



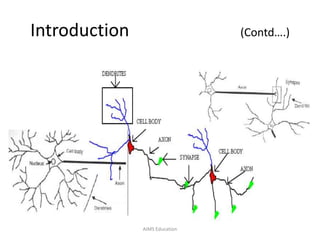

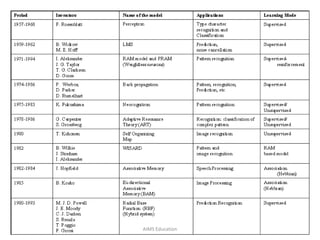

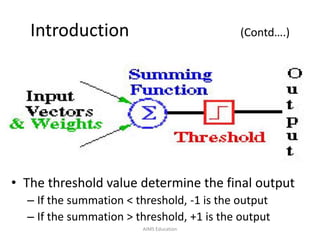


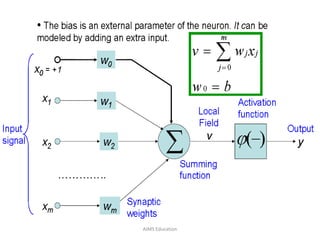
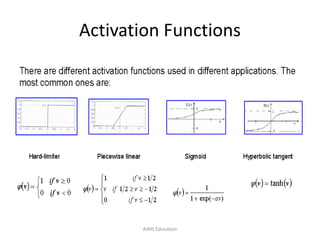



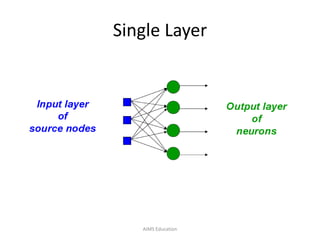
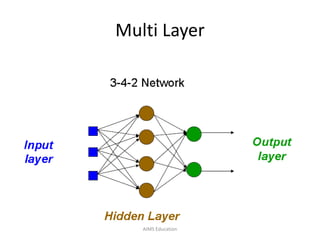



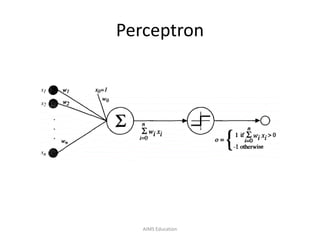




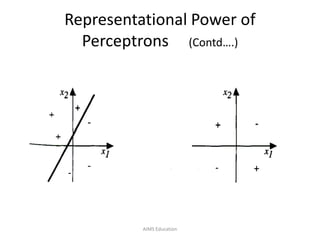









The document provides an overview of artificial neural networks (ANNs), detailing their structure, design, and applications in pattern recognition and data classification. It discusses the basic components of ANNs such as neurons, activation functions, and the training process, emphasizing the importance of weights and learning methods like the perceptron and delta rule. Additionally, it highlights suitable problems for neural network learning, indicating their robustness to noise and the challenges posed by the interpretability of learned models.









































![AI-Lecture-11[Neural Network] updated.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ai-lecture-11neuralnetworkupdated-251220065329-186ba89b-thumbnail.jpg?width=640&height=640&fit=bounds)
























