Download to read offline

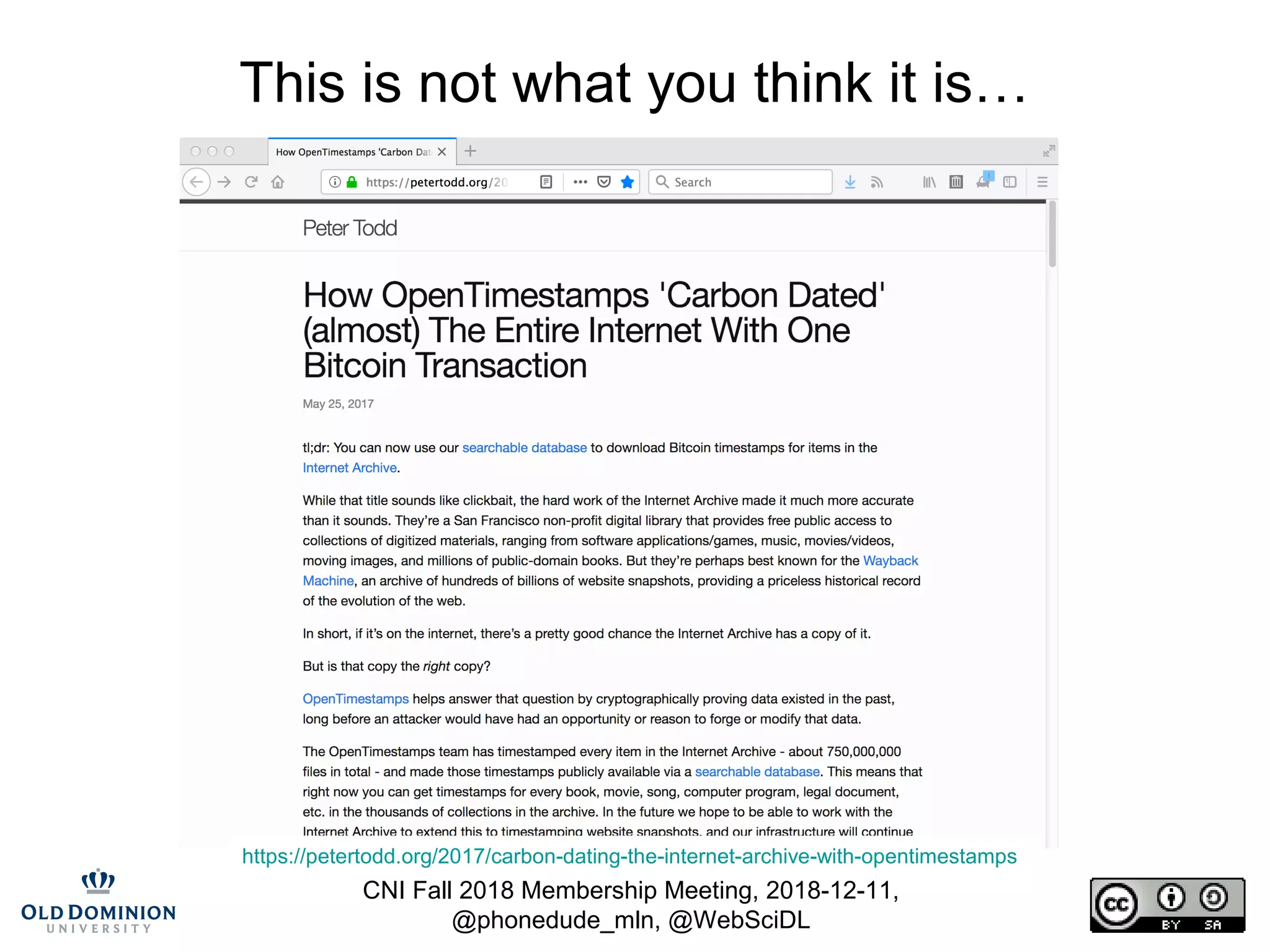
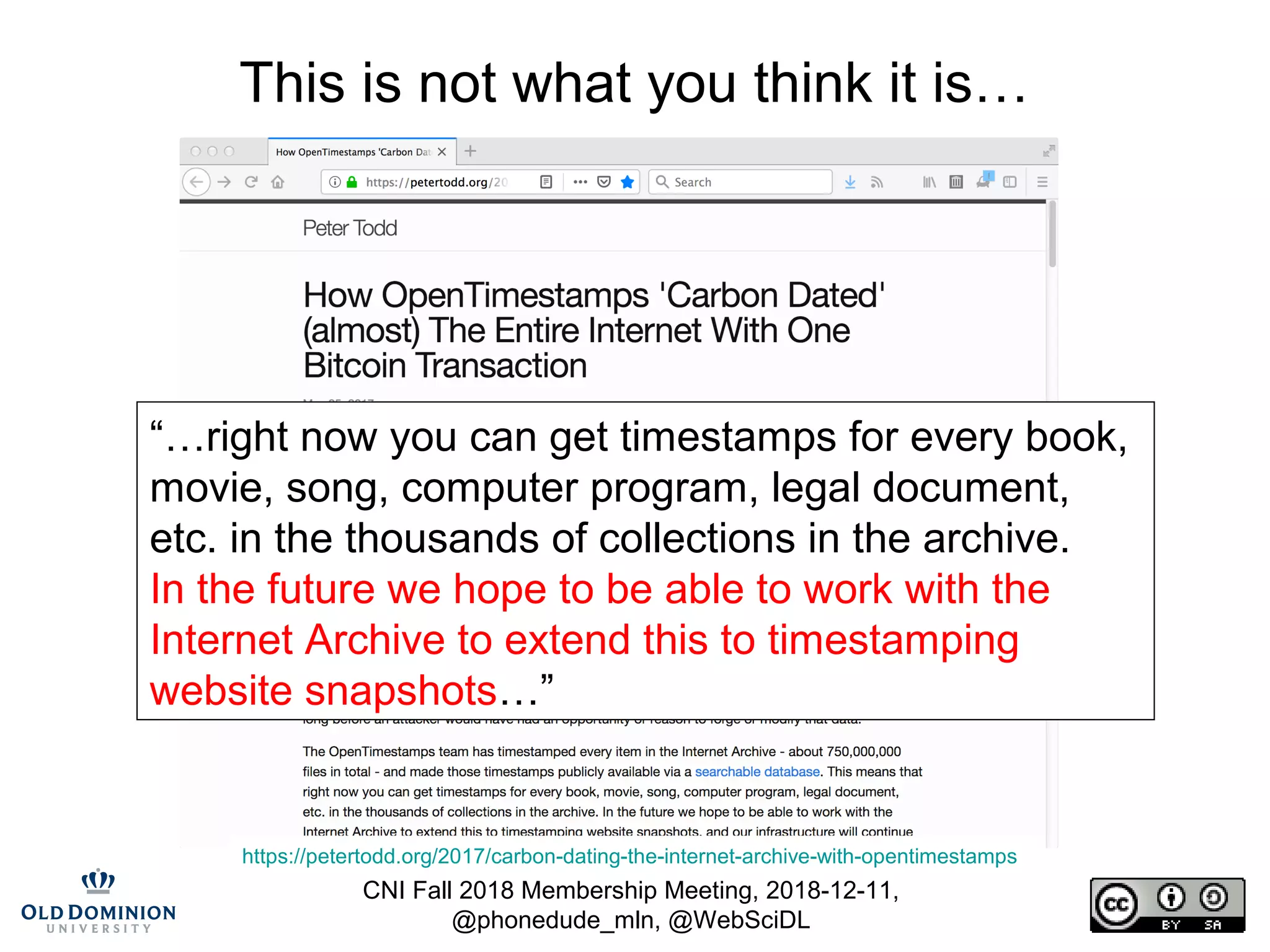

![CNI Fall 2018 Membership Meeting, 2018-12-11,
@phonedude_mln, @WebSciDL
A simplified workflow of web archiving
$ wget
WARC/1.0
WARC-Type: warcinfo
Content-Type: application/warc-fields
WARC-Date: 2018-11-03T17:20:02Z
WARC-Record-ID: <urn:uuid:6d14bf1d-0ef7-
4f03-9de2-e578d105d3cb>
WARC-Filename: foo.warc.warc.gz
WARC-Block-Digest:
sha1:WWSSYDYY7HTP4JTVOZANSIFPFHUJU64E
Content-Length: 257
software: Wget/1.15 (linux-gnu)
format: WARC File Format 1.0
[much deletia]
1) live web site
