Downloaded 43 times










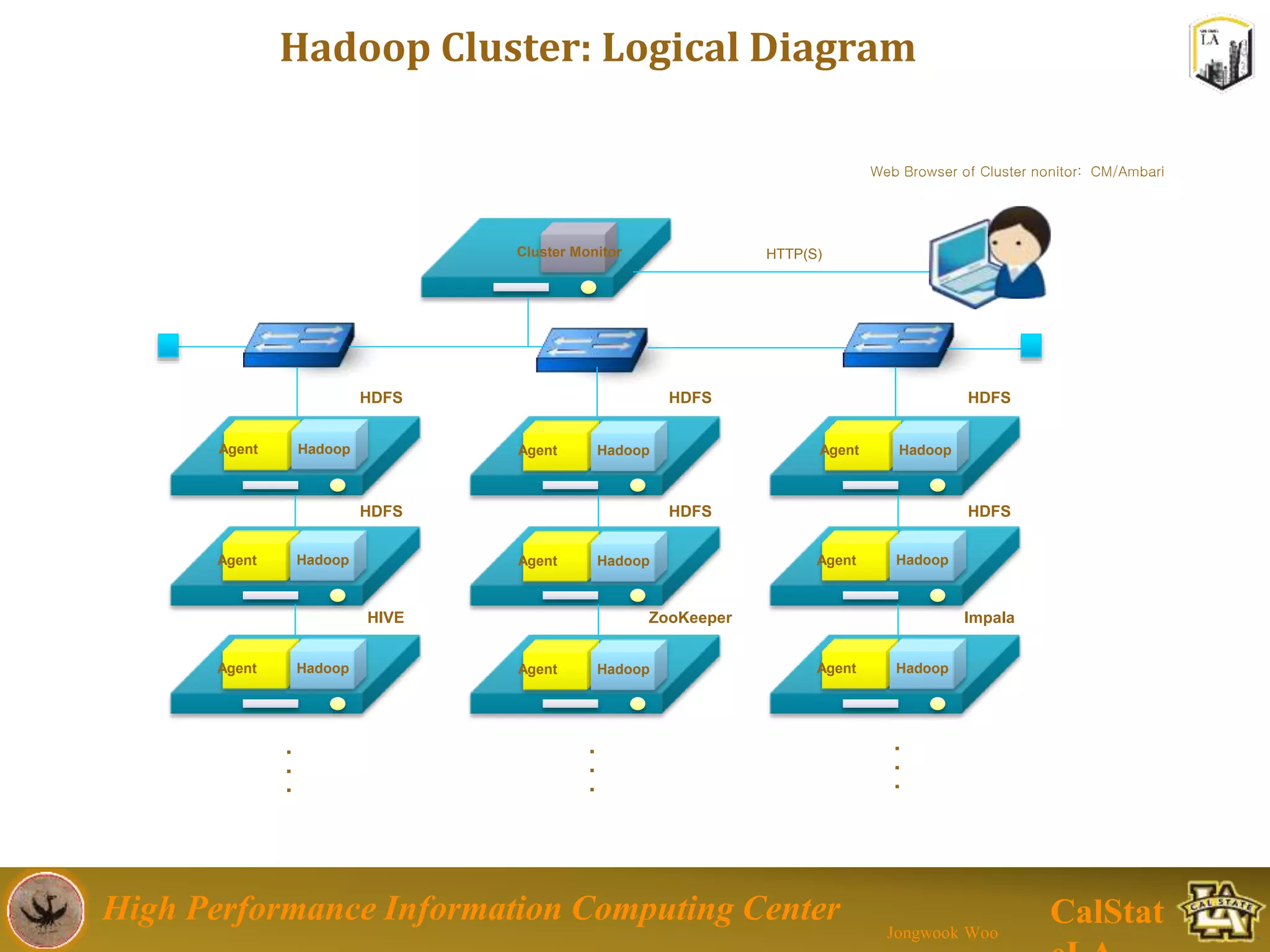



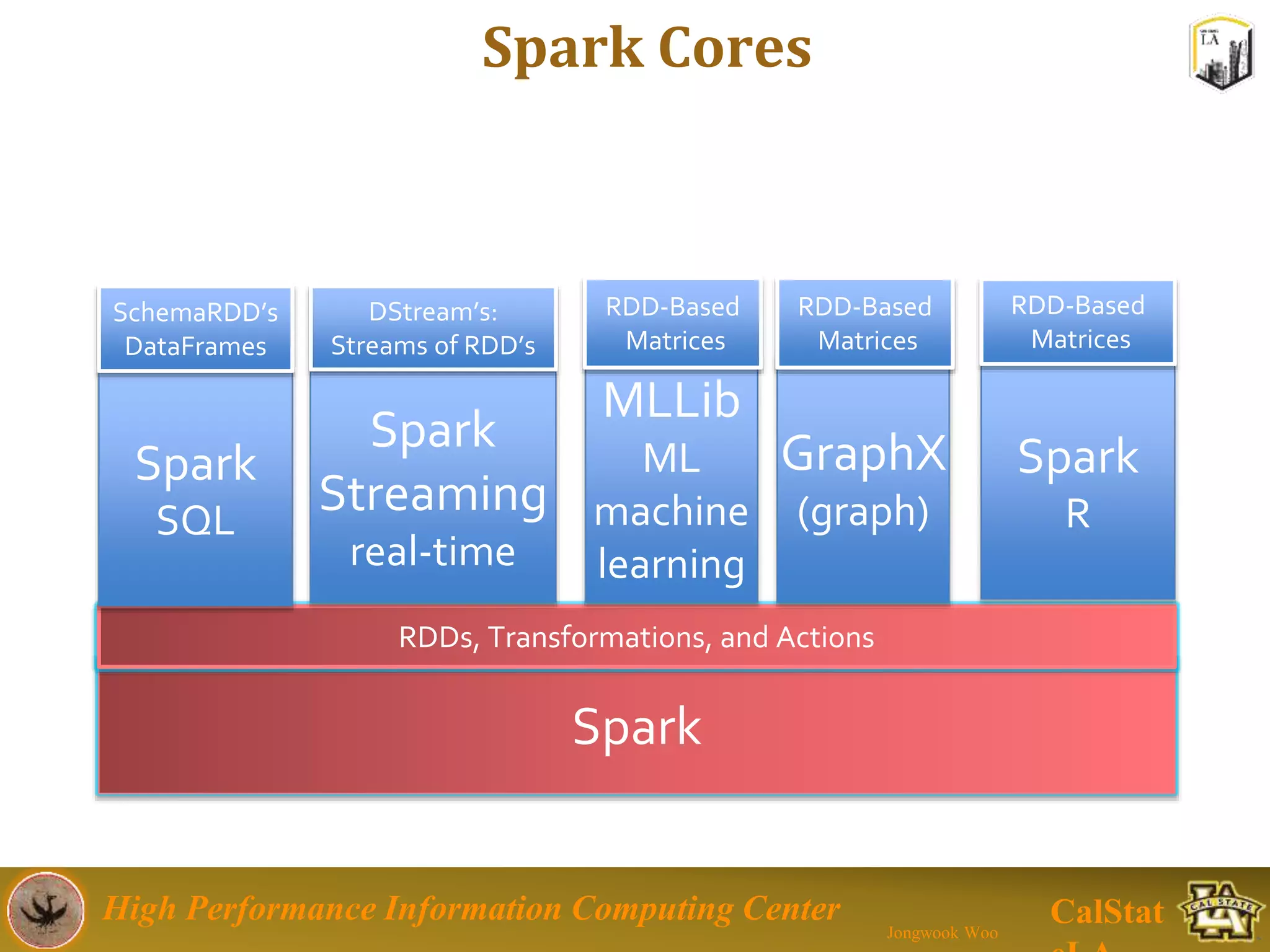





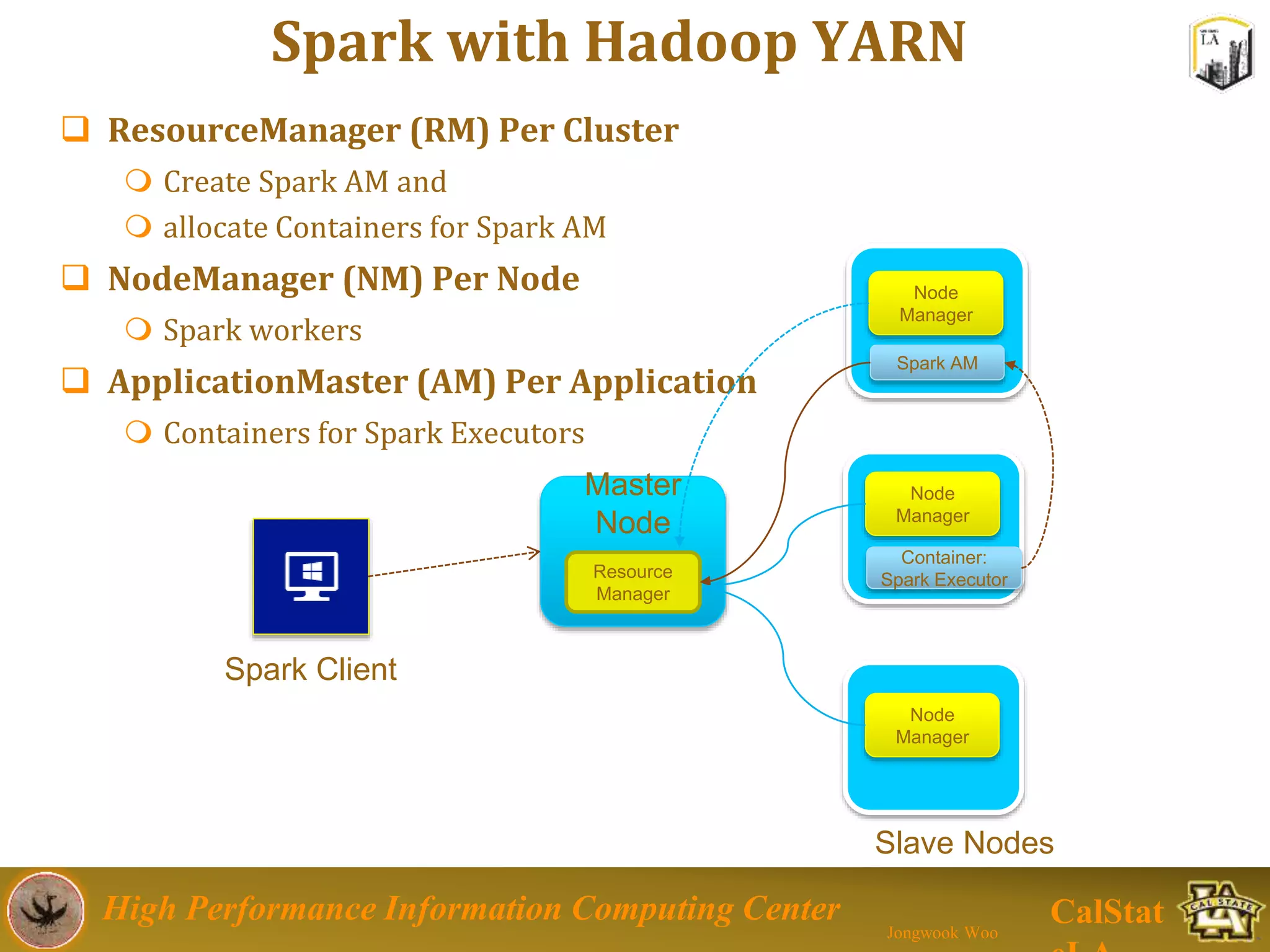
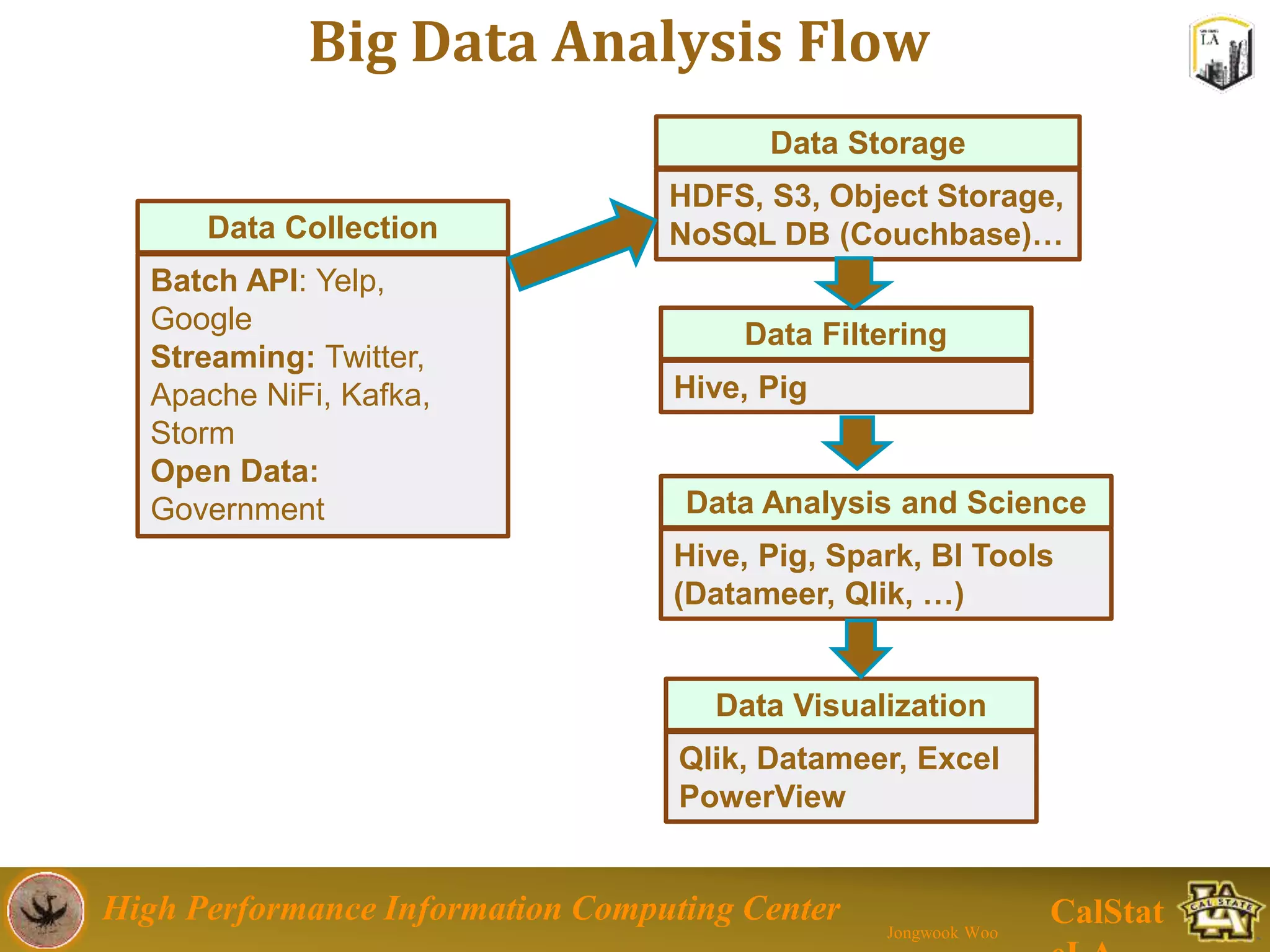
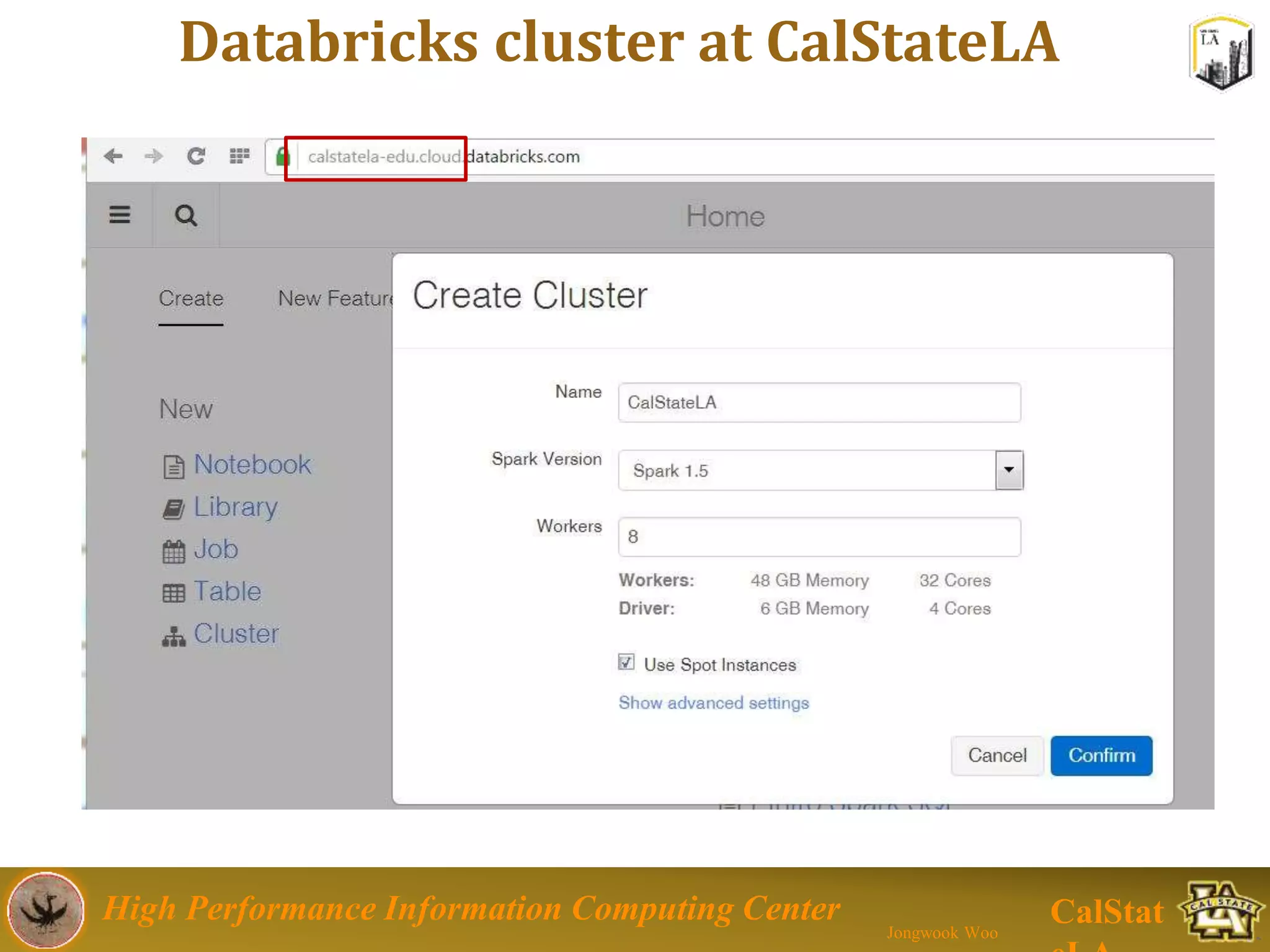




