Download as PDF, PPTX

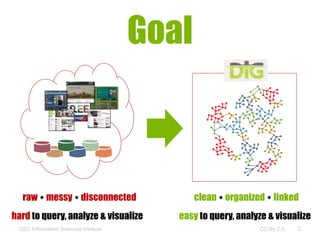





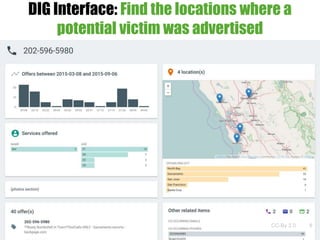





































This document discusses building knowledge graphs using DIG (Distributed Information Graphs) to integrate heterogeneous data sources. It describes the steps involved, including data acquisition, feature extraction, mapping to an ontology, entity resolution, graph construction, and deployment. As a use case, DIG has been used to build a knowledge graph from over 100 million web pages related to human trafficking to help law enforcement identify victims and prosecute traffickers.



































































