Download to read offline




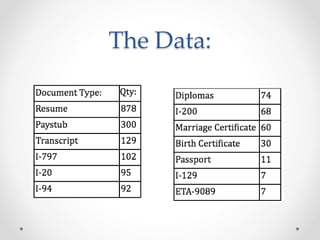


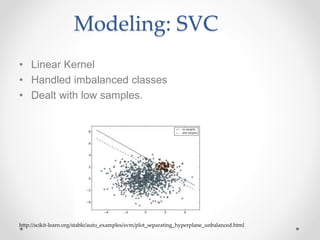

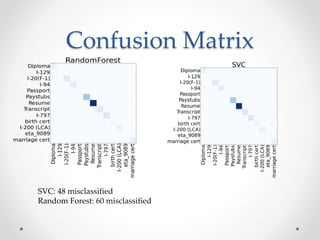






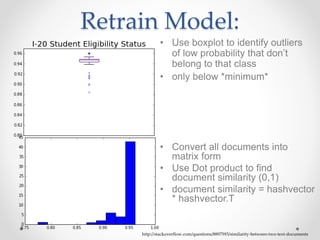
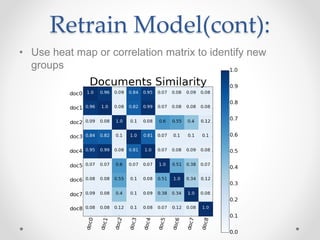




This document summarizes an effort to classify immigration documents through machine learning in order to streamline the visa application process. The goals were to accurately identify documents, provide real-time feedback on missing documents, and reduce intensive document oversight. Data was extracted from over 50,000 immigration documents using OCR and various preprocessing techniques. Classification algorithms like SVC and Random Forest were tested, with SVC performing best at handling imbalanced classes. The initial model achieved good performance on some document types but poorer on others like passports. Future work outlined improving the model through techniques like identifying outliers, document similarity, and incorporating more document types and samples.















































