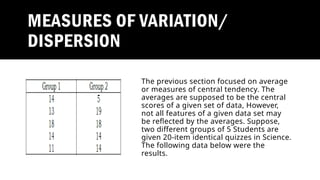
The document outlines various types of data in statistics, including continuous, discrete, nominal, interval, and categorical data, while explaining their characteristics and providing examples. It distinguishes between descriptive and inferential statistics, detailing their roles in summarizing data and making inferences about populations, respectively. Additionally, the document covers measures of central tendency and variation, along with the significance of statistical tests in research.







































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







