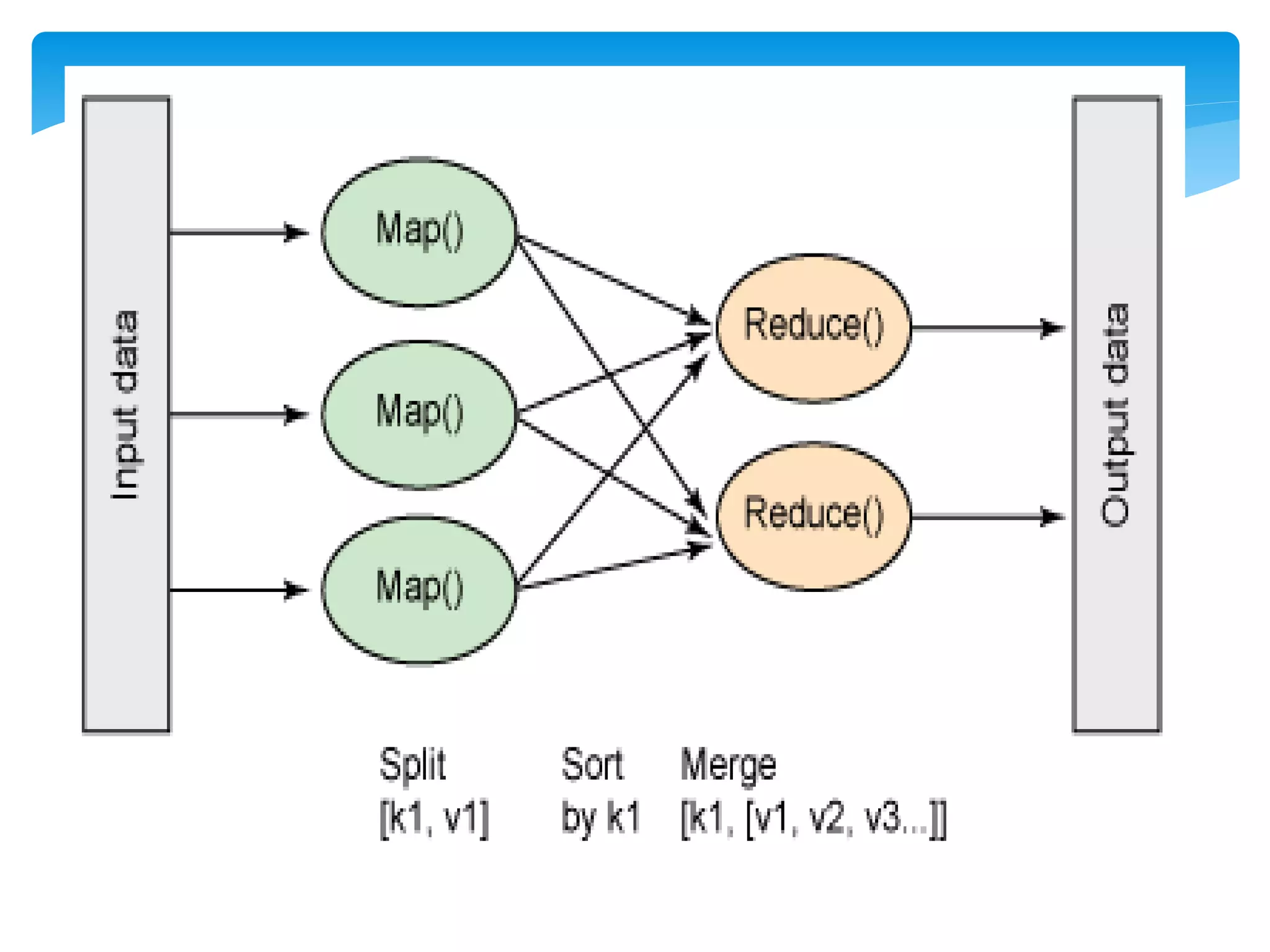
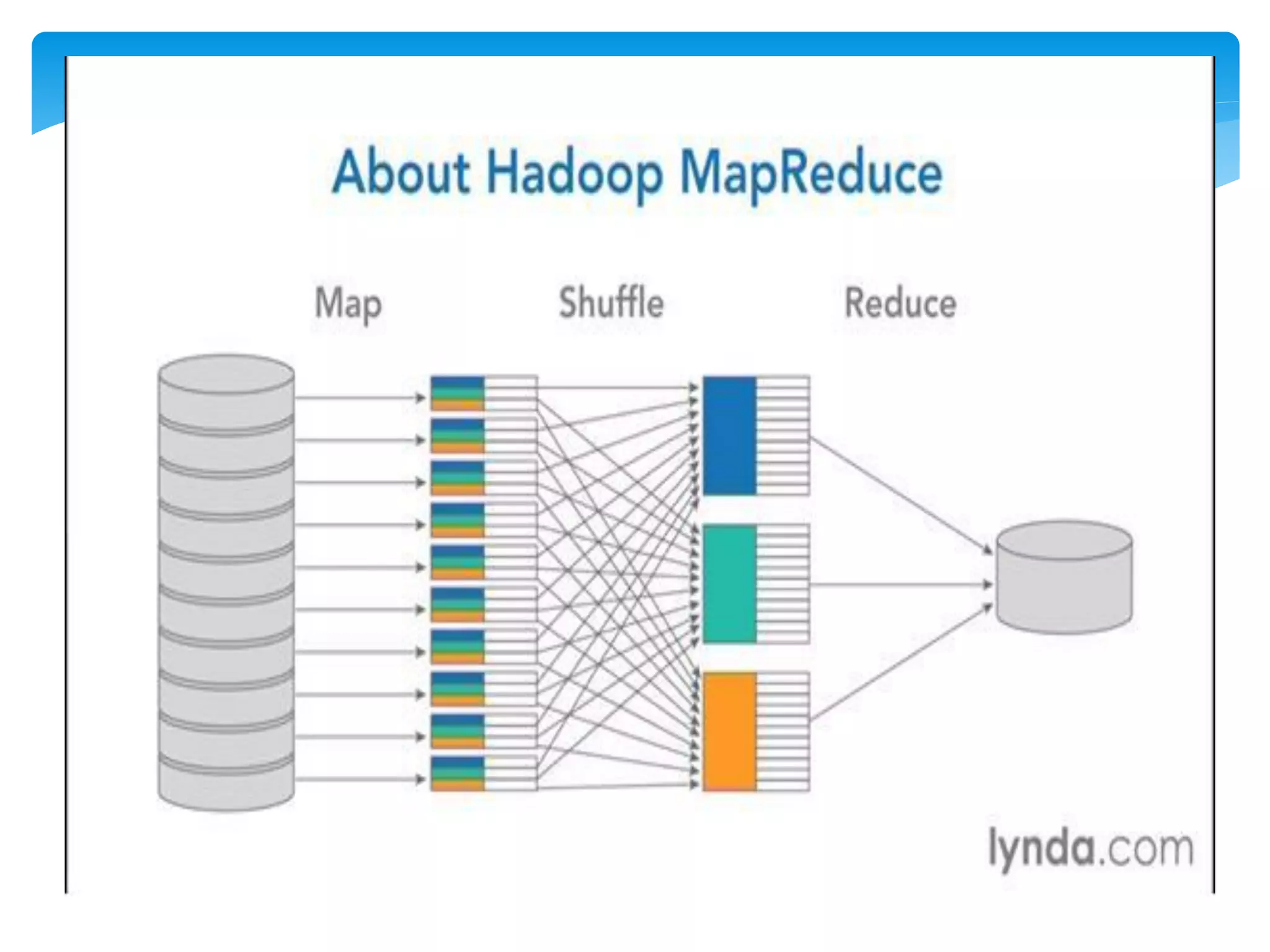
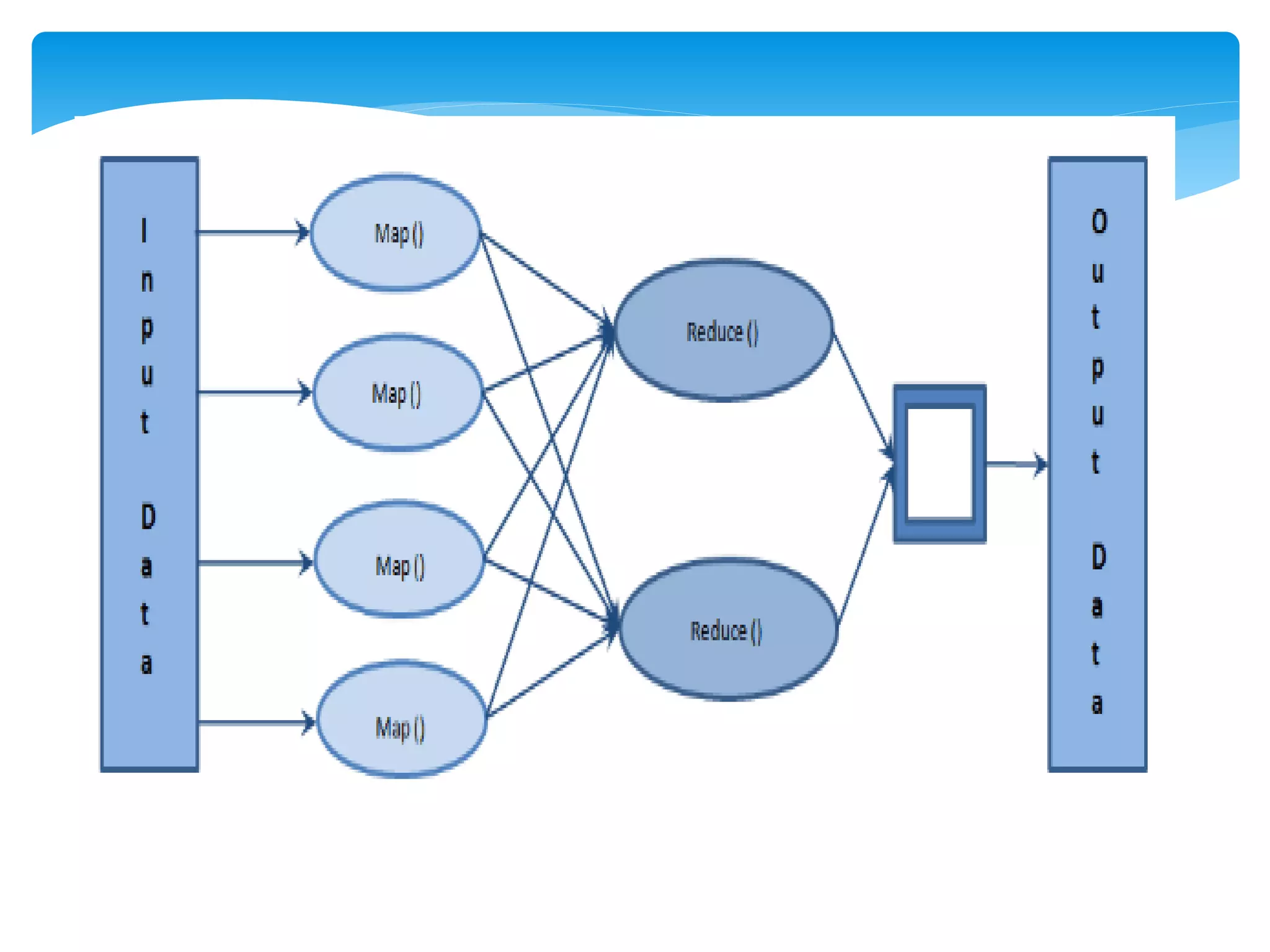
