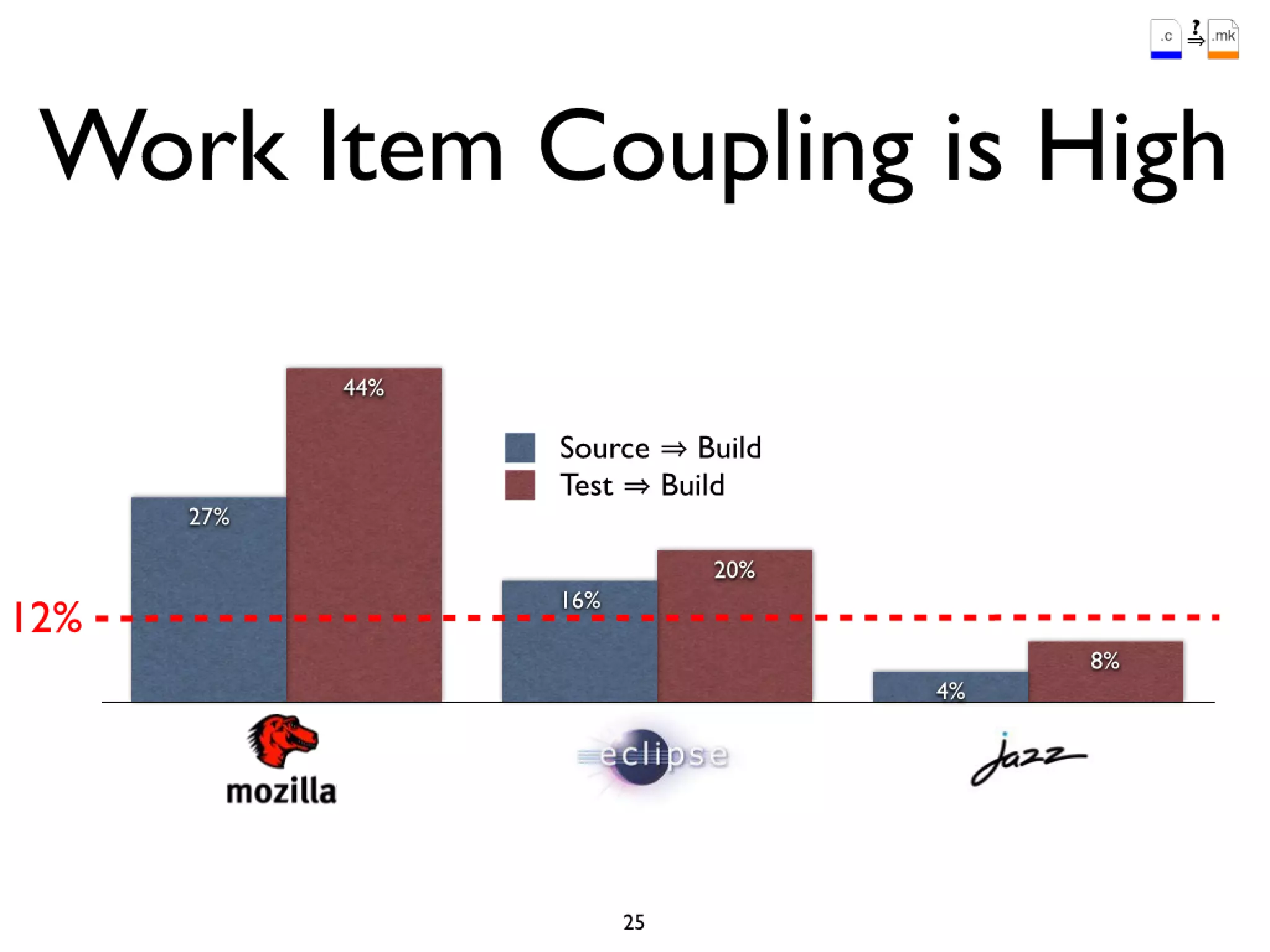
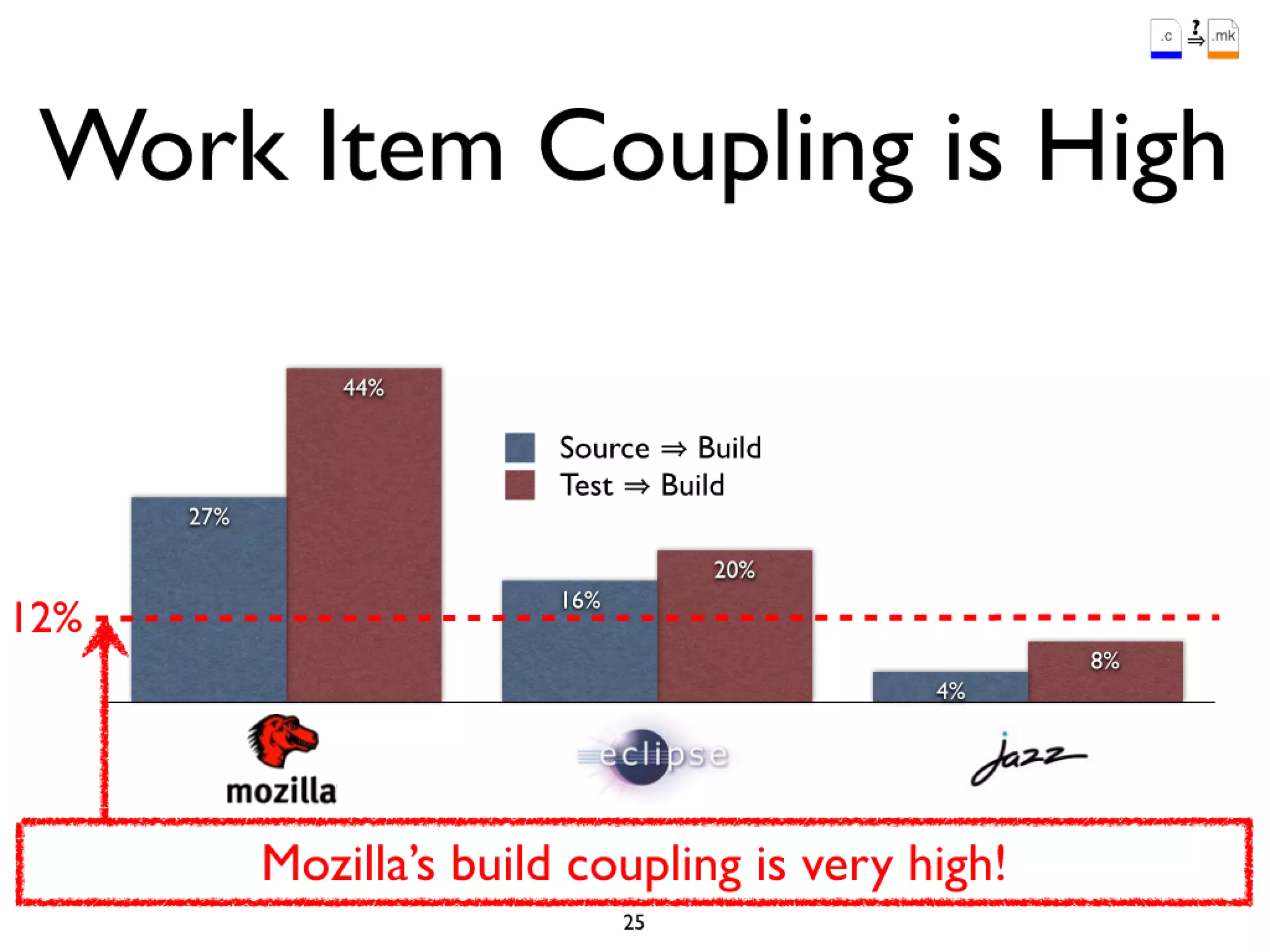
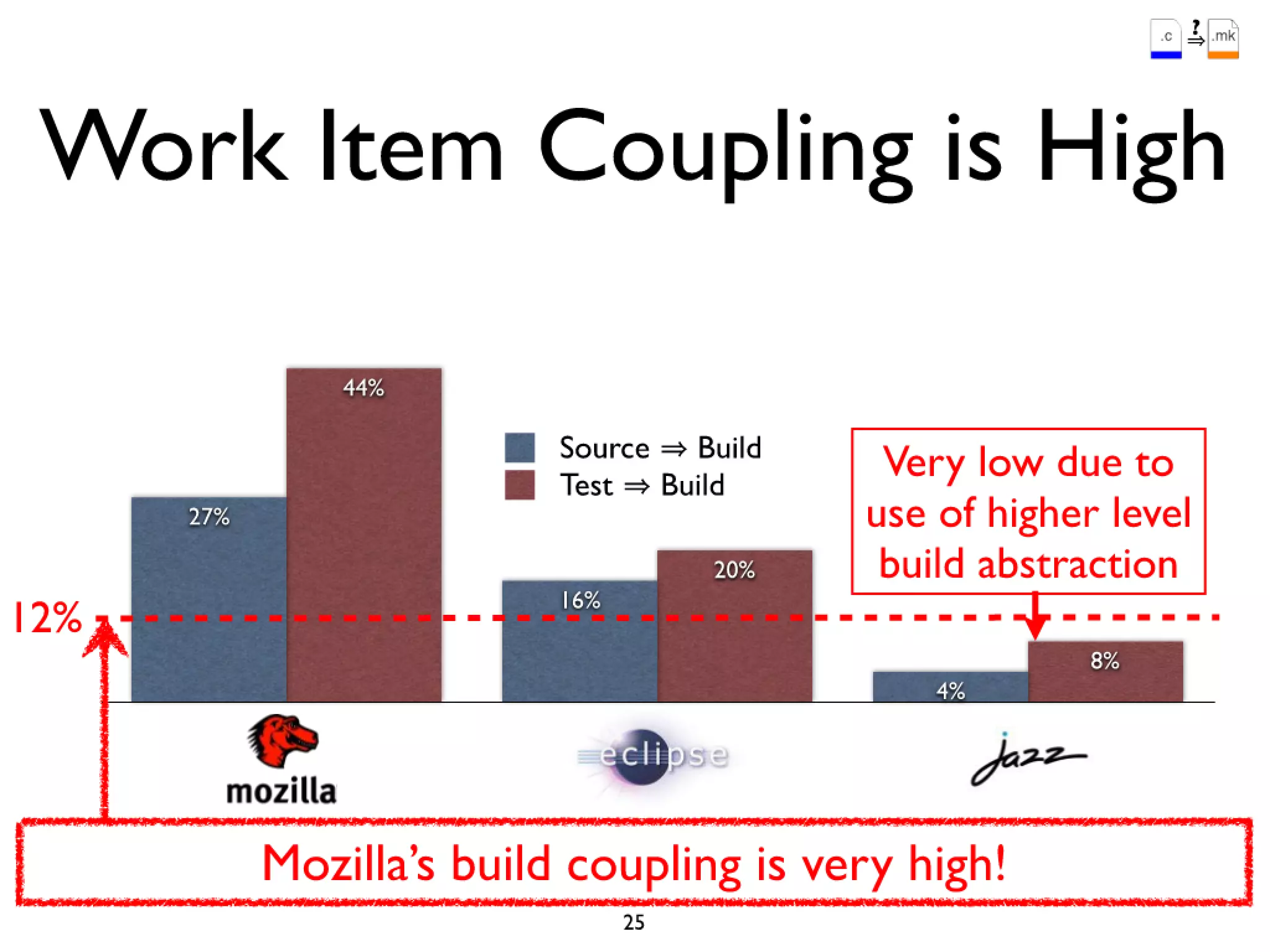
#52 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#53 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#54 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#55 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#56 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#57 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#58 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#59 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n
#60 Firefox 3.0 was built and delivered incorrectly\nusers in a networked environment address/search bar broken\ndue to an incorrect version of the SQLite library being linked in build process\nFix was delivered 4 months late in a service pack (3.0.1)\n




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













