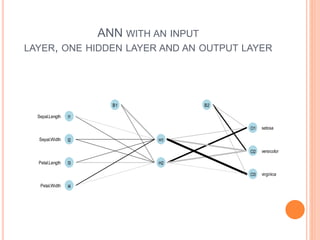
The document provides a comprehensive overview of artificial neural networks (ANNs), detailing their structure, including input, hidden, and output layers, as well as training methodologies such as supervised and unsupervised learning. It discusses the optimization of connection weights through various methods like backpropagation and criteria for determining the number of hidden nodes and layers. Additionally, it references the use of specific R software packages for implementing ANN and offers guidelines for fine-tuning and optimizing the network.







![NUMBER OF HIDDEN LAYERS
A neural net can have more than one hidden layer,
see Looney [1] for more details.
However, it is shown in White [2] that one hidden
layer with sufficient number of neurons is enough
to approximate any function of interest.
In practice, however, a network with more than
one layer may provide a more parsimonious
model for the data.
The number of neurodes, H, in the hidden layer can
be determined as in Looney [2] by a rule of thumb:
1
)
(
log
*
7
.
1 2
n
H](https://image.slidesharecdn.com/artificialneuralnetworks-240528090054-512cbb8f/85/ARTIFICIAL-NEURAL-NETWORKS-ppt-on-machine-learning-9-320.jpg)
![NUMBER OF HIDDEN LAYERS
Alternatively, one can use the Black Information
Criterion (BIC) as proposed in Swanson and White
[3] to sequentially determine H.](https://image.slidesharecdn.com/artificialneuralnetworks-240528090054-512cbb8f/85/ARTIFICIAL-NEURAL-NETWORKS-ppt-on-machine-learning-10-320.jpg)



![REFRENCES
(1) Looney, C. G. Pattern recognition using neural
networks: theory and algorithms for engineers and
scientists. Oxford University Press,Newyork, 1997.
(2) White, H. “Some asymptotic results for learning in single
hiddenlayer feedforward network models” [J. Amer.
Statist. Assoc. 84 (1989), no. 408, 1003–1013;
MR1134490 (92e:62119)]. J. Amer. Statist. Assoc.
87, 420 (1992), 1252.](https://image.slidesharecdn.com/artificialneuralnetworks-240528090054-512cbb8f/85/ARTIFICIAL-NEURAL-NETWORKS-ppt-on-machine-learning-14-320.jpg)














































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