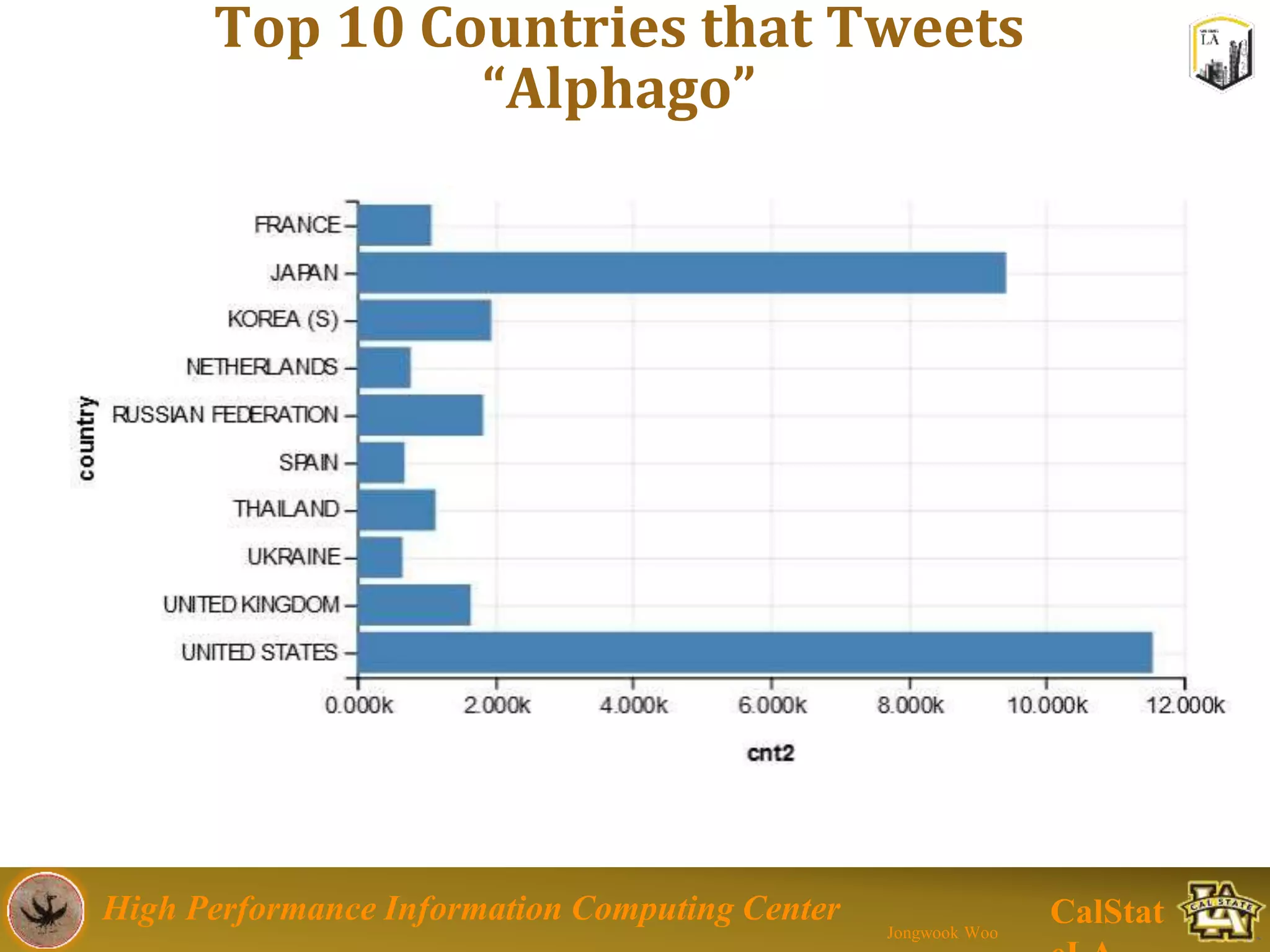
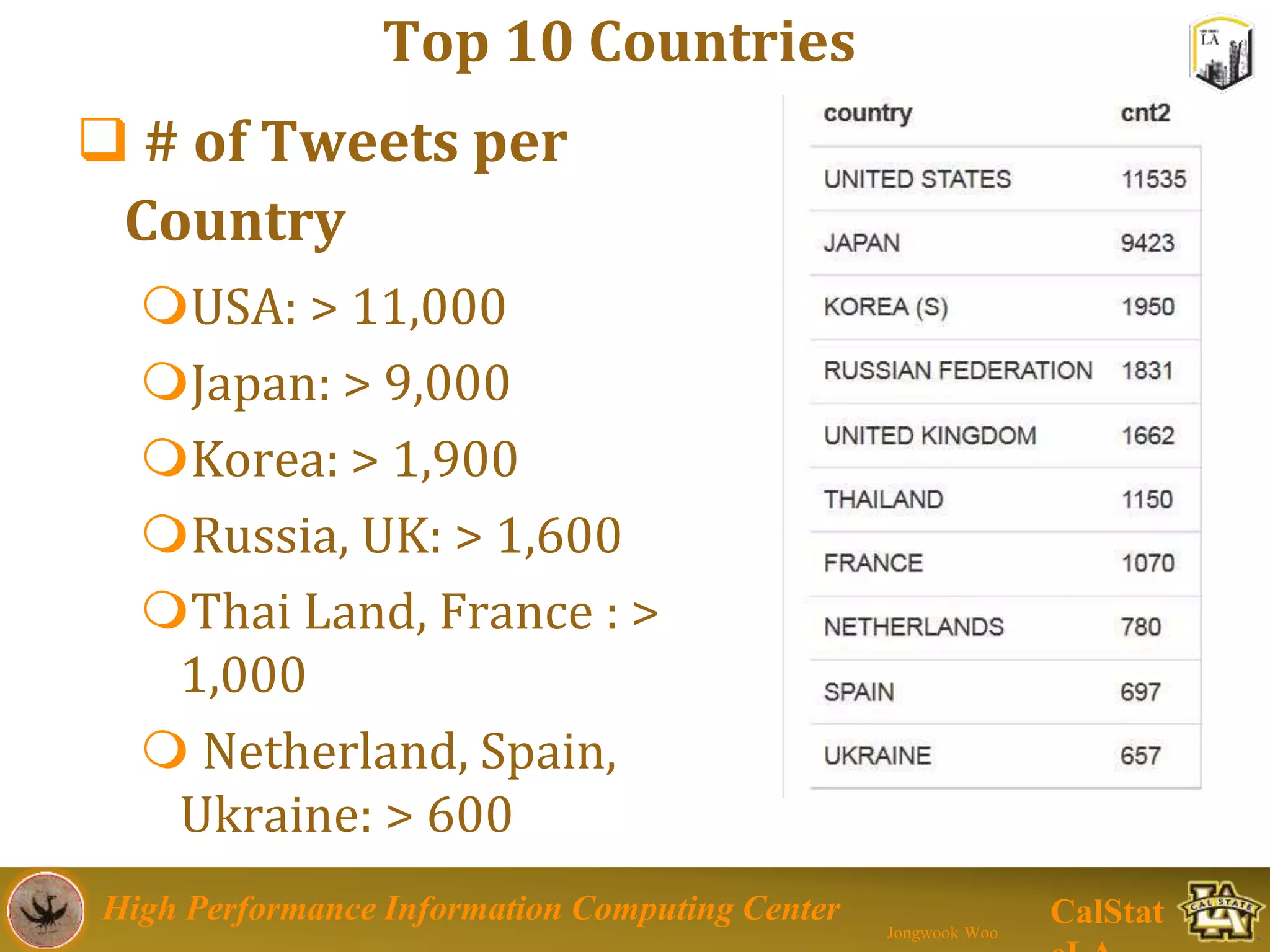
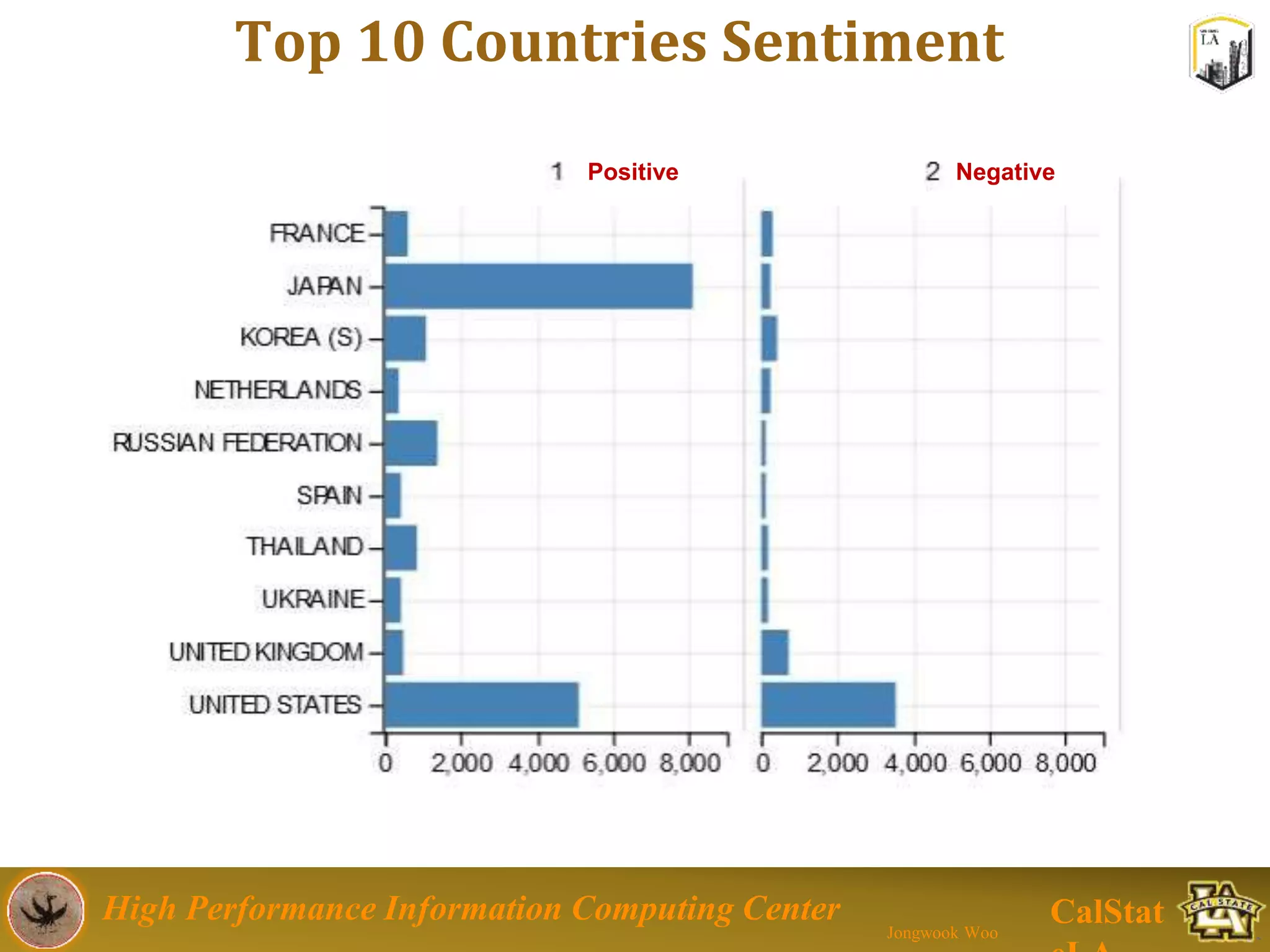

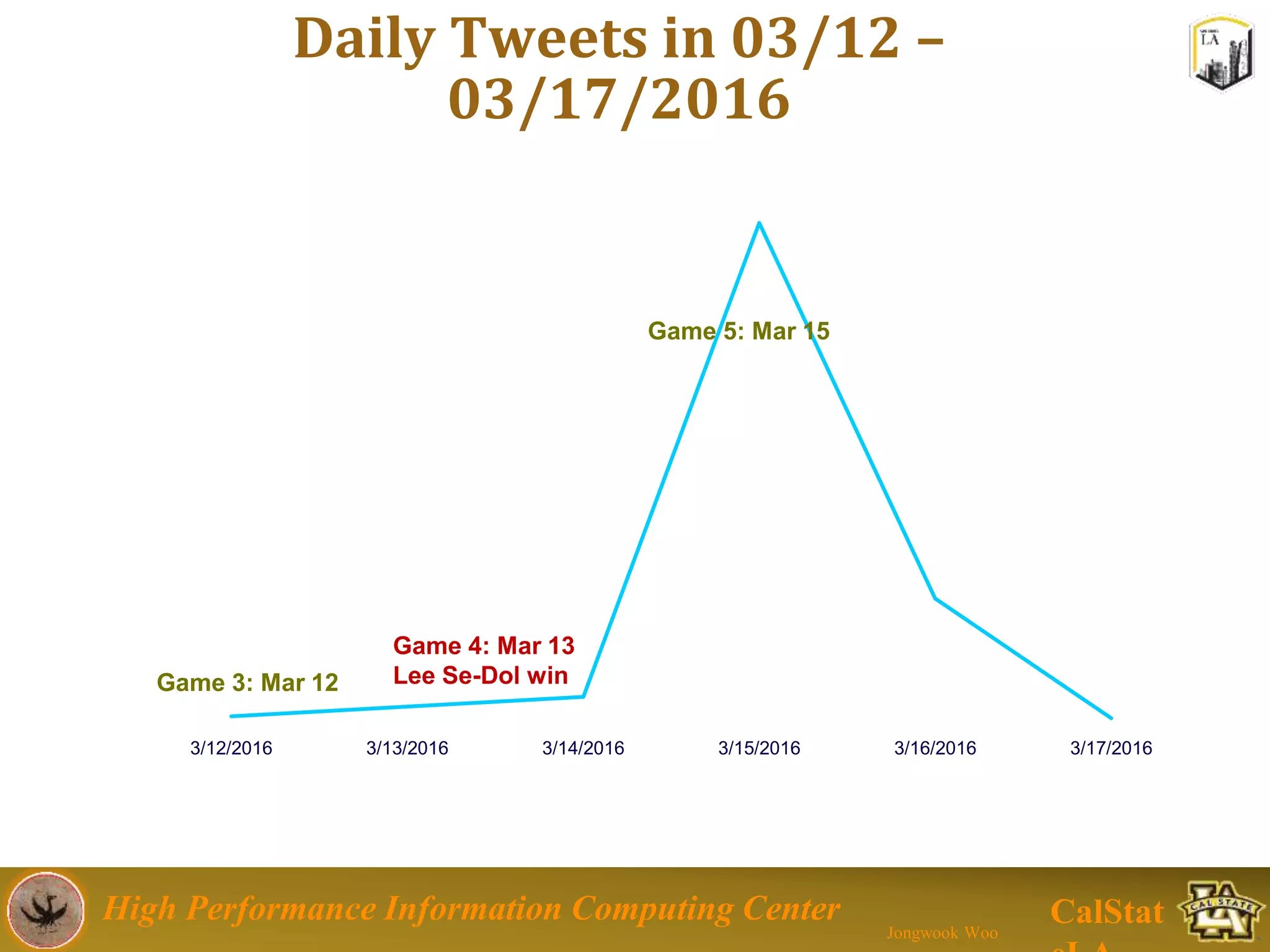
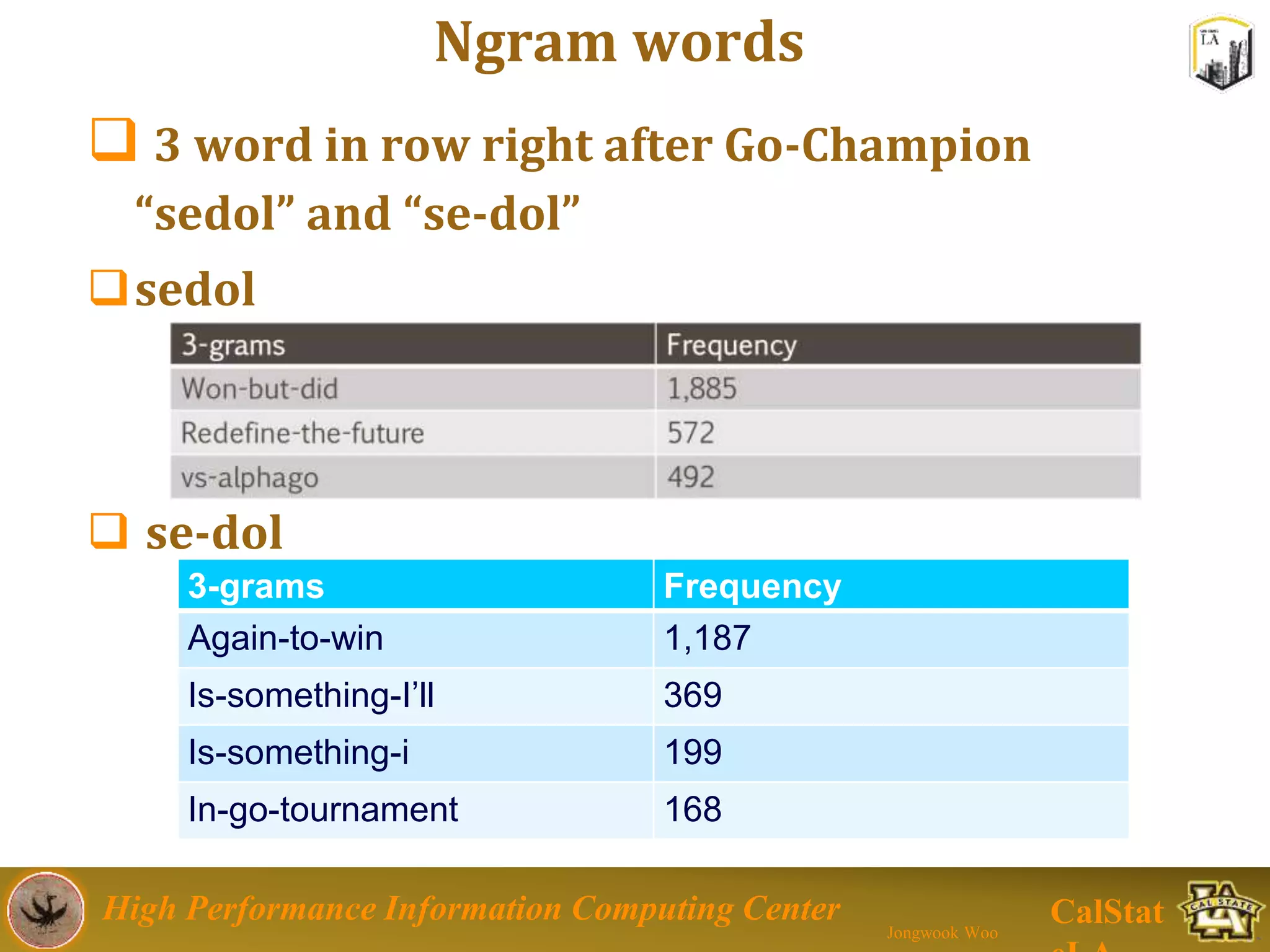
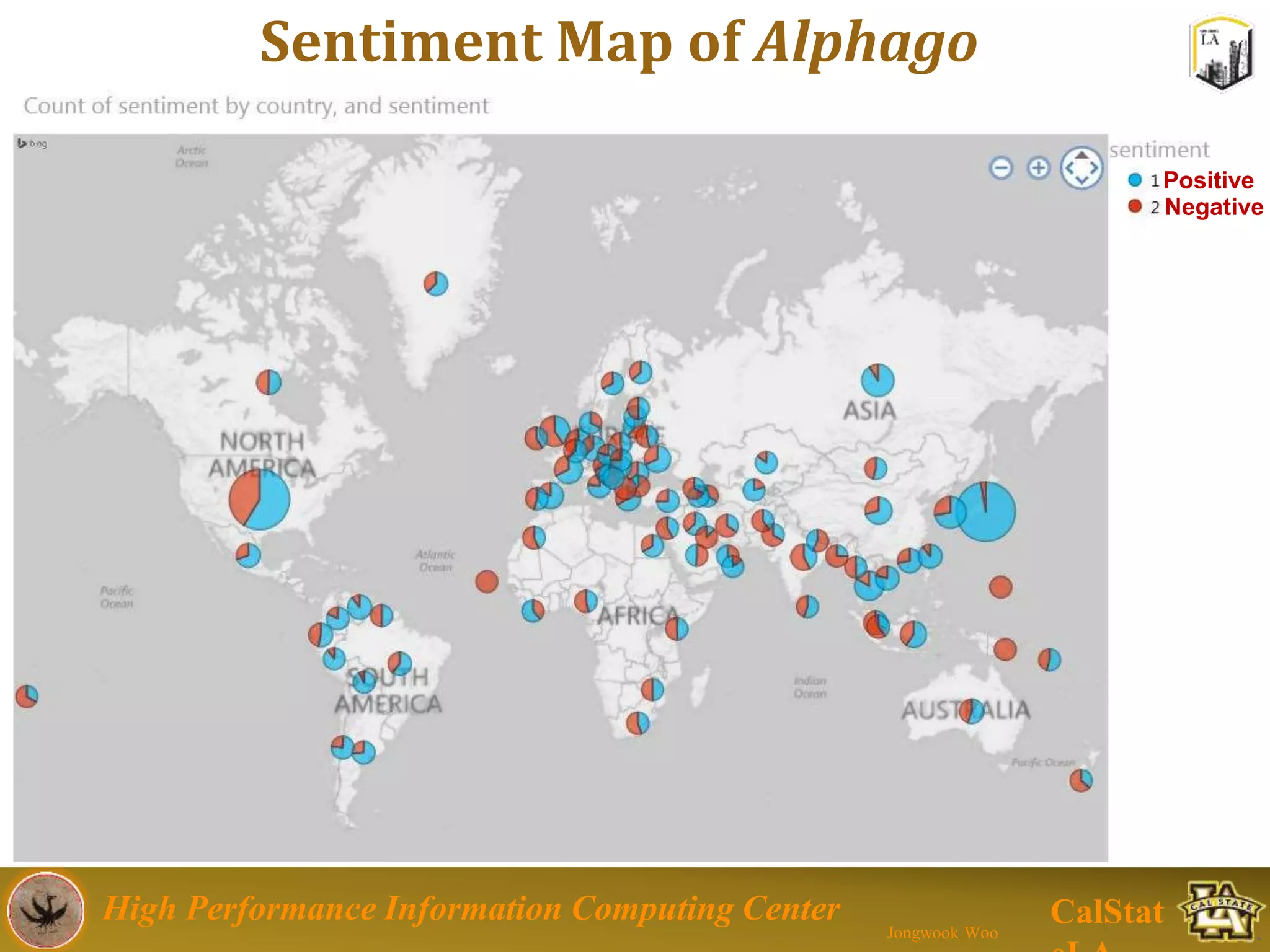


