Ambari page는 http://[AMBARI_SERVER_HOST_NAME]:8080으로 접속할 수 있습니다. Admin 계정의 기본 정보는
ID : admin, PASS : admin 입니다.
1) Ambari Dashboard UI
1. Ambari Dashboard
3
* Ambari server Port 변경은 /etc/ambari-server/conf/ambari.properties의 client.api.port 정보를 변경 또는 추가
4.
4
Ambari UI 위쪽에는다음과 같은 표시 줄이 있습니다. 이 표시줄에는 다음 정보 및 컨트롤이 포함되어 있습니다.
2) Status Bar
1. Ambari Dashboard
•Ambari 로고 - 클러스터를 모니터링하는 데 사용할 수 있는 대시보드를 엽니다.
•클러스터 이름 # ops - 진행 중인 Ambari 작업 수를 표시합니다. 클러스터 이름
또는 # ops를 선택하면 백그라운드 작업 목록이 표시됩니다.
•# alerts - 클러스터에 대한 경고 또는 중요한 알림(있을 경우)을 표시합니다.
•Dashboard - 대시보드를 표시합니다.
•Services - 클러스터의 서비스에 대한 정보 및 구성 설정입니다.
•Hosts - 클러스터의 노드에 대한 정보 및 구성 설정입니다.
