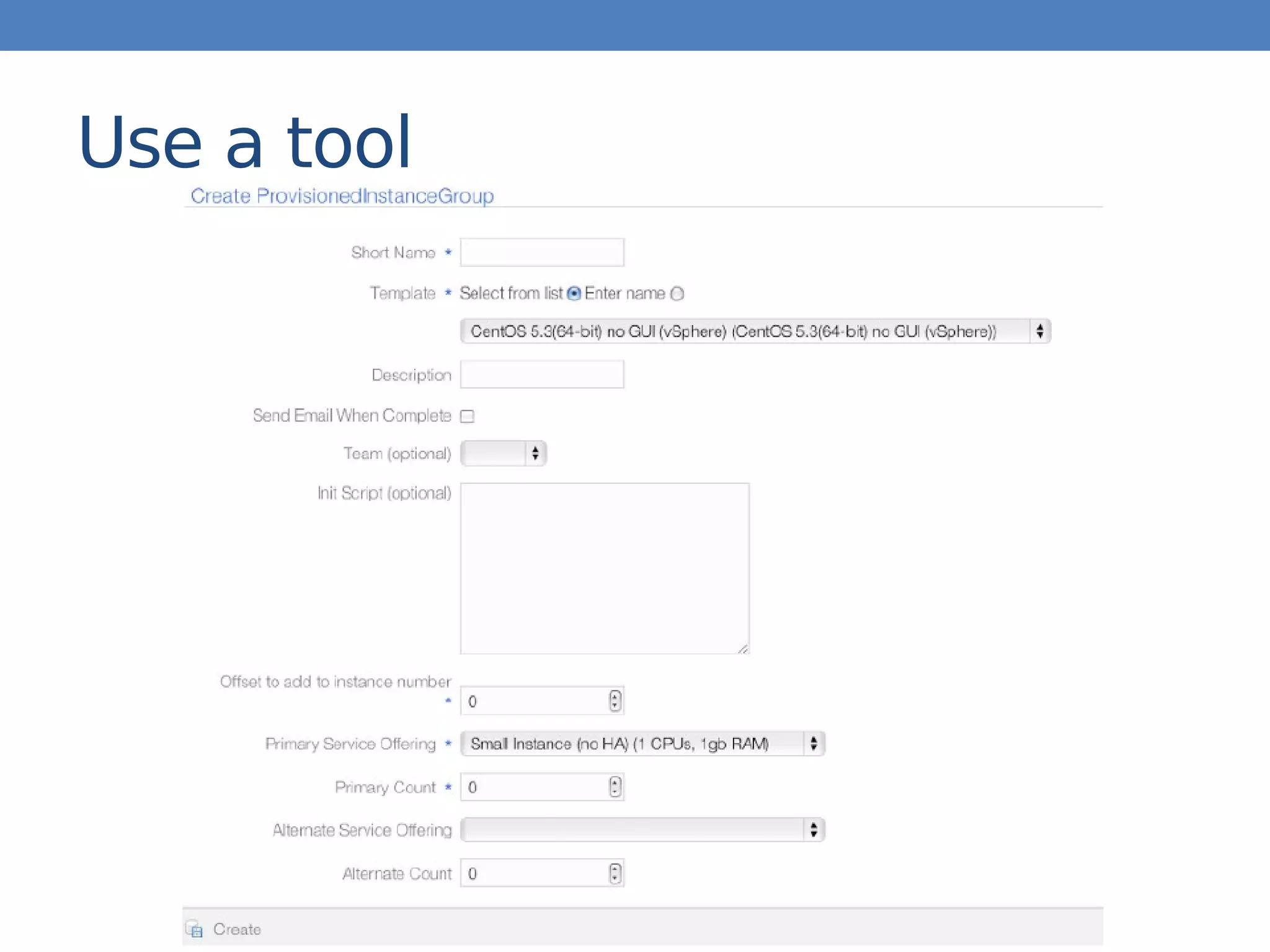
The document discusses building a development and testing cloud using Apache CloudStack, emphasizing the need for self-service and automation to empower developers and eliminate waiting times. It outlines essential features like isolated networks, resource control, and usage measurement while maintaining cost-efficiency. The author provides practical examples of configuration and resource allocation, highlighting key considerations for managing a dev/test environment.










![{
"name": "hadoop_cluster_a",
"description": "A small hadoop cluster with hbase",
"version": "1.0",
"environment": "production",
"servers": [
{
"name": "zookeeper-a, zookeeper-b, zookeeper-c",
"description": "Zookeeper nodes",
"template": "rhel-5.6-base",
"service": "small",
"port_rules": "2181",
"run_list": "role[cluster_a], role[zookeeper_server]",
"actions": [
{ "knife_ssh": ["role:zookeeper_server", "sudo chef-client"] }
]
},
{
"name": "hadoop-master",
"description": "Hadoop master node",
"template": "rhel-5.6-base",
"service": "large",
"networks": "app-net, storage-net",
"port_rules": "50070, 50030, 60010",
"run_list": "role[cluster_a], role[hadoop_master], role[hbase_master]"
},
{
"name": "hadoop-worker-a hadoop-worker-b hadoop-worker-c",
"description": "Hadoop worker nodes",
"template": "rhel-5.6-base",
"service": "medium",
"port_rules": "50075, 50060, 60030",
"run_list": "role[cluster_a], role[hadoop_worker], role[hbase_regionserver]",
"actions": [
{ "knife_ssh": ["role:hadoop_master", "sudo chef-client"] },
{ "http_request": "http://${hadoop-master}:50070/index.jsp" }
]
}
}](https://image.slidesharecdn.com/devtest3-130607131447-phpapp01/75/Building-a-Dev-Test-Cloud-with-Apache-CloudStack-12-2048.jpg)