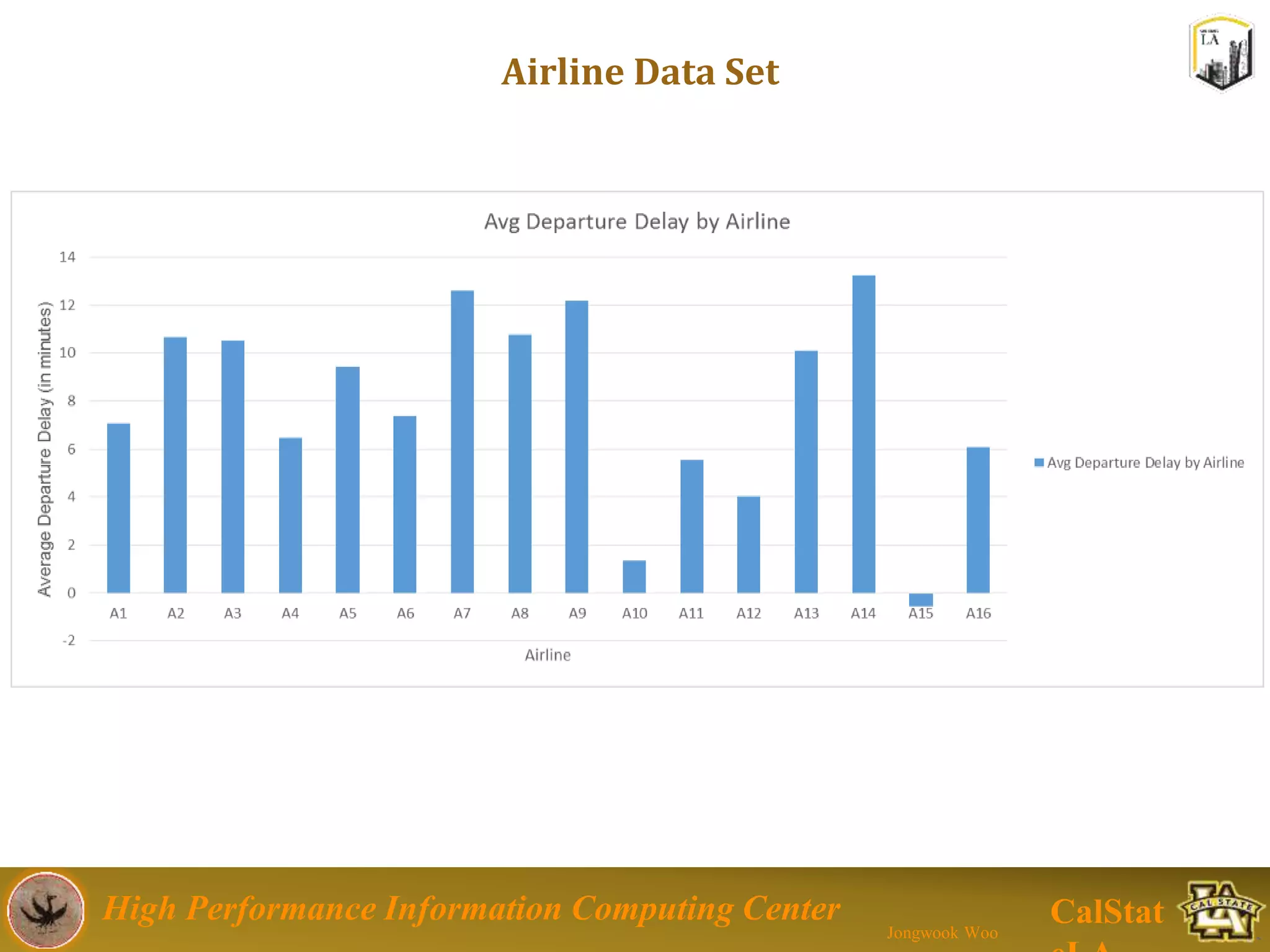
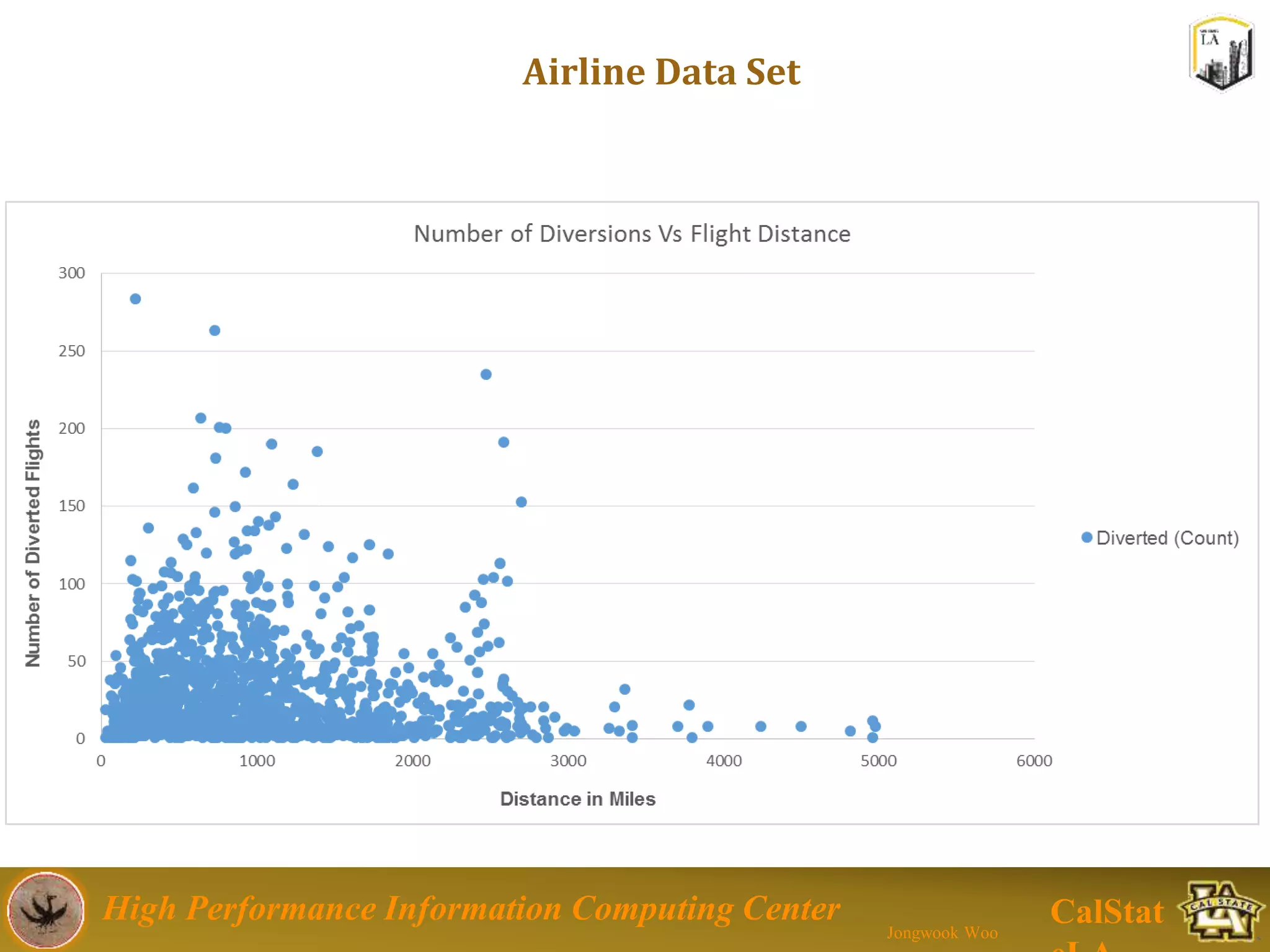
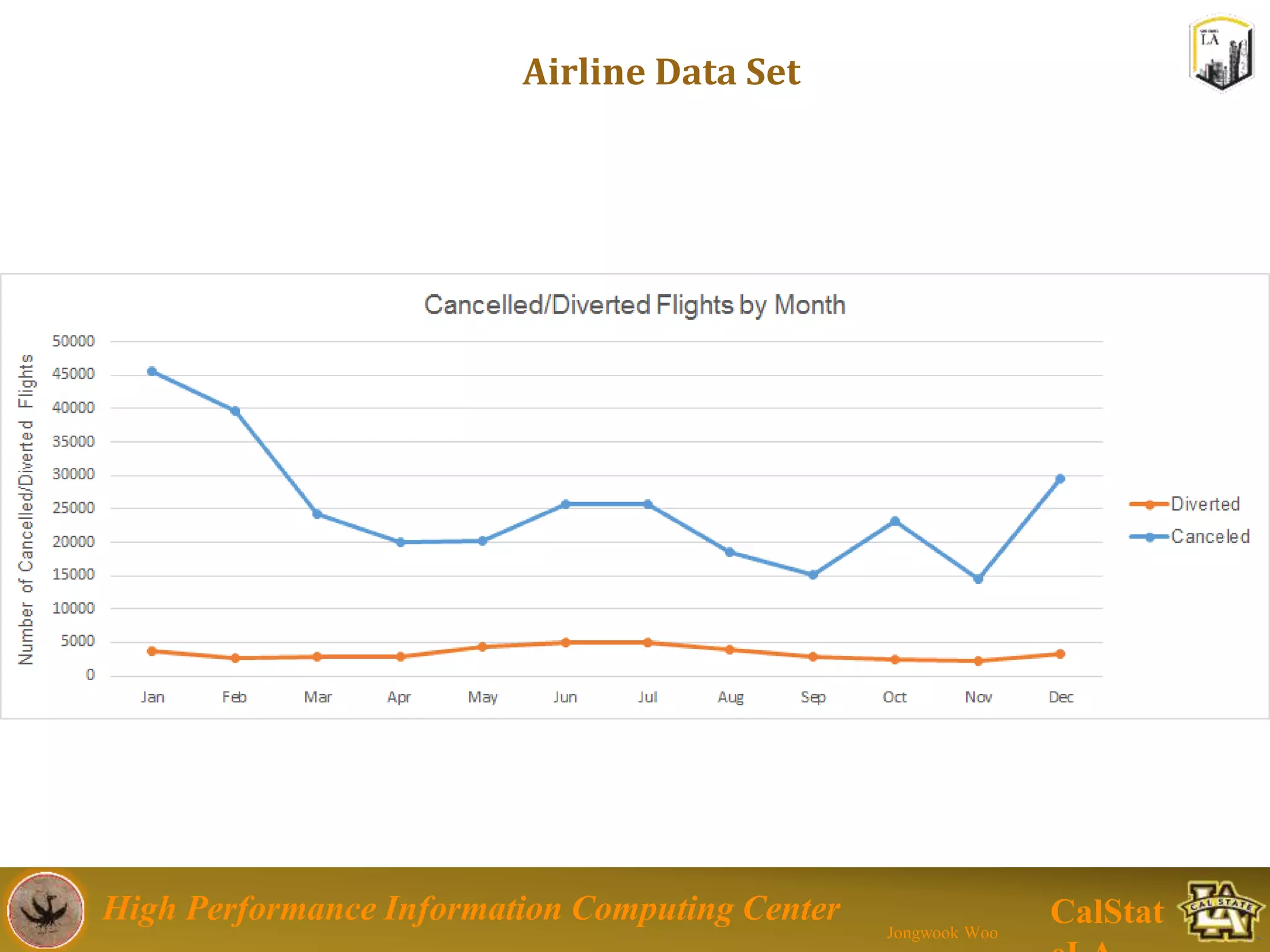

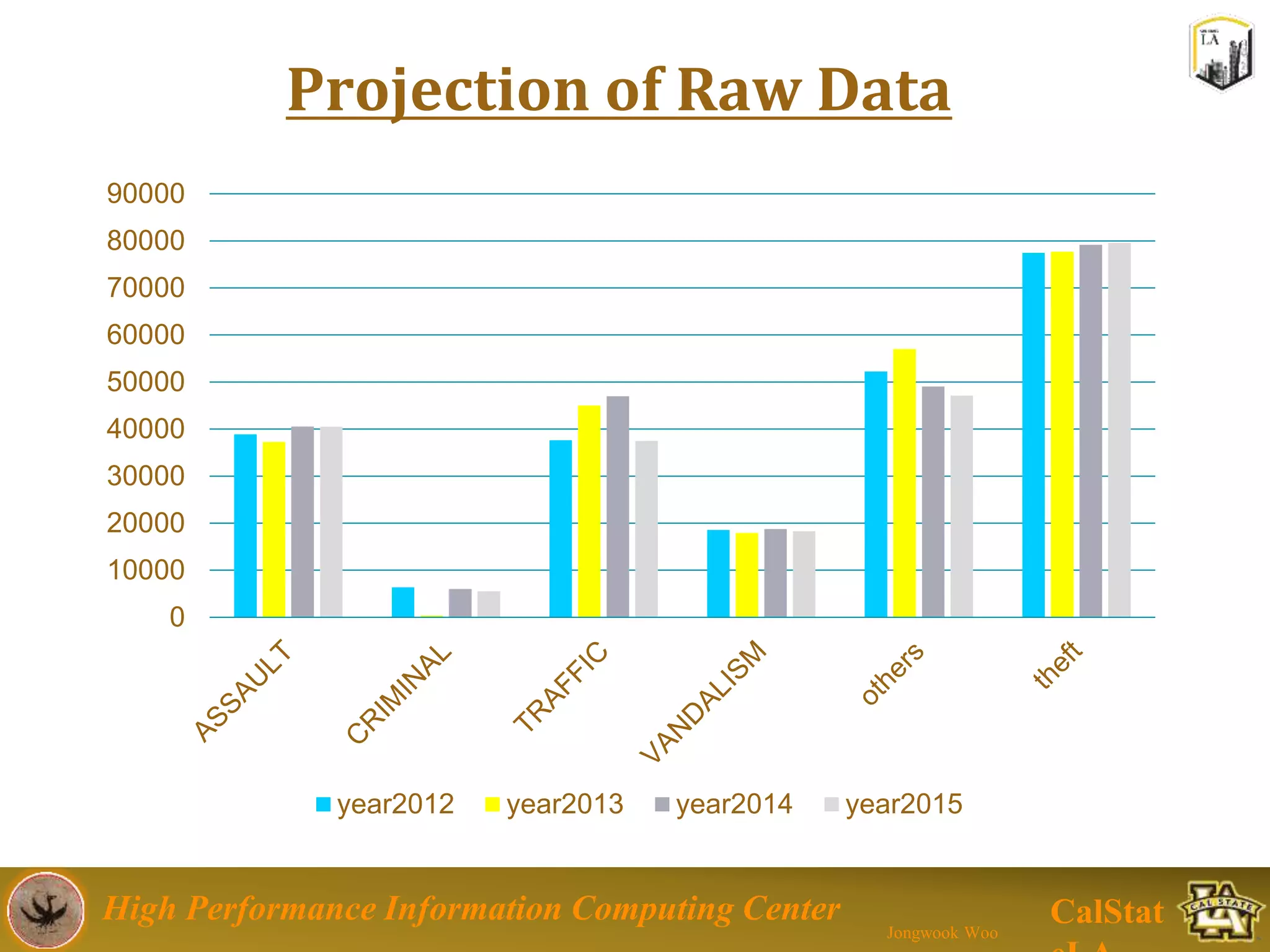
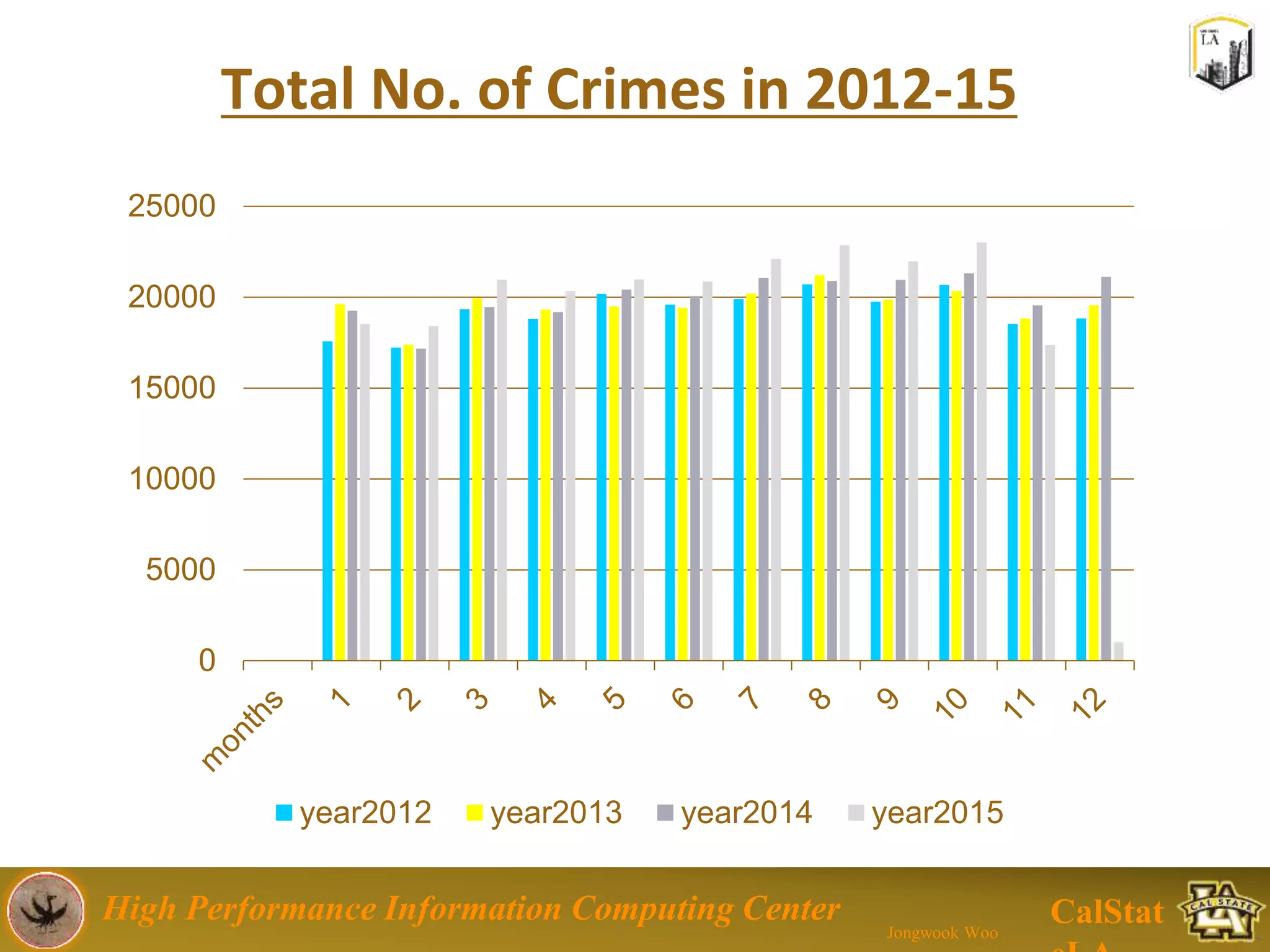
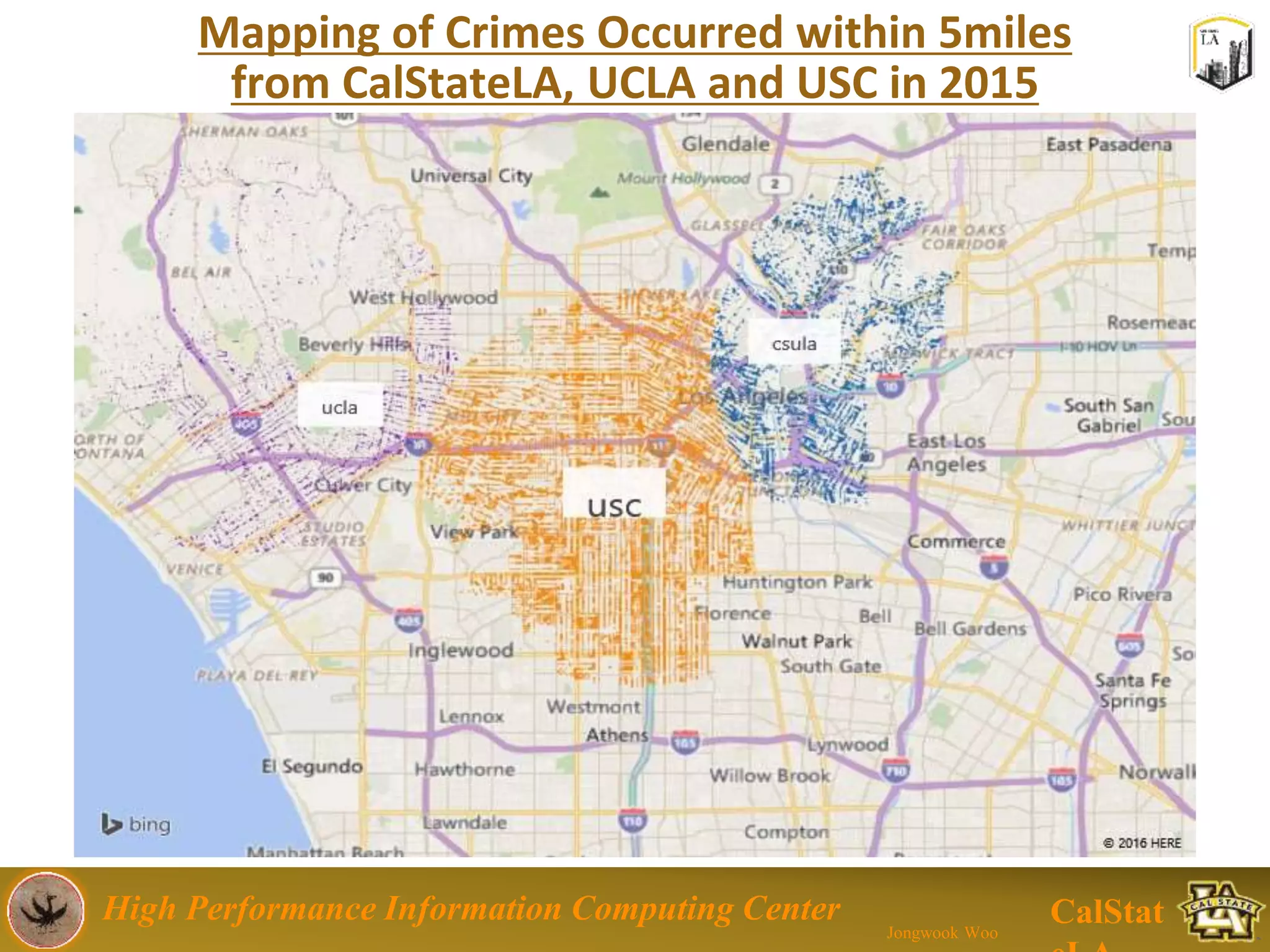
