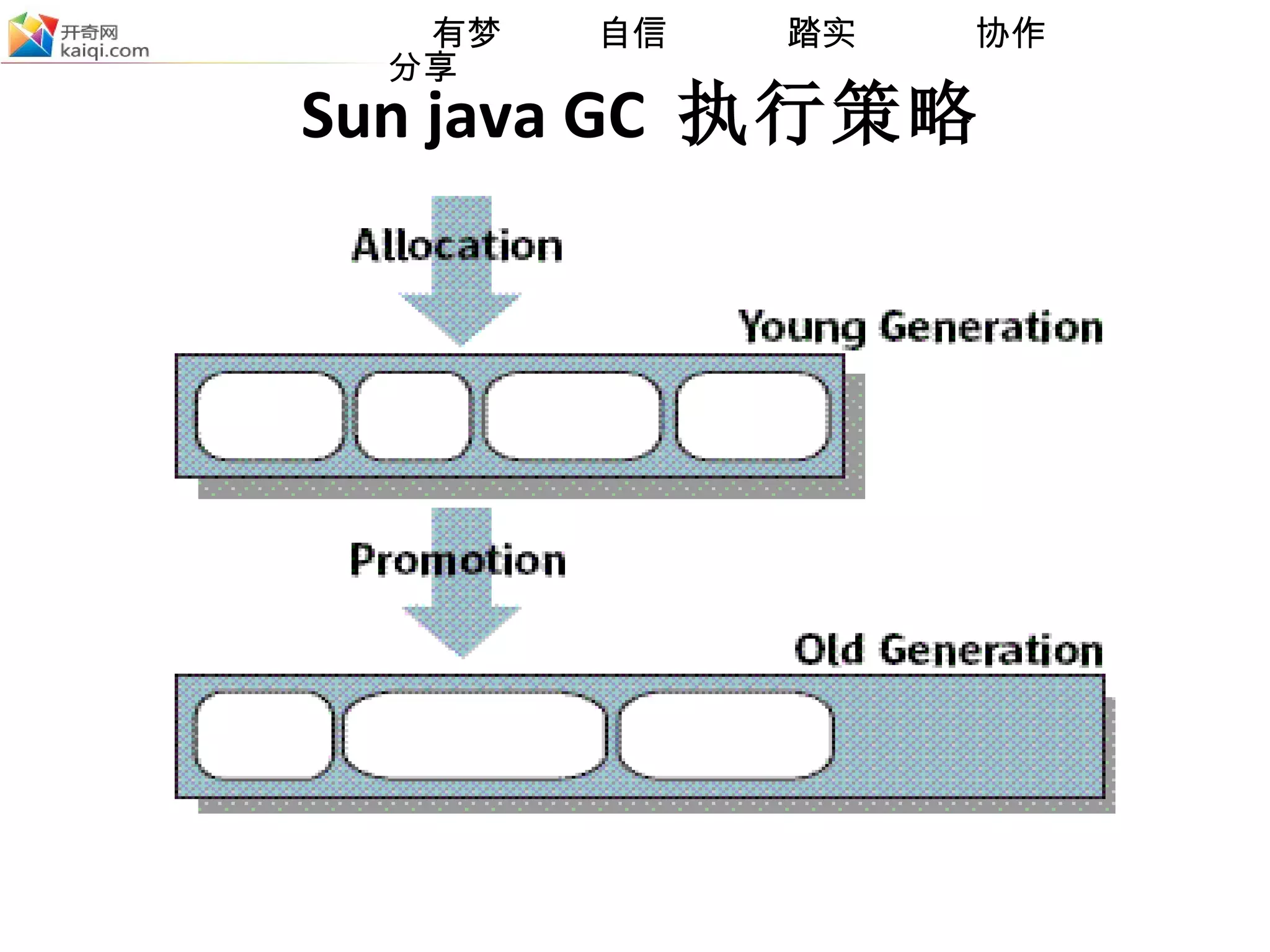
Sun java GC 执行策略 年轻代、老年代、持久代 年轻代 生命周期很短的对象,归为年轻代。由于生命周期很短,这部分对象在 gc 的时候,很大部分的对象已经成为非活动对象。因此针对年轻代的对象,采用复制算法,只需要将少量的存活下来的对象 copy 到 to space 。存活的对象数量越少,那么复制算法的效率越高。 年轻代的 gc 称为 minor gc 经过数次复制,依旧存活的对象,将被移出年轻代,移到老年代。
24.
