Download as PDF, PPTX












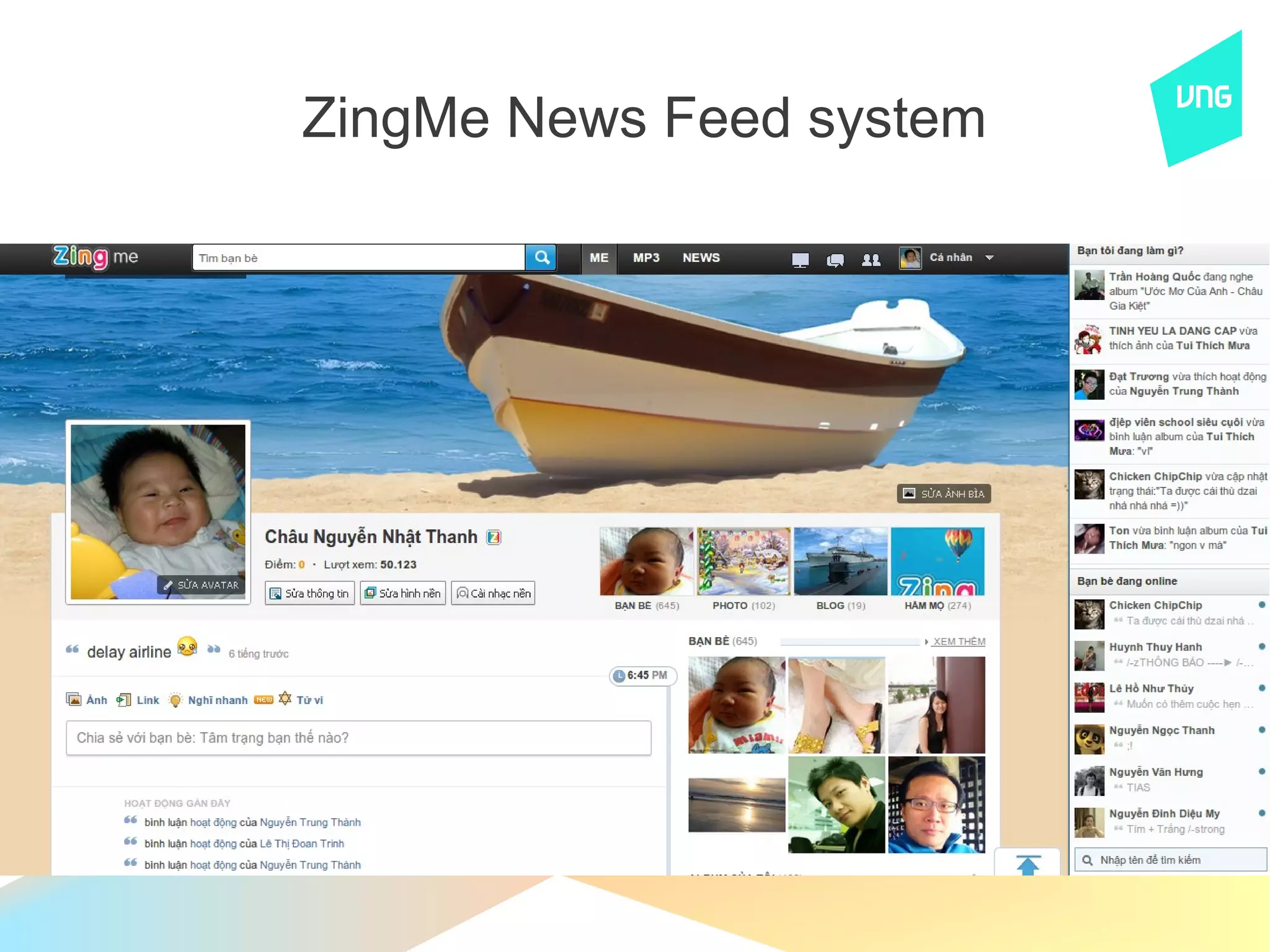

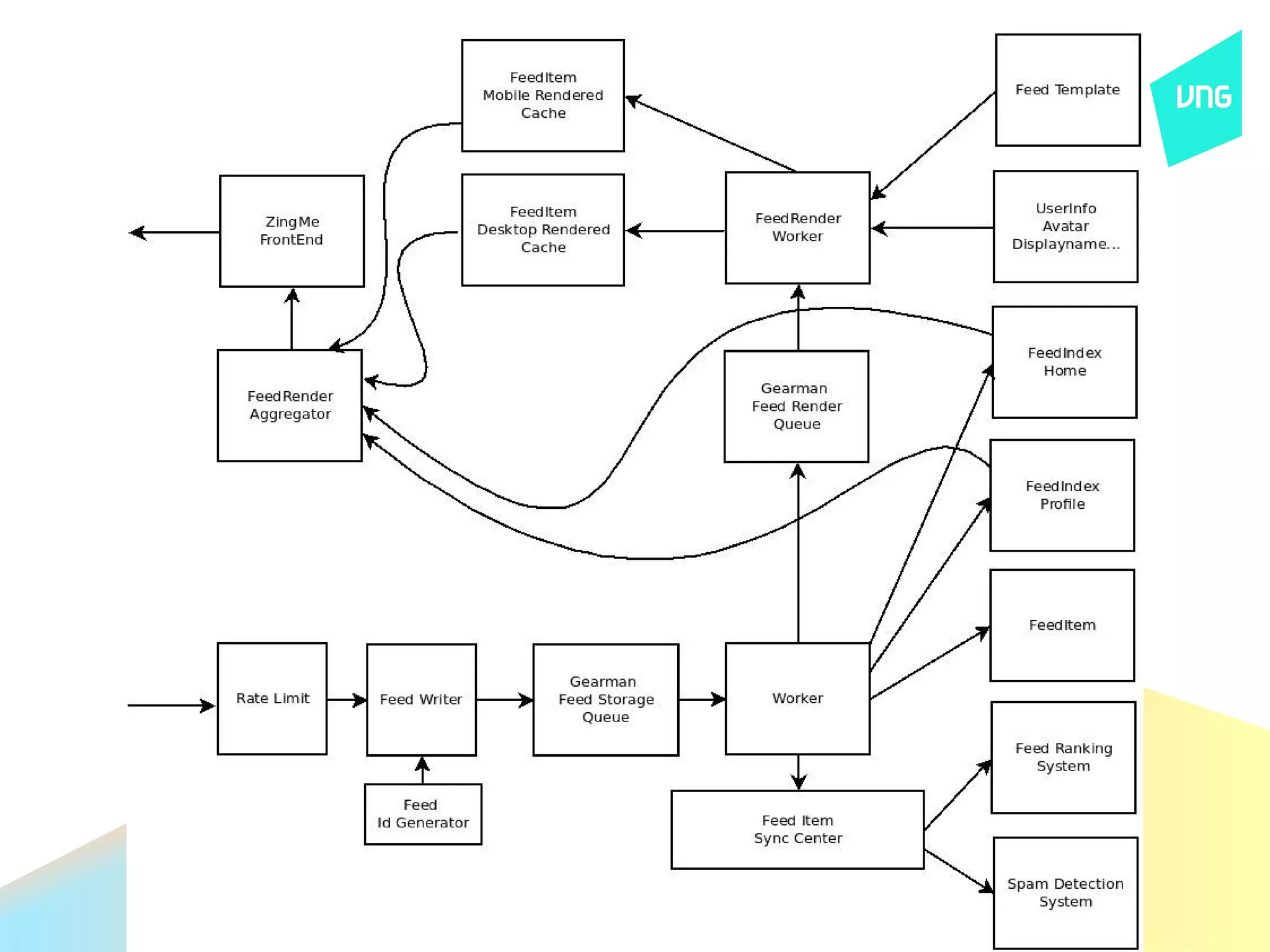
![ZingMe News Feed system
● Feed Item
● UserId, ObjectId, Created date...
● Storage: home build based on Kyoto Cabinet
● Fast recovery when crash
● Feed Index
● UserId → [feedId1,feedId2...]