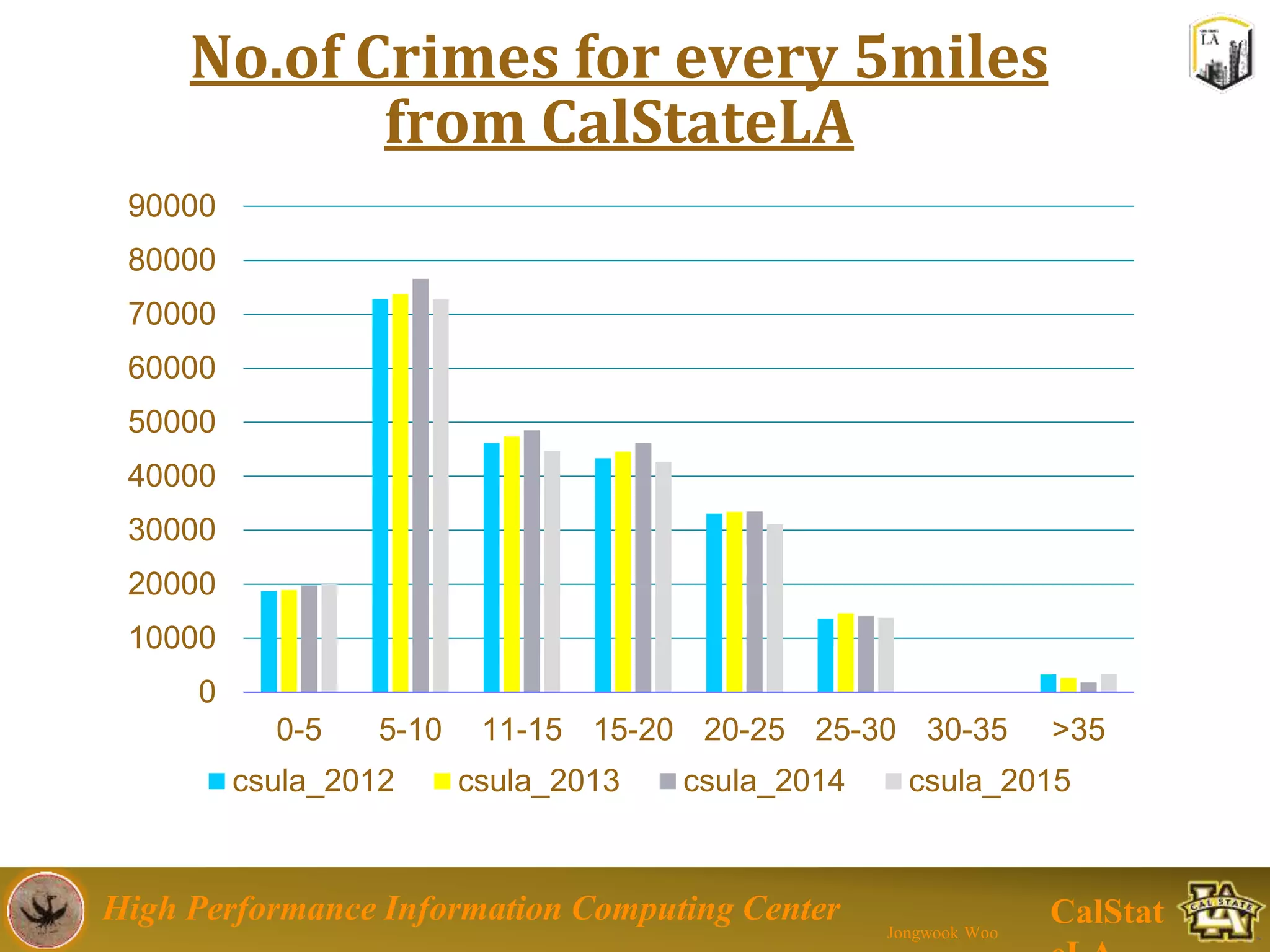
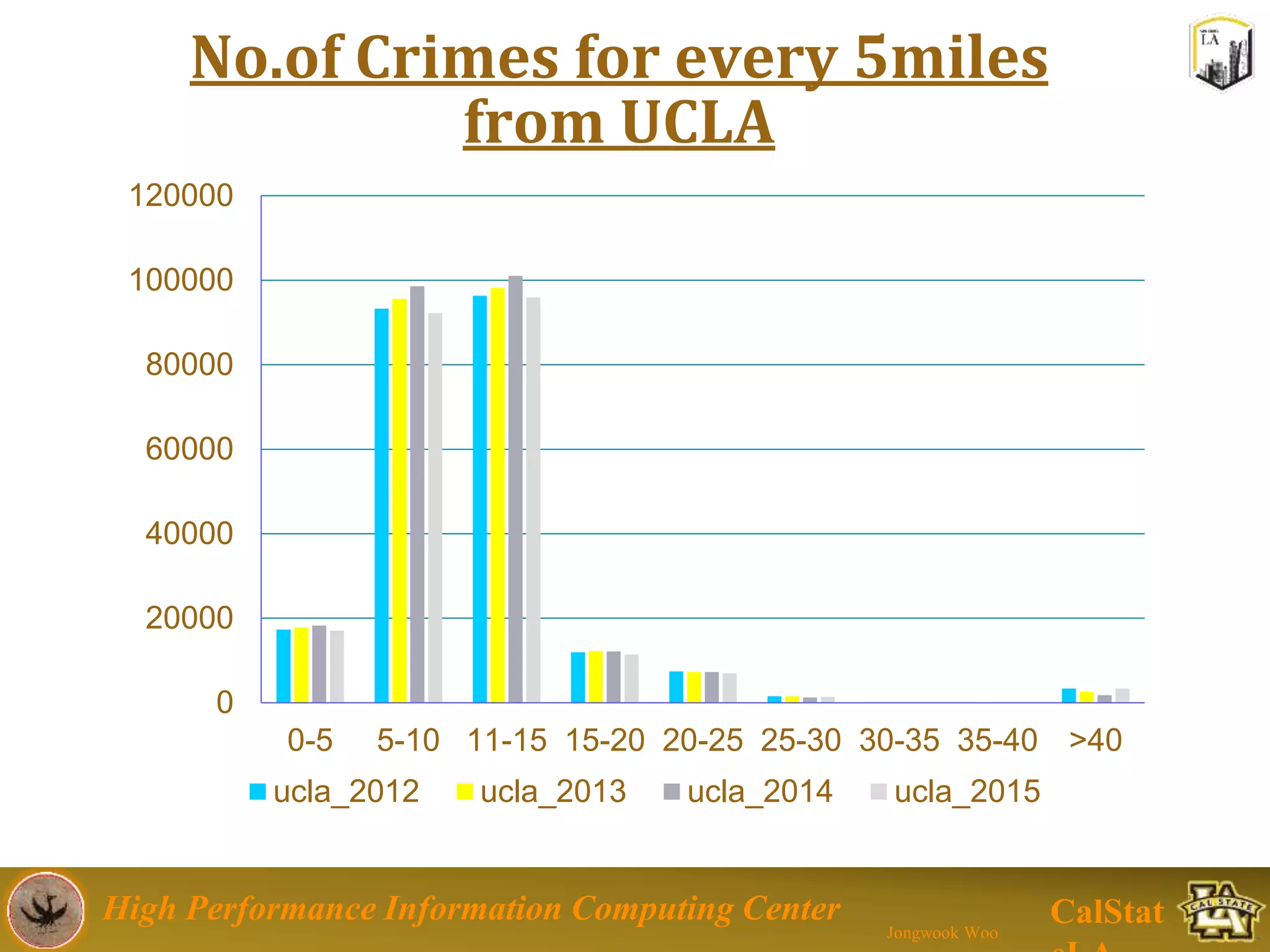
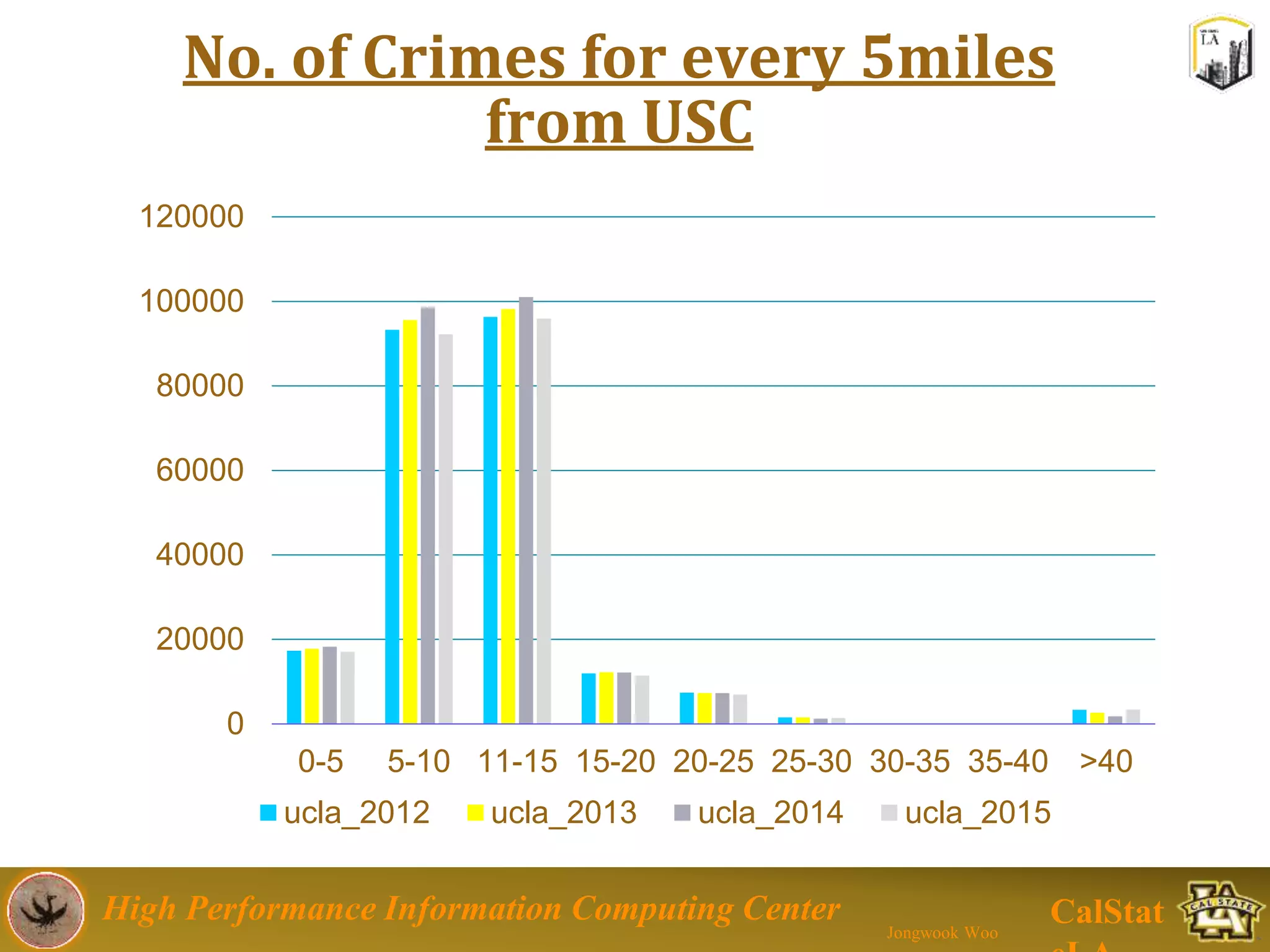
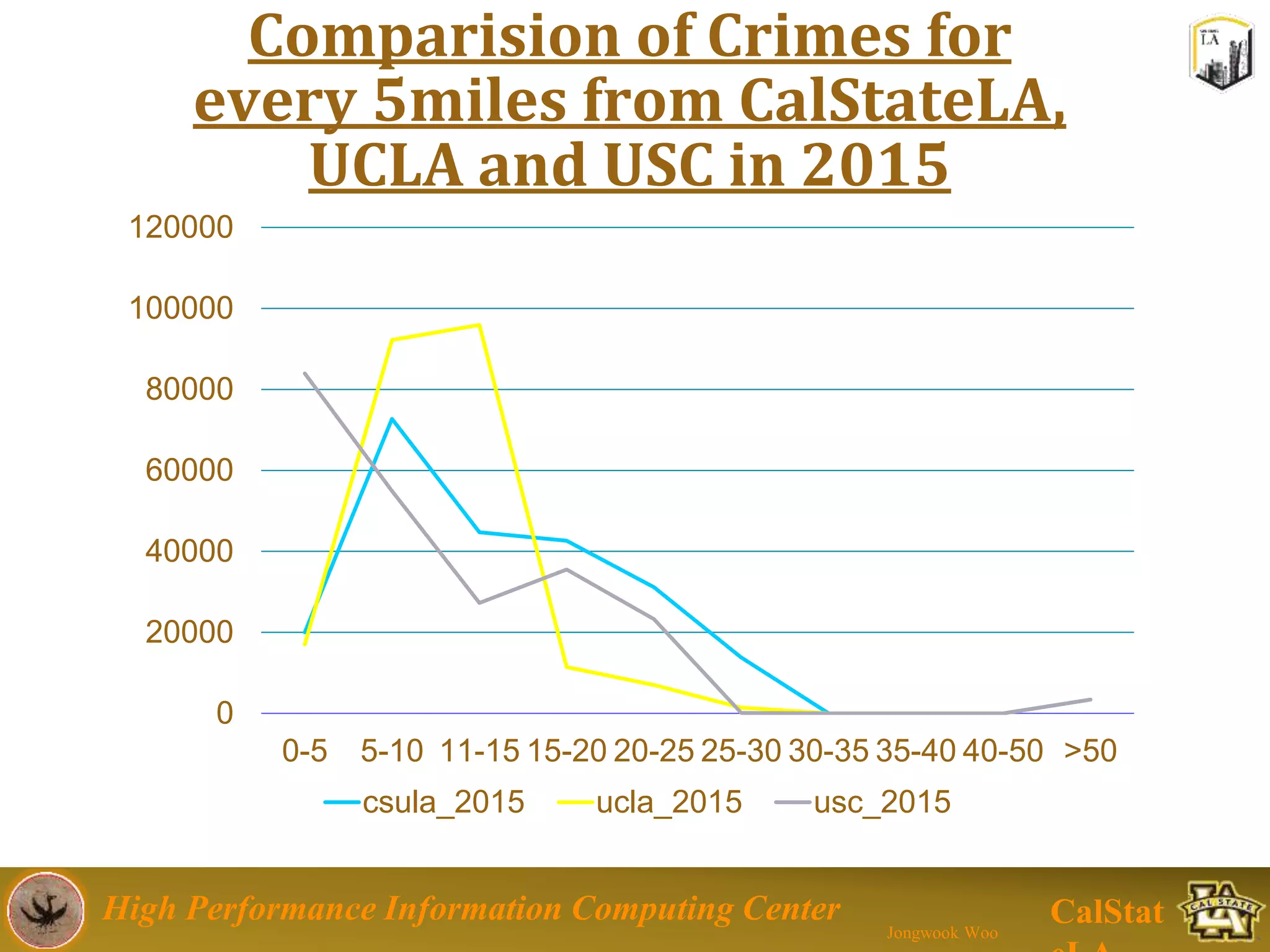
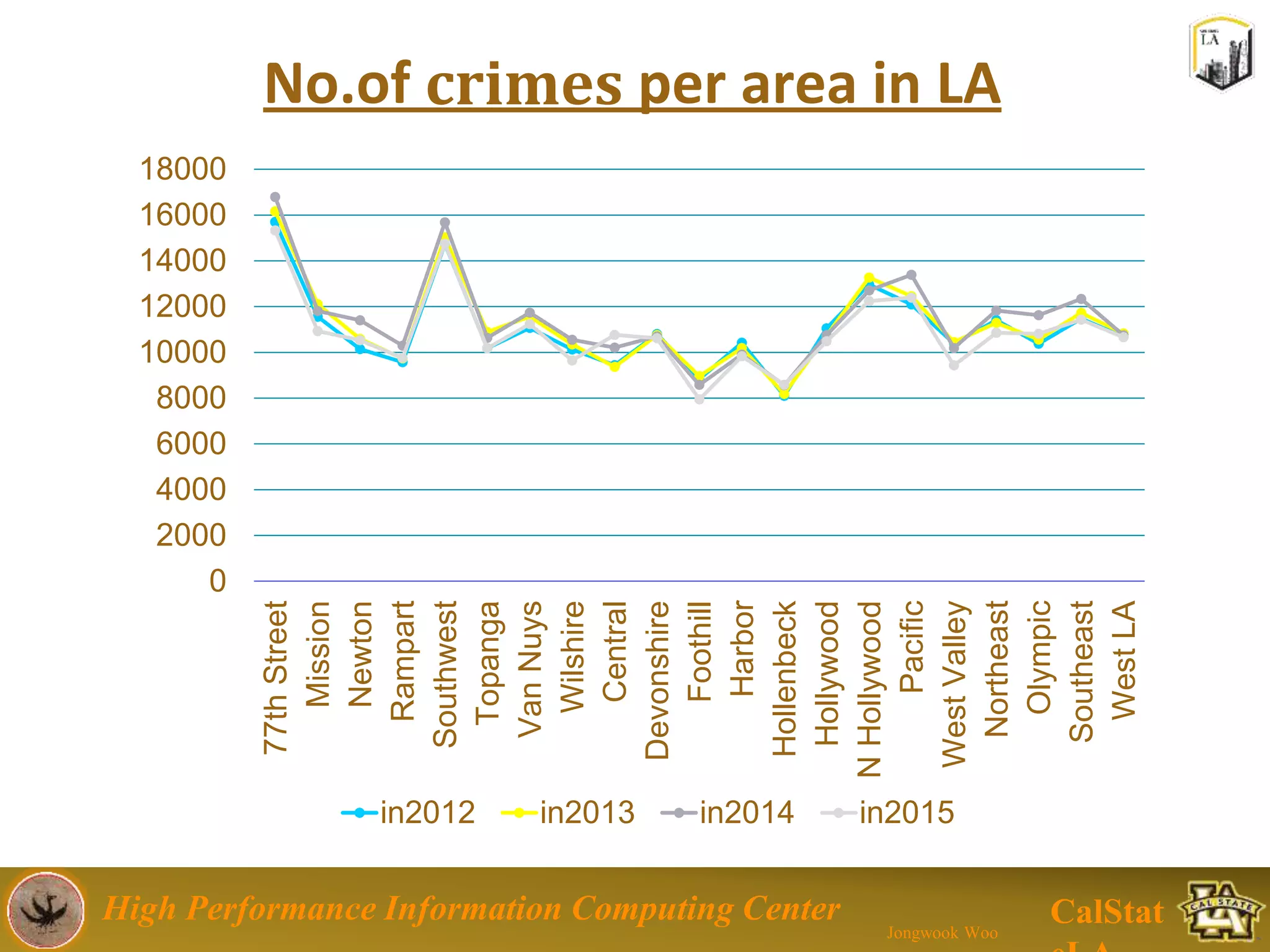
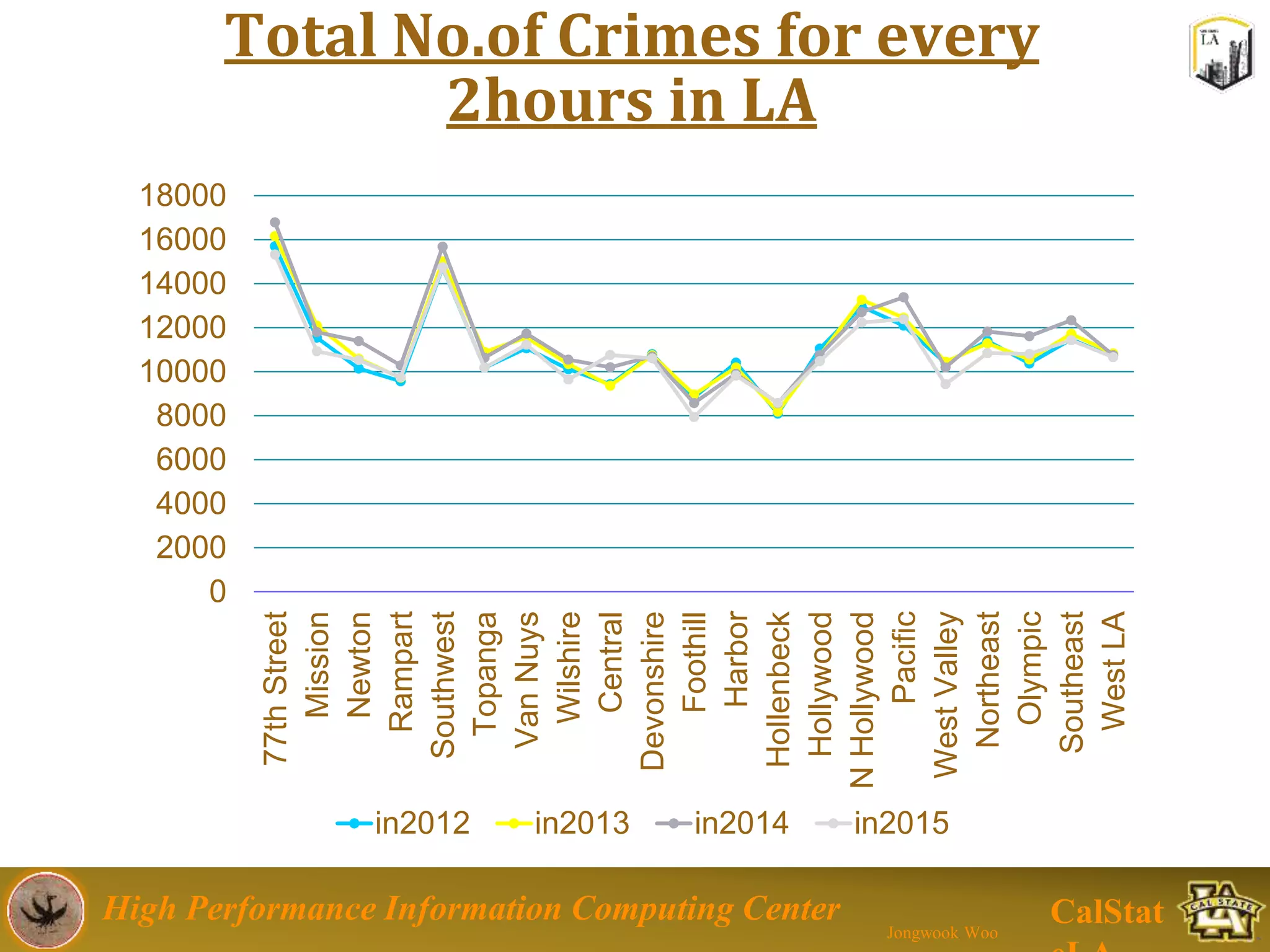