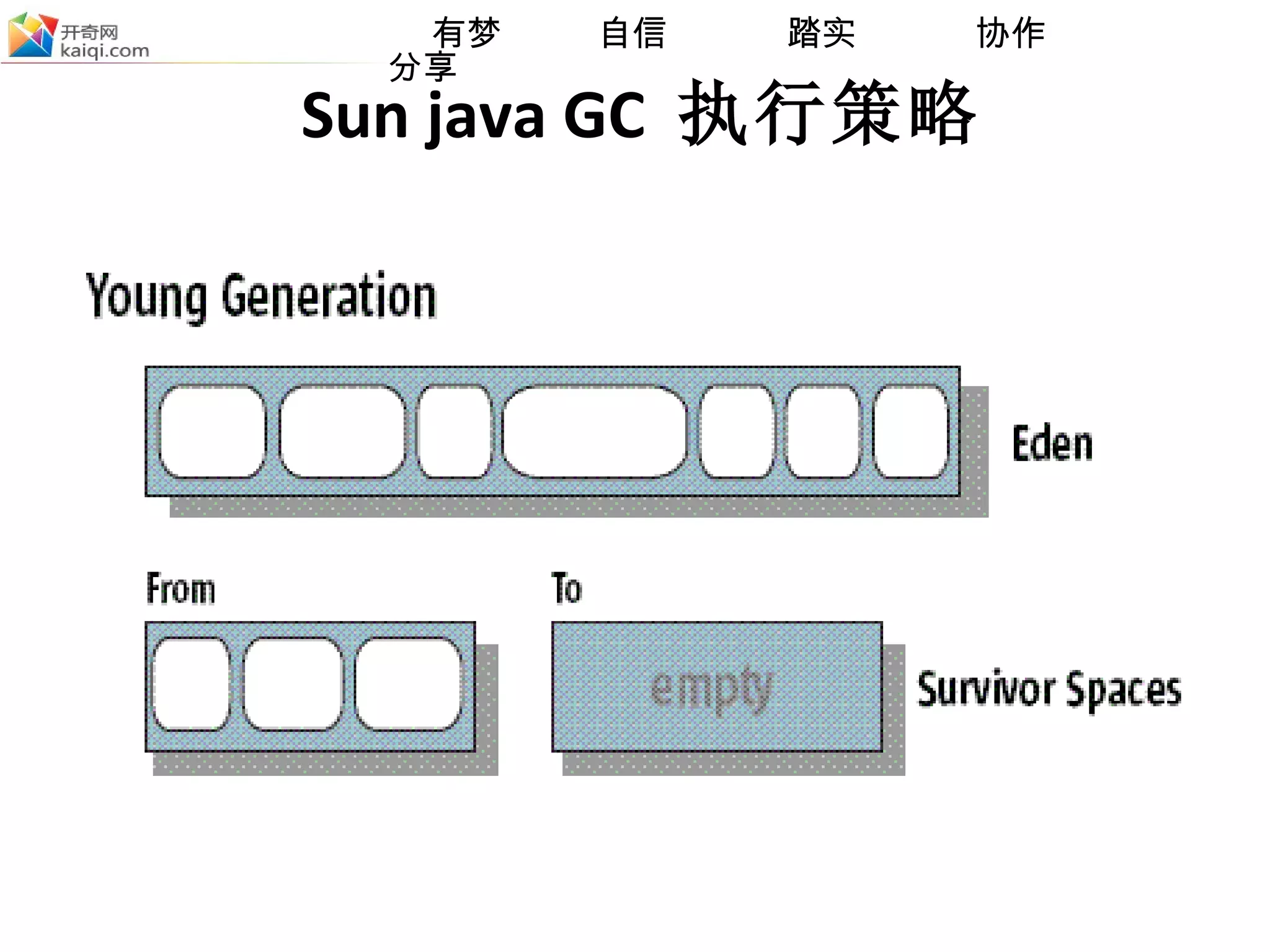
Sun java GC 执行策略 年轻代、老年代、持久代 年轻代分为: eden :每当对象创建的时候,总是被分配在这个区域 survivor1 : copy 算法中的 from space survivor2 : copy 算法中的 to sapce
Sun java GC 执行策略 年轻代、老年代、持久代 老年代: 生命周期较常的对象,归入到老年代。一般是经过多次 minor gc ,还依旧存活的对象,将移入到老年代。 老年代的 gc 称为 major gc ,就是通常说的 full gc 。 采用标记 - 整理算法。由于老年区域比较大,而且通常对象生命周期都比较长,标记 - 整理需要一定时间。所以这部分的 gc 时间比较长。 minor gc 可能引发 full gc 。当 eden + from space 的空间大于老年代的剩余空间时,会引发 full gc 。这是悲观算法,要确保 eden + from space 的对象如果都存活,必须有足够的老年代空间存放这些对象。




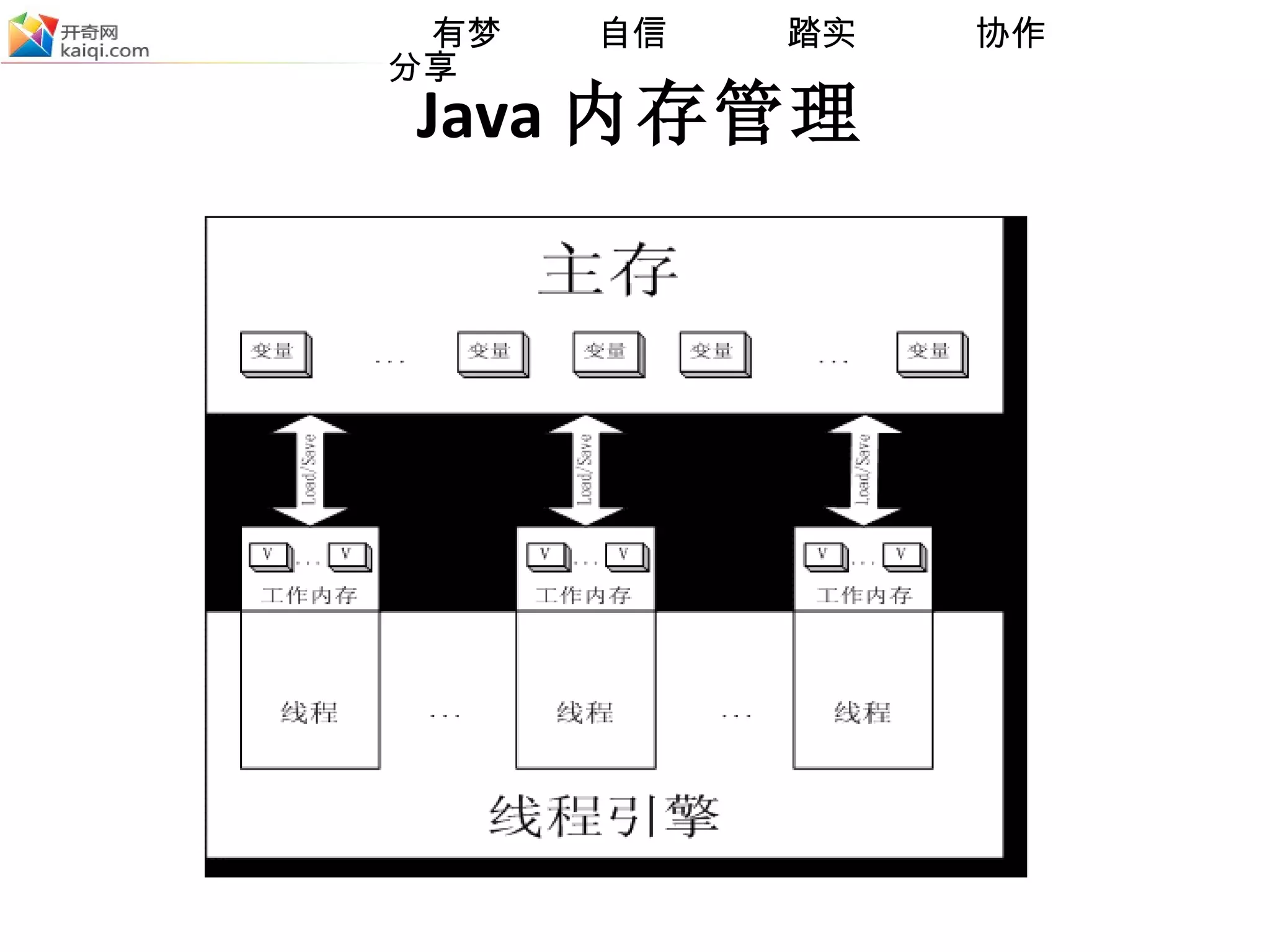



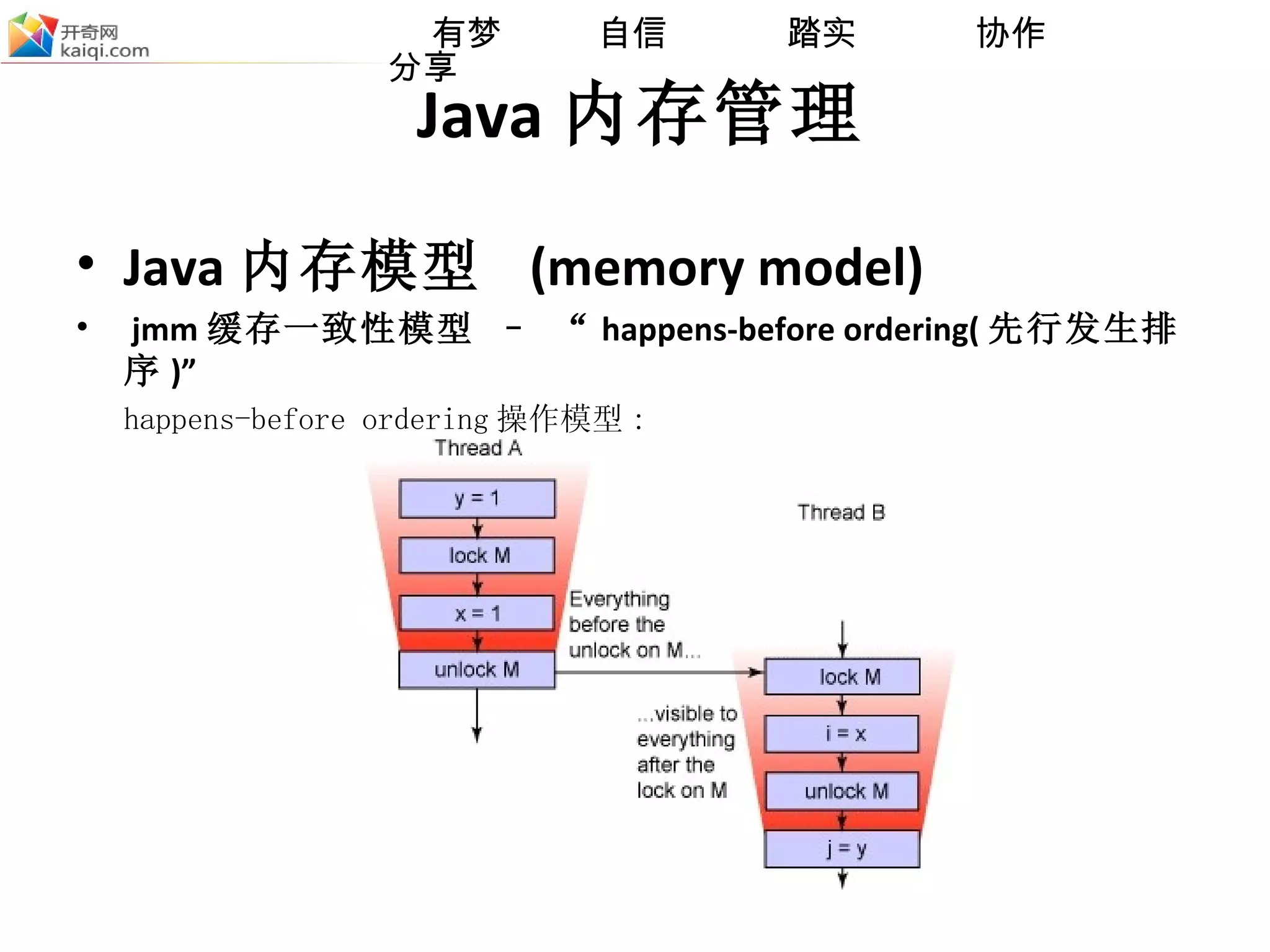
![Java 内存管理 Java 内存模型 (memory model) jmm 缓存一致性模型 – “ happens-before ordering( 先行发生排序 )” (1) 获取对象监视器的锁 (lock) (2) 清空工作内存数据 , 从主存复制变量到当前工作内存 , 即同步数据 (read and load) (3) 执行代码,改变共享变量值 (use and assign) (4) 将工作内存数据刷回主存 (store and write) (5) 释放对象监视器的锁 (unlock) [ 备注 ]](https://image.slidesharecdn.com/jvm-091113-091116020804-phpapp02/75/JVM-10-2048.jpg)