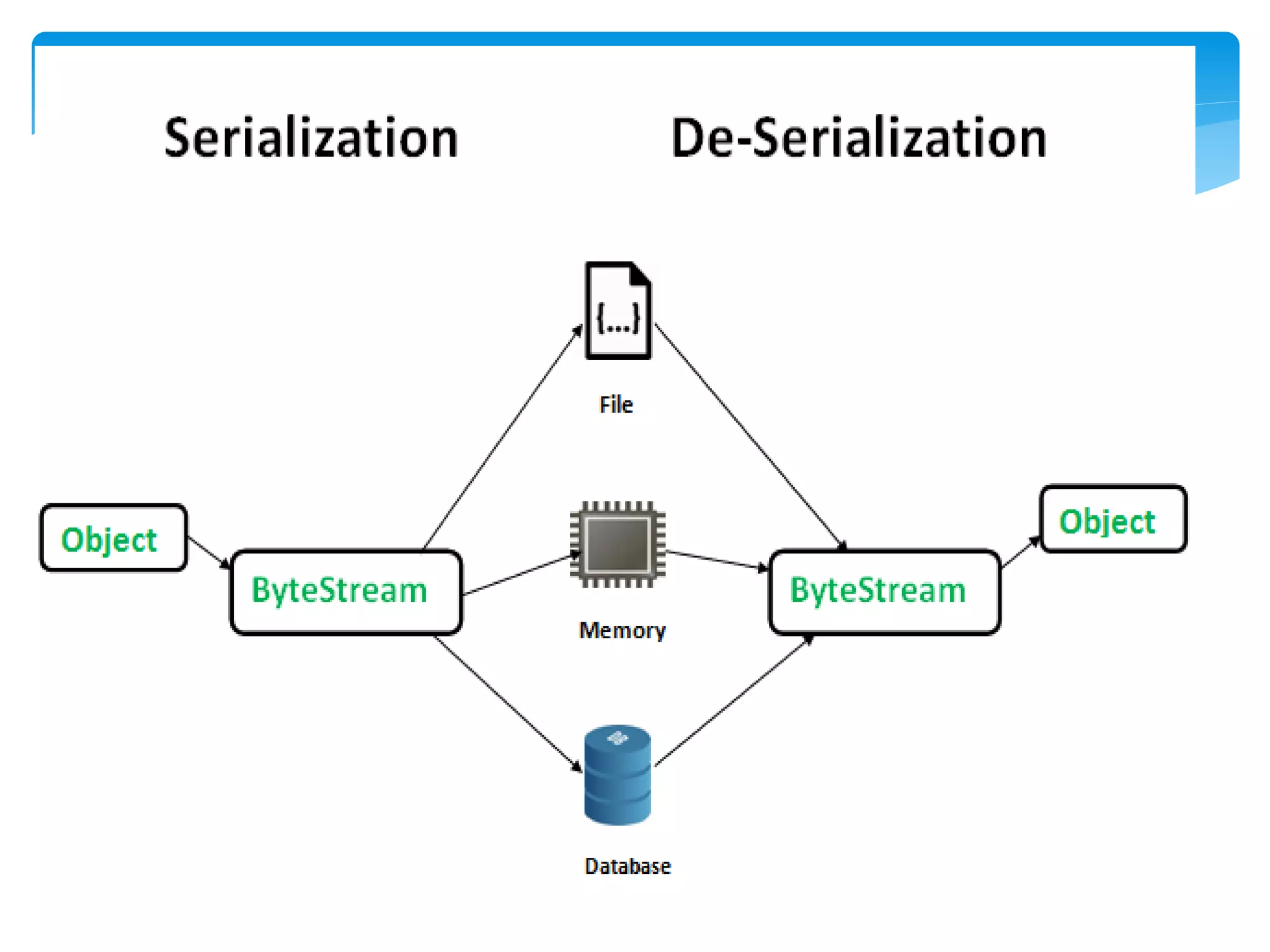
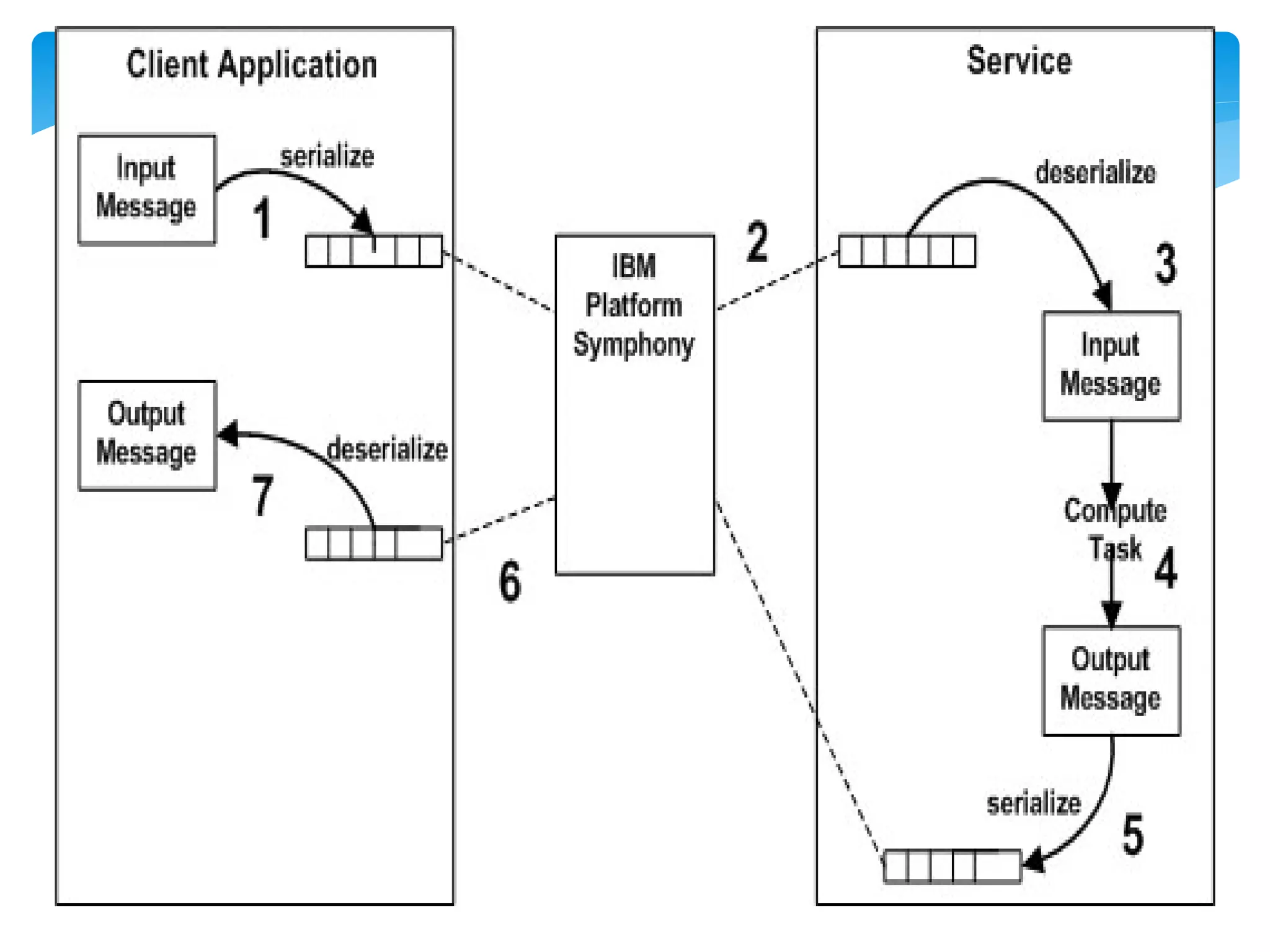
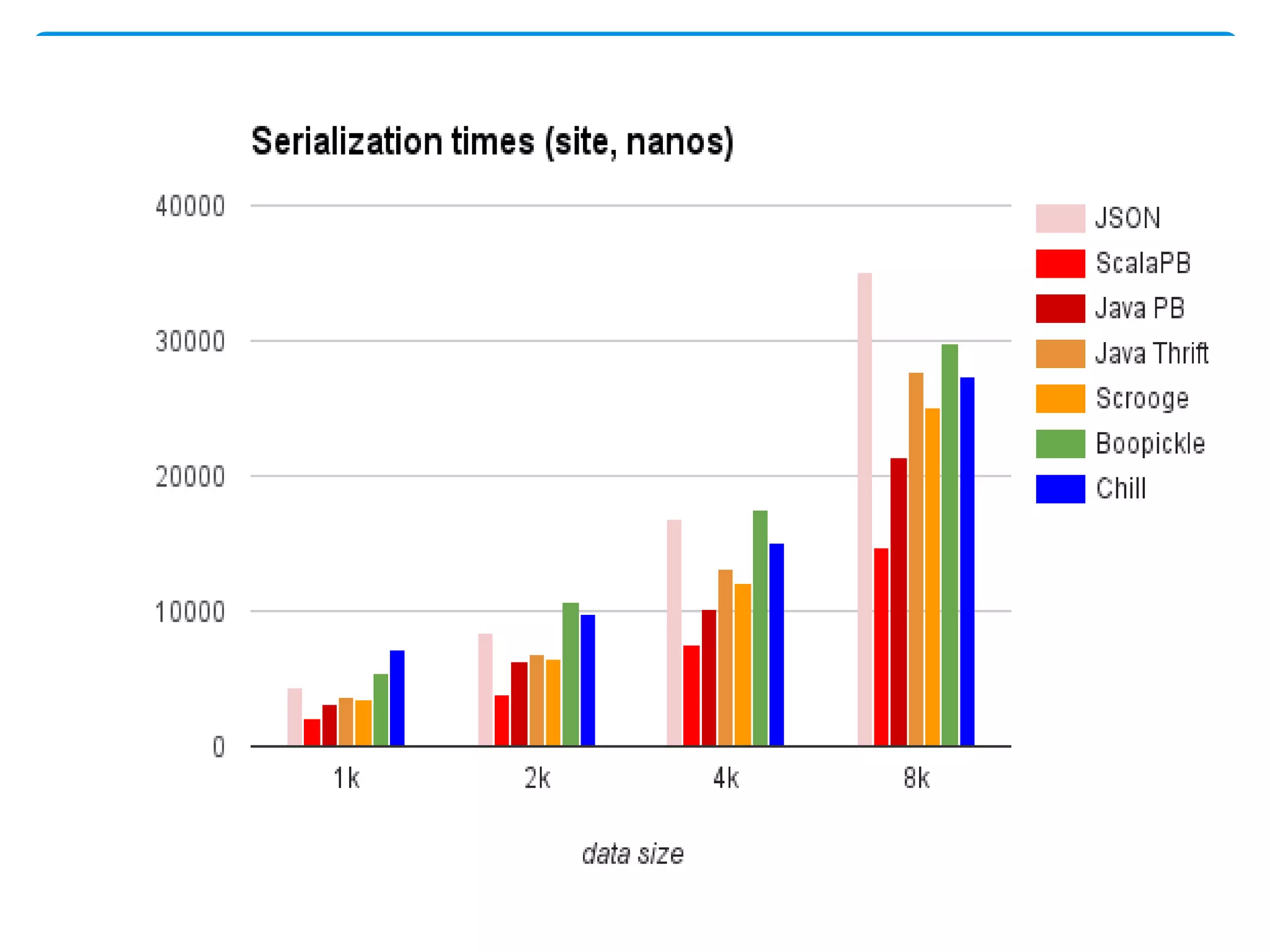
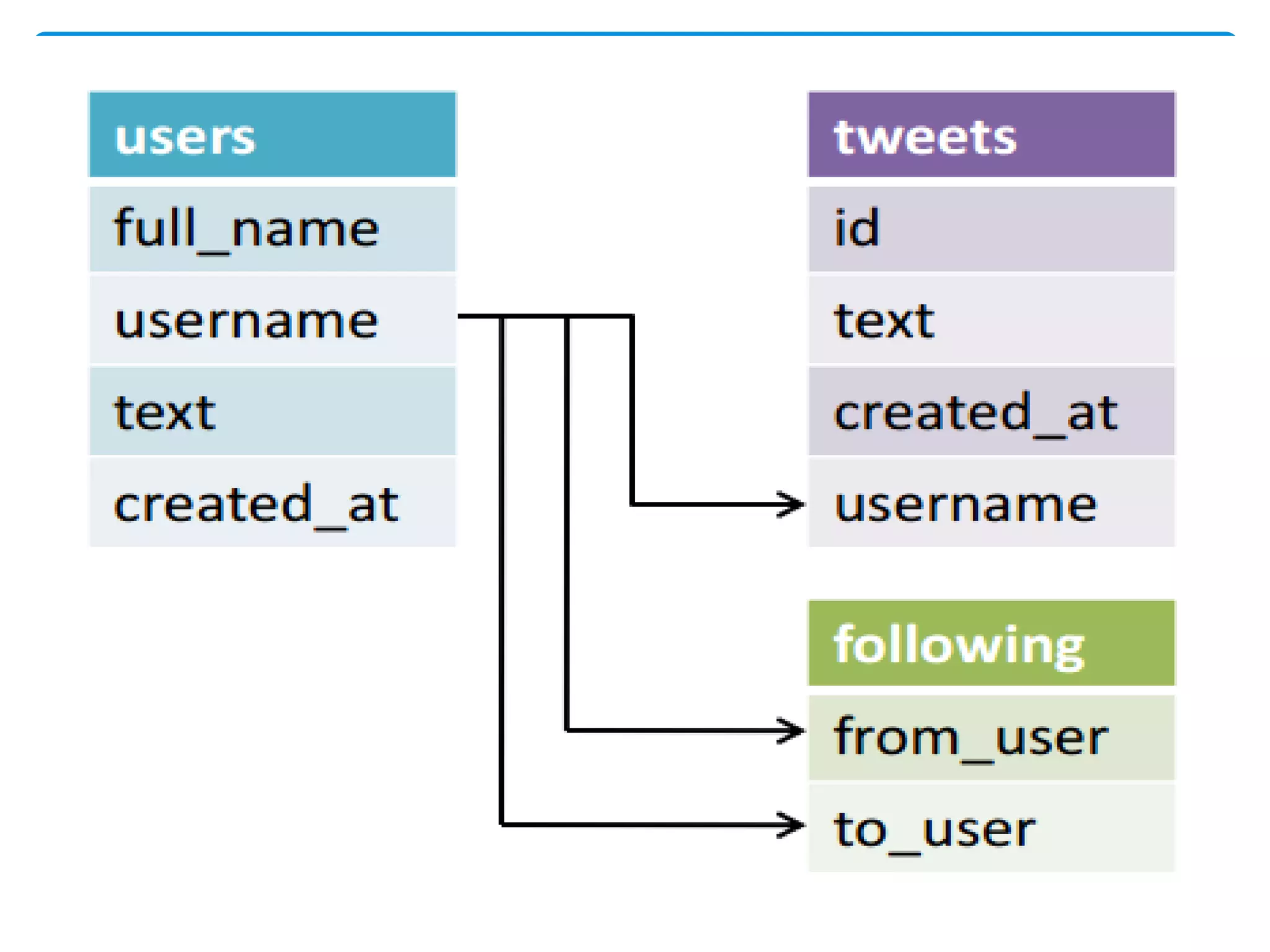