•Alerts - 정보, 경고 및 중요한 알림에 대한 로그입니다.
•Admin - 클러스터에 설치된 소프트웨어 스택/서비스, 서비스 계정 정보 및
Kerberos 보안 설정이 가능합니다.
•Admin 단추 - Ambari 관리, 사용자 설정 및 로그 아웃입니다.
5.
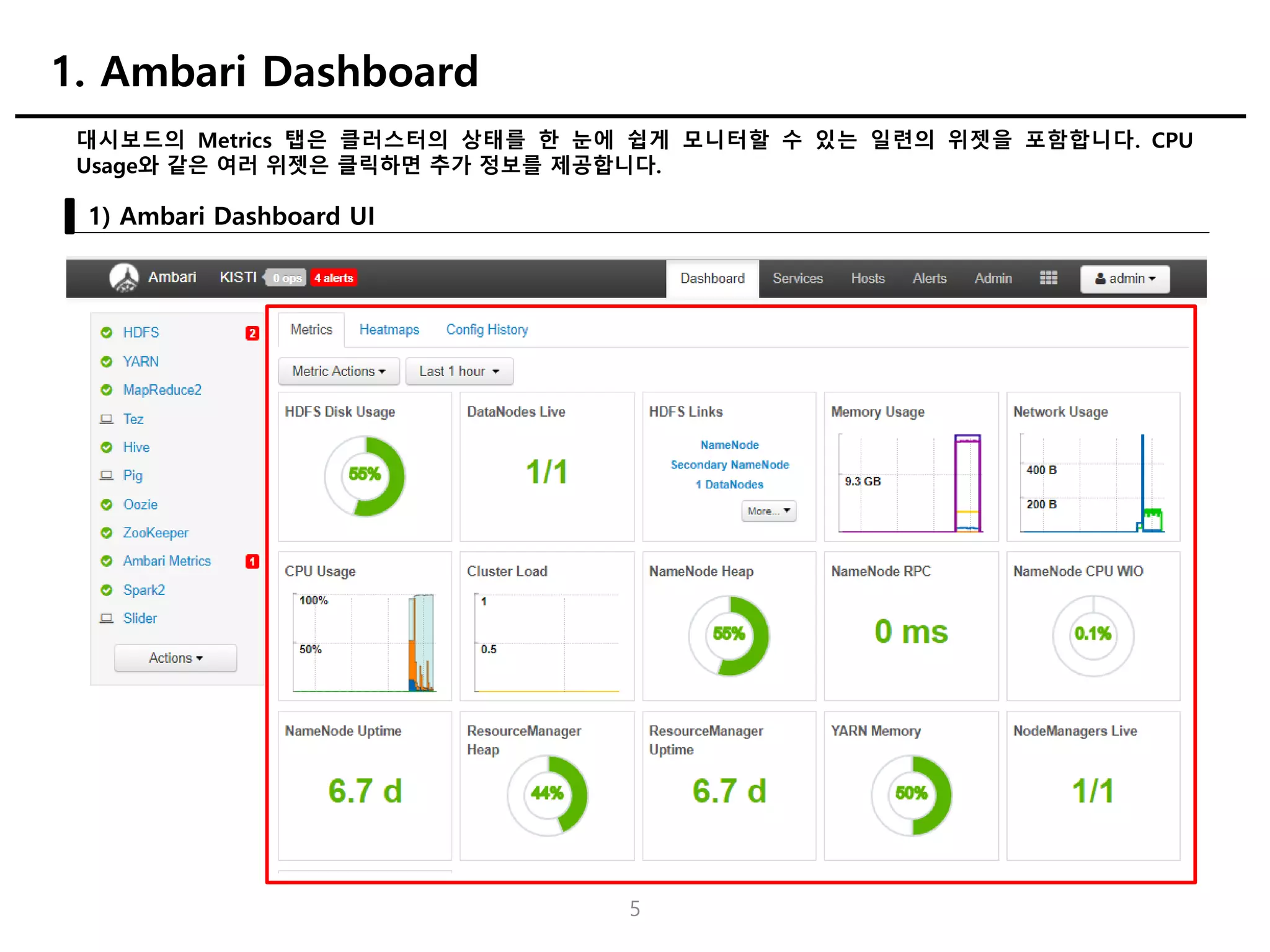
대시보드의 Metrics 탭은클러스터의 상태를 한 눈에 쉽게 모니터할 수 있는 일련의 위젯을 포함합니다. CPU
Usage와 같은 여러 위젯은 클릭하면 추가 정보를 제공합니다.
1) Ambari Dashboard UI
1. Ambari Dashboard
5
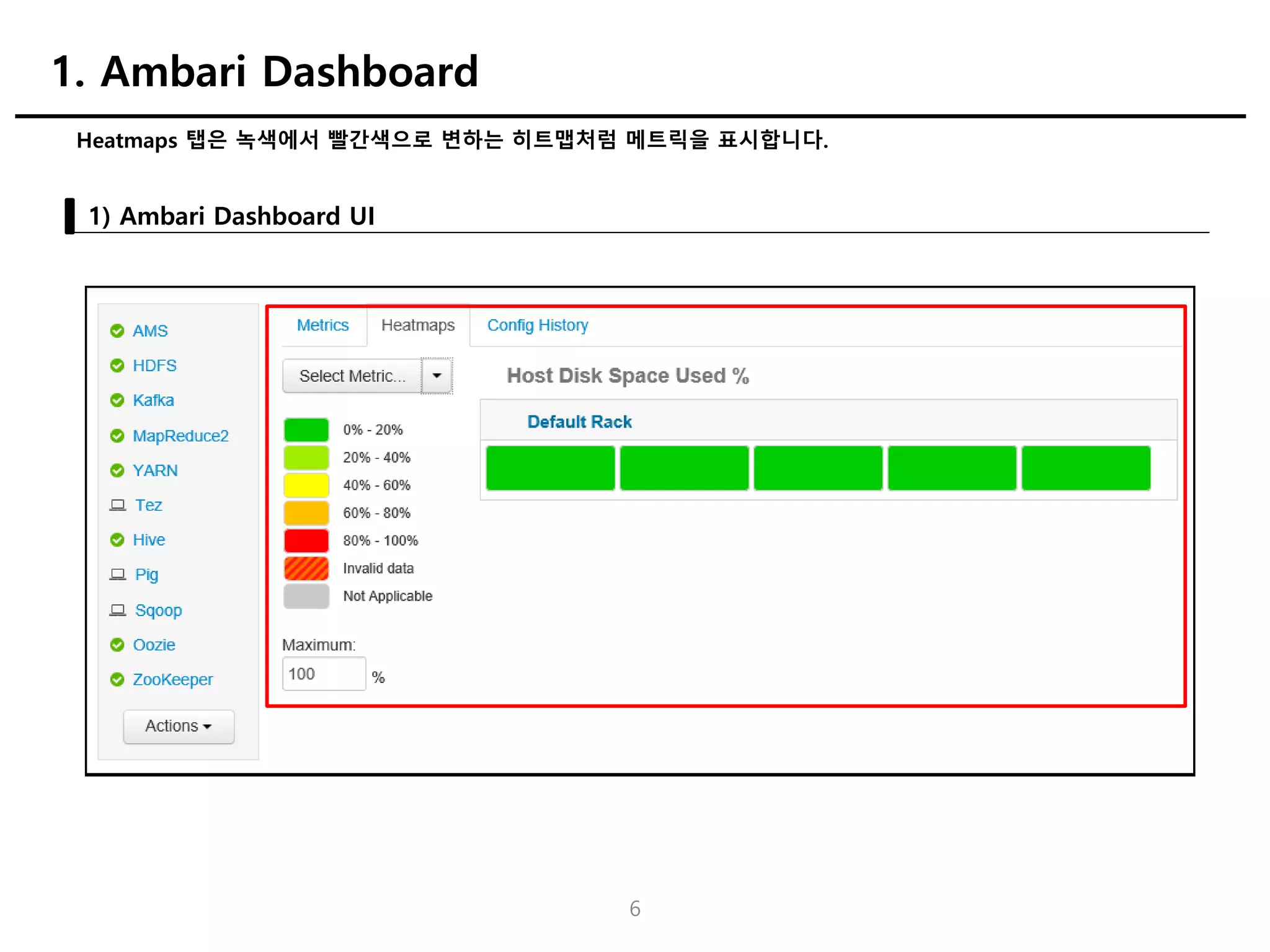
7
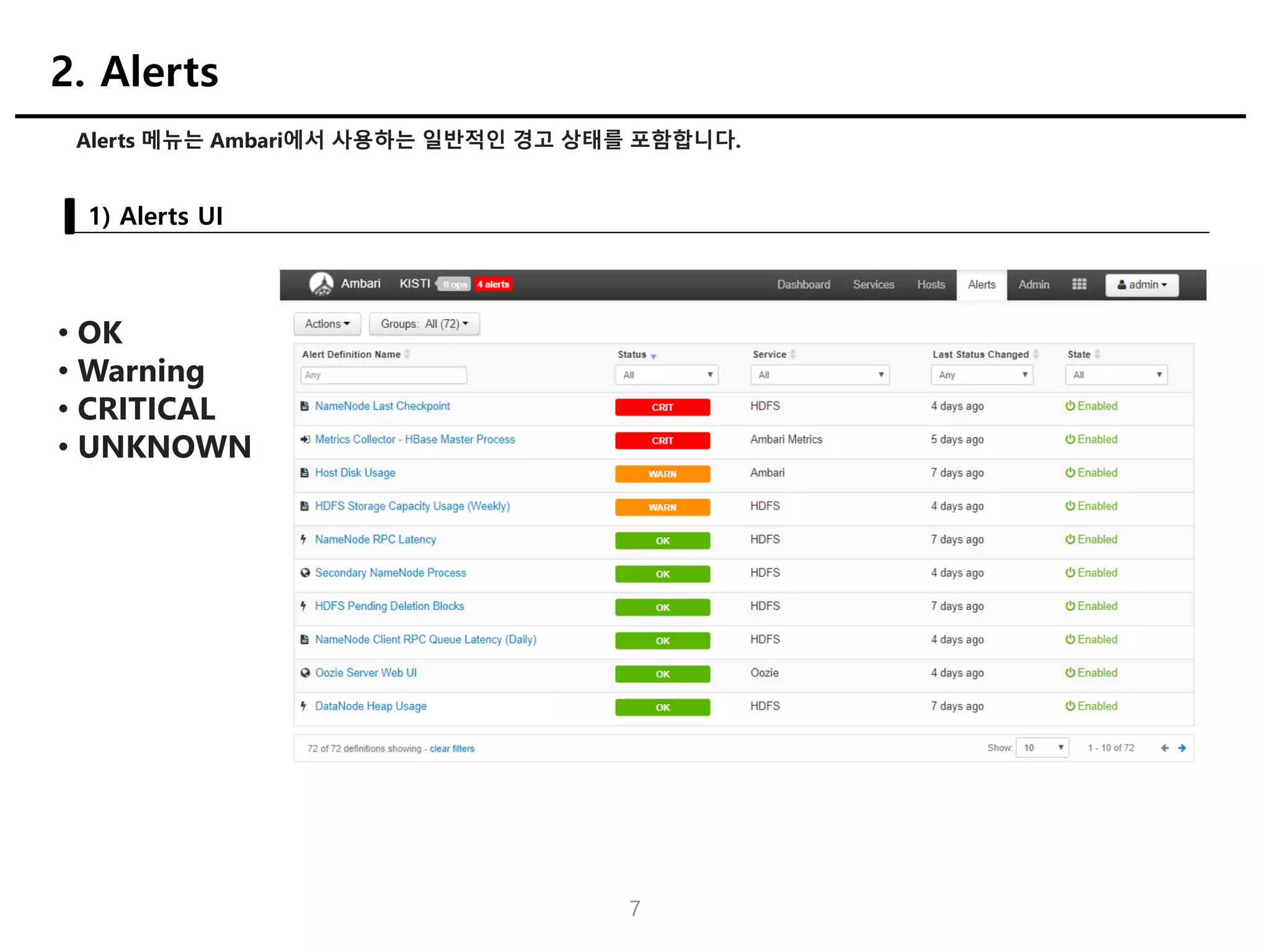
Alerts 메뉴는 Ambari에서사용하는 일반적인 경고 상태를 포함합니다.
1) Alerts UI
2. Alerts
• OK
• Warning
• CRITICAL
• UNKNOWN
8.
8
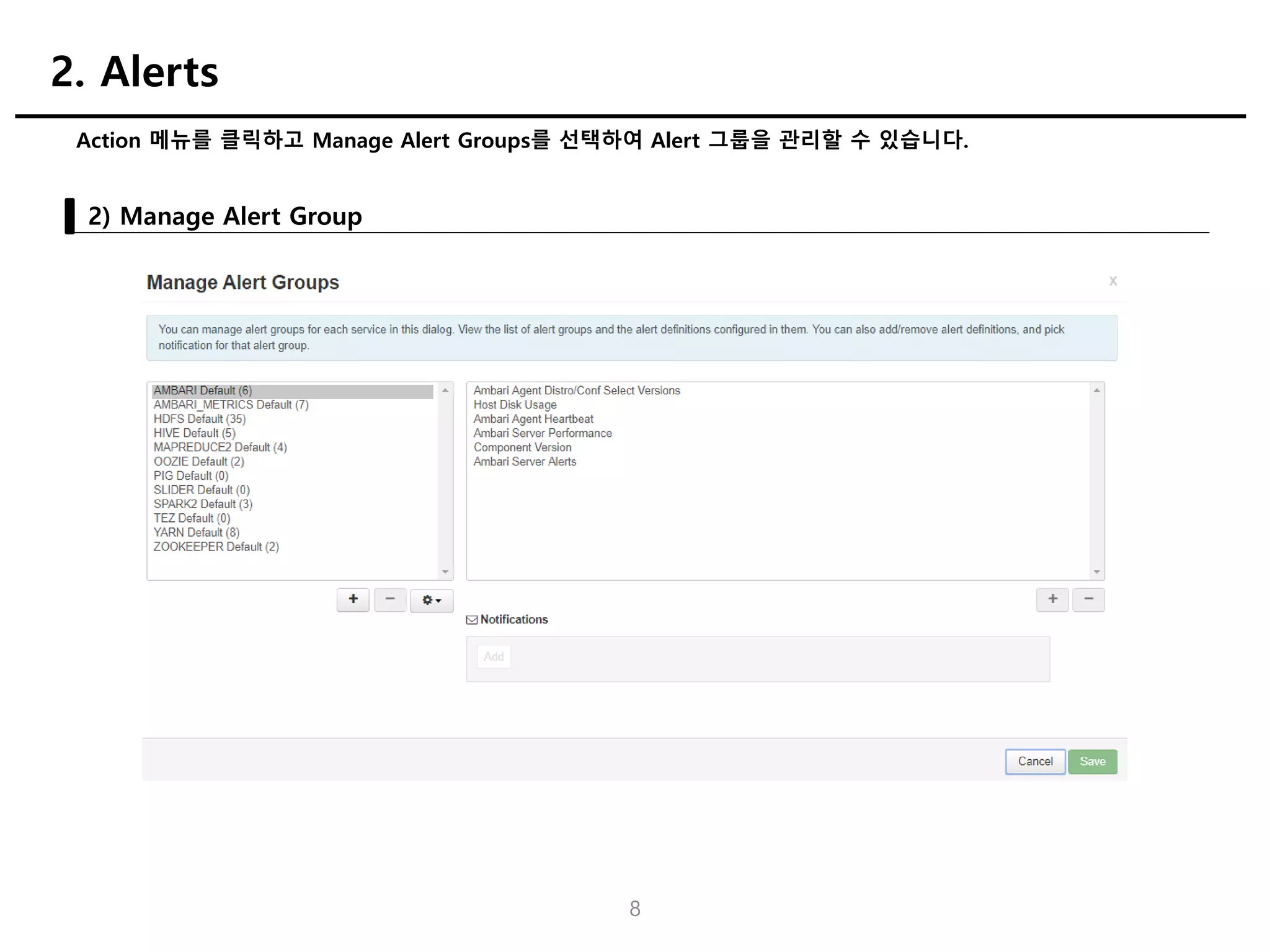
Action 메뉴를 클릭하고Manage Alert Groups를 선택하여 Alert 그룹을 관리할 수 있습니다.