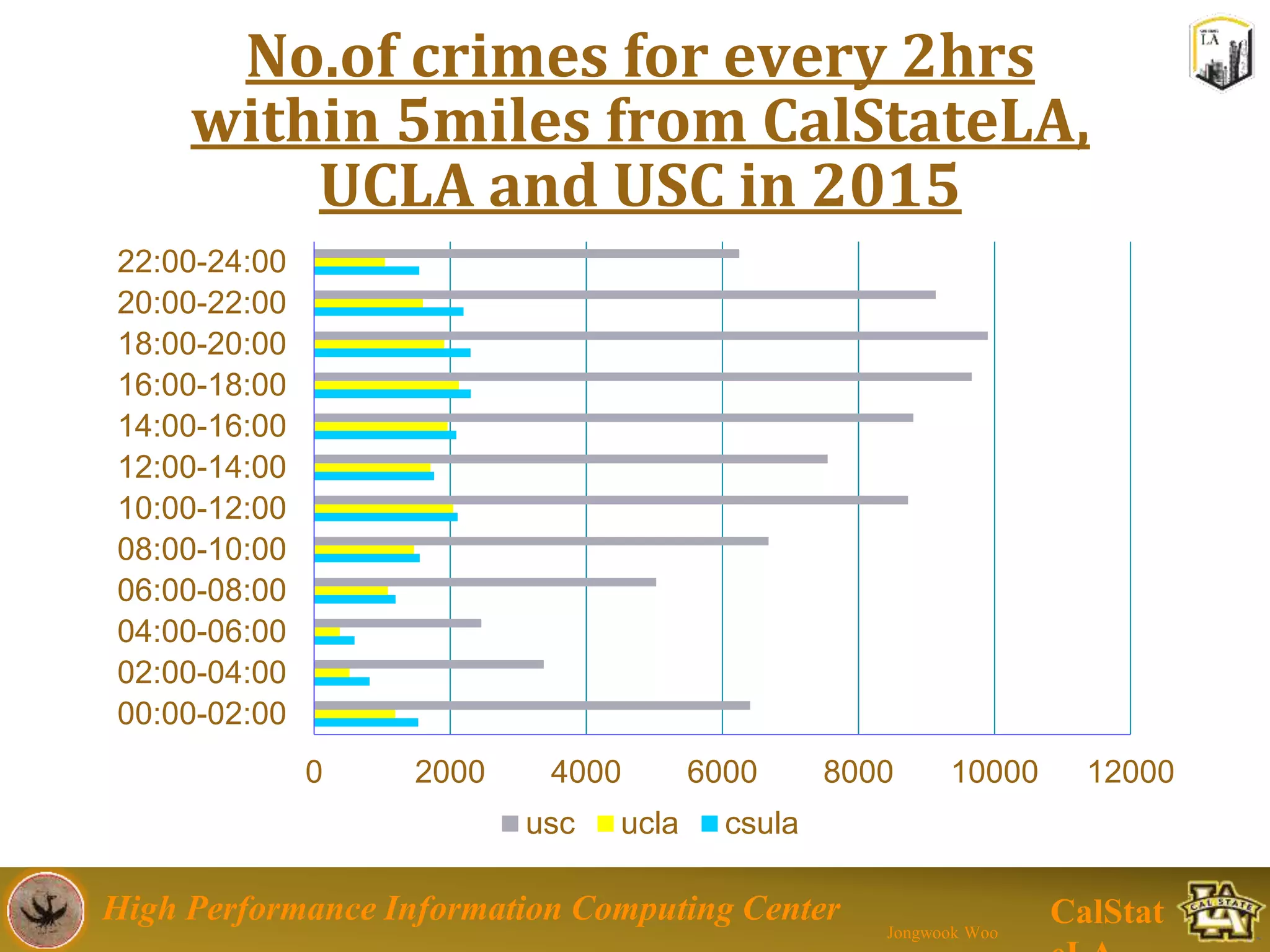
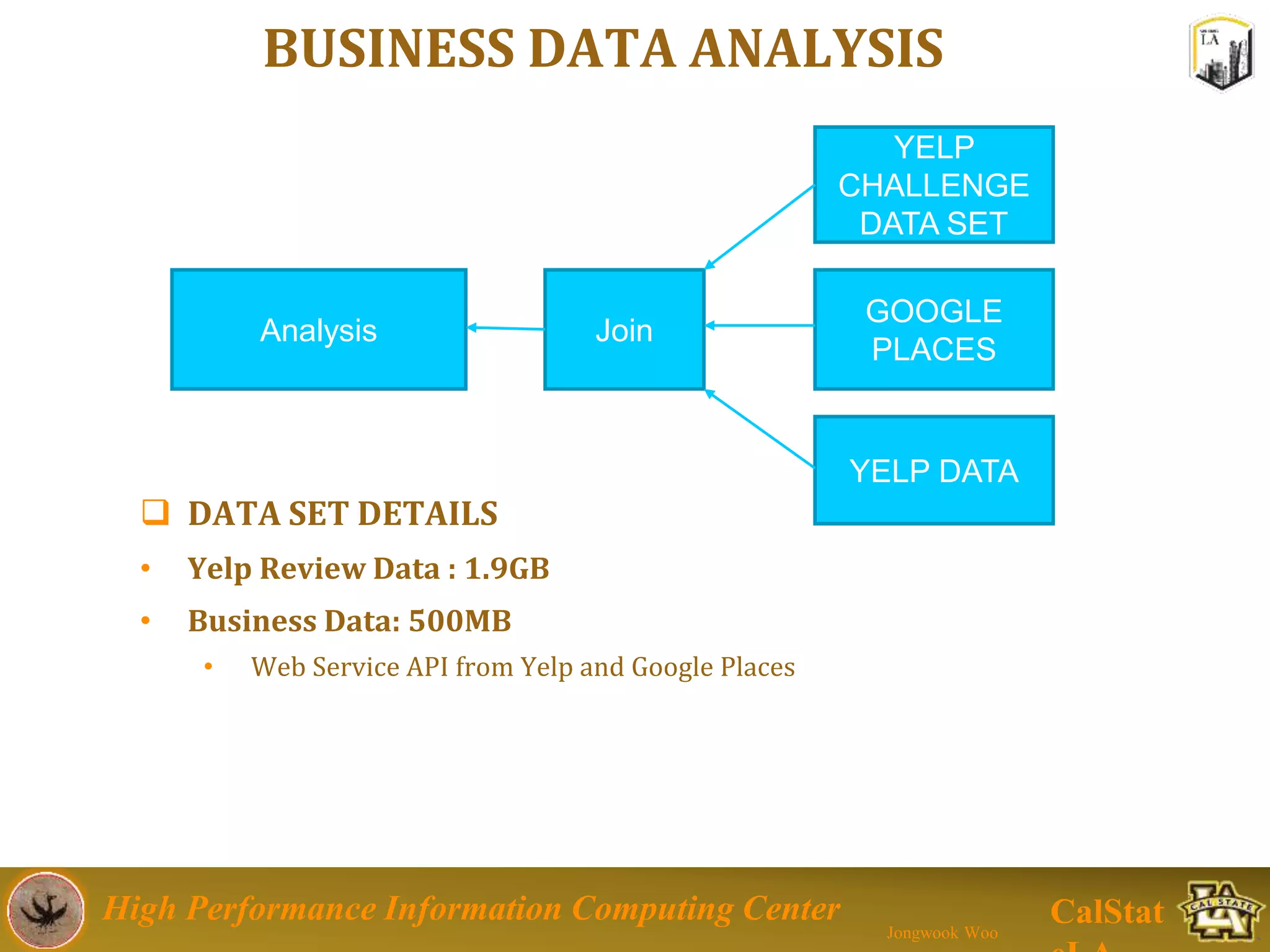
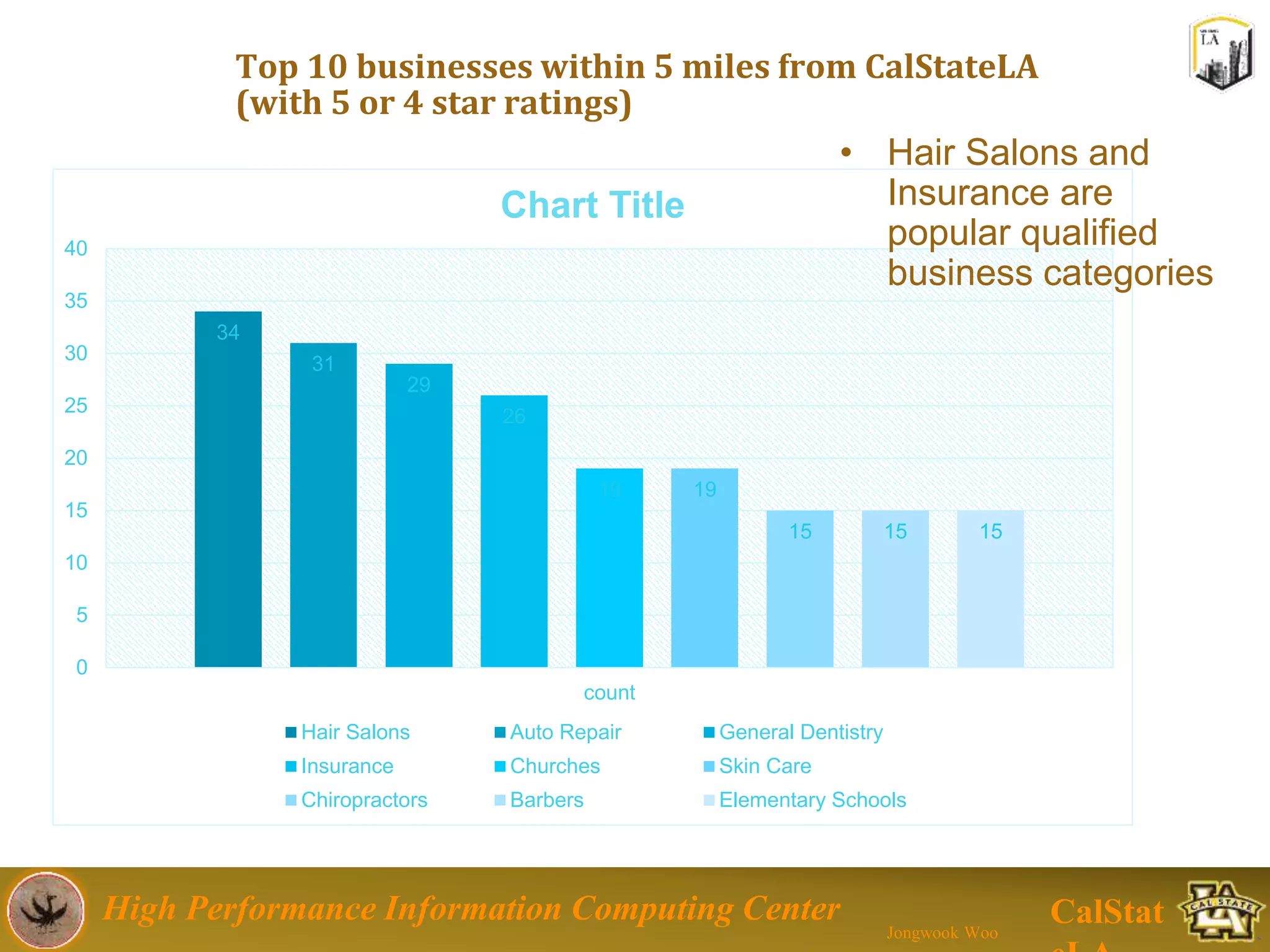
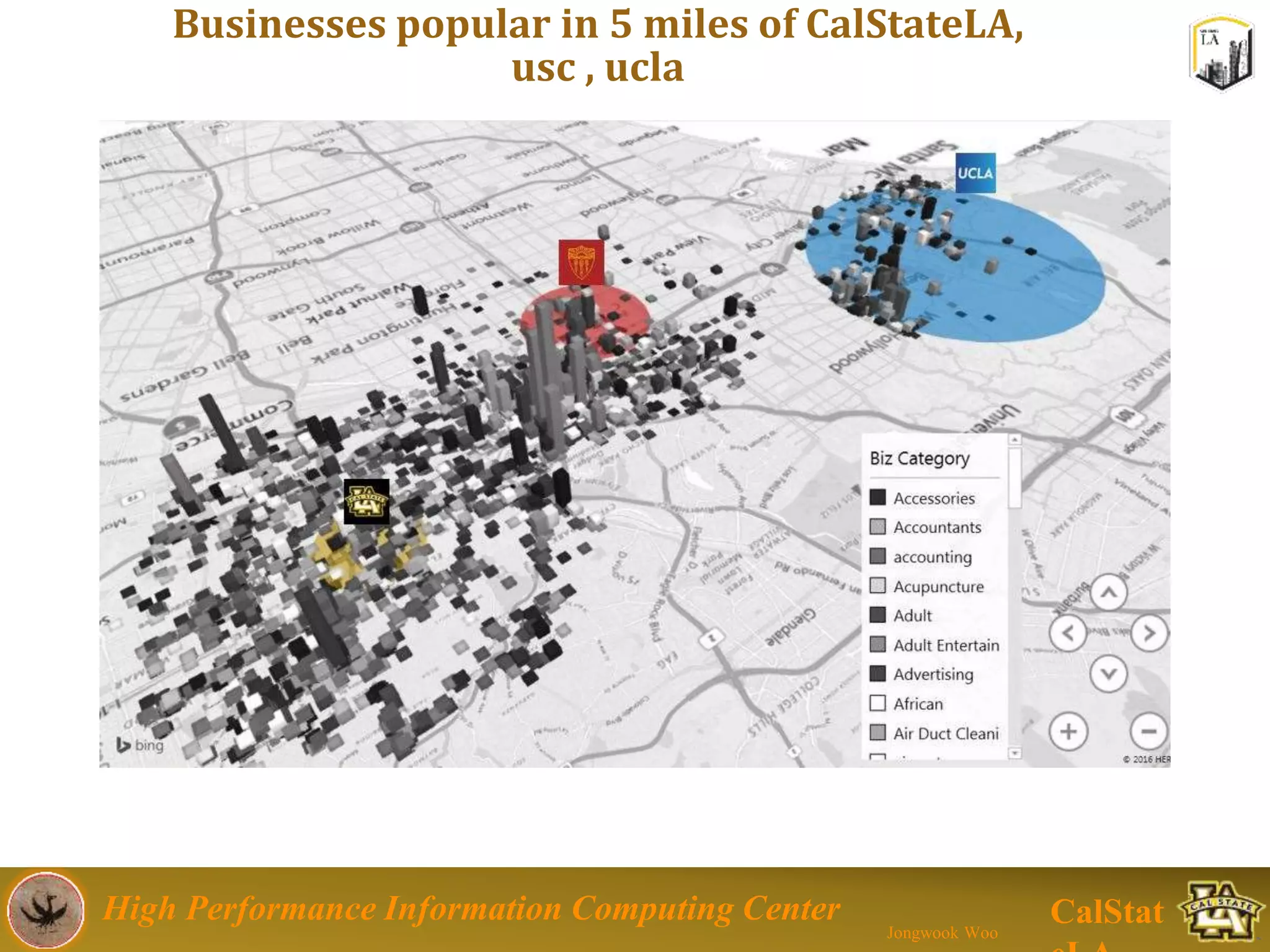
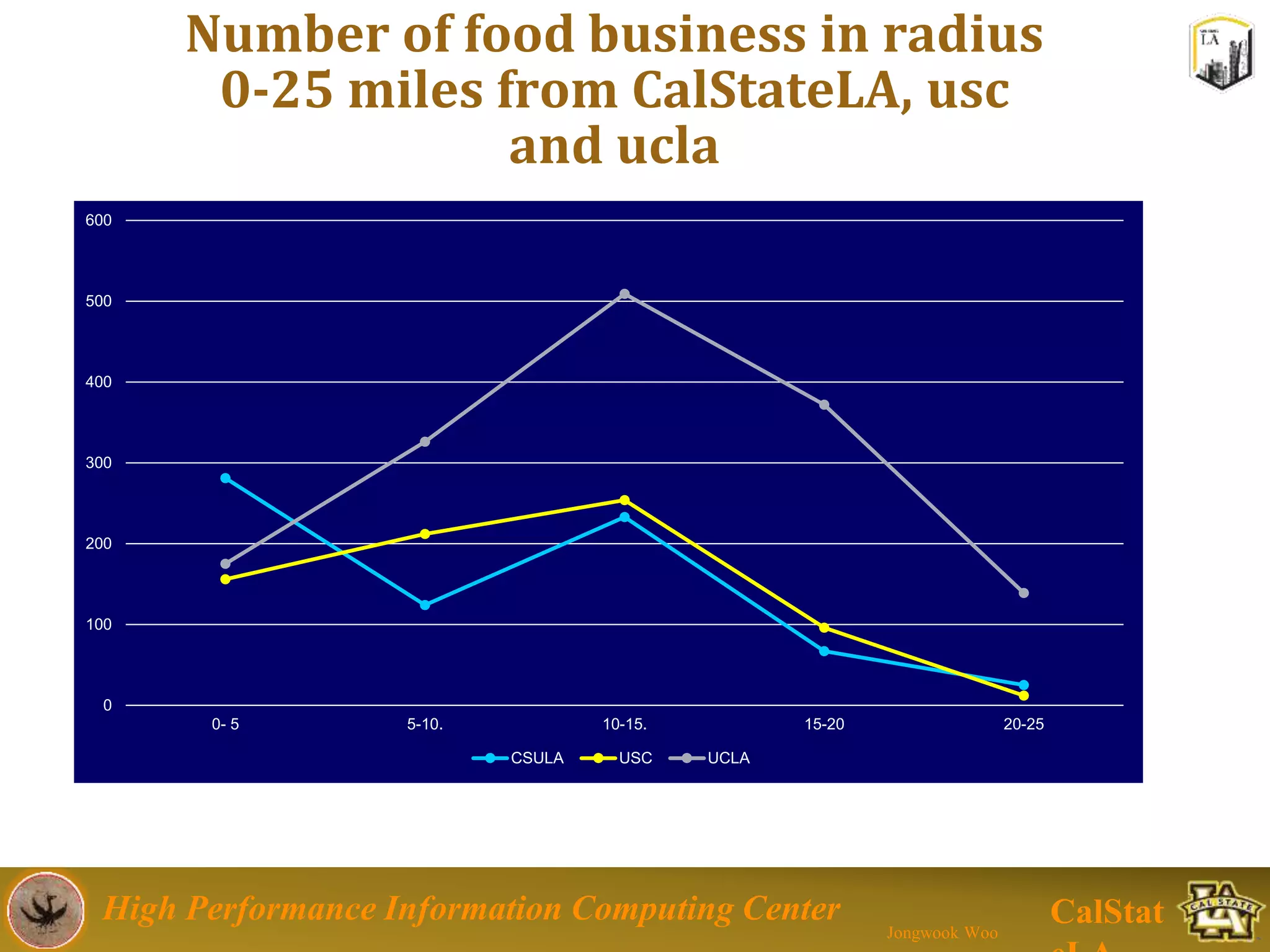



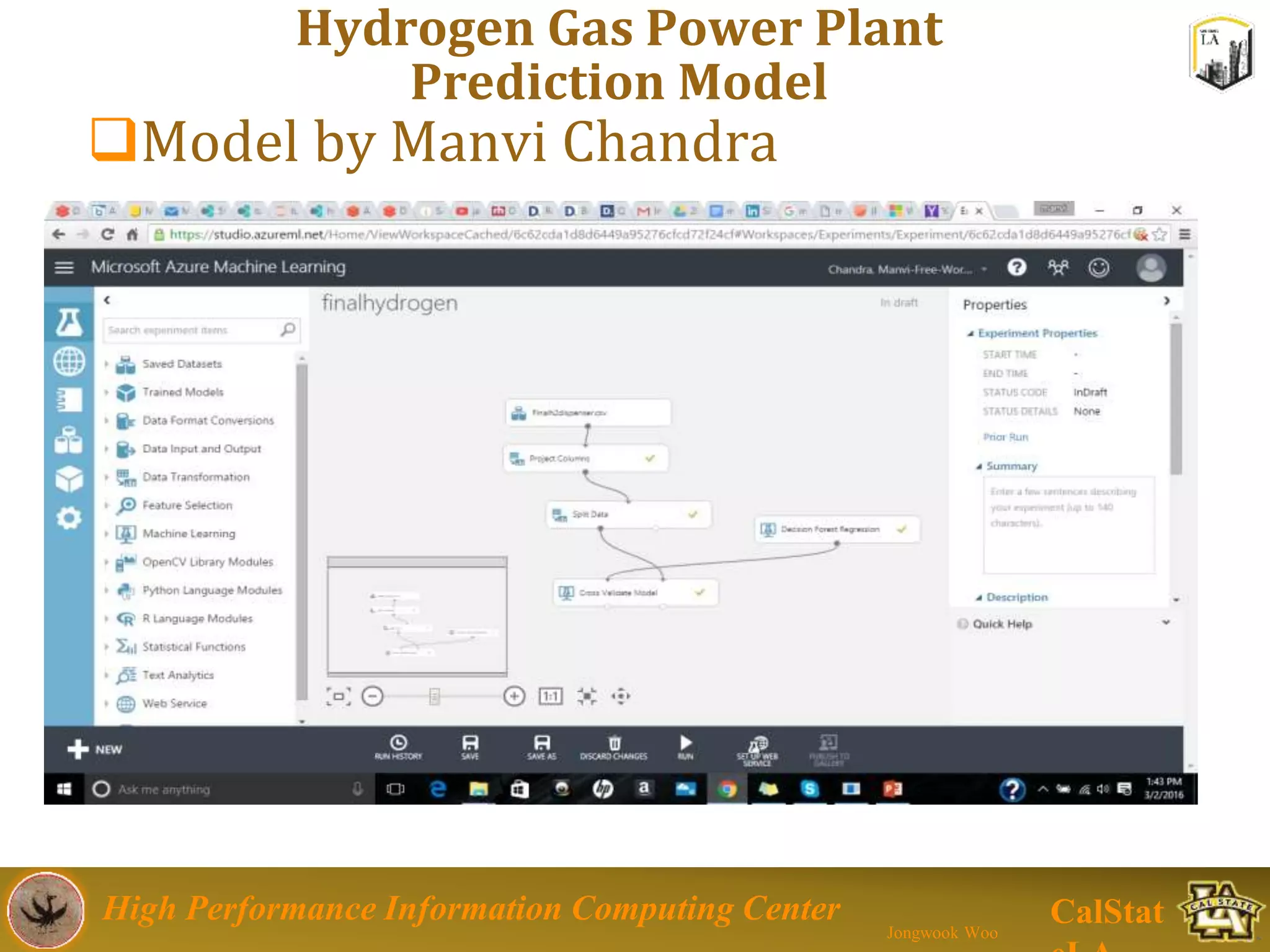










