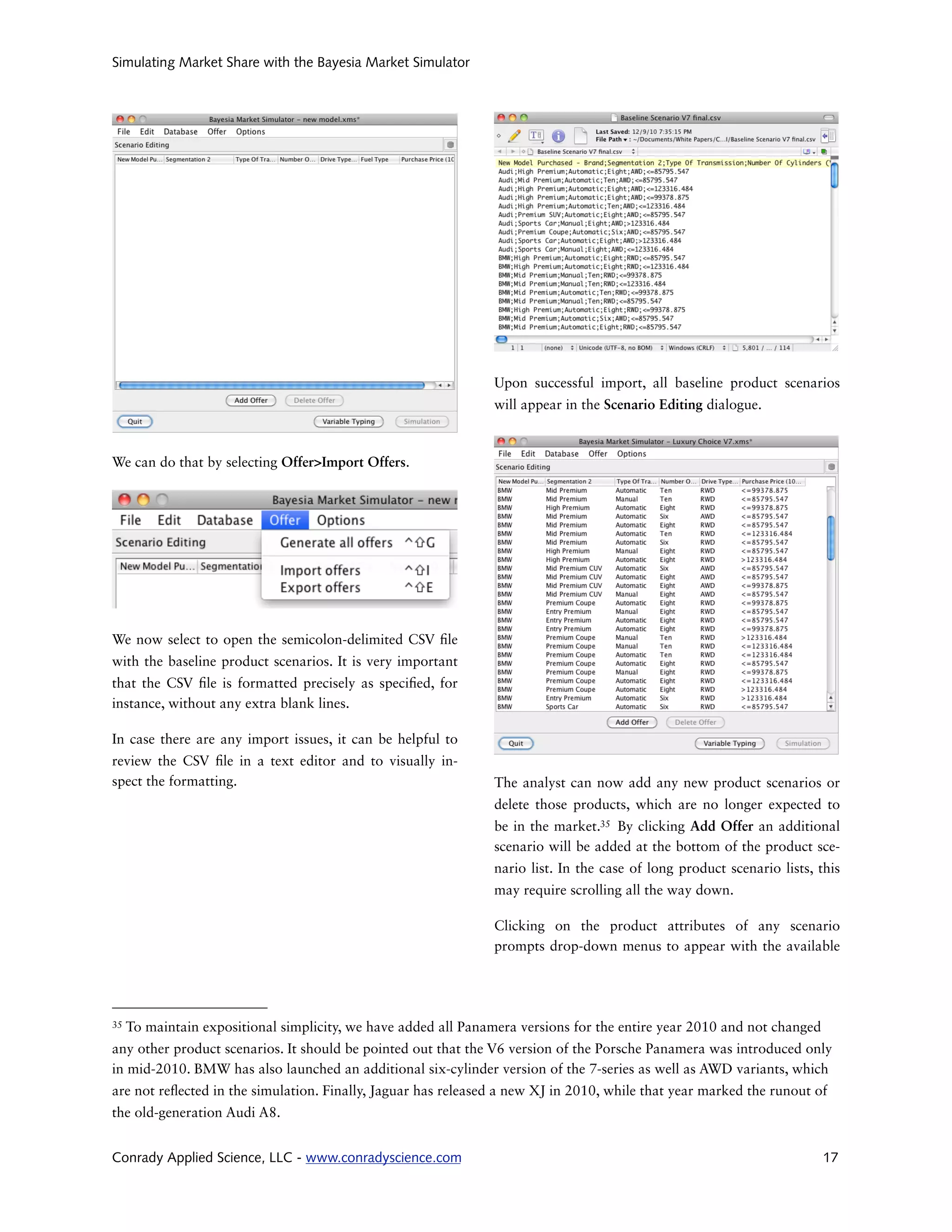
The document presents a case study using Bayesian networks to predict the U.S. market share of the Porsche Panamera through market simulations. It provides a step-by-step guide for marketing practitioners on leveraging Bayesian networks, specifically using the Bayesia Market Simulator and Bayesialab software, to estimate product market shares based on pre-introduction data. The approach claims to enhance forecasting abilities, making market analysis more accessible and practical for businesses.





![Simulating Market Share with the Bayesia Market Simulator
as together they de ne the sales volume expectation, “oracles” that allow us to “deliberately reason about the
which, for obvious reasons, is a key element in most consequences of actions we have not yet taken.” 8
business cases.
Bayesian Networks for Choice Modeling
As a result, it is critical for decision makers to correctly Using Bayesian networks9 as the general framework for
predict the future market shares of products not yet de- modeling a domain or system has many advantages,
veloped. The task of such market share forecasts typi- which Darwiche (2010) summarizes as follows:
cally falls into marketing and market research depart-
ments, who are mostly closely involved with understand- • “Bayesian networks provide a systematic and localized
ing consumer behavior and, more speci cally, the method for structuring probabilistic information
product choices they make. about a situation into a coherent whole […]”
If we fully understood the consumer’s decision making • “Many applications can be reduced to Bayesian net-
process and observed all components of it, we could work inference, allowing one to to capitalize on Bayes-
simply generate a deterministic model for predicting ian network algorithms instead of having to invent
future consumer choices. However, we do not and it is specialized algorithms for each new application.”
obvious that many elements contributing to a consumer’s
Given the very attractive properties of Bayesian net-
purchase decision are inherently unobservable. Despite
works for representing a wide range of problem do-
our limited comprehension of the true human choice
mains, it seems appropriate applying them for choice
process, there are a number of tools that still allow mod-
modeling as well. In particular, the BayesiaLab software
eling consumer choice with what is observable, and ac-
package has made it very convenient to automatically
counting for what will remain unknowable. In this con-
machine-learn fairly large and complex Bayesian net-
text, and based on the seminal works of Nobel-laureate
works from observational data.
