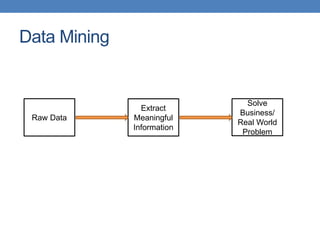
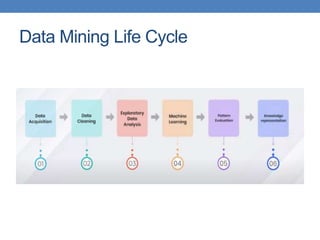
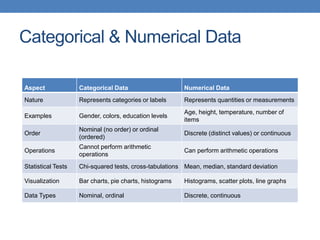
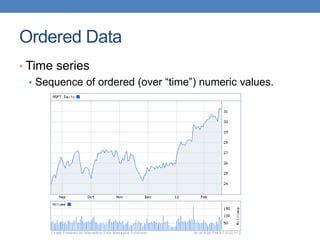
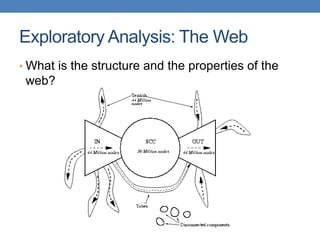
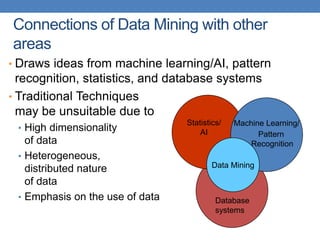
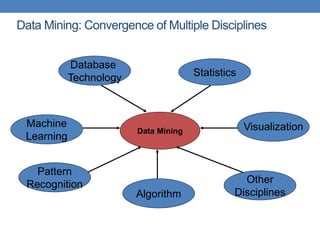
This document provides an introduction to data mining, emphasizing its definition as the analysis of large datasets to find useful patterns and insights. It discusses the necessity of data mining in handling vast amounts of data generated in the digital age and highlights various applications such as knowledge discovery, predictive analytics, and decision support. Additionally, the document describes types of data, their attributes, and the data mining process with examples across different domains.