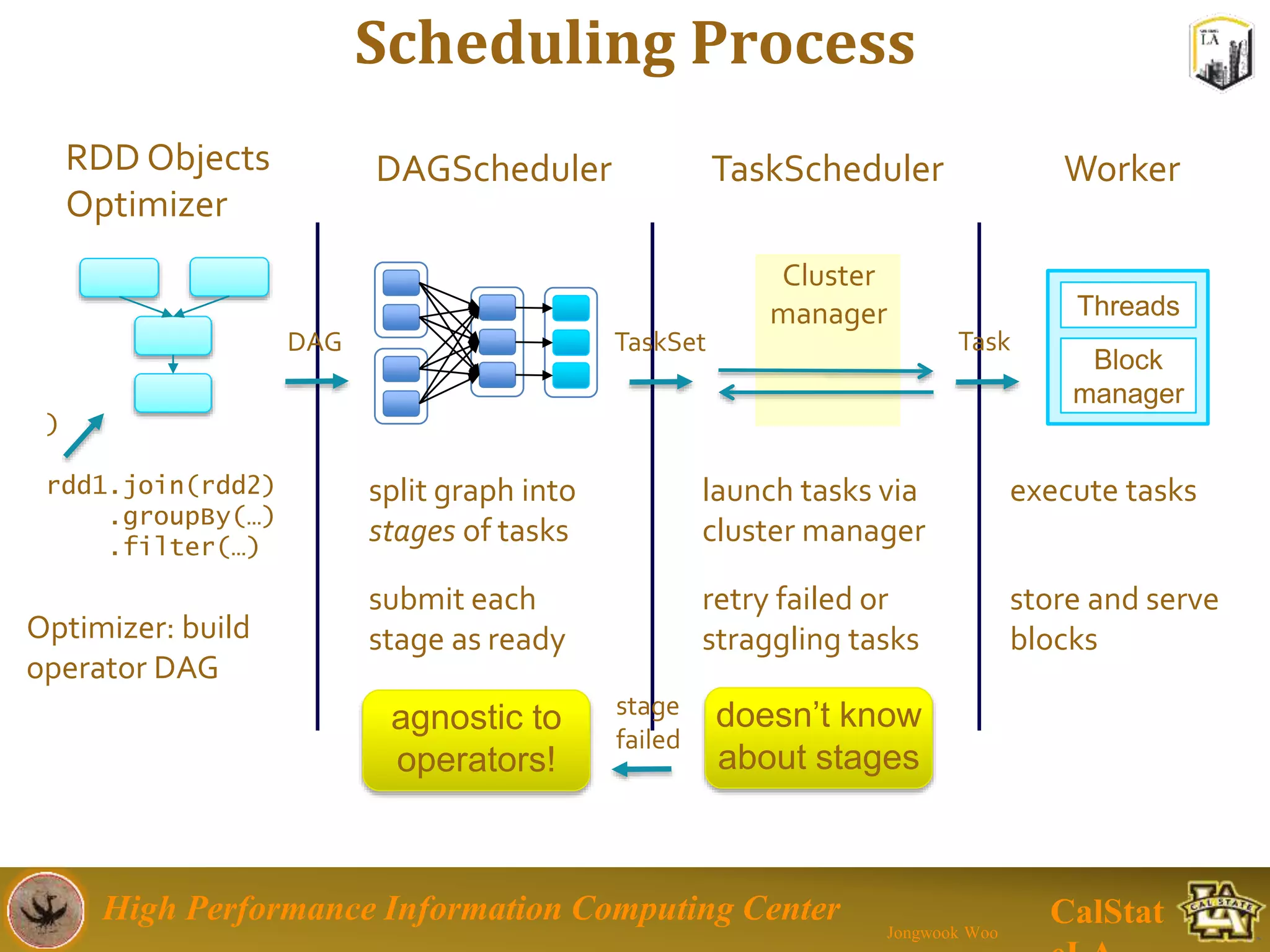
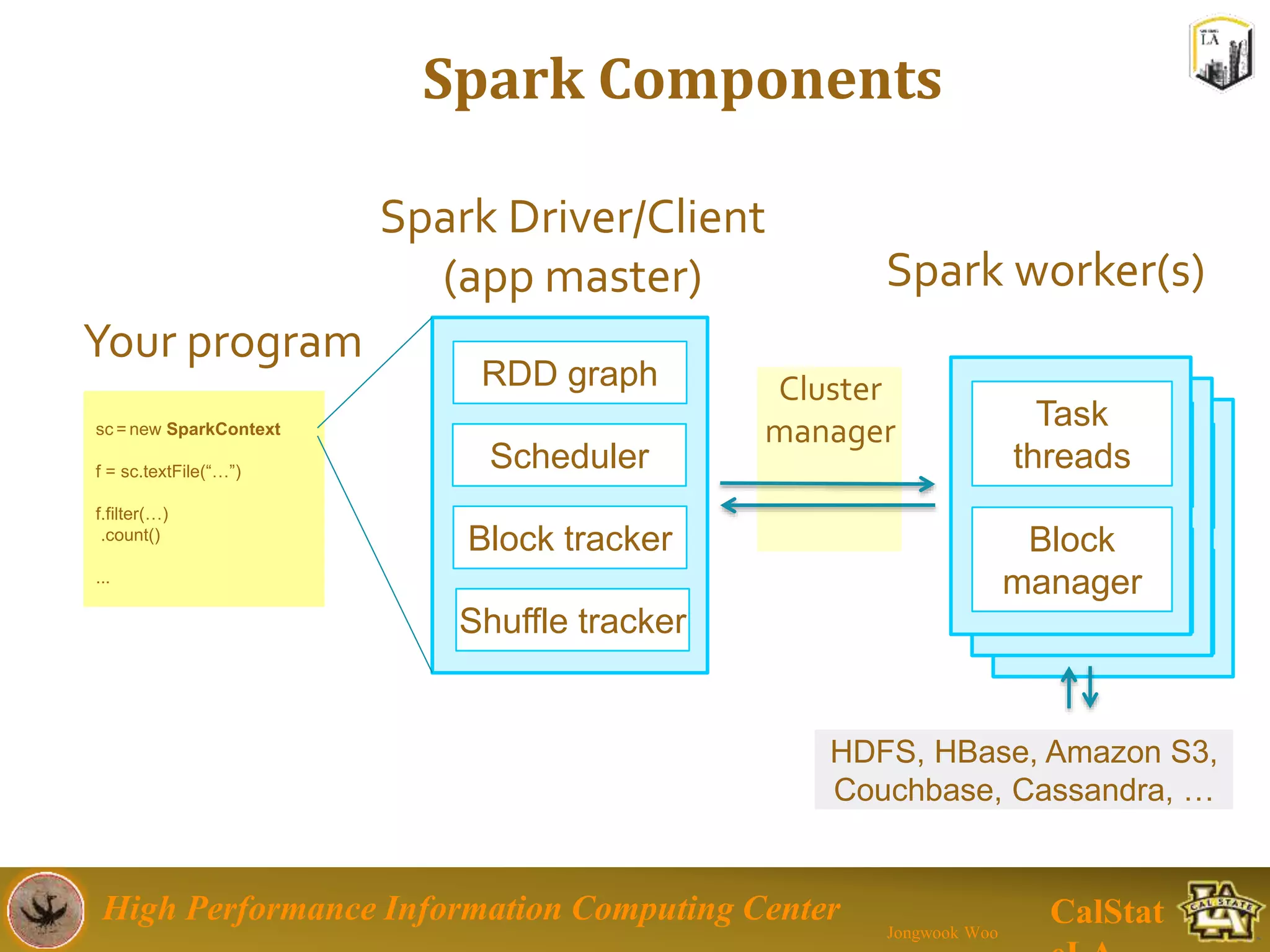
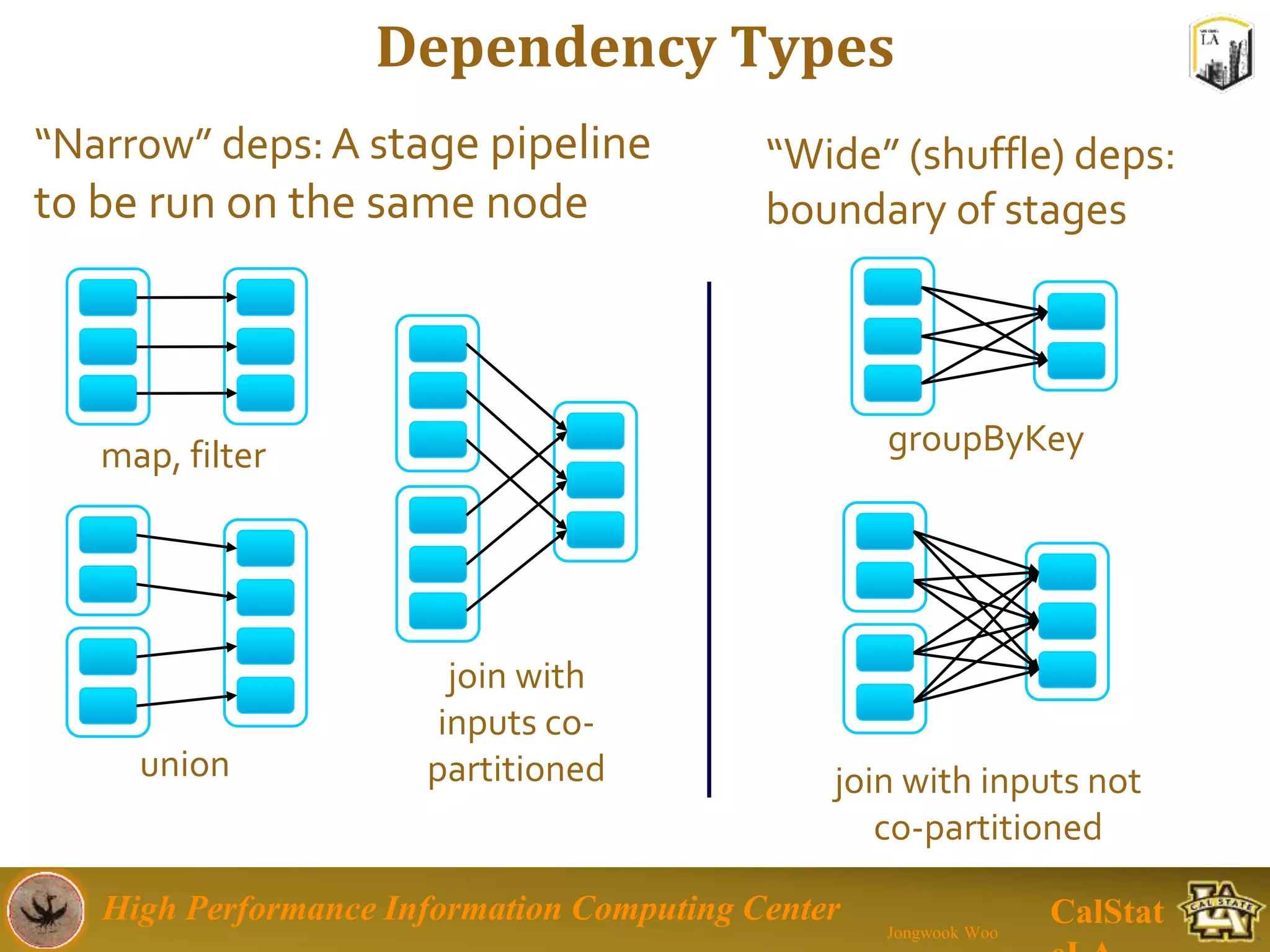
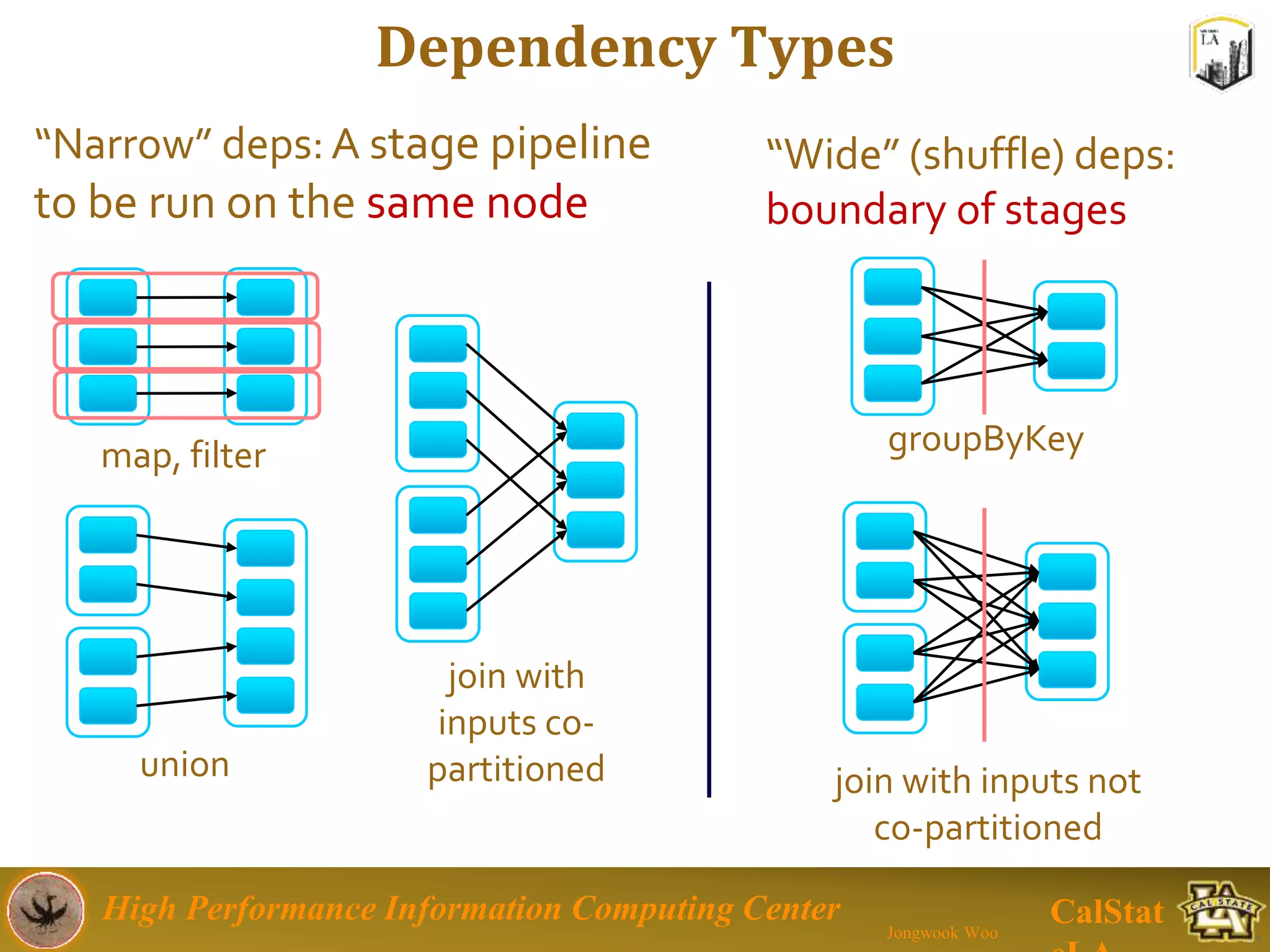
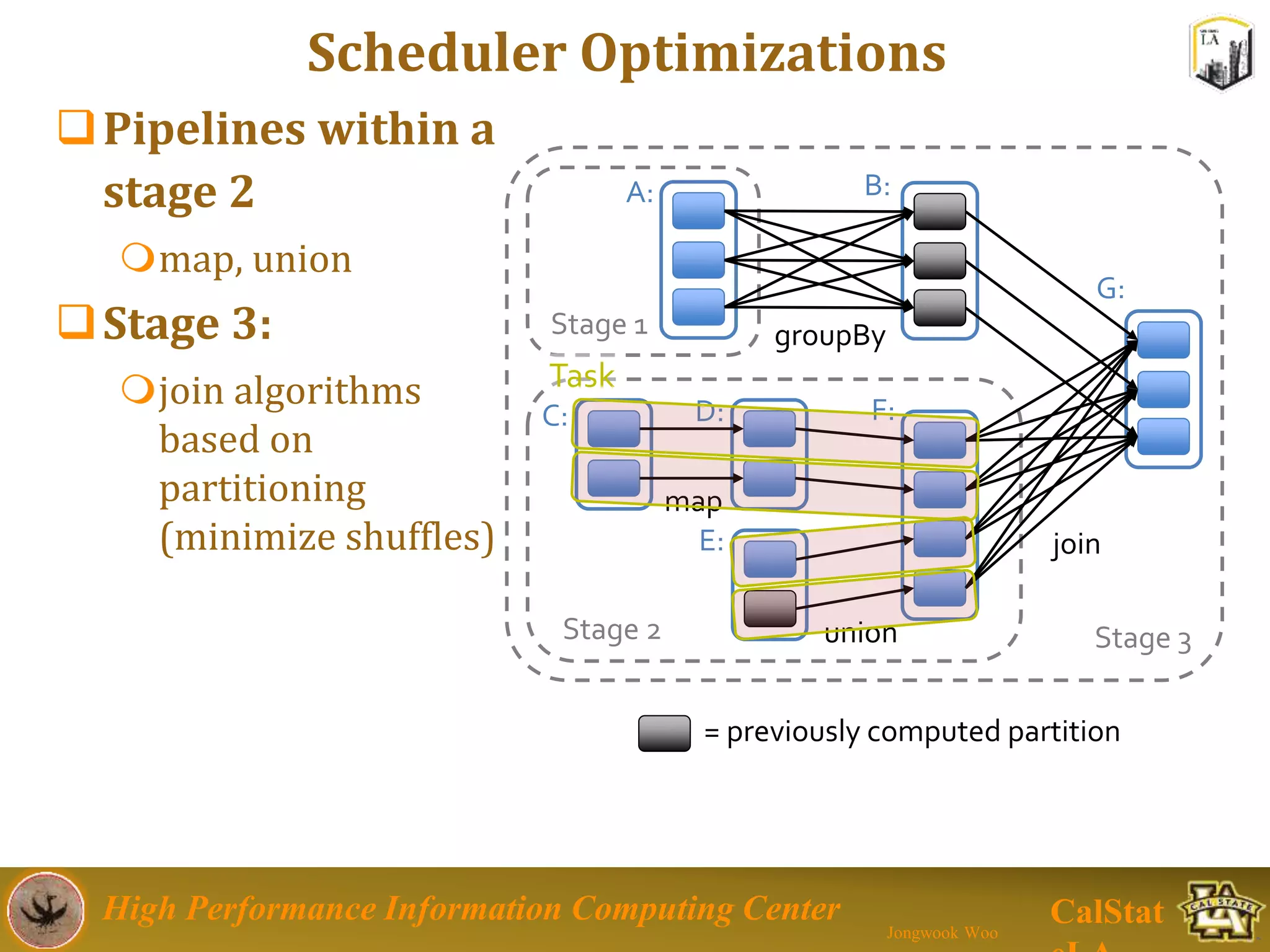