https://climate.nasa.gov/vital-signs/carbon-dioxide/
2) Crawled by any of
several archival crawlers 3) Result stored in a WARC File
(like tar or zip, but for Web archives)
4) WARC files are indexed,
served by replay software
(there are several variations of
Wayback Machine)
5) User chooses date of
capture (Memento-Datetime)
6) Page replayed with banner,
rewritten links, etc.](https://image.slidesharecdn.com/cni-fall-2018-nelson-181211155801/75/Blockchain-Can-Not-Be-Used-To-Verify-Replayed-Archived-Web-Pages-6-2048.jpg)



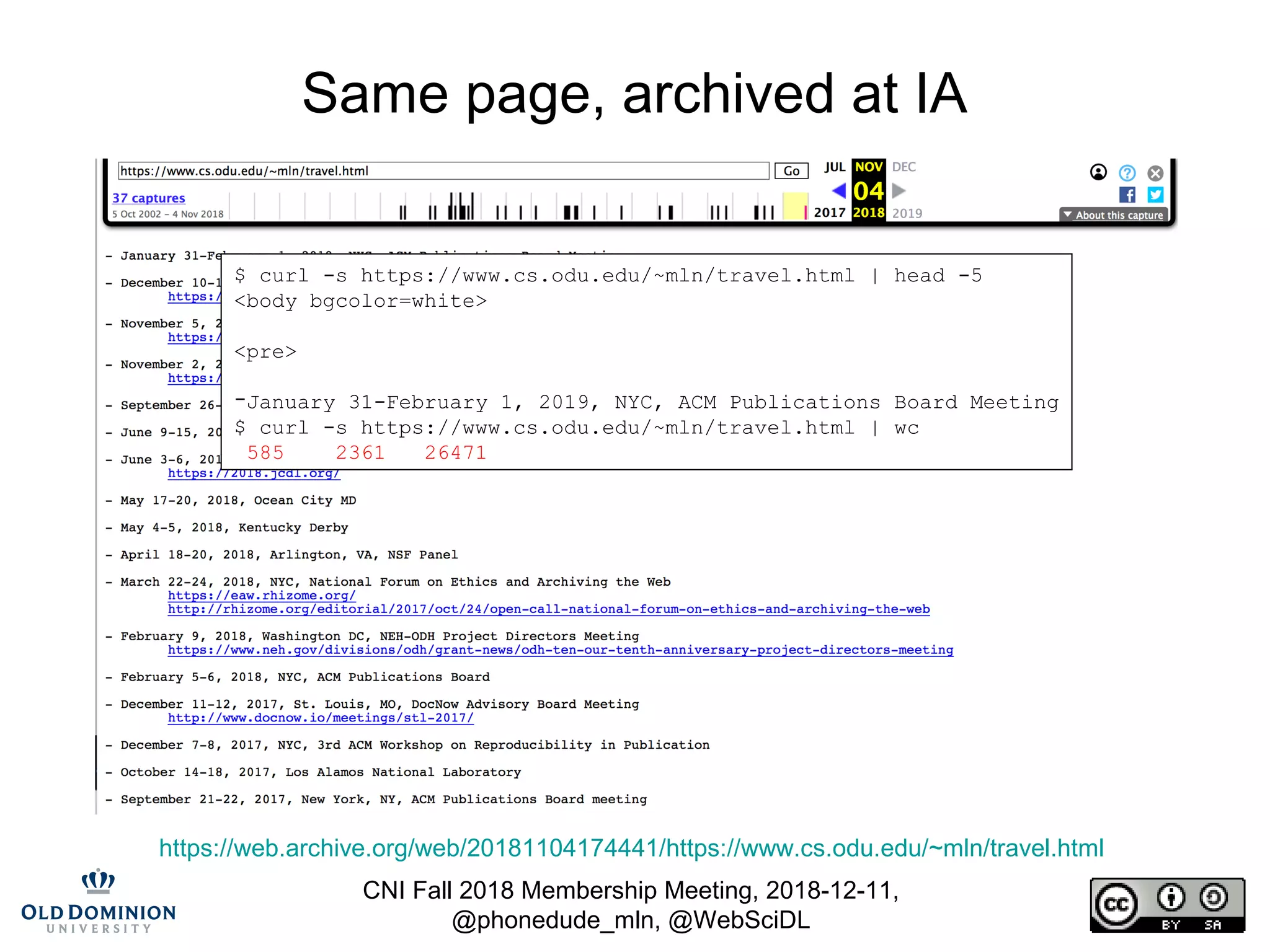
![CNI Fall 2018 Membership Meeting, 2018-12-11,
