Download as PDF, PPTX










![Motivation
Approach
Evaluation
More Information
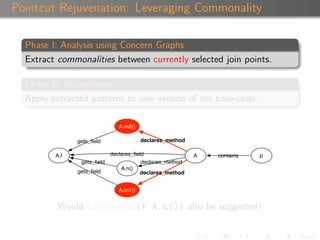
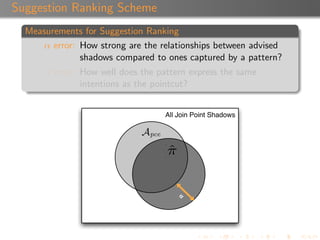
Suggestion Confidence
Each suggestion is associated with a confidence value ([0,1]).
A suggestion inherits the confidence of the pattern that
produced it.
A pattern’s confidence is calculated using a combination of α,
β, and the depth of the patterns.
Khatchadourian, Greenwood, Rashid, Xu Rejuvenate Pointcut](https://image.slidesharecdn.com/aosd09-101005223612-phpapp02/85/Rejuvenate-Pointcut-A-Tool-for-Pointcut-Expression-Recovery-in-Evolving-Aspect-Oriented-Software-29-320.jpg)
![Motivation
Approach
Evaluation
More Information
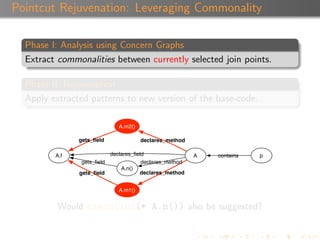
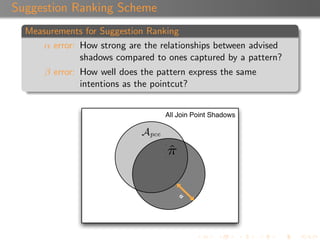
Suggestion Confidence
Each suggestion is associated with a confidence value ([0,1]).
A suggestion inherits the confidence of the pattern that
produced it.
A pattern’s confidence is calculated using a combination of α,
β, and the depth of the patterns.
Khatchadourian, Greenwood, Rashid, Xu Rejuvenate Pointcut](https://image.slidesharecdn.com/aosd09-101005223612-phpapp02/85/Rejuvenate-Pointcut-A-Tool-for-Pointcut-Expression-Recovery-in-Evolving-Aspect-Oriented-Software-30-320.jpg)
![Motivation
Approach
Evaluation
More Information
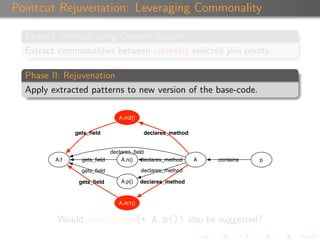
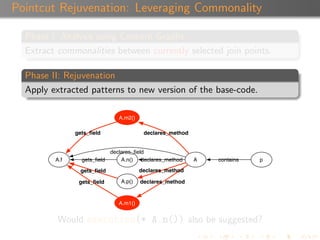
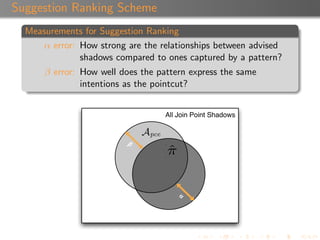
Suggestion Confidence
Each suggestion is associated with a confidence value ([0,1]).
A suggestion inherits the confidence of the pattern that
produced it.
A pattern’s confidence is calculated using a combination of α,
β, and the depth of the patterns.
Khatchadourian, Greenwood, Rashid, Xu Rejuvenate Pointcut](https://image.slidesharecdn.com/aosd09-101005223612-phpapp02/85/Rejuvenate-Pointcut-A-Tool-for-Pointcut-Expression-Recovery-in-Evolving-Aspect-Oriented-Software-31-320.jpg)
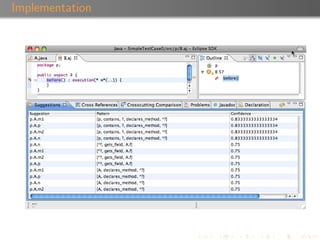










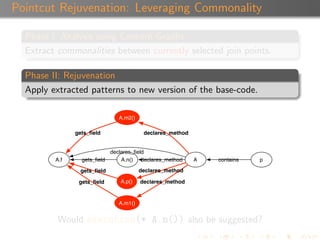
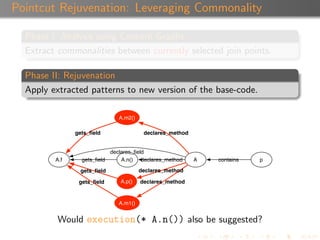
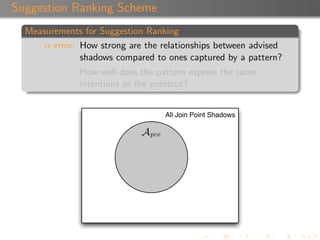
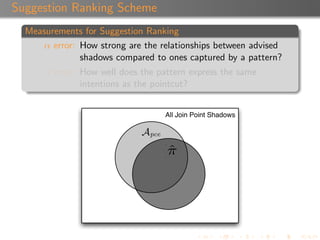
The document discusses 'Rejuvenate Pointcut', a technique for recovering pointcut expressions in evolving aspect-oriented software to maintain the integrity of pointcuts across code changes. It outlines the motivation behind the approach, the methodology for analyzing and rejuvenating pointcuts, and evaluation results demonstrating its effectiveness in identifying new join points introduced in later software versions. The research includes a tool for implementation, available for public use, along with related materials and technical reports.























































































