Download as PDF, PPTX

![3
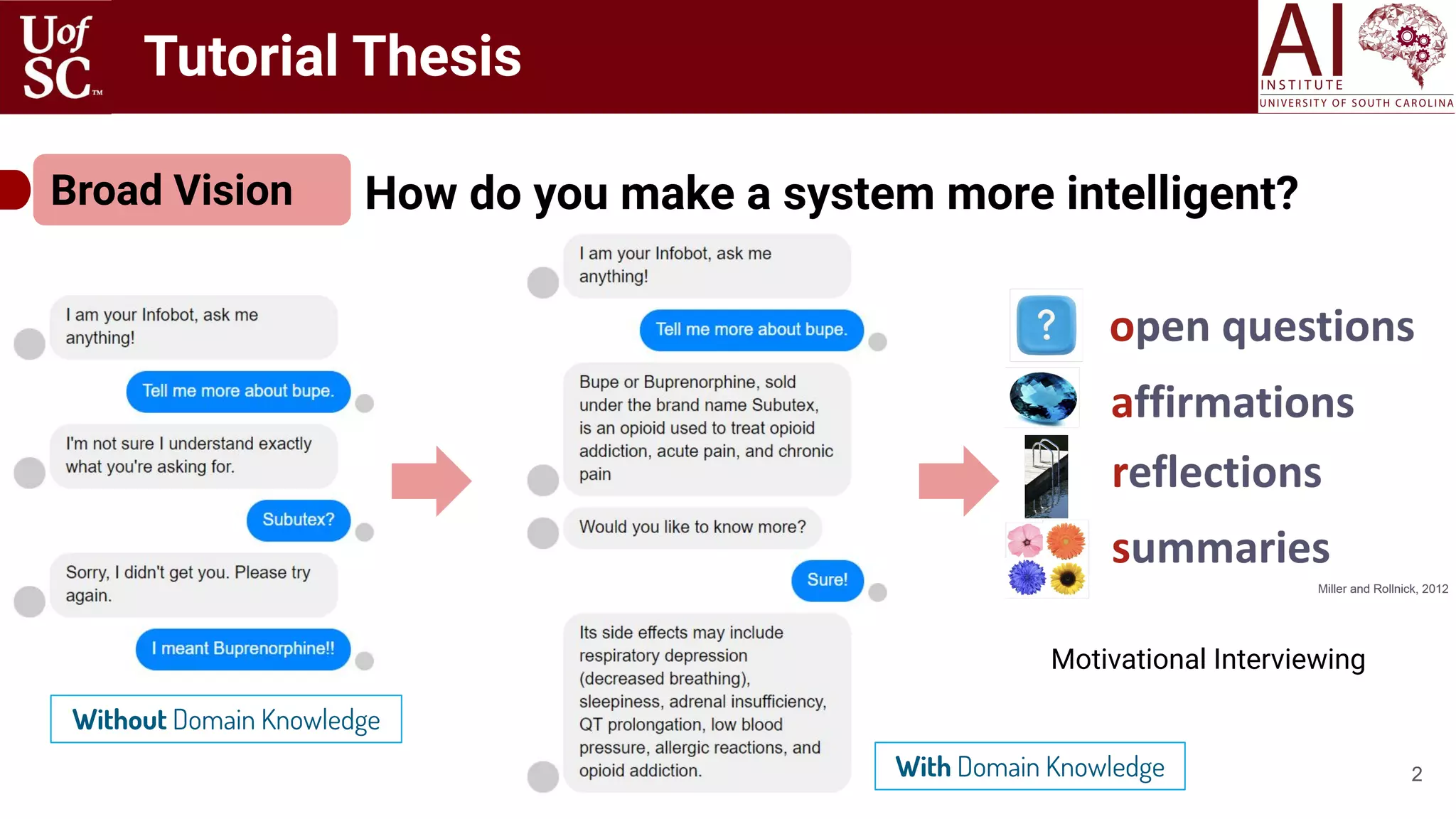