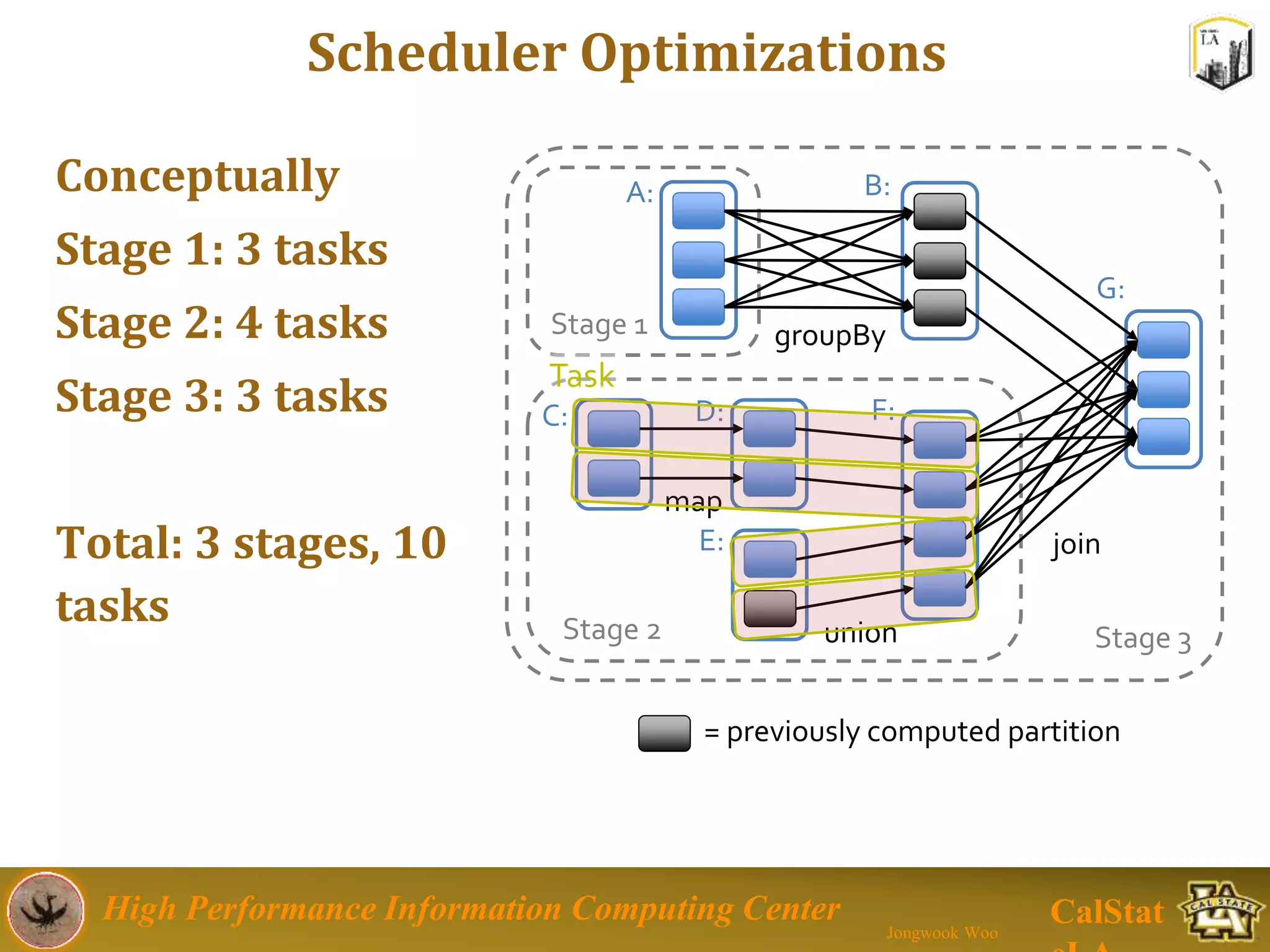

This document summarizes a presentation on big data trends and open data. It introduces the speaker, Jongwook Woo, and his experience in big data. It then covers topics including what is big data, Hadoop and Spark frameworks, using open data for analysis, and examples of analyzing Twitter data on AlphaGo and government airline and crime data sets.

























































![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
