本文件由软件工程师莫枢撰写,目的是促进对Java虚拟机(JVM)及其代码的理解。作者通过分享阅读HotSpot VM的经验,鼓励开发者关注基础知识和替代方案,而不仅仅是源码,特别是对初学者而言。文中还列出了多个JVM的替代项目和推荐阅读材料,旨在帮助读者以更有效的方式深入了解虚拟机的内部运作。








![读HotSpot VM源码想了解什么?
• JVM crash了!为什么?怎么办?
• JVM报OutOfMemoryError了 …
• 想学习如何操纵字节码
• “这段代码创建了多少个对象”?
• “JVM会让String共享char[]”?
• 其它](https://image.slidesharecdn.com/0-1-120302095459-phpapp02/75/HotSpot-VM-2012-03-03-9-2048.jpg)



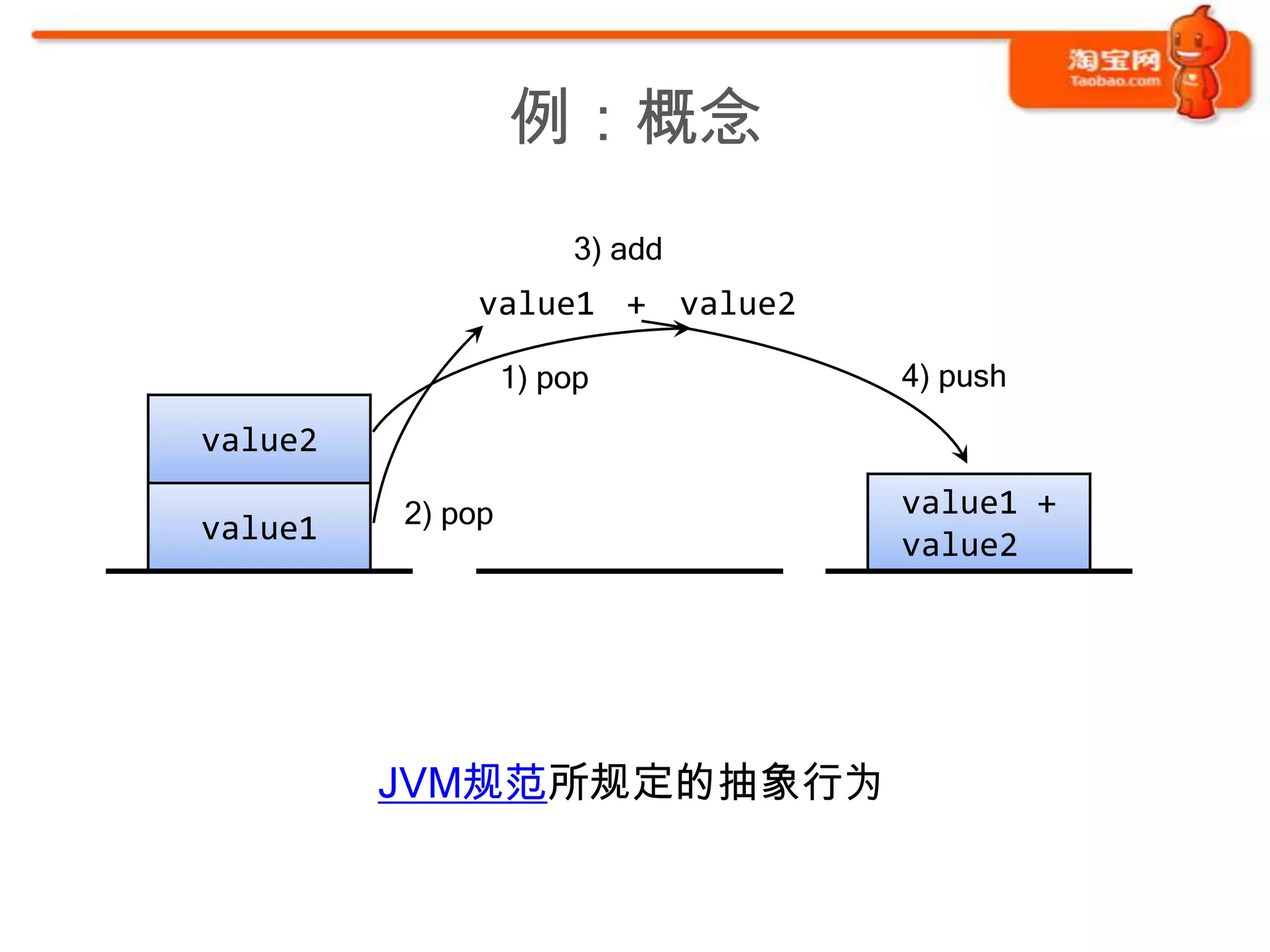
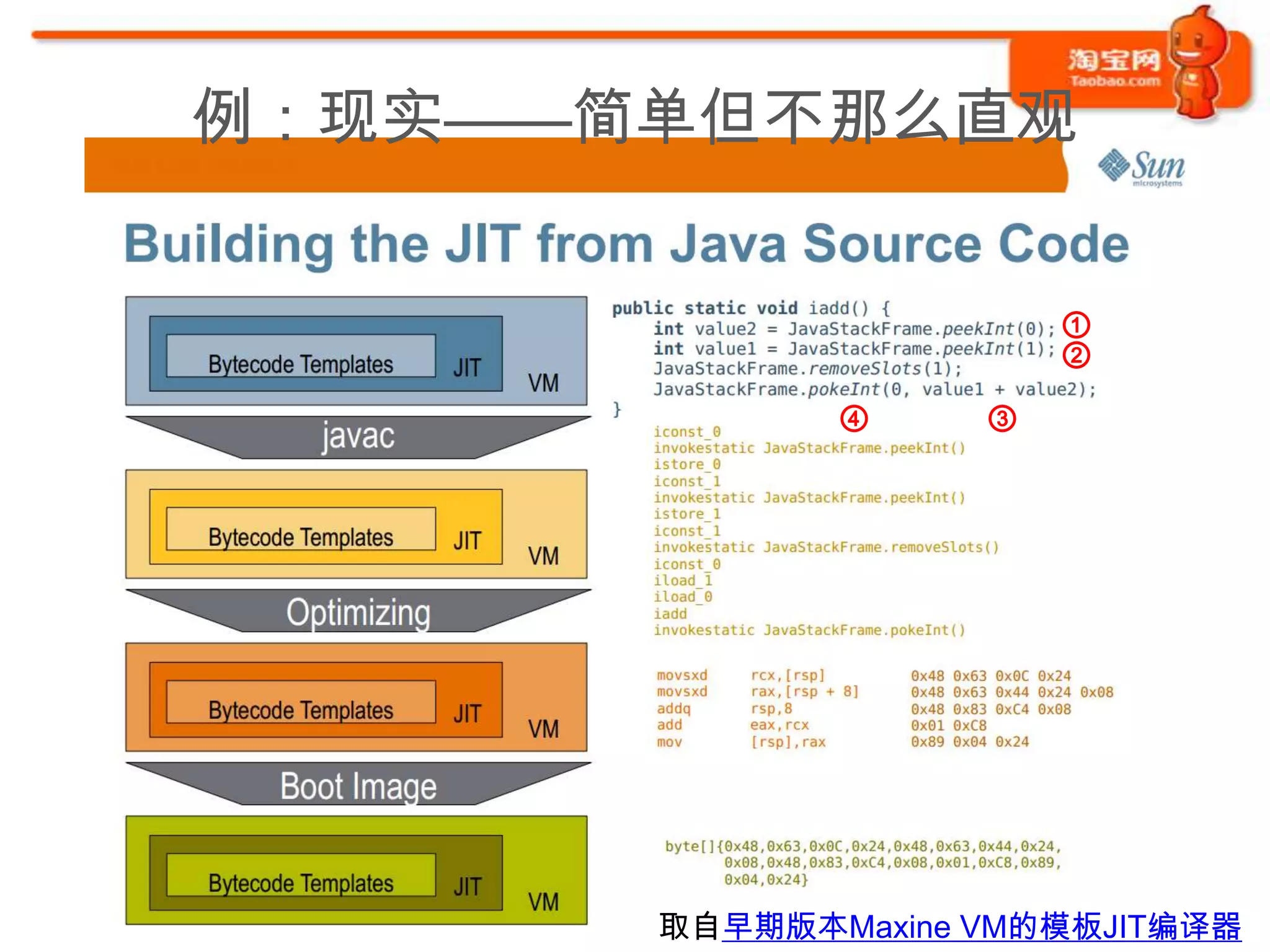
![例:理想——简单直观
case SVM_INSTRUCTION_IADD: {
/* instruction body */
jint value1 = stack[stack_size - 2].jint; ②
jint value2 = stack[--stack_size].jint;①
stack[stack_size - 1].jint = value1 + value2;
④ ③
/* dispatch */
goto dispatch;
}
取自SableVM的switch版解释器
(sablevm/src/libsablevm/instructions_switch.c)](https://image.slidesharecdn.com/0-1-120302095459-phpapp02/75/HotSpot-VM-2012-03-03-16-2048.jpg)


























































![[NDC 2018] 신입 개발자가 알아야 할 윈도우 메모리릭 디버깅](https://cdn.slidesharecdn.com/ss_thumbnails/v7-180427162920-thumbnail.jpg?width=640&height=640&fit=bounds)



