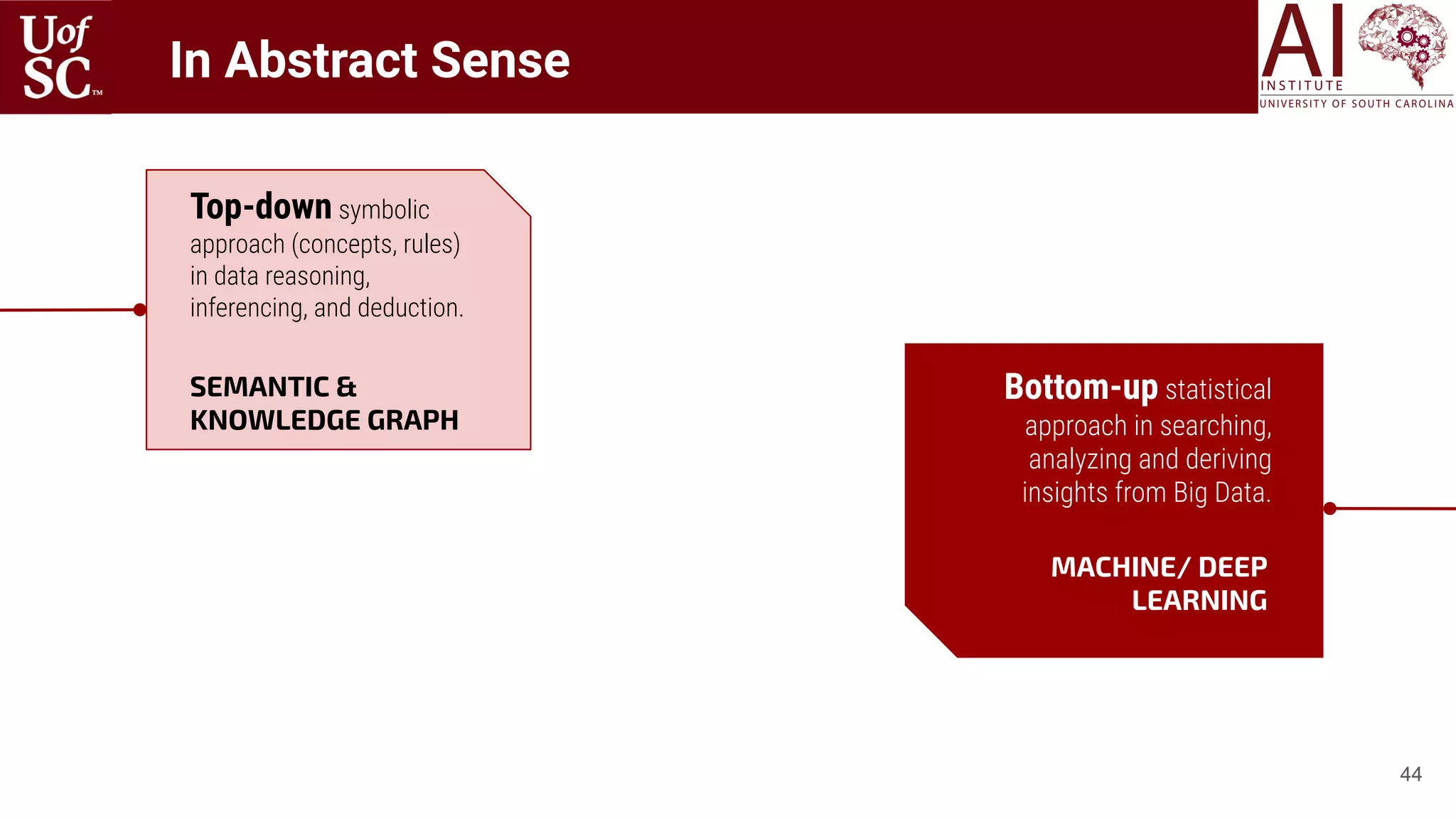
How to gain deep
understanding of the content?
