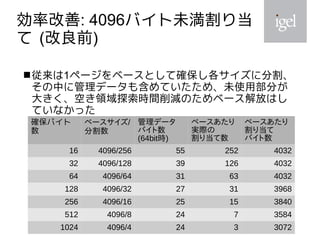
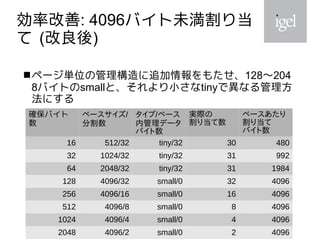
2021年は、大規模PC環境向けOS配信管理ソリューションの開発に伴い、BitVisorに含まれていた細かい問題が修正されました。変更内容には、10コア20スレッド対応、ヒープ割り当て改善などが含まれます。これらの変更内容について紹介します。









![11
効率改善: 管理用データ構造のス
リム化
ページ単位の割り当てサイズを保持していたallocsize[]
配列を廃止
単なるシフト演算なので、RAM参照より計算したほうが速い
ページ管理構造体から仮想アドレスを削除
物理アドレスから簡単に計算できる
ページ管理構造体に入れているサイズやタイプ等を8
ビットにすることで、構造体サイズを小さく保ちつつ
機械語は複雑にならないように
32バイト単位にすることで配列のオフセットアドレスの計算もシンプル
になる](https://image.slidesharecdn.com/202112summit-211206092440/85/BitVisor-Summit-10-1-BitVisor-2021-11-320.jpg)

































































