This document provides information about a course on data mining and data warehousing. It includes the vision and mission statements of the university and computer science department. It outlines the program outcomes, program educational objectives, and course outcomes. Finally, it provides a detailed syllabus covering topics like data preprocessing, frequent pattern mining, classification, clustering, and data warehousing. The goal is to teach students how to extract useful patterns from data through techniques like association rule mining, classification, and clustering.











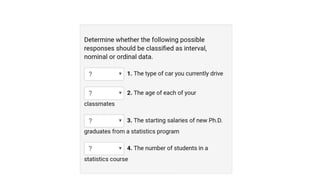
![1960s
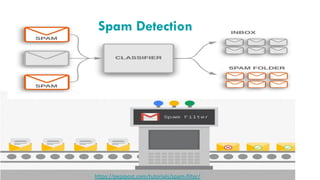
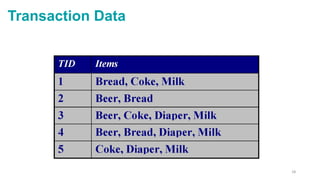
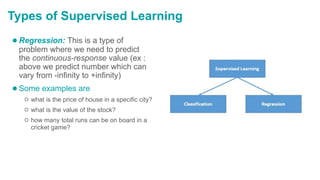
Data Collection
[Computers, Tape]
1970s
Data Access
Relational Database
1980s
Application oriented RDBMS
Object Oriented Model
1990s
Data Mining
Data Warehousing
2000s
Big Data Analytics
No-SQL
Evolution of Data Mining](https://image.slidesharecdn.com/dmdwunit1-221012065903-d1d22c93/85/DMDW-Unit-1-pdf-12-320.jpg)





















































































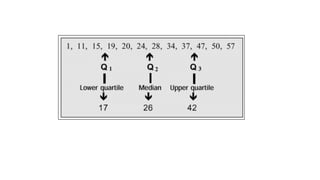


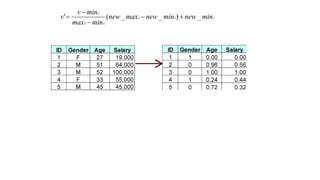
![Data Transformation: Normalization
●Min-max normalization: to [new_minA
, new_maxA
]
○ Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0]. Then
$73,600 is mapped to](https://image.slidesharecdn.com/dmdwunit1-221012065903-d1d22c93/85/DMDW-Unit-1-pdf-117-320.jpg)









![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)





