Download to read offline


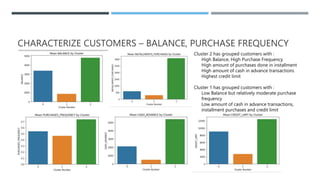




This document discusses two clustering problems. For the first problem using a credit card dataset, K-means clustering was used to group customers into two clusters based on their balance, purchase frequency, and other attributes. The second problem used the South German credit data, where K-means clustering was applied after removing missing values and the target column, then predictions were made on good vs bad credits and characteristics of bad creditors were analyzed.
























