@phonedude_mln, @WebSciDL
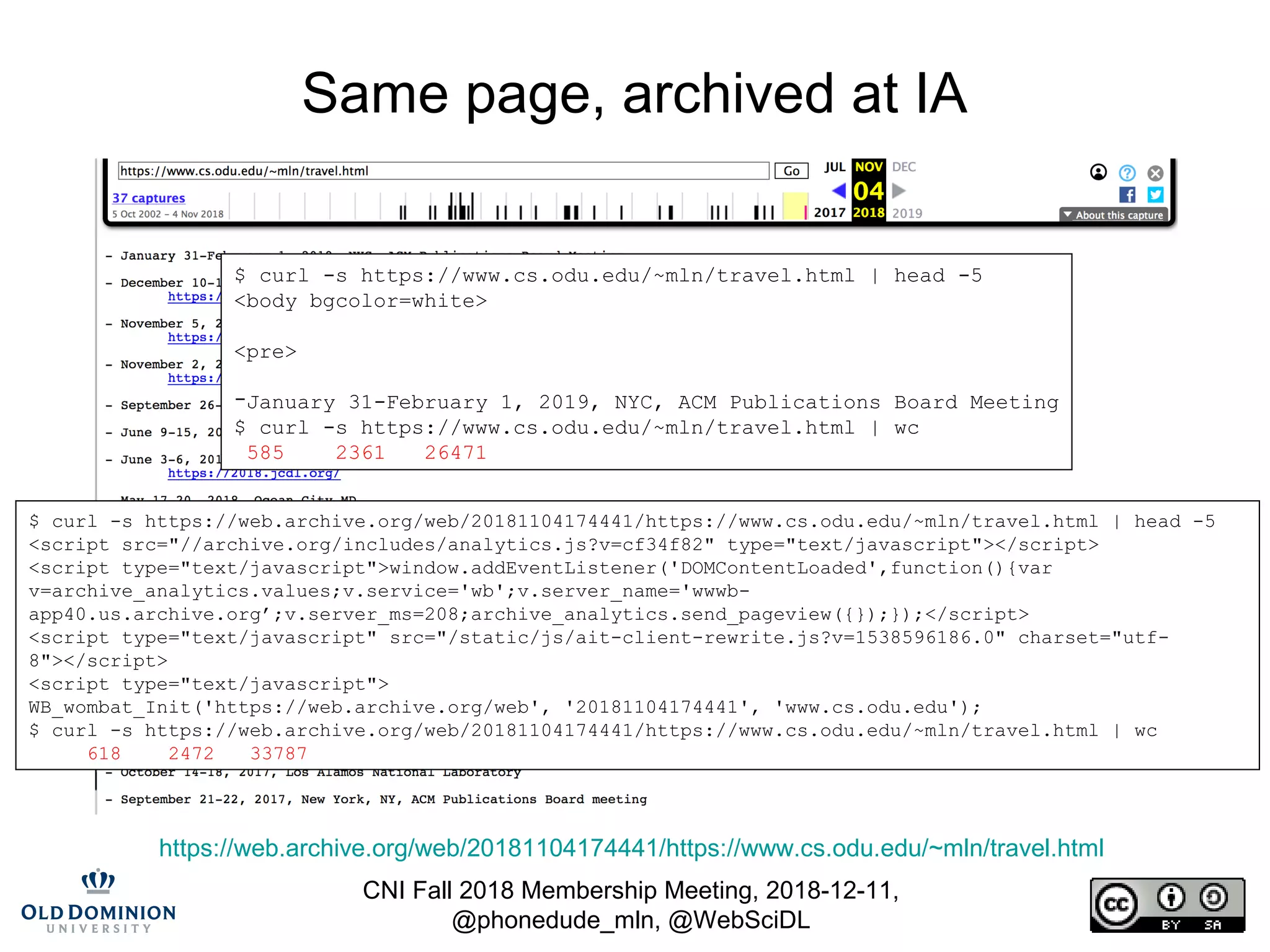
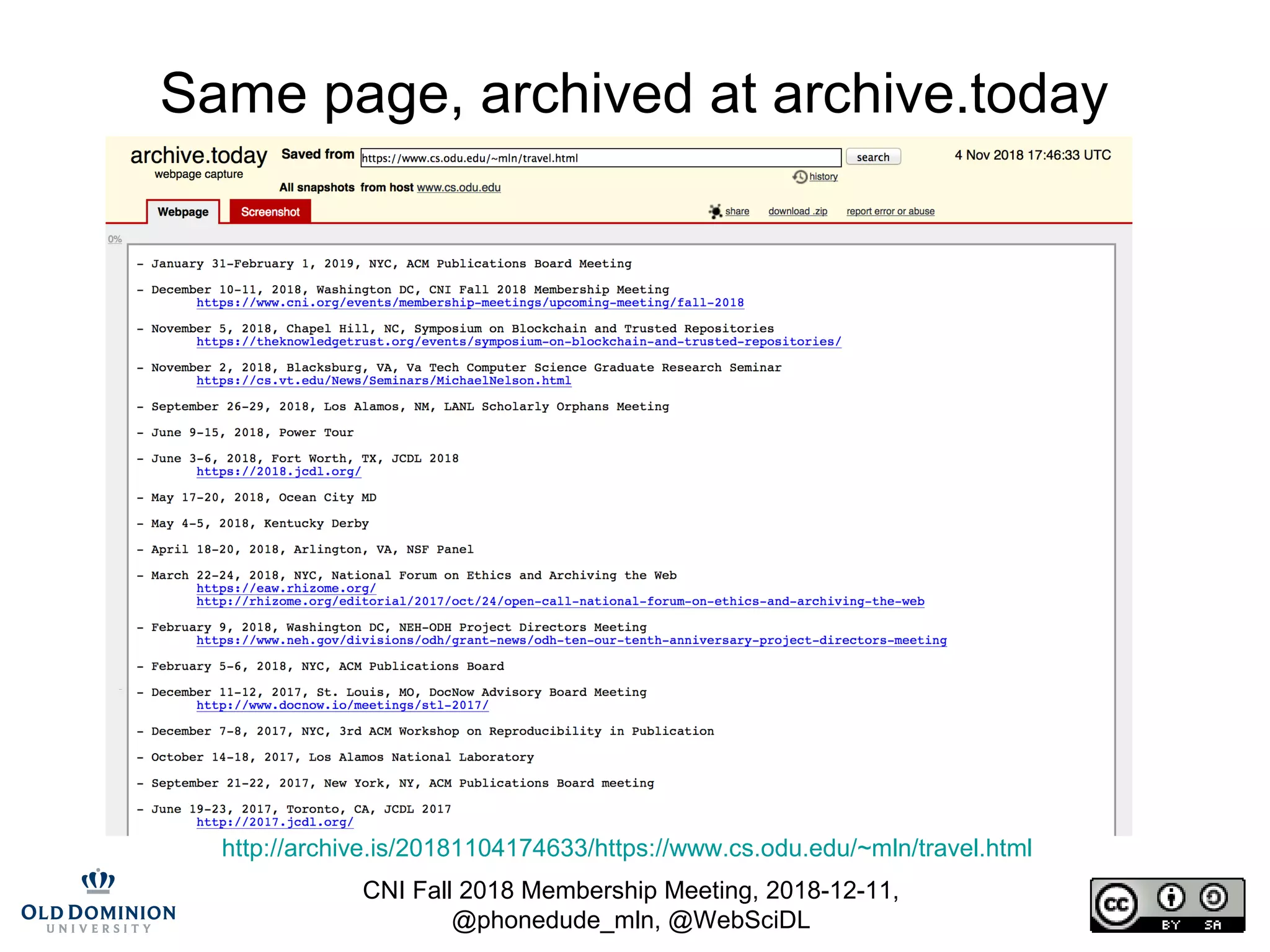
Same page, archived at archive.today
http://archive.is/20181104174633/https://www.cs.odu.edu/~mln/travel.html
$ curl -s http://archive.is/20181104174633/https://www.cs.odu.edu/~mln/travel.html | head -5
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><html style="background-
color:#EEEEEE" prefix="og: http://ogp.me/ns# article: http://ogp.me/ns/article#" itemscope
itemtype="http://schema.org/Article"><!--174.109.72.208--><!--curl/7.30.0--><head><meta http-