Daniel McFadden7, choice modeling has emerged as an
important tool in understanding and simulating con- Beyond the convenience and speed of estimating Bayes-
sumer choice. ian networks with BayesiaLab, there are three fundamen-
tal differences in modeling consumer choice with Bayes-
Such choice models serve a representation of the “real
ian networks compared to traditional discrete choice
world” and thus become, what Judea Pearl likes to call
models.10
7 Daniel McFadden received, jointly with James Heckman, the 2000 Nobel Memorial Prize in Economic Sciences;
McFadden’s share of the prize was “for his development of theory and methods for analyzing discrete choice”.
8 A recurring quote from Judea Pearl’s many lectures on causality.
9 A Bayesian network is a graphical model that represents the joint probability distribution over a set of random vari-
ables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could
represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to
compute the probabilities of the presence of various diseases. A very concise introduction to Bayesian networks can be
found in Darwiche (2010).
10 A very brief overview about utility-based choice models is provided in the appendix.
Conrady Applied Science, LLC - www.conradyscience.com 3](https://image.slidesharecdn.com/bayesialabchoicemodeling1-12930950397007-phpapp01/75/Bayesia-Lab-Choice-Modeling-1-6-2048.jpg)













![Simulating Market Share with the Bayesia Market Simulator
Appendix vance how individual product and consumer attributes
relate to these unobservable utilities. However, there are
Utility-Based Choice Theory methods that allow us to estimate these unknown vari-
In today’s choice modeling practice, utility-based choice ables and, based on this knowledge, they allow us to
theory plays a dominant role. predict choice in the future. One such method is brie y
highlighted in the following.
1. The rst concept of utility-based choice theory is
that each individual chooses the alternative that Multinomial Logit Models
yields him or her the highest utility. In the domain of choice modeling, MultiNomial Logit
models (MNL) have become the workhorse of the indus-
2. The second idea refers to being able to collapse a try, but here we only want to provide a cursory overview,
vector describing attributes of choice alternatives so the reader can compare the approach presented in the
into a single scalar utility value for the chooser. For case study with current practice.
instance, a vector of attributes for one choice alter-
native, e.g. [Price, Fuel Economy, Safety Rating], MNL models provide a functional form for describing
would translate into one scalar value, e.g. [5], spe- the relationship between the utilities of alternatives and
ci c to each chooser. the probability of choice.
The following example is meant to illustrate both: For instance, using an MNL model for a choice situation
with three vehicle alternatives, Altima, Accord and
For Consumer A: Camry, the probability of choosing the Altima can be
expressed as:
• Utility of Product 1:
[Price=$25,000, Fuel Economy=25MPG, Safety Rat- exp(VAltima )
ing=4 stars] = 7 ✓
Pr(Altima) =
exp(VAltima ) + exp(VAccord ) + exp(VCamry )
• Utility of Product 2:
[Price=$29,000, Fuel Economy=23MPG, Safety Rat- VAltima in this case stands for the utility of the Altima
ing=5 stars] = 5.5 alternative. The utilities VAltima, VAccord, and VCamry are a
function of the product attributes, e.g.
For Consumer B:
VAltima = β1 × Cost Altima + β 2 × FuelEconomyAltima + β 3 × SafetyRatingAltima
• Utility of Product 1:
[Price=$25,000, Fuel Economy=25MPG, Safety Rat- As we can observe tangible attributes like vehicle cost,
ing=4 stars] = 4 fuel economy and safety rating, and we can also observe
who bought which vehicle, we can estimate the unknown
• Utility of Product 2: parameters. Once we have the parameters, we can simu-
[Price=$29,000, Fuel Economy=23MPG, Safety Rat- late choices based on new, hypothetical product attrib-
ing=5 stars] = 7.5 ✓ utes, such as a better fuel economy for the Altima or a
lower price for the Camry.
This concept implies that consumers make tradeoffs,
either explicitly or implicitly, and that there exists an The parameters of MNL models can be estimated both
amount x of “Fuel Economy” that is equivalent in utility from “stated preference” (SP) data, i.e. asking consumers
to an amount y of “Safety”. The reader may reasonably about what they would choose, and “revealed prefer-
object that not even a fuel economy of 100MPG would ence” (RP) data, i.e. observing what they have actually
make it acceptable to drive a vehicle that is rated very chosen. There are numerous variations and extensions
poorly on safety. to the class of MNL models and the reader is referred to
Train (2003) and Koppelman (2006) for a comprehen-
Also, we do not know a priori what the utility values are sive introduction.
nor can we measure them. Neither do we know in ad-
Conrady Applied Science, LLC - www.conradyscience.com 22](https://image.slidesharecdn.com/bayesialabchoicemodeling1-12930950397007-phpapp01/75/Bayesia-Lab-Choice-Modeling-1-25-2048.jpg)














