2) Manage Alert Group
2. Alerts
9.
9
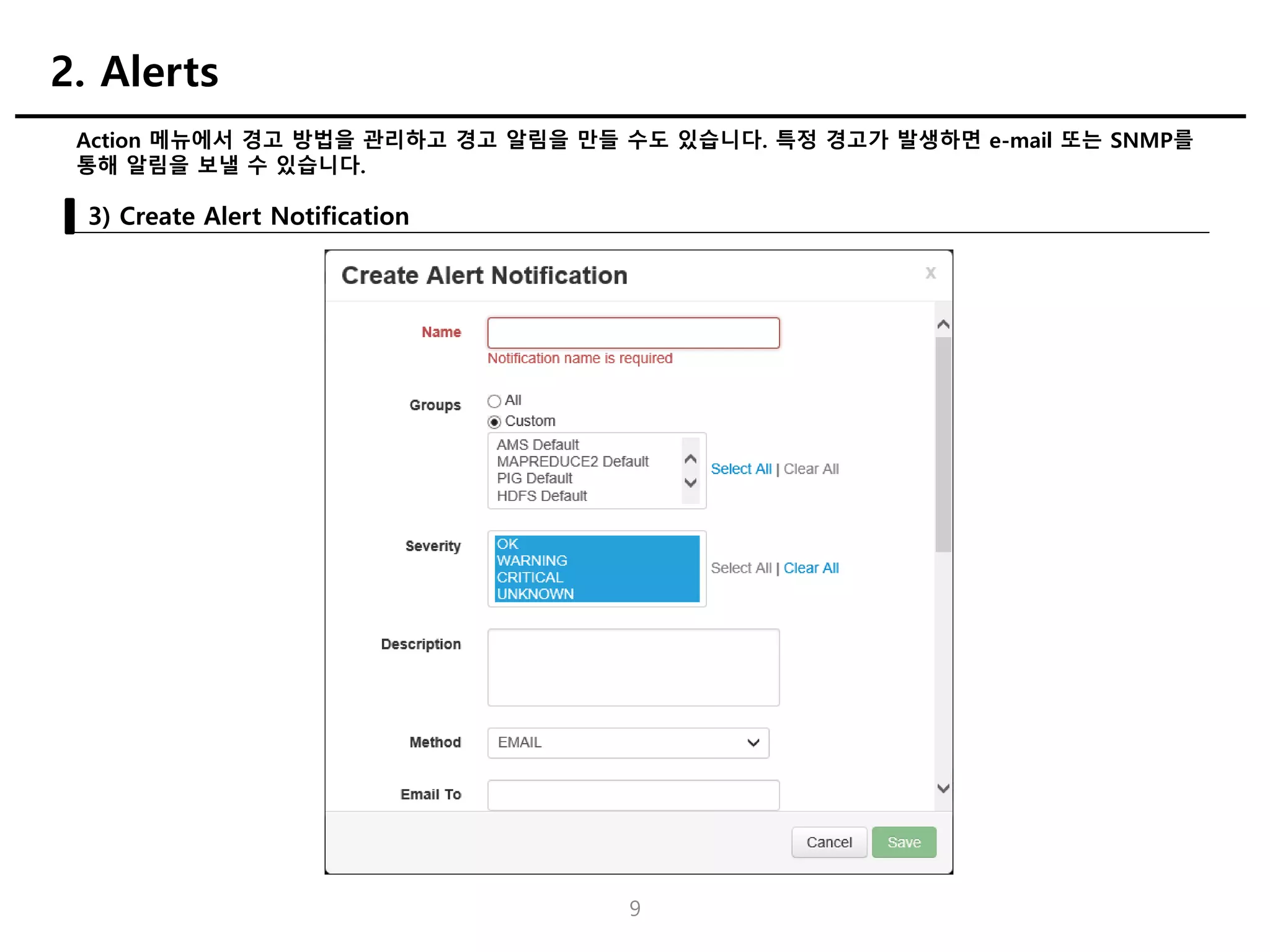
Action 메뉴에서 경고방법을 관리하고 경고 알림을 만들 수도 있습니다. 특정 경고가 발생하면 e-mail 또는 SNMP를
통해 알림을 보낼 수 있습니다.
3) Create Alert Notification
2. Alerts
10.
10
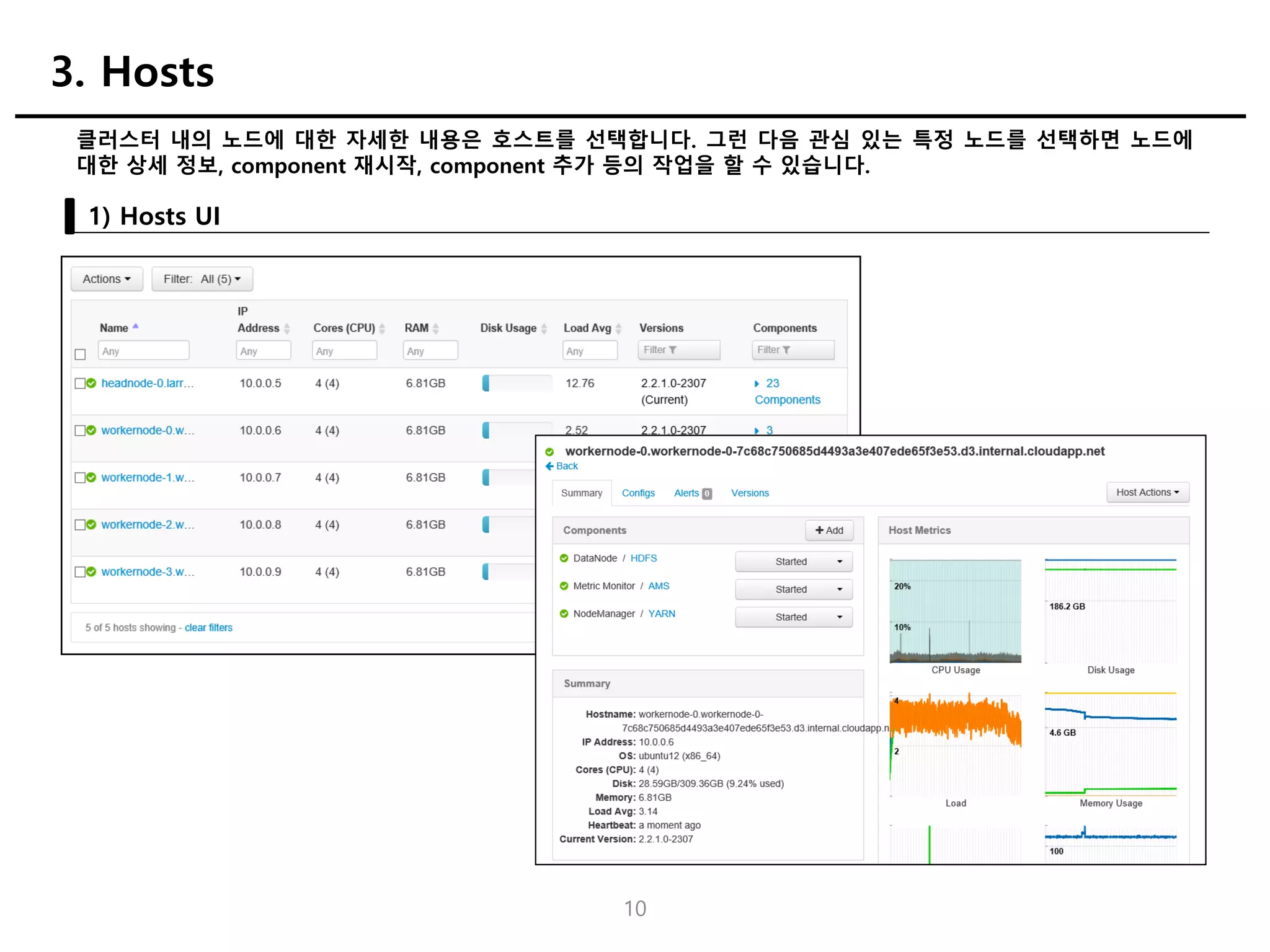
클러스터 내의 노드에대한 자세한 내용은 호스트를 선택합니다. 그런 다음 관심 있는 특정 노드를 선택하면 노드에
대한 상세 정보, component 재시작, component 추가 등의 작업을 할 수 있습니다.