equiv="Content-Type" content="text/html;charset=utf-8"/><meta name="robots"
content="index,noarchive"/><meta name="viewport" content="device-width=300, initial-scale=1"/><meta
property="twitter:card" content="summary"/><meta property="twitter:site" content="@archiveis"/><meta
property="og:type" content="article"/><meta property="og:site_name" content="archive.is"/><meta
property="og:url" content="http://archive.is/l6QdV" itemprop="url"/><meta property="og:title"
content="https://www.cs.odu.edu/~mln/travel.html"/><meta property="twitter:title"
content="https://www.cs.odu.edu/~mln/travel.html"/><meta property="twitter:description"
content="archived 4 Nov 2018 17:46:33 UTC" itemprop="description"/><meta
property="article:published_time" content="2018-11-04T17:46:33Z" itemprop="dateCreated"/><meta
property="article:modified_time" content="2018-11-04T17:46:33Z" itemprop="dateModified"/><link
rel="image_src"
href="https://archive.is/l6QdV/d7e3acef18a0433590880dfcc26f8e1f5f18f91e/scr.png"/><meta
property="og:image"
content="https://archive.is/l6QdV/d7e3acef18a0433590880dfcc26f8e1f5f18f91e/scr.png"
itemprop="image"/><meta property="twitter:image"
content="https://archive.is/l6QdV/d7e3acef18a0433590880dfcc26f8e1f5f18f91e/scr.png"/><meta