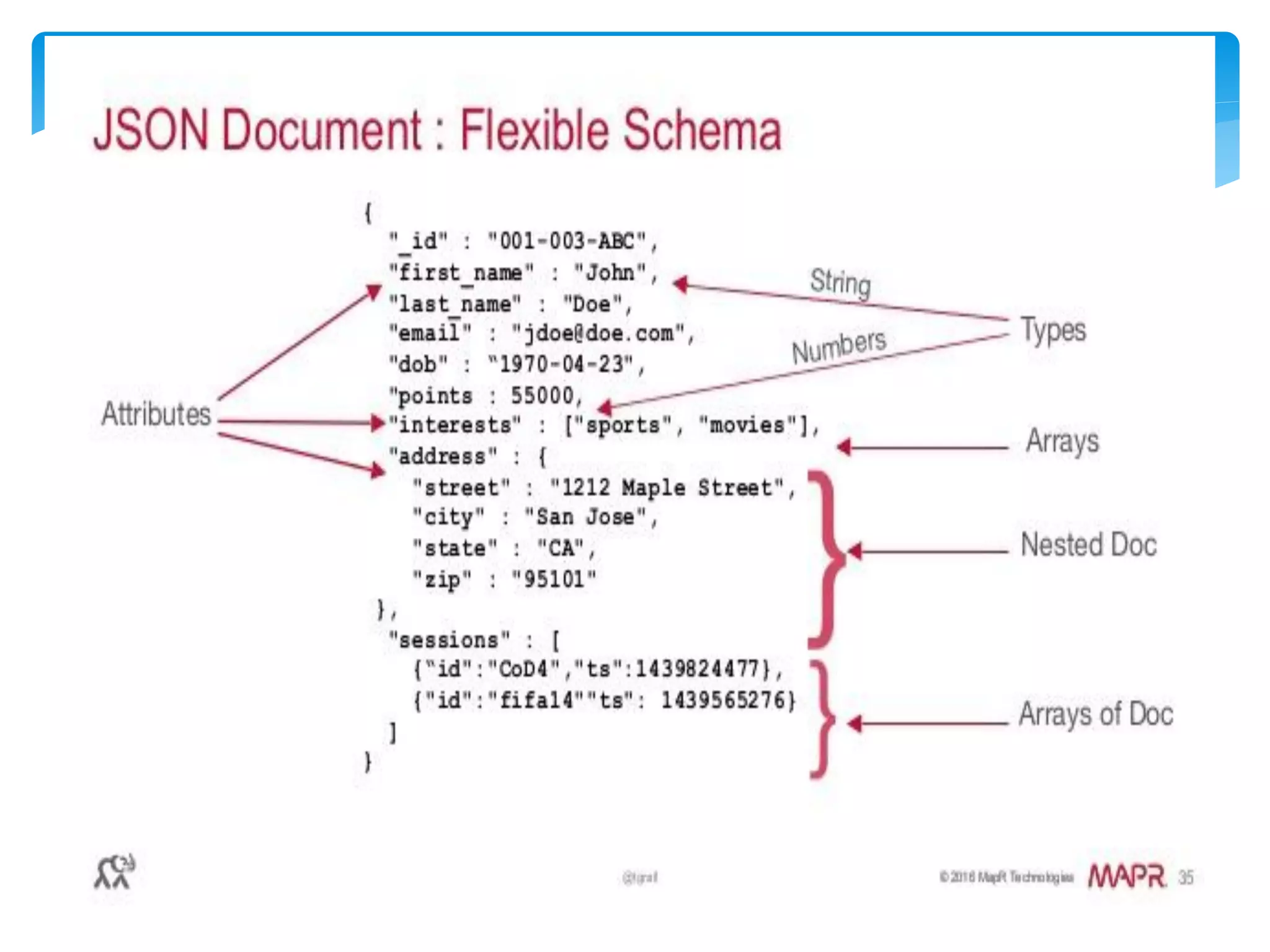
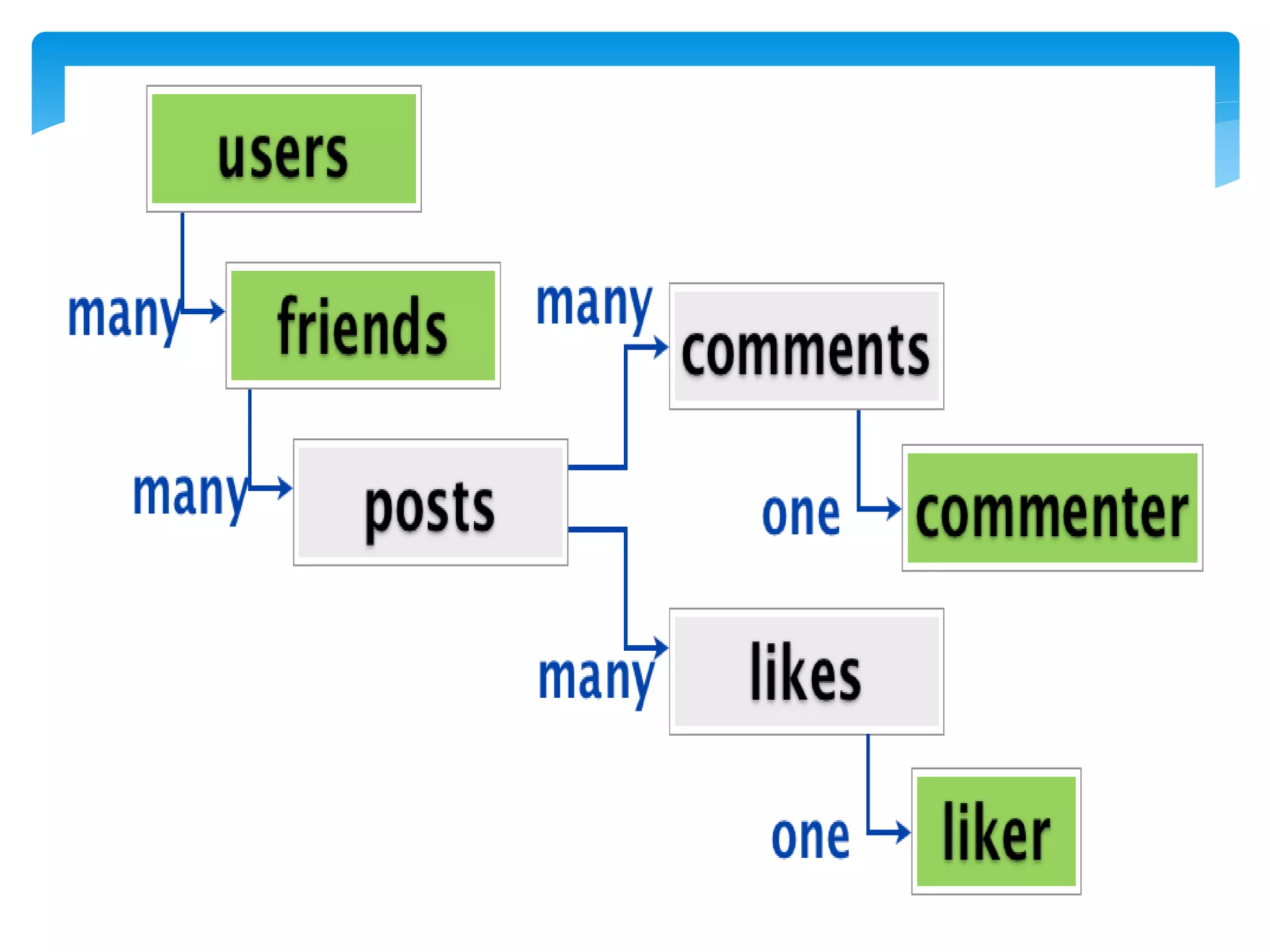
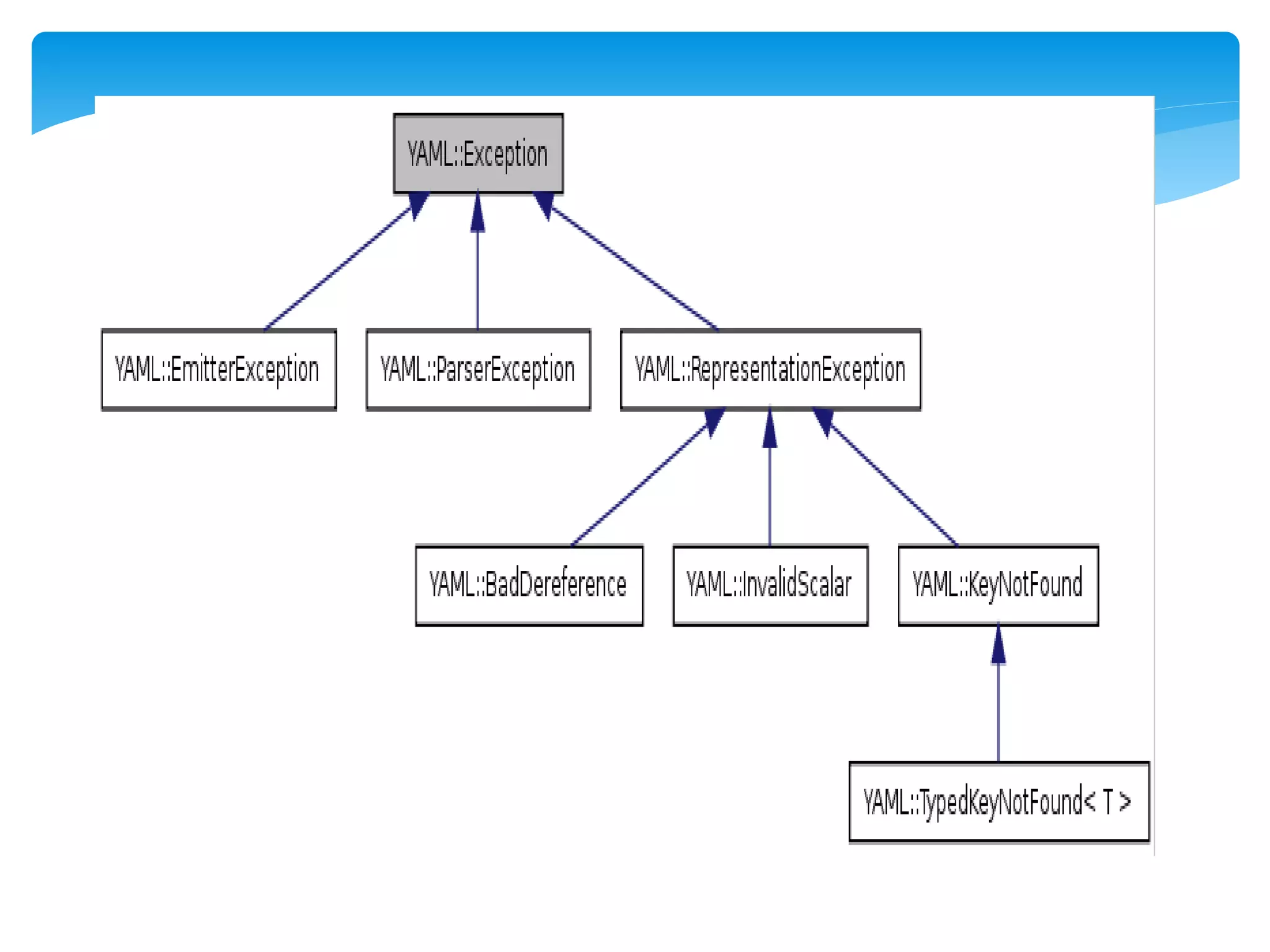
MapReduce is a programming model used for processing and generating large data sets in a parallel, distributed manner. It involves three main steps: Map, Shuffle, and Reduce. In the Map step, data is processed by individual nodes. In the Shuffle step, data is redistributed based on keys. In the Reduce step, processed data with the same key is grouped and aggregated. Serialization is the process of converting data into a byte stream for storage or transmission. It allows data to be transferred between systems and formats like JSON, XML, and binary formats are commonly used. Schema control is important for big data serialization to validate data structure.