Downloaded 23 times

































![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
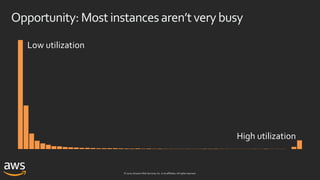
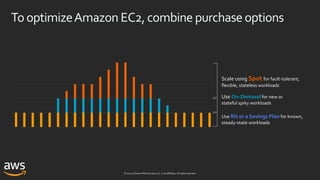
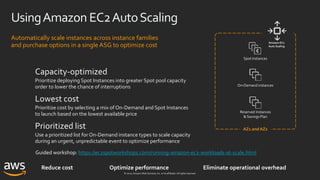
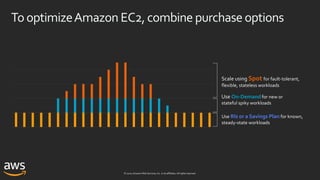
ASG capacity-optimizedallocation strategy
us-east-1a
Desired capacity: 12
SpotAllocationStrategy: capacity-optimized
OnDemandBaseCapacity: 0 OnDemandPercentageAboveCapacity: 0
r5.large
m4.large
m5.large
R5 R5
R5 R5
us-east-1b us-east-1c
Overrides: [“r5.large”, “m4.large”, ”m5.large”]
$$
$
$$$
r5.large
m4.large
m5.large
$$$
$$
$
r5.large
m4.large
m5.large
$
$$$
$$](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-37-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
ASG lowest-priceallocationstrategy
us-east-1a
Desired capacity: 12
SpotAllocationStrategy: lowest-price
OnDemandBaseCapacity: 0 OnDemandPercentageAboveCapacity: 0
r5.large
m4.large
m5.large
R5 R5
R5 R5
us-east-1b us-east-1c
Overrides: [“r5.large”, “m4.large”, ”m5.large”]
$$
$
$$$
r5.large
m4.large
m5.large
$$$
$$
$
r5.large
m4.large
m5.large
$
$$$
$$](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-38-320.jpg)

![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-44-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-45-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-46-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-47-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-48-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
APIparameters
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": "MyLaunchTemplate"
},
"Overrides": [
{
"InstanceType": "m4.xLarge",
"WeightedCapacity": "1"
},
{
"InstanceType": "m4.2xLarge",
"WeightedCapacity": "2"
},
{
"InstanceType": "m4.4xLarge",
"WeightedCapacity": "4"
}
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 10,
"OnDemandPercentageAboveBaseCapacity": 50,
"SpotAllocationStrategy": “capacity-optimized",
"SpotInstancePools": 2
}
}
AZ1 and AZ2
Desired
Min
Max
On-Demand base
50% On-Demand
50% Spot
Minimum On-Demand (10)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-49-320.jpg)

![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": ”MyLaunchTemplate"
},
"Overrides": [
{ "InstanceType": "m4.4xlarge" },
{ "InstanceType": "m5.4xlarge" },
{ "InstanceType": "c5d.4xlarge" },
{ "InstanceType": "m5d.4xlarge" },
{ "InstanceType": "c4.4xlarge" }
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 0,
"OnDemandPercentageAboveBaseCapacity": 30,
"SpotAllocationStrategy": "lowest-price",
"SpotInstancePools": 2
}
}
Producer fleetconfiguration
AZ1 and AZ2
Desired – 50
Min – 20
Max – 80
30% On-Demand (15)
70% Spot (35)](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-51-320.jpg)
![© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
"MixedInstancesPolicy": {
"LaunchTemplate": {
"LaunchTemplateSpecification": {
"LaunchTemplateName": ”MyLaunchTemplate"
},
"Overrides": [
{ "InstanceType": "m4.4xlarge" },
{ "InstanceType": "m5.4xlarge" },
{ "InstanceType": "c5d.4xlarge" },
{ "InstanceType": "m5d.4xlarge" },
{ "InstanceType": "c4.4xlarge" }
]
},
"InstancesDistribution": {
"OnDemandAllocationStrategy": "prioritized",
"OnDemandBaseCapacity": 250,
"OnDemandPercentageAboveBaseCapacity": 0,
"SpotAllocationStrategy": "lowest-price",
"SpotInstancePools": 2
}
}
Consumer fleetconfiguration
AZ1 and AZ2
Minimum On-Demand (250)
Min – 200
Max – 350
On-Demand Base – 250
0% On-Demand (0)
100% Spot (50)
Desired – 300](https://image.slidesharecdn.com/2020-04-09awswebinar6-costoptimisationonaws-200414093837/85/AWS-SSA-Webinar-Cost-optimisation-on-AWS-52-320.jpg)













The document outlines various Amazon EC2 instances and cost optimization strategies. It highlights instances tailored for specific workloads, such as general-purpose, memory-optimized, storage-optimized, and accelerated computing. Additionally, it details cost-saving measures such as savings plans, instance scheduling, and the use of spot instances to achieve significant discounts on AWS services.


























