1) Hosts UI
3. Hosts
11.
11
Hosts 탭에서는 다음과같은 작업을 수행할 수 있습니다.
2) Host Actions
3. Hosts
Actions 메뉴를 사용하여 수행할 작업을 선택합니다.
• Start all components - 호스트에서 모든 구성 요소를
시작합니다.
• Stop all components - 호스트에서 모든 구성 요소를
중지합니다.
• Restart all components - 호스트에서 모든 구성 요소
를 중지하고 시작합니다.
• Turn on maintenance mode - 호스트에 대한 경고를
표시하지 않습니다. 경고를 생성하는 작업을 수행하는
경우 이 모드를 활성화해야 합니다. 예를 들어 서비스를
중지하고 시작합니다.
• Turn off maintenance mode - 호스트를 정상 경고 상
태로 되돌립니다.
• Stop - 호스트에서 DataNode 또는 NodeManagers를
중지합니다.
• Start - 호스트에서 DataNode 또는 NodeManagers를
시작합니다.
• Restart - 호스트에서 DataNode 또는 NodeManagers
를 중지하고 시작합니다.
• Decommission - 호스트를 클러스터에서 제거합니다.
• Recommission - 이전에 서비스를 해지한 호스트를
클러스터에 추가합니다.
12.
12
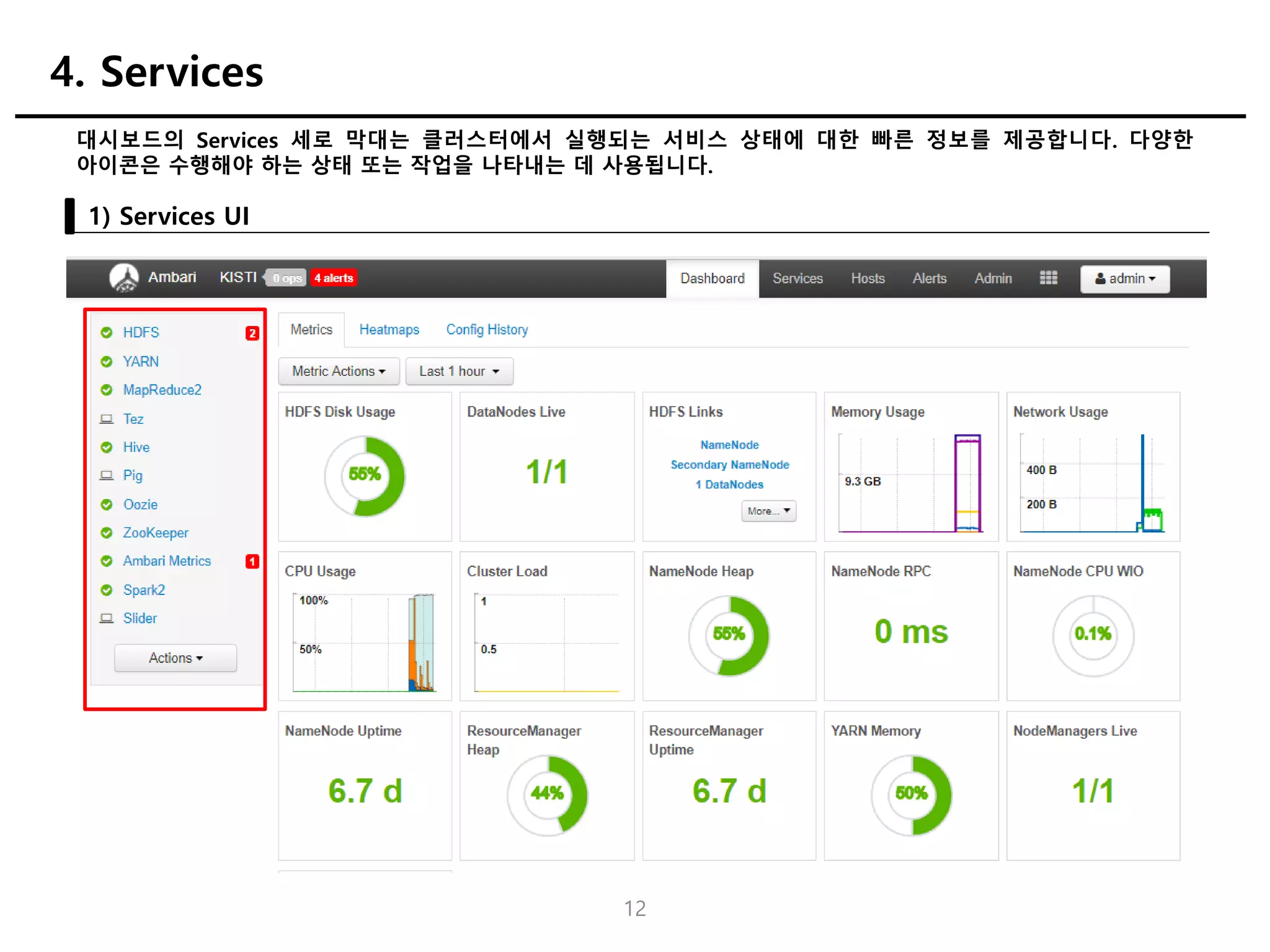
대시보드의 Services 세로막대는 클러스터에서 실행되는 서비스 상태에 대한 빠른 정보를 제공합니다. 다양한
아이콘은 수행해야 하는 상태 또는 작업을 나타내는 데 사용됩니다.
1) Services UI
4. Services
13.
