Downloaded 35 times






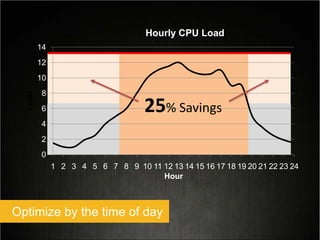
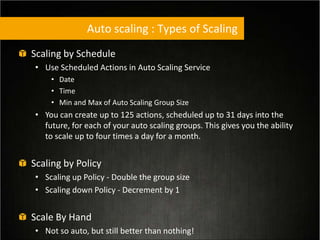
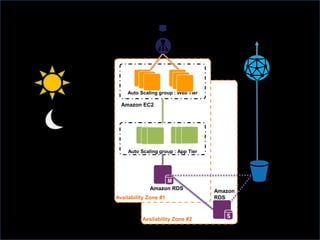
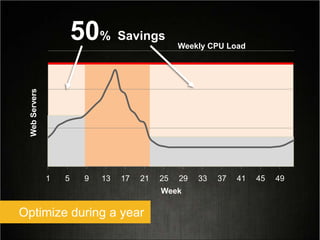
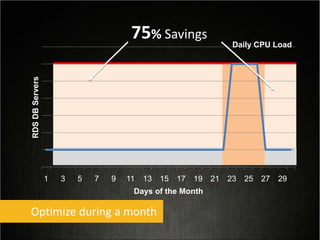

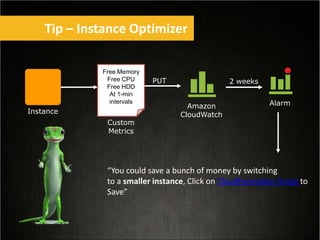


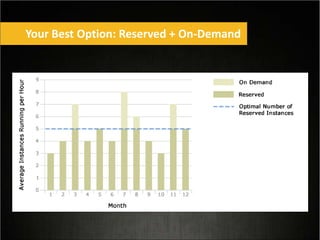
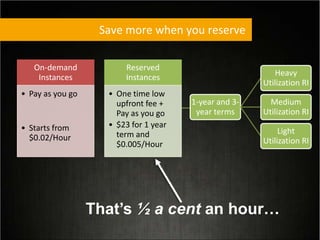
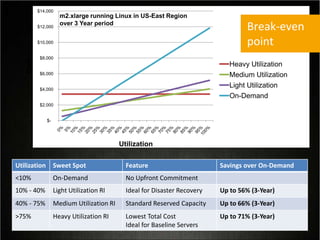


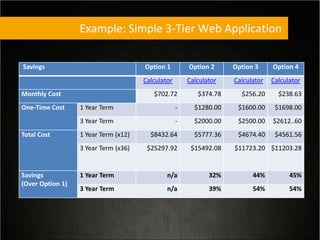
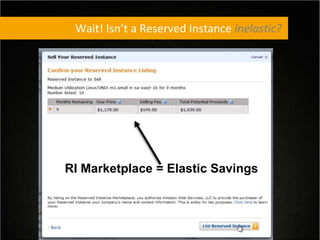

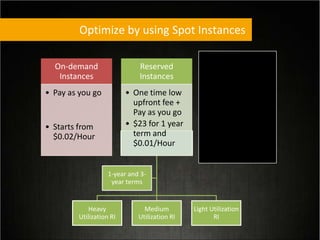
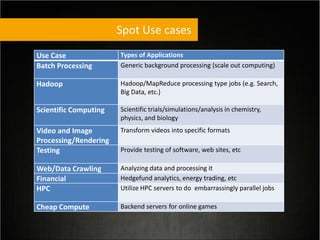
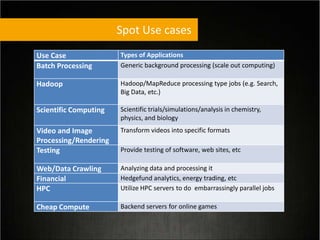
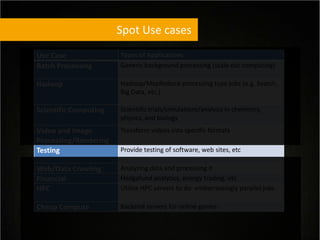
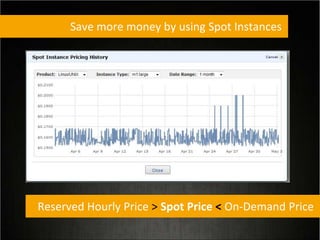
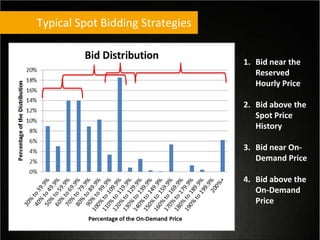



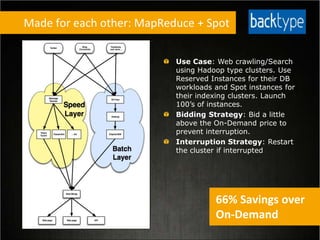



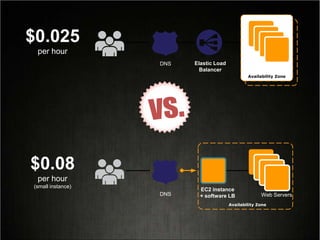

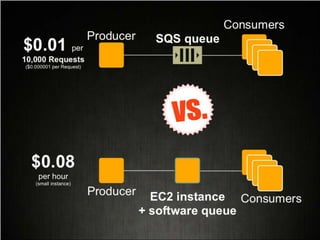







This document provides tips for optimizing costs in the cloud. It recommends turning off unused resources, auto-scaling based on time of day and load, choosing the right instance types, using reserved instances for steady workloads and spot instances for intermittent workloads, converting standalone instances into managed services, caching content at the edge, and choosing the appropriate storage options. The key strategies discussed are rightsizing, auto-scaling, reserved instances, spot instances, caching, and cost-optimized storage.




























