Tutorial Thesis
3
agitation
nervous
panicky
>Millions
Social Media
Deep
Clustering
Neural
Parsing
Repeated
panic attacks
agitation
nervous
panicky
Repeated
panic attacks
anxiety
KG
Sleep Disorder
Circadian
Rhythm
Disorder
Context understanding
Shallow
Semantics
Deeper
Semantics
[Lin 2020, Kitaev 2018]
https://github.com/facebookresearch/deepcluster
[Gaur 2020]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-3-2048.jpg)
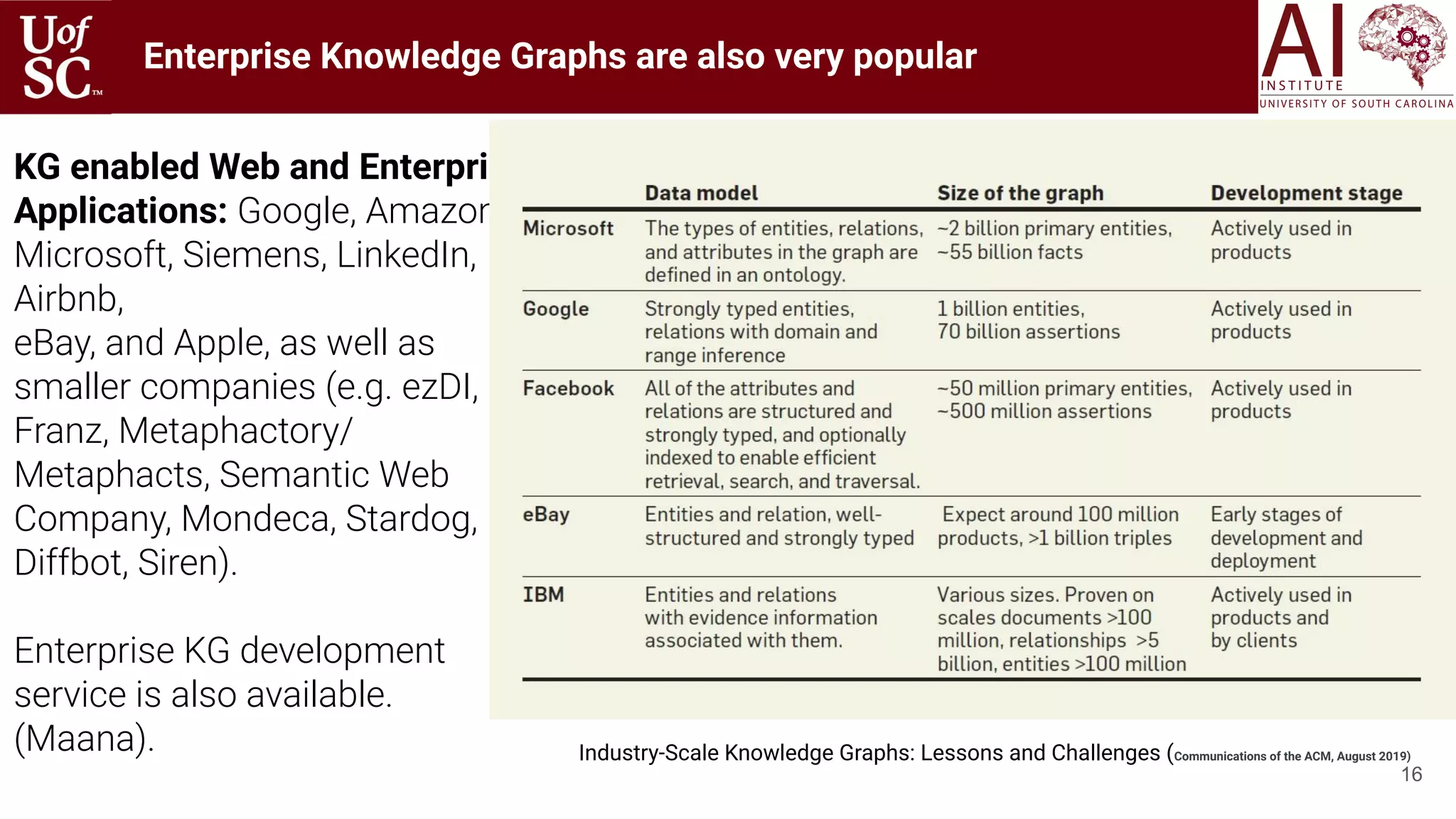
![Knowledge in computing
4
The role of knowledge in computing has long been recognized
- at least since Vannever Bush’s 1945 seminal piece: As We May Think.