property="twitter:image:src"
content="https://archive.is/l6QdV/d7e3acef18a0433590880dfcc26f8e1f5f18f91e/scr.png"/><meta
property="twitter:image:width" content="1024"/><meta property="twitter:image:height"
content="768"/><link rel="icon" href="//www.google.com/s2/favicons?domain=www.cs.odu.edu"/><link
rel="canonical" href="https://archive.is/l6QdV"/><link rel="bookmark"
href="http://archive.today/20181104174633/https://www.cs.odu.edu/~mln/travel.html"/><title></title><
/head><body style="margin:0;background-color:#EEEEEE"><center><div id="HEADER" style="font-
family:sans-serif;background
[much deletia – you get the point]
$ curl -s http://archive.is/20181104174633/https://www.cs.odu.edu/~mln/travel.html | wc
730 3640 62392](https://image.slidesharecdn.com/cni-fall-2018-nelson-181211155801/75/Blockchain-Can-Not-Be-Used-To-Verify-Replayed-Archived-Web-Pages-13-2048.jpg)



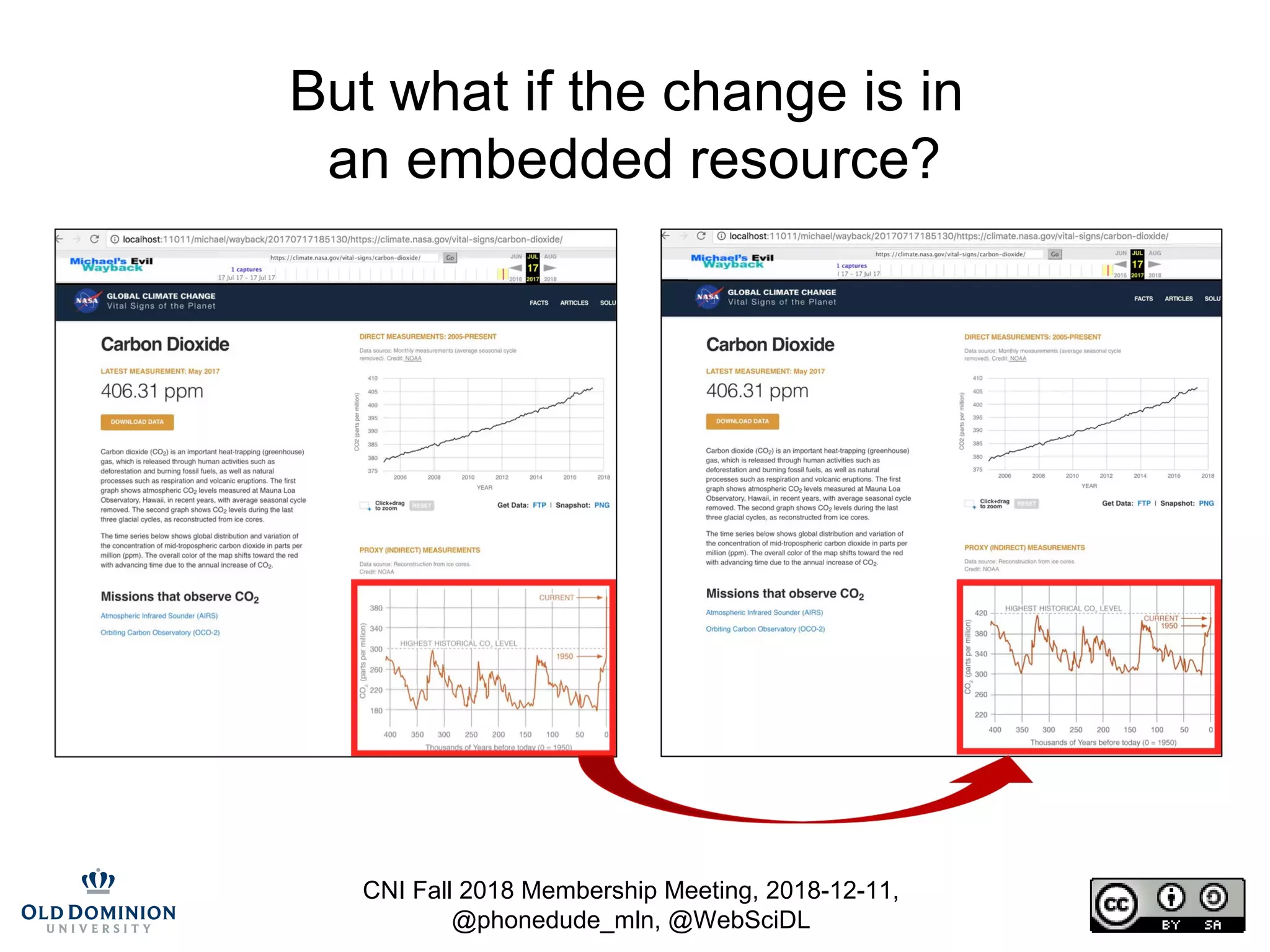

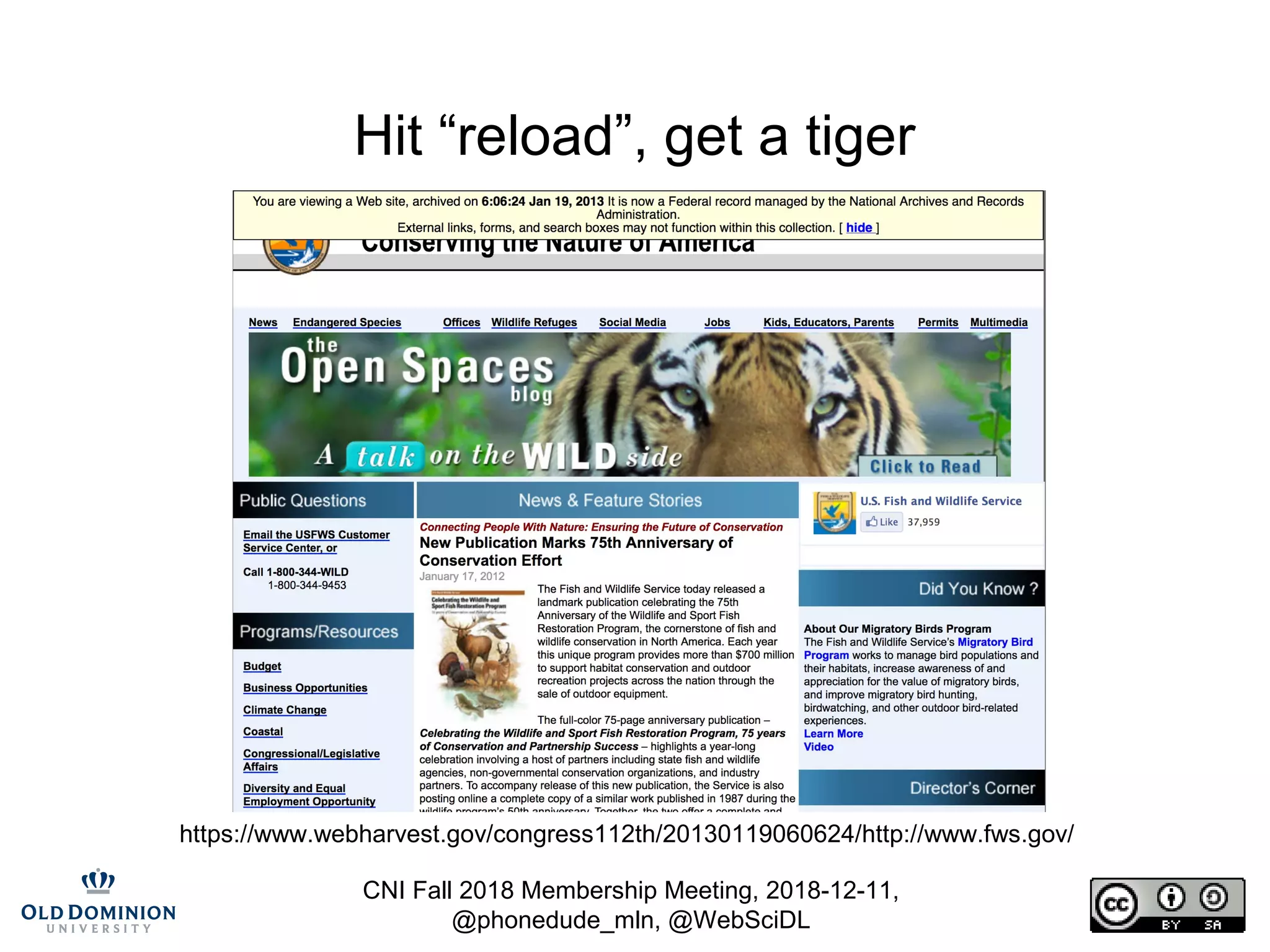
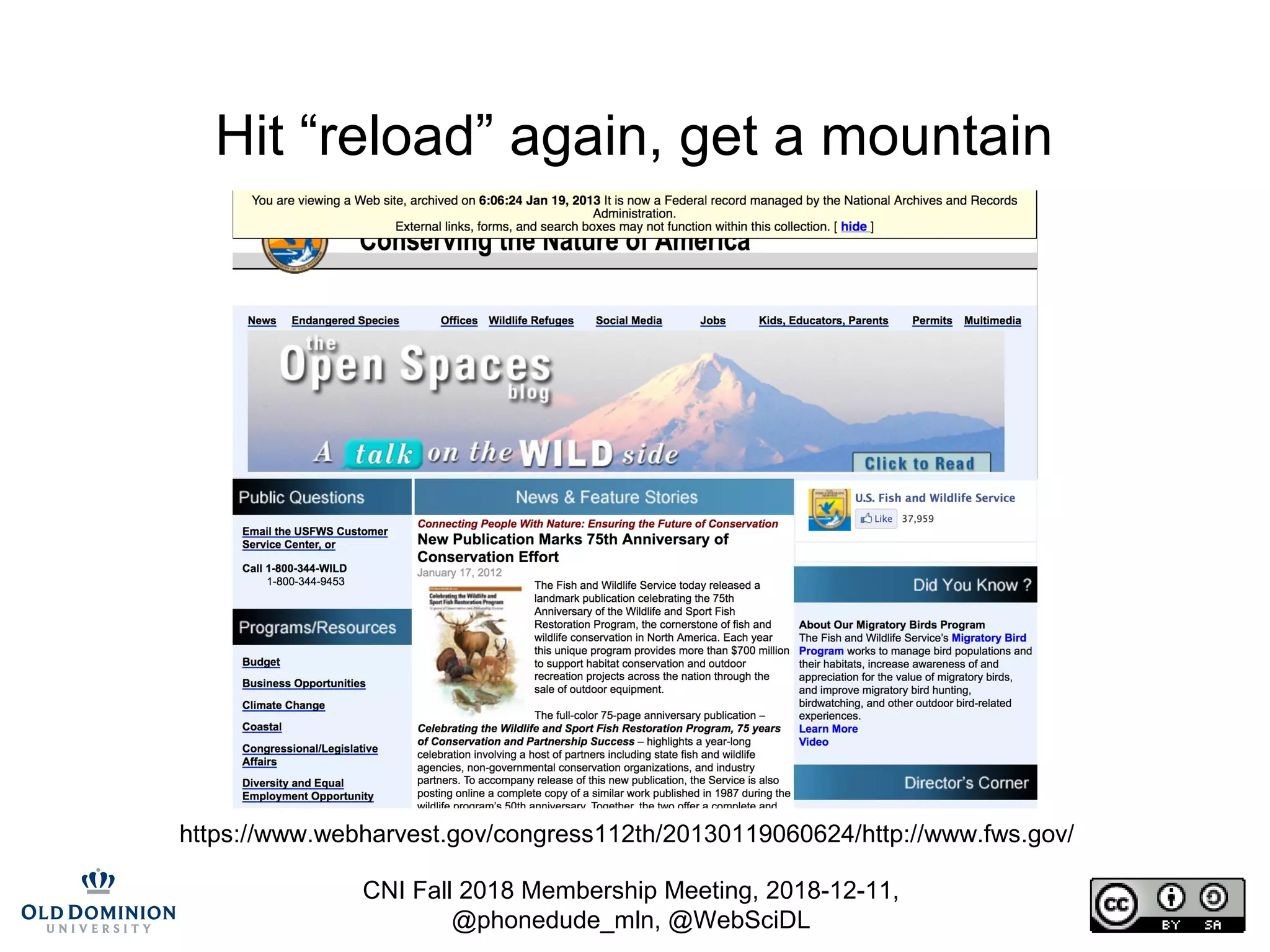

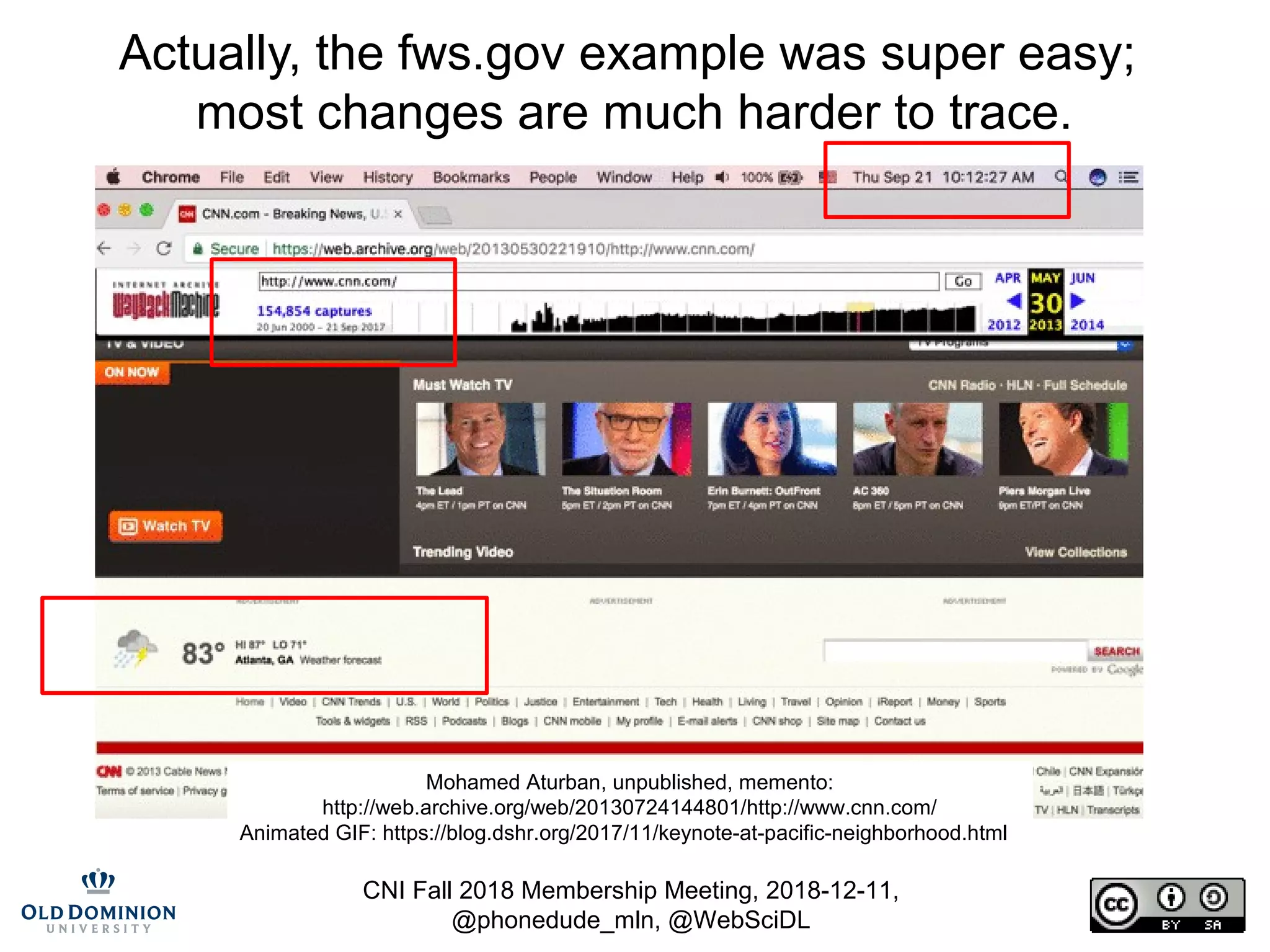












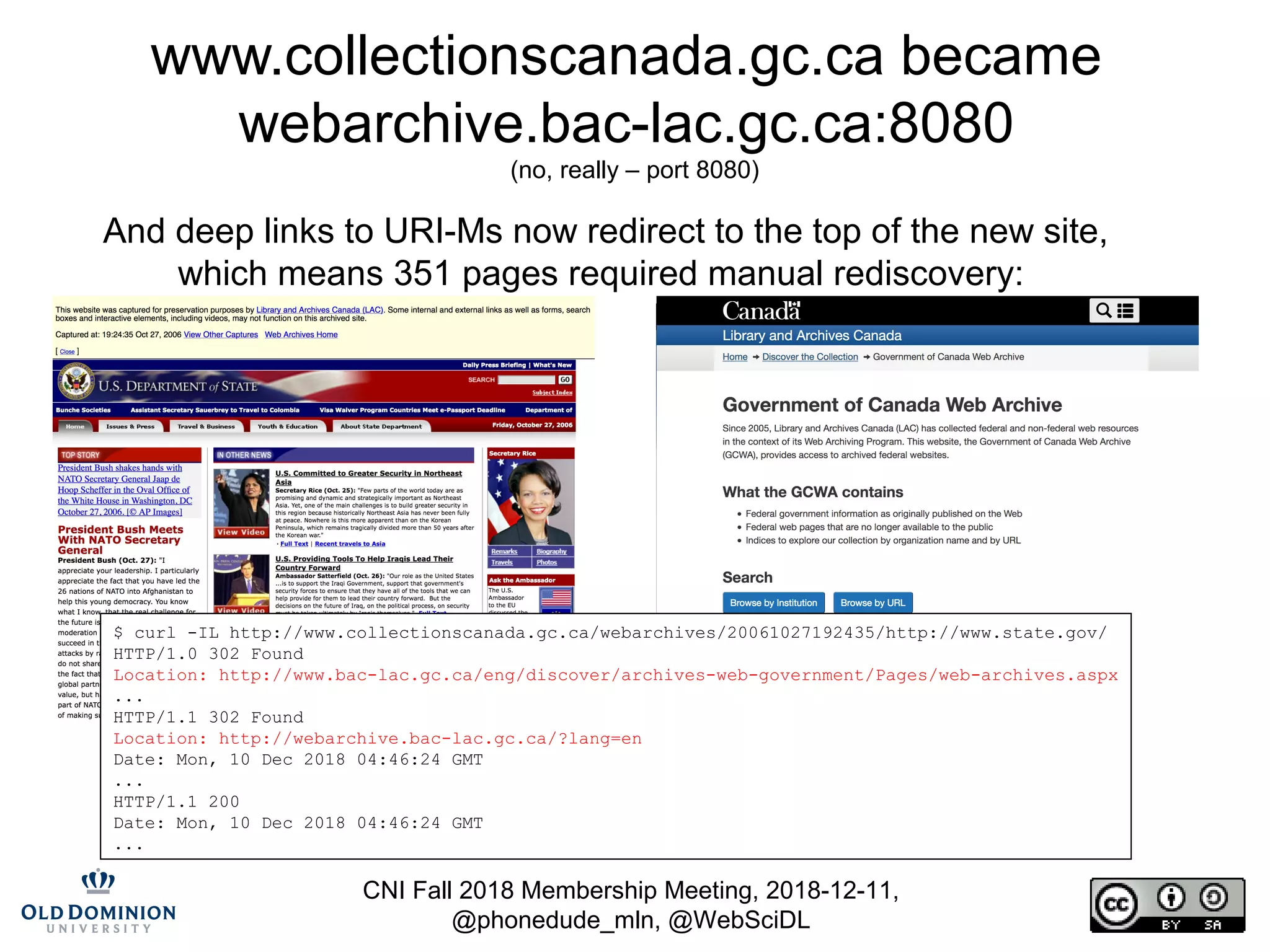

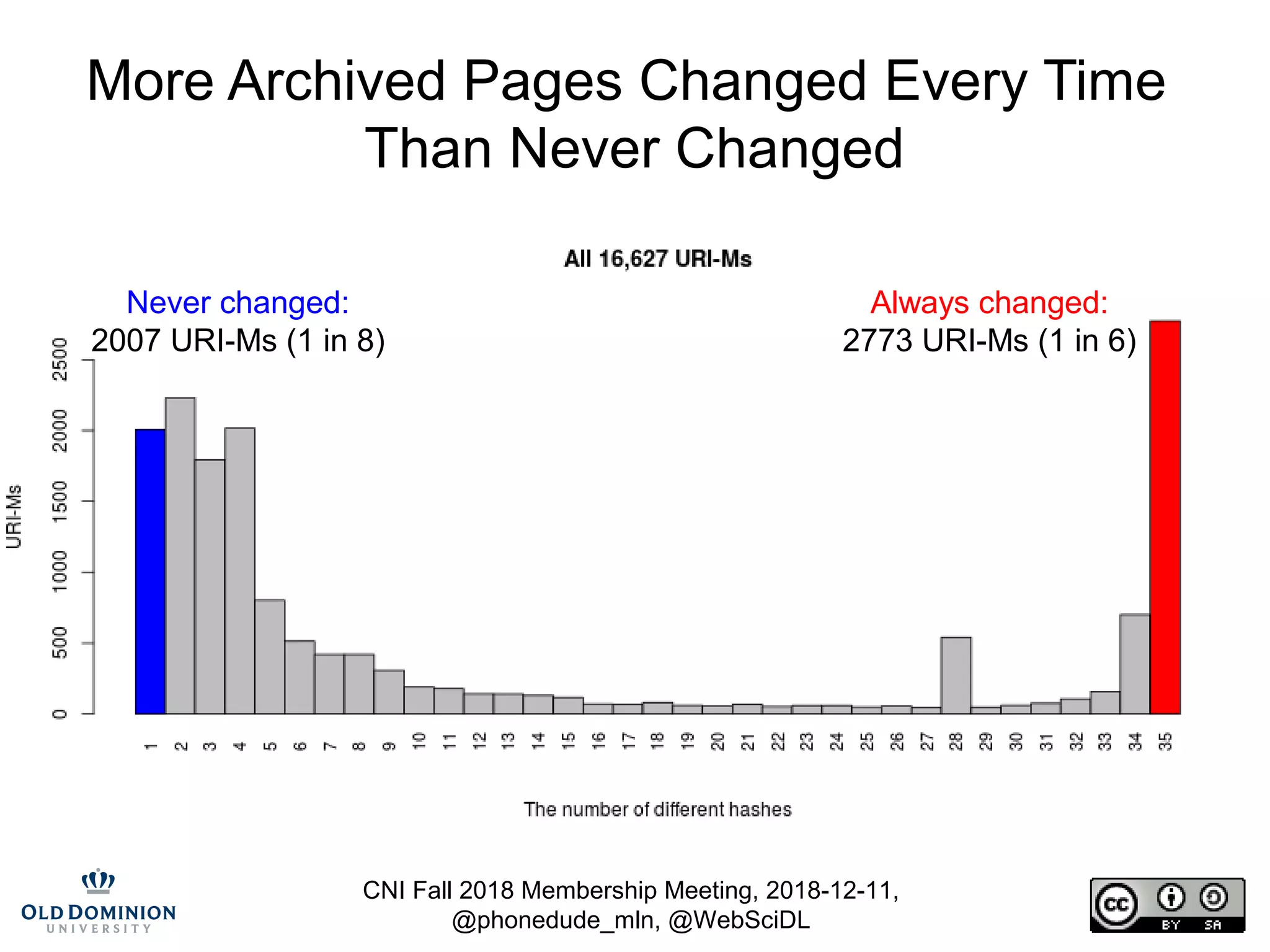




The document summarizes discussions from the CNI Fall 2018 Membership Meeting, focusing on the challenges of web archiving, particularly in verifying changes and the limitations of using blockchain for this purpose. It emphasizes that web archiving differs from simple file backups, as it involves preserving continuous changes without the ability to ensure fixity over time. The presentation presents methods and examples of web archiving processes, including the challenges of rendering embedded content and tracking changes across multiple WARC files.























































