13
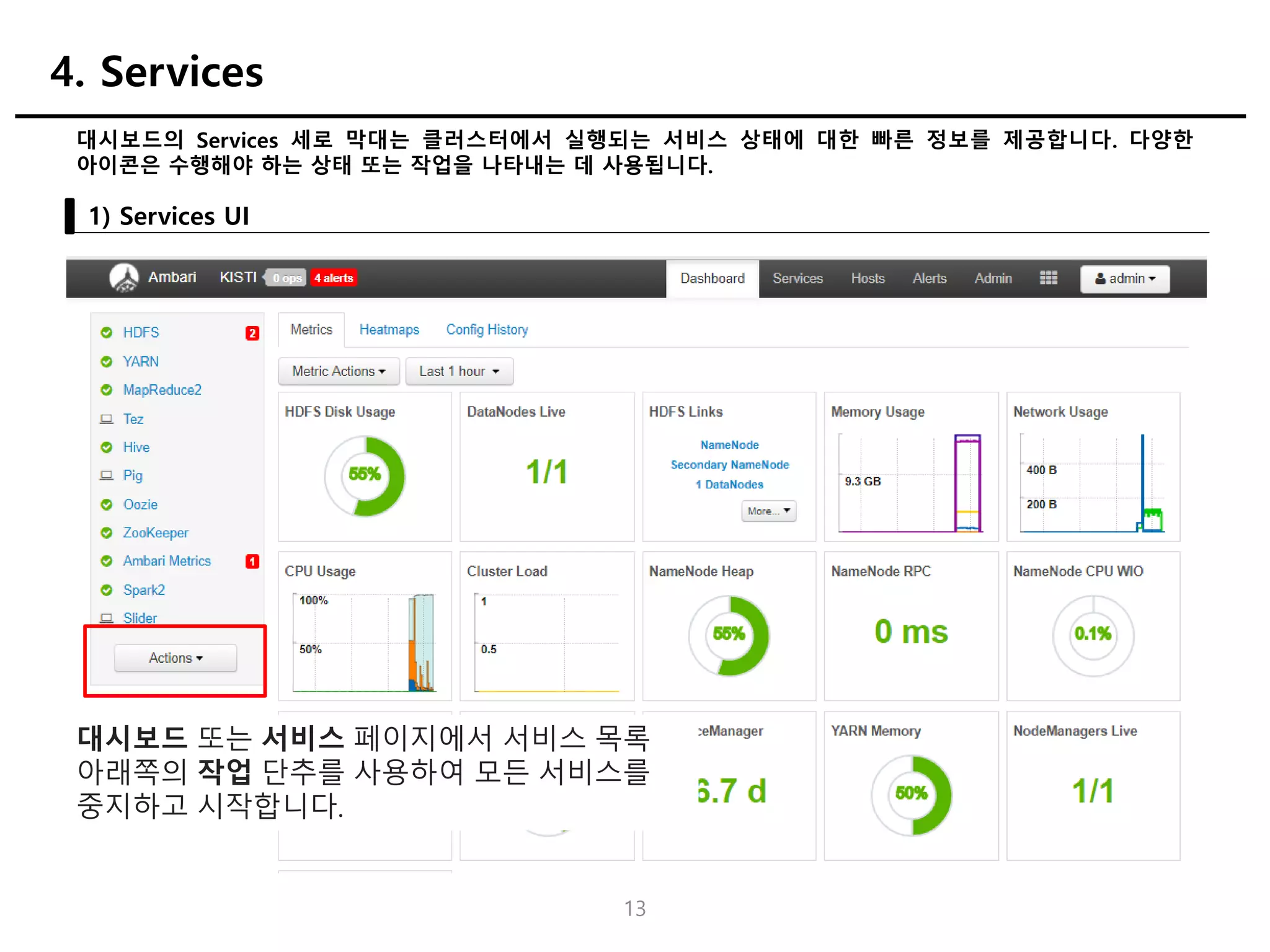
대시보드의 Services 세로막대는 클러스터에서 실행되는 서비스 상태에 대한 빠른 정보를 제공합니다. 다양한
아이콘은 수행해야 하는 상태 또는 작업을 나타내는 데 사용됩니다.
1) Services UI
4. Services
대시보드 또는 서비스 페이지에서 서비스 목록
아래쪽의 작업 단추를 사용하여 모든 서비스를
중지하고 시작합니다.
14.
14
특정 서비스를 선택하면해당 서비스에 대한 자세한 정보가 표시됩니다.
1) Services UI
4. Services
15.
15
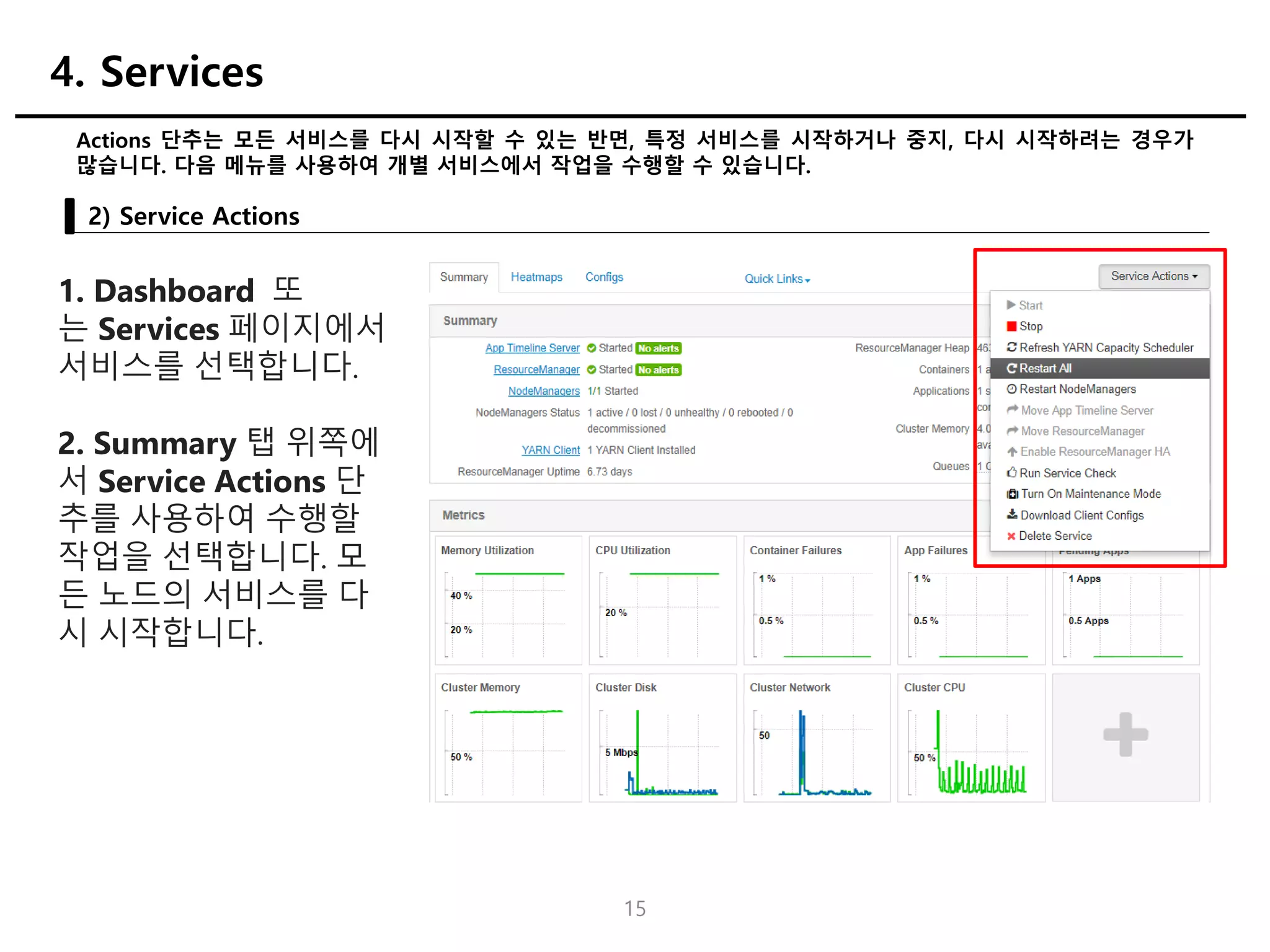
Actions 단추는 모든서비스를 다시 시작할 수 있는 반면, 특정 서비스를 시작하거나 중지, 다시 시작하려는 경우가
많습니다. 다음 메뉴를 사용하여 개별 서비스에서 작업을 수행할 수 있습니다.
2) Service Actions
4. Services
1. Dashboard 또
는 Services 페이지에서
서비스를 선택합니다.
2. Summary 탭 위쪽에
서 Service Actions 단
추를 사용하여 수행할
작업을 선택합니다. 모
든 노드의 서비스를 다
시 시작합니다.
16.