Enhanced (semantic) applications such as search,
browsing, personalization, recommendation,
advertisement, and summarization.
Improve integration of data, including data of
diverse modalities and from diverse sources.
Empower/enhance ML and NLP techniques. Use
as a knowledge transfer mechanism across
domains, between humans and machines
Improve automation and support intelligent
human-like behavior and activities that may
involve conversations or question-answering and
robots.
~2000
~2025
Focus:
From small data to big data.
Data alone is not enough.
[Domingos 2012].
Knowledge will propel
machine understanding of
content. [Sheth, et al. 2017]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-4-2048.jpg)
![Tutorial Thesis
5
Interpretability + Traceability → Explainability
Ethics, Bias, and False Alarms
Deeper Understanding of Content including
Context Understanding
What is the right knowledge graph to use?
[Semantic, Cognitive, Perceptual Computing, Sheth 2015]
Structured and
Unstructured
Data
Models
Knowledge
Graph/Base
Compute
Application/
Workflow
David Cox Talk: Neurosymbolic AI
F. Lécué: On the Role of Knowledge Graphs in Explainable AI A Machine Learning Perspective](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-5-2048.jpg)



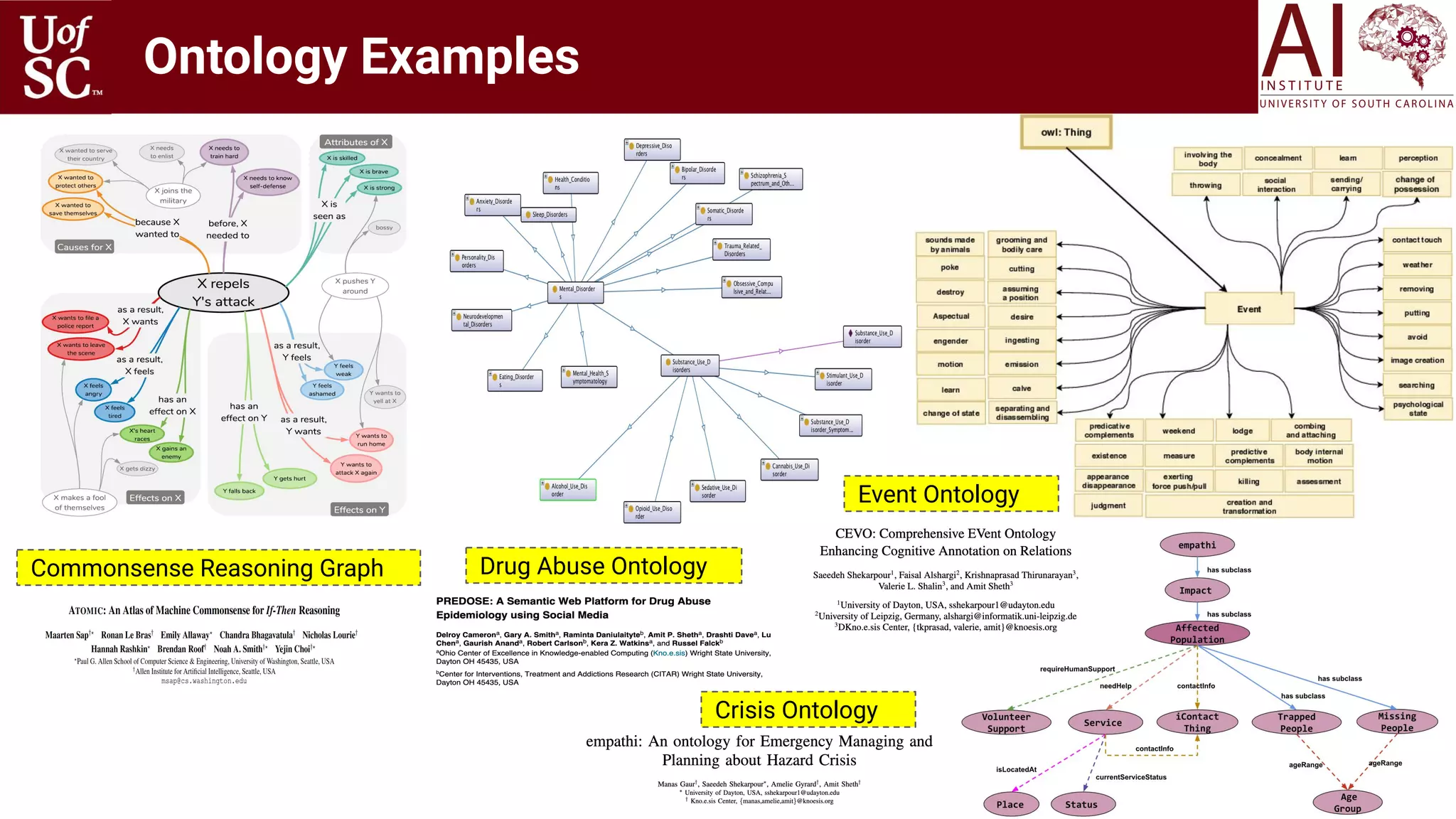

![Proliferation Broad-based &
Domain-Specific KGs
13
Examples of General Purpose Knowledge Graphs
1. DBpedia [Auer 2007, Lehmann 2015]
2. Yago [Rebele 2016]
3. Freebase [Bollacker 2008]
4. ConceptNet [Speer 2017]
5. Knowledge Vault [Dong 2014]
6. NELL [Mitchell 2018]
7. Wikidata [Vrandečić 2014]
Example of Healthcare-specific Knowledge Graphs
1. SNOMED-CT [ACL Chang 2020]
2. Unified Medical Language System (UMLS) [Yip 2019]
3. DataMed [JAMIA Chen 2018]
4. International Classification of Diseases (ICD-10)
[JAMIA Choi 2016]
5. DrugBank, Rx-NORM and MedDRA [ BMC Celebi 2019]
6. Drug Abuse Ontology [BMI Cameron 2013]
