Download to read offline



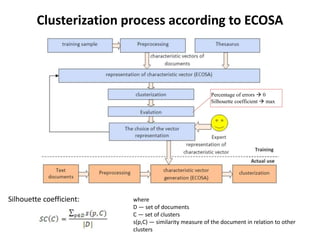


This document discusses clustering text documents using WordNet and semantic similarity measures. It presents the ECOSA algorithm, which reduces the dimensions of document characteristic vectors. The clustering process using ECOSA has two steps: training and actual use. It aggregates concepts from WordNet and uses a measure of semantic similarity. The clustering process aims to minimize errors and maximize the silhouette coefficient according to ECOSA.
![dipLODocus[RDF]: Short and Long-Tail RDF Analytics for Massive Webs of Data](https://cdn.slidesharecdn.com/ss_thumbnails/iswc2011wylotdata01-140127105144-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































