Download as PDF, PPTX






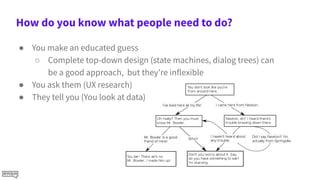













 ticket
● Need to book a [train](train) ride
● A [rail](train) journey please
● One [plane](air) ticket
● Need to book a [plane](air) ride
● i'd like to book a trip
● Need a vacation](https://image.slidesharecdn.com/aiyourdata1-210318165742/85/Ai-your-data-Rasa-Summit-2021-20-320.jpg)




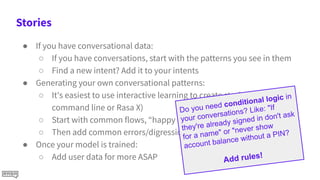




The document discusses the importance of data in building effective conversational AI systems and emphasizes understanding user needs through methods like UX research and analyzing patterns. It highlights the ideal approach of starting with a limited number of intents to streamline training and improve performance, while also advocating for the curation and annotation of data. The document further suggests utilizing user conversations to enhance the AI's understanding and iteratively improve its functionality.


































































