Download as PDF, PPTX






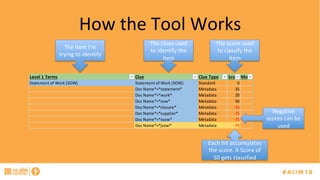



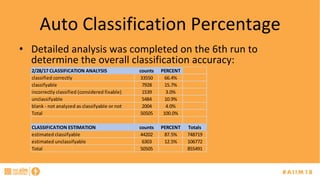
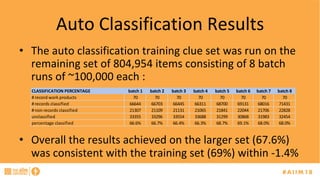



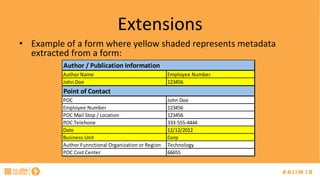



The document discusses the challenges of managing records, particularly identifying and categorizing documents in repositories using semantic technology like auto classification. It details an approach employing machine learning to enhance document classification accuracy, including the iterative training process and outcomes from a specific case study. Additionally, it provides recommendations for improving document management practices and potential applications of the technology in extracting metadata and screening for sensitive information.



















![[AIIM17] Analytics and AI will Lead to True Records Management Automation - J...](https://cdn.slidesharecdn.com/ss_thumbnails/aiim17analyticsandaiwillleadtotruerecordsmanagementautomation-joemariano-170327220638-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Webinar Slides] Using AI to Easily Automate All of Your Correspondence Channels](https://cdn.slidesharecdn.com/ss_thumbnails/20191009-aiimwebinar-v6-191010231303-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Webinar Slides] Maximizing Workforce Capacity - Proven Practices for Saving ...](https://cdn.slidesharecdn.com/ss_thumbnails/maximizingworkforcecapacityprovenpracticesforsavingtimemoneyandeffort-200528143451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] When Your Current Systems No Longer Help You Do Your Job, It...](https://cdn.slidesharecdn.com/ss_thumbnails/whenyourcurrentsystemsnolongerhelpyoudoyourjobitstimeforarevolutioncom-200406135243-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Information Access and Information Control: Two Cloud Conten...](https://cdn.slidesharecdn.com/ss_thumbnails/informationaccessandinformationcontrol-twocloudcontentmanagementsuccessstories-200326165820-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Data Privacy for the IM Practitioner - Practical Advice for ...](https://cdn.slidesharecdn.com/ss_thumbnails/dataprivacyfortheimpractitioner-200227185912-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] New Approaches to Classification and Retention for Organizat...](https://cdn.slidesharecdn.com/ss_thumbnails/newapproachestoclassificationandretentionfororganizationalintelligence-200130155211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Driving Digital Change With O365 & Intelligent Information M...](https://cdn.slidesharecdn.com/ss_thumbnails/20191120-aiimwebinar-v6-191121181355-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Working Faster and Smarter in a Digital Transforming World W...](https://cdn.slidesharecdn.com/ss_thumbnails/20191106-aiimwebinar-v2-191106204930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Capture Leaders & Their Projects: We Asked, They Answered. D...](https://cdn.slidesharecdn.com/ss_thumbnails/20190424-slideshare-3-190429170112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] eSignatures: Learn How This Technology Can Revolutionize You...](https://cdn.slidesharecdn.com/ss_thumbnails/20190213-aiimwebinar-v3-190214220024-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Your 2019 Information Management Resolution: Part Two](https://cdn.slidesharecdn.com/ss_thumbnails/20181213-aiimwebinar-v3-181214192614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Data Explosion in Your Organization? Harness It with a Compr...](https://cdn.slidesharecdn.com/ss_thumbnails/20181010-aiimwebinar-v7-181025012246-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] It All Starts Here— Effectively Capturing Paper and Digital ...](https://cdn.slidesharecdn.com/ss_thumbnails/20180919-aiimwebinar-v6-180919220541-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Improving your Organization’s Collaborative and Case-Centric...](https://cdn.slidesharecdn.com/ss_thumbnails/20180607-aiimwebinar-v5slideshare-180607151715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Modern Problems Require Modern Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/20180606-aiimwebinar-v3pdf-180607023225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar Slides] Dreading Your Data Migration Project? 3 Ways Robotic Process...](https://cdn.slidesharecdn.com/ss_thumbnails/20180510-aiimwebinar-v6-180514164150-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AIIM18] Intelligent Information Management – Platinum Hit? Or Just Backgroun...](https://cdn.slidesharecdn.com/ss_thumbnails/aiimkeynote-3-180427050620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AIIM18] Killing Multiple Privacy Birds With One Stone: Meeting both US and E...](https://cdn.slidesharecdn.com/ss_thumbnails/reidgdprpresenstation-180427050526-thumbnail.jpg?width=640&height=640&fit=bounds)



