● Storage: home build
● Fast recovery when crash](https://image.slidesharecdn.com/hanoiphp2012-121214202719-phpapp01/75/Building-ZingMe-News-Feed-System-19-2048.jpg)













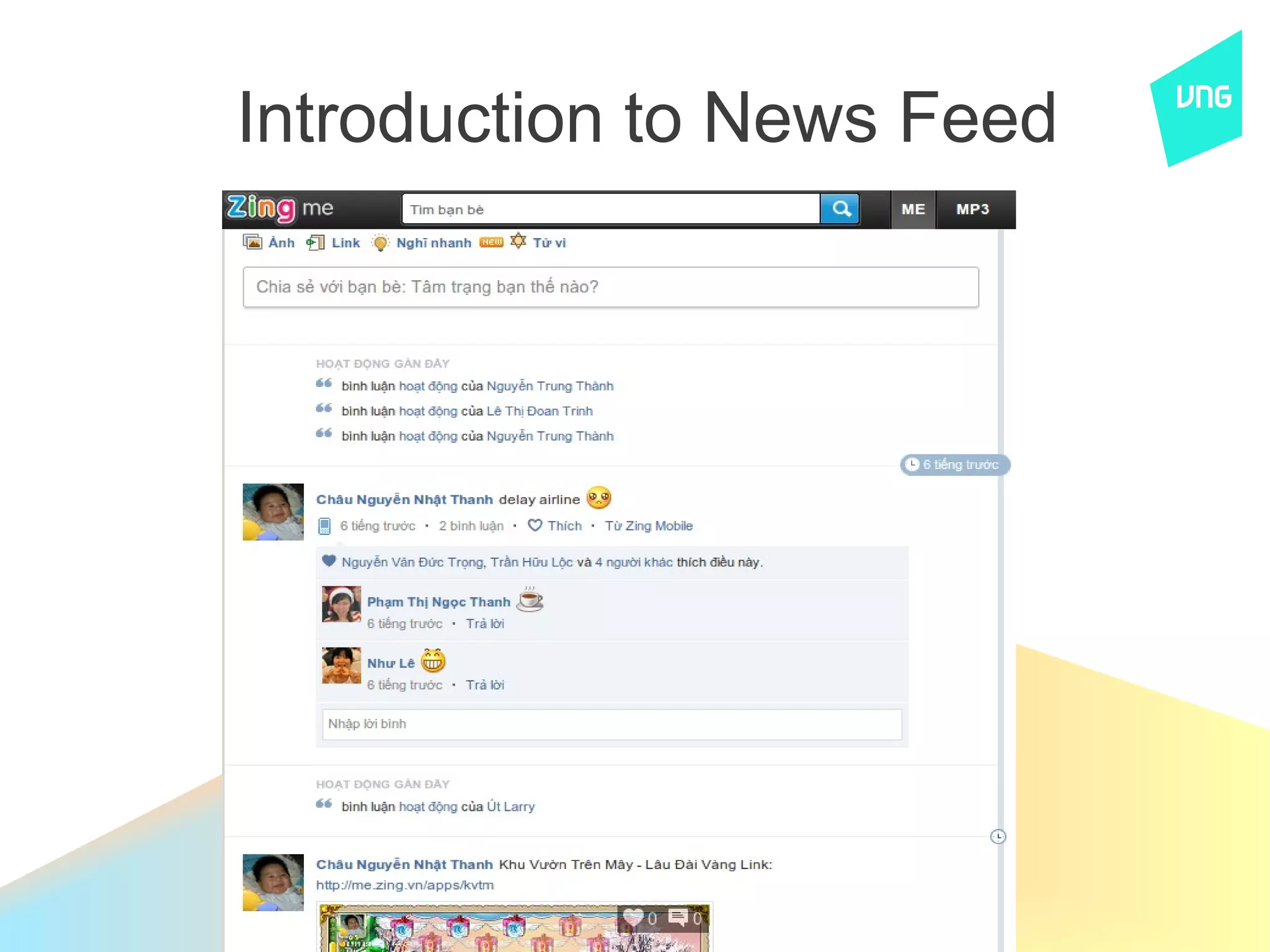
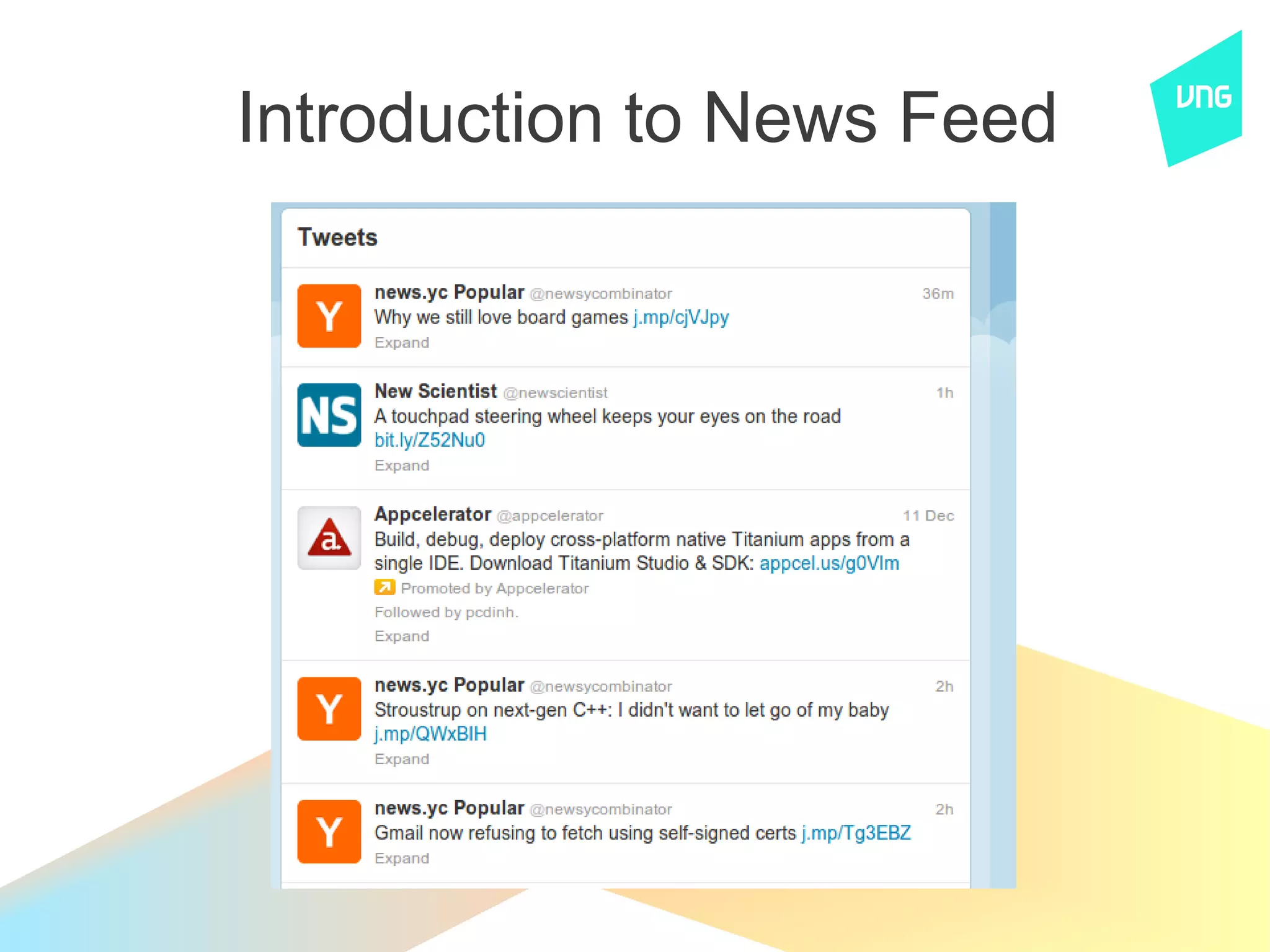
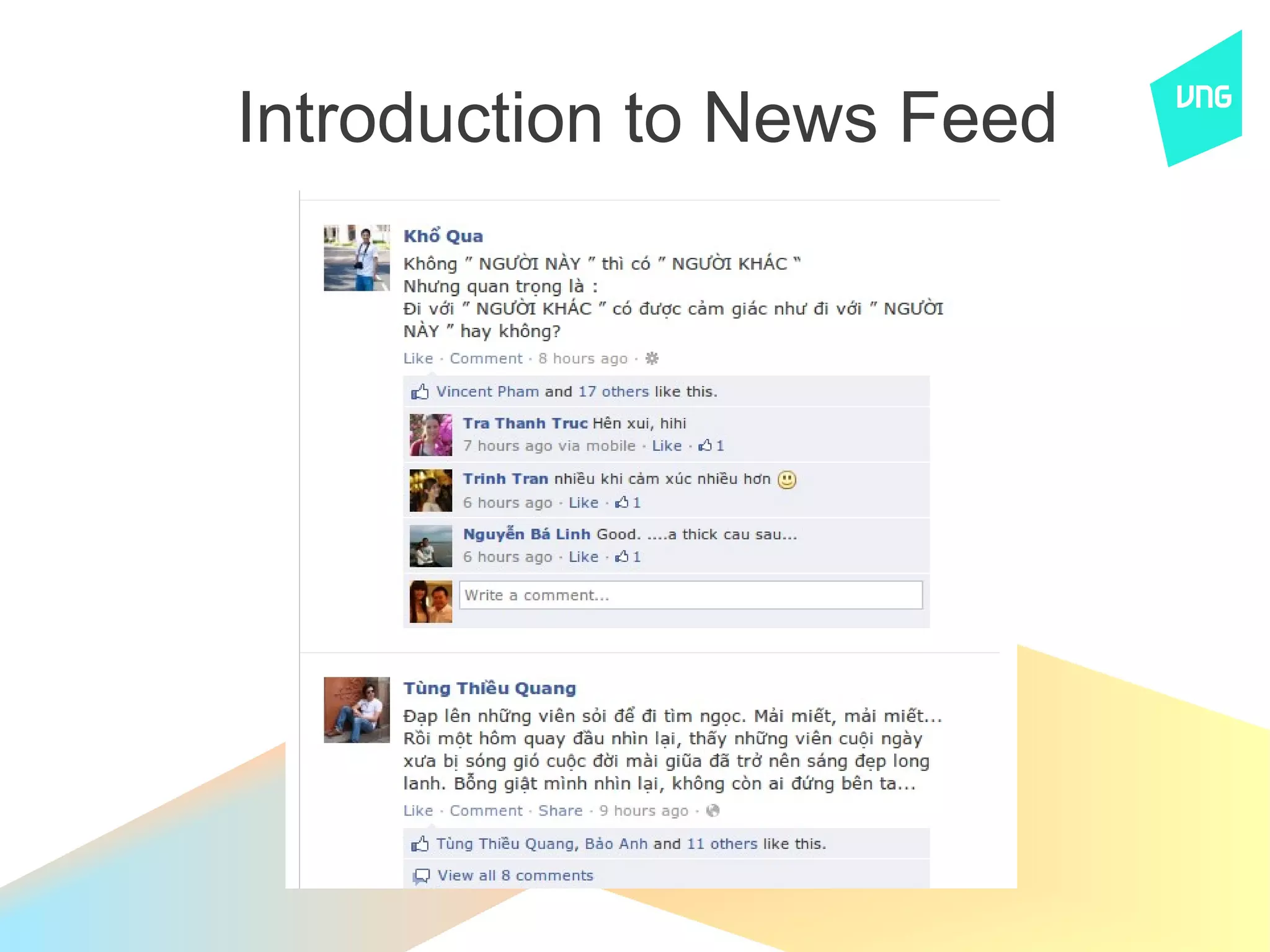
The document discusses the history and current system of ZingMe's news feed. It describes moving from a PHP/MySQL version to a Java/Cassandra version and now a home-built Kyoto Cabinet and feed index system. Key aspects of the current system include rate limiting, feed storage in a Gearman queue, rendering feeds, caching, and aggregating feeds for users. Statistics provided include 15M daily actions, 80M registered users, and 3M daily active users. The document also discusses Twemcache and Redis as alternatives to their current solutions.





























