![Java 内存管理 Java 栈内存与堆内存 栈 (stack) 优势 : 管理简单, 存取速度快,数据可以共享。 缺点 : 存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。 堆 (heap) 优势 : 可以动态地分配内存大小,生存期也不必事先告诉编译器,灵活 。 缺点 : 存取速度较慢。 [ 备注 ]](https://image.slidesharecdn.com/jvm-091113-091116020804-phpapp02/75/JVM-16-2048.jpg)



![Java 内存管理 JVM 的 stack 和 heap 分配 非静态方法和静态方法 : 非静态方法有一个隐含的传入参数,该参数是 JVM 给它的,这个隐含的参数就是对象实例在 stack 中的地址指针。因此非静态方法在调用前,必须先 new 一个对象实例,获得 stack 中的地址指针,否则 JVM 将无法将隐含参数传给非静态方法。 静态方法无此隐含参数,因此也不需要 new 对象,只要 class 文件被 ClassLoader load 进入 JVM 的 stack ,该静态方法即可被调用。 当然此时静态方法是存取不到 heap 中的对象属性的。 [ 备注 ]](https://image.slidesharecdn.com/jvm-091113-091116020804-phpapp02/75/JVM-20-2048.jpg)









![Java OOM OOM(Native Heap) 错误提示: requested XXXX bytes for ChunkPool::allocate. Out of swap space 。 同样这类 OOM 产生的问题也是分成正常使用耗尽和无释放资源耗尽两类。 无释放资源耗尽 , 要确定这类问题,就需要去观察 Native Heap Memory 的增长和使用情况,在服务器应用起来以后,运行一段时间后 JVM 对于 Native Heap Memory 的使用会达到一个稳定的阶段,此时可以看看什么操作对于 Native Heap Memory 操作频繁,而且使得 Native Heap Memory 增长 . 能够通过 JVM 启动时候增加 -verbose:jni 参数来观察对于 Native Heap Memory 的操作。 另一种情况就是正常消耗 Native Heap Memory ,对于 Native Heap Memory 的使用主要取决于 JVM 代码生成,线程创建,用于优化的临时代码和对象产生。当正常耗尽 Native Heap Memory 时,那么就需要增加 Native Heap Memory ,此时就会和我们前面提到增加 java Heap Memory 的情况出现矛盾。 [ 备注 ]](https://image.slidesharecdn.com/jvm-091113-091116020804-phpapp02/75/JVM-32-2048.jpg)

![Java OOM Java 虚拟机 (JVM) 及其内存分配的设置 (Sun HotSpot JVM 5) 关于 Heap 的几个参数设置: 在申请了 Java Heap 以后,剩下的可用资源就会被使用到 Native Heap 。 Xms: java heap 初始化时的大小。默认情况是机器物理内存的 1/64 。这个主要是根据应用启动时消耗的资源决定,分配少了申请起来会降低启动速度,分配多了也浪费。 