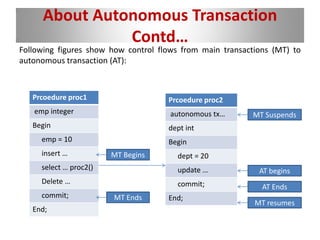
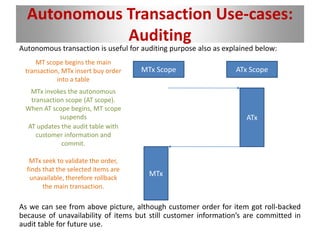
The document discusses autonomous transactions in PostgreSQL, highlighting their purpose in allowing partial transaction commits without affecting the main transaction. It explains the characteristics, use-cases such as error logging and auditing, and compares the implementation of autonomous transactions in PostgreSQL with other databases like Oracle and IBM DB2. The conclusion emphasizes their utility in sectors like retail and banking for effective data management.



























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