16
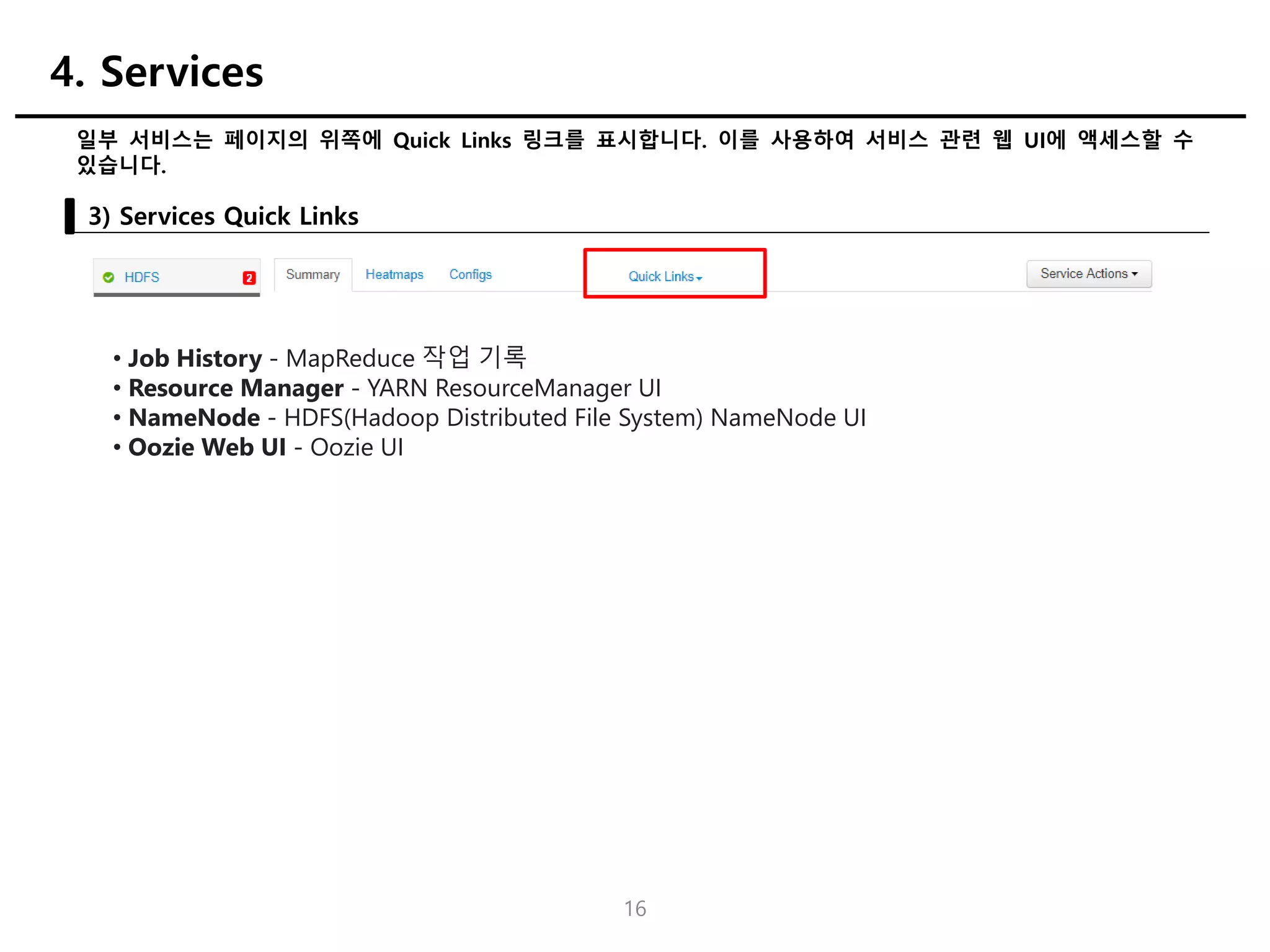
일부 서비스는 페이지의위쪽에 Quick Links 링크를 표시합니다. 이를 사용하여 서비스 관련 웹 UI에 액세스할 수
있습니다.
3) Services Quick Links
4. Services
• Job History - MapReduce 작업 기록
• Resource Manager - YARN ResourceManager UI
• NameNode - HDFS(Hadoop Distributed File System) NameNode UI
• Oozie Web UI - Oozie UI
17.
17
View는 3rd PartyAPI 및 UI와 함께 플러그인하여 Ambari를 확장하는 방법입니다. Hortonworks Ambari에서는
기본적으로 HDFS, YARN, HIVE 등에 대한 View를 제공합니다.
1) View UI
5. View
• Yarn 큐 관리자: 큐 관리자는 YARN 큐를 보고 수정하기 위한 간단한 UI를
제공합니다.
• Hive 뷰: Hive 뷰를 사용하면 웹 브라우저에서 직접 Hive 쿼리를 실행할 수
있습니다. 쿼리를 저장하고 결과 확인하며 클러스터 저장소에 결과를 저장
하거나 로컬 시스템에 다운로드할 수 있습니다.
18.
18
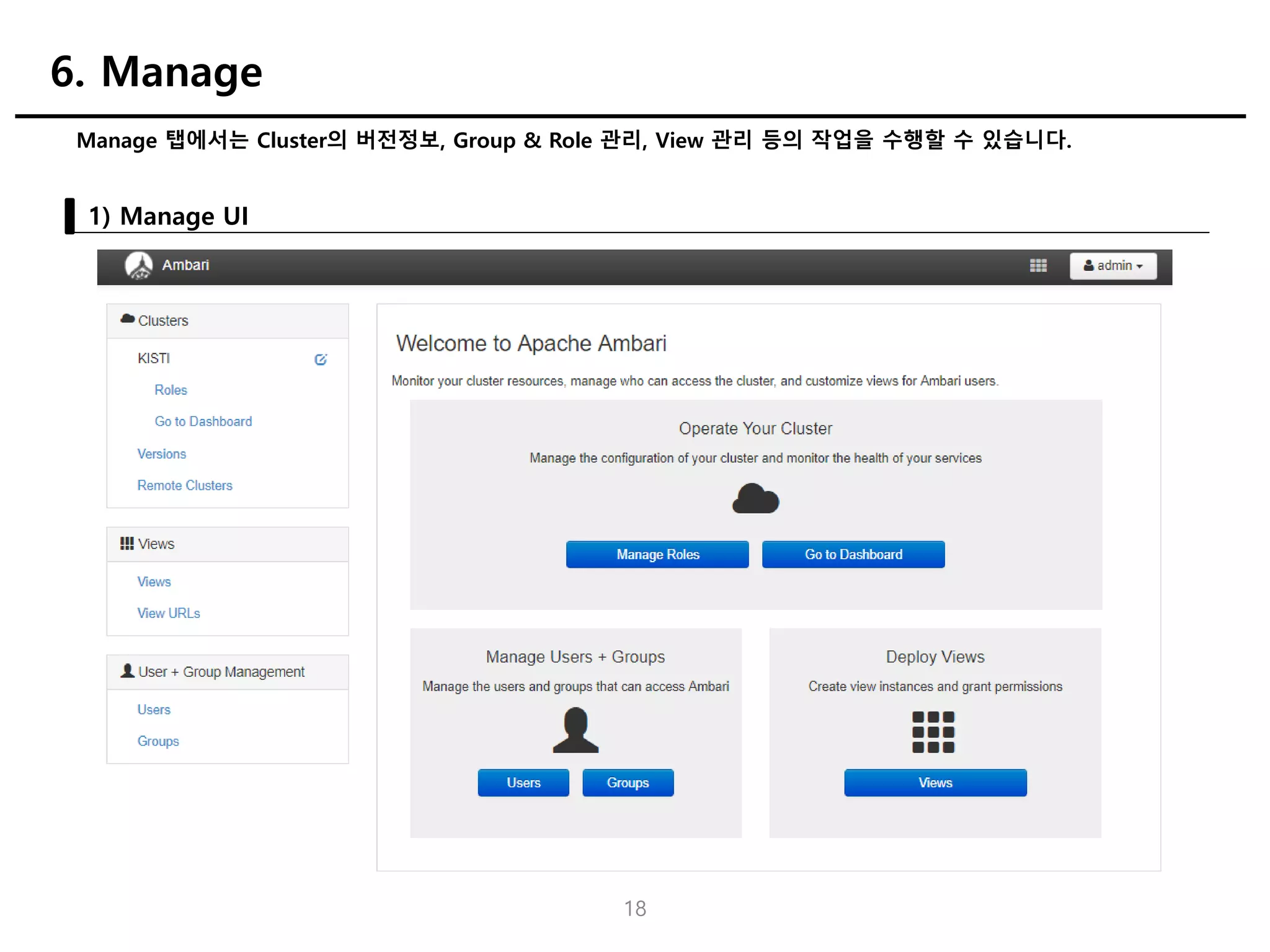
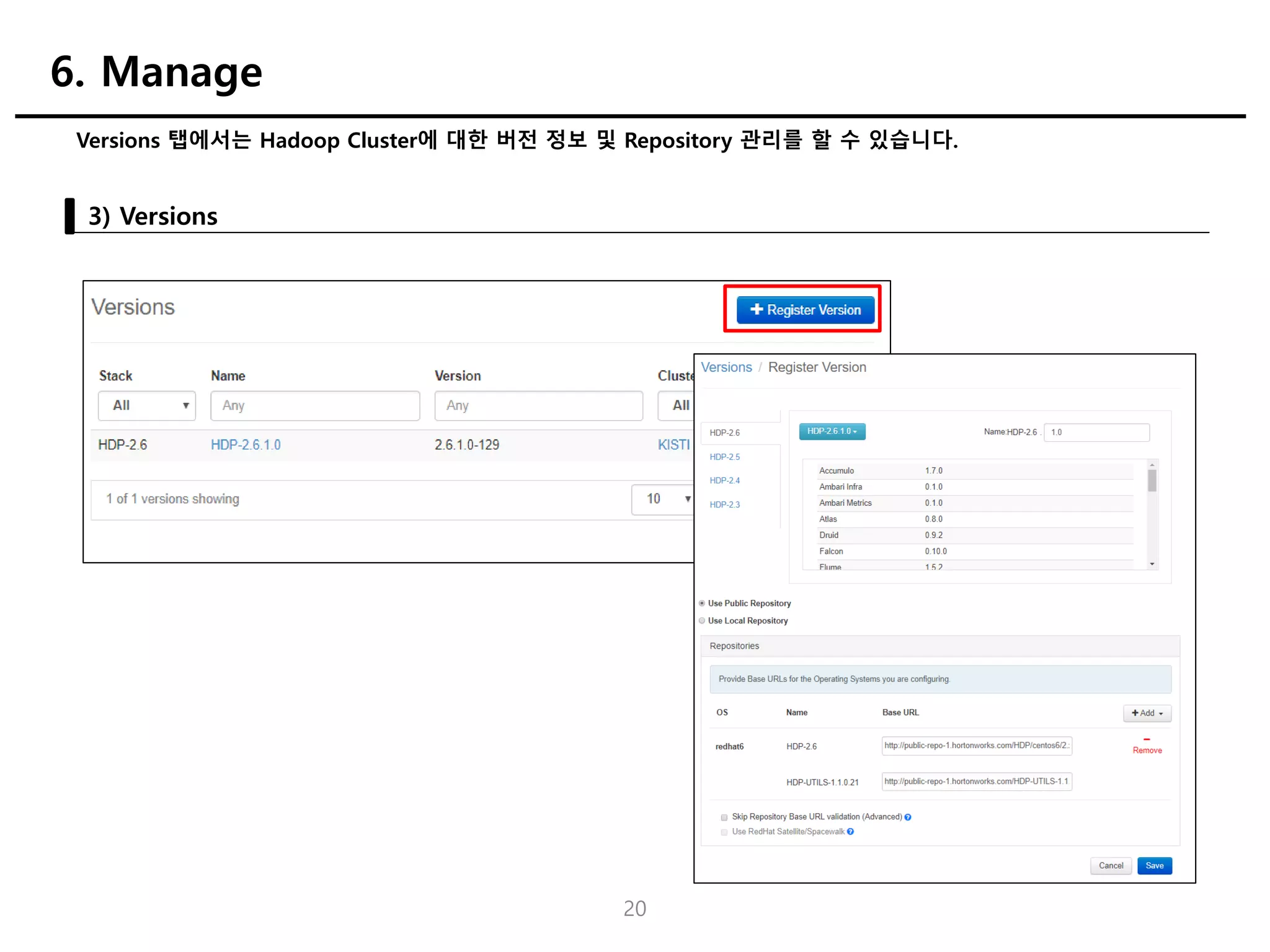
Manage 탭에서는 Cluster의버전정보, Group & Role 관리, View 관리 등의 작업을 수행할 수 있습니다.
1) Manage UI
6. Manage
19.
19
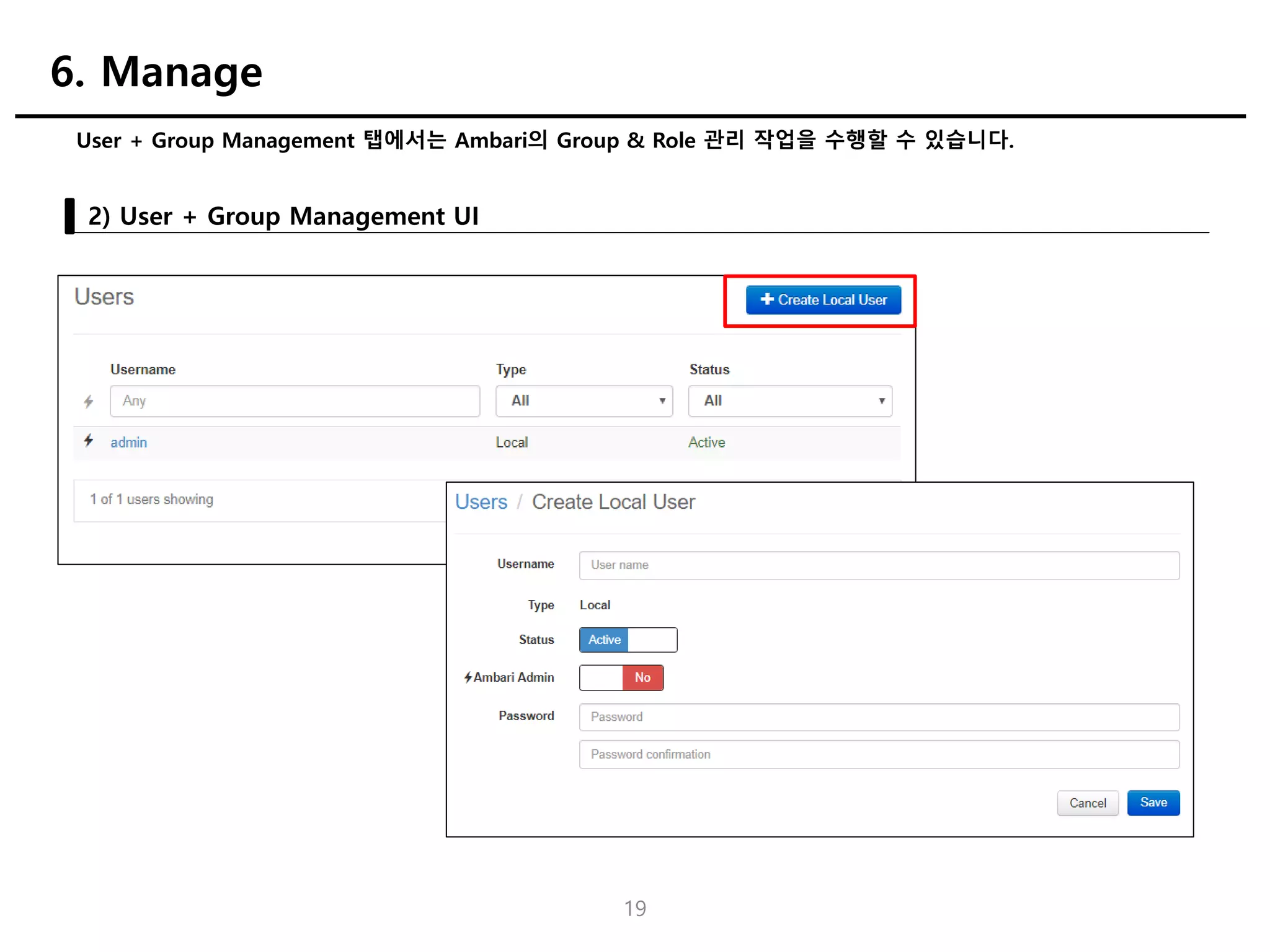
User + GroupManagement 탭에서는 Ambari의 Group & Role 관리 작업을 수행할 수 있습니다.
2) User + Group Management UI
6. Manage
21
1) Ambari Server재시작 & postgresql 재시작
[참고] Ambari 서비스 재시작
1. Ambari Server 재시작
# ssh hdm1
# su - root
# ambari-server restart
Using python /usr/bin/python
Restarting ambari-server
Waiting for server stop...
Ambari Server stopped
Ambari Server running with administrator privileges.
Organizing resource files at /var/lib/ambari-server/resources...
Ambari database consistency check started...
Server PID at: /var/run/ambari-server/ambari-server.pid
Server out at: /var/log/ambari-server/ambari-server.out
Server log at: /var/log/ambari-server/ambari-server.log
Waiting for server start.................................................
Server started listening on 8080
2. postgresql 재시작
# ssh hdm1
# su - root
# service postgresql restart
22.
22
2) Ambari Agent재시작
[참고] Ambari 서비스 재시작
## 모든 클러스터 호스트에서 수행
# su - root
>> ambari-agent restart
[hdm1] Restarting ambari-agent
[hdm1] Verifying Python version compatibility...