Xmx:java heap 的 最大值,默认是机器物理内存的 1/4 ,最大也就到 1G 。这个值决定了最多可用的 Java Heap Memory ,分配过少就会在应用需要大量内存作缓存或者零时对象时出现 OOM 的问题,如果分配过大, 那么就会产生上文提到的第二类 OOM 。所以如何配置还是根据运行过程中的分析和计算来确定,如果不能确定还是采用默认的配置。 Xmn:java heap 新生代的空间大小。在 GC 模型中,根据对象的生命周期的长短,产生了内存分代的设计:年 轻 代(内部也分成三部分,类似于整体划分的作用,可以通过配置来设置比例),老年代,持久代。每一代的管理和回收策略都不相同,最为活跃的就是青年代,同时这部分的内存分配和管理效率也是最高。通常情况下,对于内存的申请优先在新生代中申请,当内存不够时会整理新生代,当整理以后还是不能满足申请的内存,就会向老年代移动一些生命周期较长的对象。 这种整理和移动会消耗资源,同时降低系统运行响应能力,因此如果青年代设置的过小,就会频繁的整理和移动,对性能造成影响。 那是否把年青代设置的越大越好,其实不然,年青代采用的是复制搜集算法,这种算法必须停止所有应用程序线程, 服务器线程切换时间就会成为应用响应的瓶颈(当然永远不用收集那么就不存在这个问题)。老年代采用的是串行标记收集的方式,并发收集可以减少对于应用的影响。 Xss: 线程堆栈最大值。允许更多的虚拟内存空间地址被 Java Heap 使用 [ 备注 ]](https://image.slidesharecdn.com/jvm-091113-091116020804-phpapp02/75/JVM-34-2048.jpg)































































































