Download to read offline






















![Statistical parsing
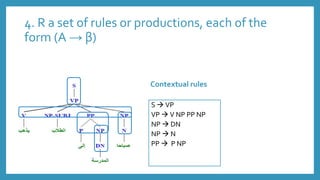
• Contextual rules
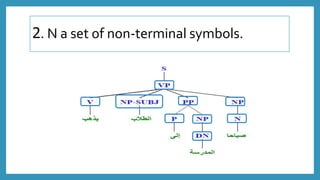
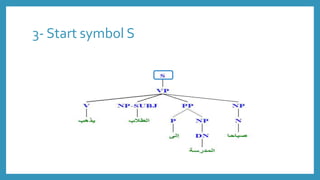
S VP
S VP NP
VP V NP PP NP
VP V NP
NP DN
NP N
PP P NP
• Lexical rules
N صباحا
DN الطالب
DN المدرسة
V يذهب
PP إلى
[0.4]
[0.6]
[0.3]
[0.7]
[0.5]
[0.5]
[1.0]
[0.4]
[0.3]
[0.3]
[1.0]
[1.0]
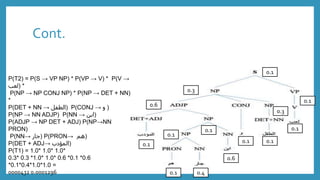
P is the set of probabilities associated to rules P (A → β)
We need mechanisms that allow us to find the
most likely parse(s)](https://image.slidesharecdn.com/arabicsyntacticparsing-210418201647/85/Arabic-syntactic-parsing-33-320.jpg)
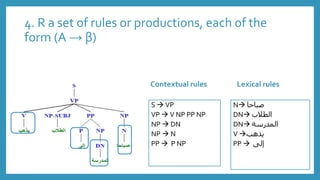
![How to calculate probability of rules
• P(X |Y ) =
𝐶𝑜𝑢𝑛𝑡 𝑋 𝑌)
𝐶𝑜𝑢𝑛𝑡 (𝑌)
P(VP V) =
𝐶𝑜𝑢𝑛𝑡 𝑉 𝑉𝑃)
𝐶𝑜𝑢𝑛𝑡 (𝑉𝑃)
P(VP V NP) =
𝐶𝑜𝑢𝑛𝑡 𝑉 𝑁𝑃 𝑉𝑃)
𝐶𝑜𝑢𝑛𝑡 (𝑉𝑃)
113/183
70/183
VP V 113
VP V NP 70
[0.6]
[0.4]](https://image.slidesharecdn.com/arabicsyntacticparsing-210418201647/85/Arabic-syntactic-parsing-34-320.jpg)



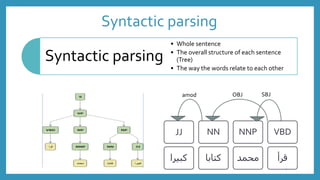
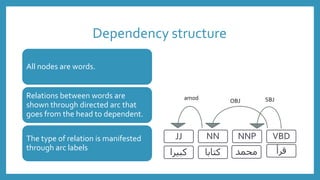
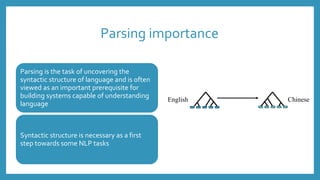
The document discusses Arabic syntactic parsing. It introduces part-of-speech tagging, which assigns grammatical categories to individual words. Syntactic parsing then determines the overall structure of each sentence by showing how words relate to each other through trees or dependency structures. Parsing uncovers the syntactic structure of language and is important for natural language processing tasks, but Arabic presents challenges like complex morphology, pro-drop verbs, and flexible word order.