[hdm1] Using python /usr/bin/python
[hdm1] Found ambari-agent PID: 50225
[hdm1] Stopping ambari-agent
[hdm1] Removing PID file at /run/ambari-agent/ambari-agent.pid
[hdm1] ambari-agent successfully stopped
[hdm1] Verifying Python version compatibility...
[hdm1] Using python /usr/bin/python
[hdm1] Checking for previously running Ambari Agent...
[hdm1] Starting ambari-agent
[hdm1] Verifying ambari-agent process status...
[hdm1] Ambari Agent successfully started
[hdm1] Agent PID at: /run/ambari-agent/ambari-agent.pid
[hdm1] Agent out at: /var/log/ambari-agent/ambari-agent.out
[hdm1] Agent log at: /var/log/ambari-agent/ambari-agent.log
23.
Service 상태 점검
#curl -u admin:admin -X GET http://[SERVER_HOSTNAME]:8080/api/v1/clusters/ [CLUSTER_NAME] /services/[SERVICE_NAME]
# curl -u admin:admin -X GET http://192.168.11.148:8080/api/v1/clusters/prum/services/HAWQ
Service 중지
# curl -u admin:admin -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service via REST
"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http:// [SERVER_HOSTNAME] :8080/api/v1/clusters/[CLUSTER_NAME]/services/ [SERVICE_NAME]
curl -u admin:admin -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service via REST
"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http://192.168.11.148:8080/api/v1/clusters/prum/services/HAWQ
Service 시작
# curl -u admin:admin -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start Service via REST"}, "Body": {"ServiceInfo": {"state":
"STARTED"}}}' http:// [SERVER_HOSTNAME] :8080/api/v1/clusters/[CLUSTER_NAME]/services/ [SERVICE_NAME]
# curl -u admin:admin -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start Service via REST"}, "Body": {"ServiceInfo": {"state":
"STARTED"}}}' http://hdm1.gphd.local:8080/api/v1/clusters/sdi/services/HDFS
Configuration 수정
- 주의점 : delete 시 Ambari UI 상에서 완전 삭제 됨, set을 이용하여 다시 추가 가능
- set을 이용하여 추가 시 Advanced에 추가되는 것이 아닌 Custom으로 추가 됨, 원래 위치가 Advanced 여도 마찬가지
# /var/lib/ambari-server/resources/scripts/configs.sh [set|get|delete] [hostname] [clustername] [config_file_name] [config_key] [config_value]
# /var/lib/ambari-server/resources/scripts/configs.sh set localhost sdi mapred-site "mapreduce.map.memory.mb" "512"
# /var/lib/ambari-server/resources/scripts/configs.sh get localhost sdi mapred-site
# /var/lib/ambari-server/resources/scripts/configs.sh delete localhost sdi mapred-site "mapreduce.map.memory.mb“
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=41812517
23
Apache Ambari를 REST API를 통해 조작하는 방법에 대해 설명합니다.
1) Ambari REST API
[참고] Ambari REST API


![Ambari page는 http://[AMBARI_SERVER_HOST_NAME]:8080 으로 접속할 수 있습니다. Admin 계정의 기본 정보는
ID : admin, PASS : admin 입니다.
1) Ambari Dashboard UI
1. Ambari Dashboard
3
* Ambari server Port 변경은 /etc/ambari-server/conf/ambari.properties의 client.api.port 정보를 변경 또는 추가](https://image.slidesharecdn.com/apacehambari-170914044620/75/Apaceh-Ambari-Overview-3-2048.jpg)




![21
1) Ambari Server 재시작 & postgresql 재시작
[참고] Ambari 서비스 재시작
1. Ambari Server 재시작
# ssh hdm1
# su - root
# ambari-server restart
Using python /usr/bin/python
Restarting ambari-server
Waiting for server stop...
Ambari Server stopped
Ambari Server running with administrator privileges.
Organizing resource files at /var/lib/ambari-server/resources...
Ambari database consistency check started...
Server PID at: /var/run/ambari-server/ambari-server.pid
Server out at: /var/log/ambari-server/ambari-server.out
Server log at: /var/log/ambari-server/ambari-server.log
Waiting for server start.................................................
Server started listening on 8080
2. postgresql 재시작
# ssh hdm1
# su - root
# service postgresql restart](https://image.slidesharecdn.com/apacehambari-170914044620/75/Apaceh-Ambari-Overview-21-2048.jpg)
![22
2) Ambari Agent 재시작
[참고] Ambari 서비스 재시작
## 모든 클러스터 호스트에서 수행
# su - root
>> ambari-agent restart
[hdm1] Restarting ambari-agent
[hdm1] Verifying Python version compatibility...
[hdm1] Using python /usr/bin/python
[hdm1] Found ambari-agent PID: 50225
[hdm1] Stopping ambari-agent
[hdm1] Removing PID file at /run/ambari-agent/ambari-agent.pid
[hdm1] ambari-agent successfully stopped
[hdm1] Verifying Python version compatibility...
[hdm1] Using python /usr/bin/python
[hdm1] Checking for previously running Ambari Agent...
[hdm1] Starting ambari-agent
[hdm1] Verifying ambari-agent process status...
[hdm1] Ambari Agent successfully started
[hdm1] Agent PID at: /run/ambari-agent/ambari-agent.pid
[hdm1] Agent out at: /var/log/ambari-agent/ambari-agent.out
[hdm1] Agent log at: /var/log/ambari-agent/ambari-agent.log](https://image.slidesharecdn.com/apacehambari-170914044620/75/Apaceh-Ambari-Overview-22-2048.jpg)
![Service 상태 점검
# curl -u admin:admin -X GET http://[SERVER_HOSTNAME]:8080/api/v1/clusters/ [CLUSTER_NAME] /services/[SERVICE_NAME]
# curl -u admin:admin -X GET http://192.168.11.148:8080/api/v1/clusters/prum/services/HAWQ
Service 중지
# curl -u admin:admin -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service via REST
"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http:// [SERVER_HOSTNAME] :8080/api/v1/clusters/[CLUSTER_NAME]/services/ [SERVICE_NAME]
curl -u admin:admin -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service via REST
"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http://192.168.11.148:8080/api/v1/clusters/prum/services/HAWQ
Service 시작
# curl -u admin:admin -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start Service via REST"}, "Body": {"ServiceInfo": {"state":
"STARTED"}}}' http:// [SERVER_HOSTNAME] :8080/api/v1/clusters/[CLUSTER_NAME]/services/ [SERVICE_NAME]
# curl -u admin:admin -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start Service via REST"}, "Body": {"ServiceInfo": {"state":
"STARTED"}}}' http://hdm1.gphd.local:8080/api/v1/clusters/sdi/services/HDFS
Configuration 수정
- 주의점 : delete 시 Ambari UI 상에서 완전 삭제 됨, set을 이용하여 다시 추가 가능
- set을 이용하여 추가 시 Advanced에 추가되는 것이 아닌 Custom으로 추가 됨, 원래 위치가 Advanced 여도 마찬가지
# /var/lib/ambari-server/resources/scripts/configs.sh [set|get|delete] [hostname] [clustername] [config_file_name] [config_key] [config_value]
# /var/lib/ambari-server/resources/scripts/configs.sh set localhost sdi mapred-site "mapreduce.map.memory.mb" "512"
# /var/lib/ambari-server/resources/scripts/configs.sh get localhost sdi mapred-site
# /var/lib/ambari-server/resources/scripts/configs.sh delete localhost sdi mapred-site "mapreduce.map.memory.mb“
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=41812517
23
Apache Ambari를 REST API를 통해 조작하는 방법에 대해 설명합니다.
1) Ambari REST API
[참고] Ambari REST API](https://image.slidesharecdn.com/apacehambari-170914044620/75/Apaceh-Ambari-Overview-23-2048.jpg)



![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)

![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)




![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)
![Docker 기본 및 Docker Swarm을 활용한 분산 서버 관리 A부터 Z까지 [전체모드에서 봐주세요]](https://cdn.slidesharecdn.com/ss_thumbnails/dockerandswarmmode-181009120848-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Atlassian meets dev ops and itsm] kakao meets jira](https://cdn.slidesharecdn.com/ss_thumbnails/atlassianmeetsdevopsanditsmkakaomeetsjira-190424020429-thumbnail.jpg?width=640&height=640&fit=bounds)






![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)