Many are also community-developed.](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-13-2048.jpg)

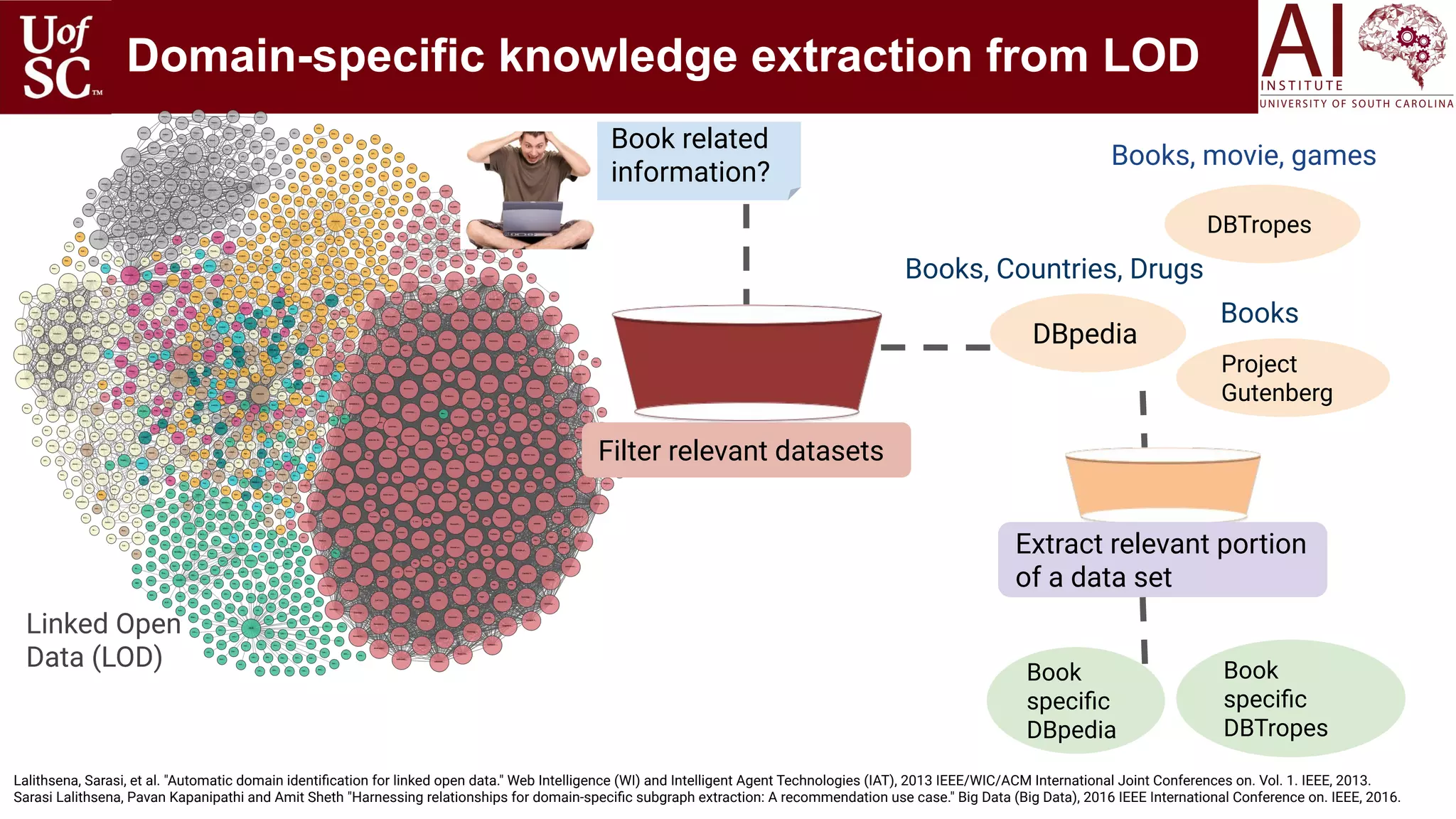
![Why Knowledge Graphs: Shortcomings of
Deep Learning (DL)
17
Trivial Case for
Classification
Text: I sometimes wonder how many alcoholics are relapsing under the lockdowns (former
alcoholic).
Question: Does the person has addiction?
Answer: Yes
Not Trivial Text: Then others that insisted that what I have is depression even though manic episodes aren't
characteristic to depression. I dread having to retread all this again because the clinic where I get
my mental health addressed is closing down due to loss in business caused by the pandemic
Question: Does the person suffer from depression?
Answer: Yes Correct: No
Disjunctive
Questions
Question: Are you feeling nervous or anxious or on edge?
Question: Is the feeling of restlessness due to stress or anxiety ?
Questions: Does an employee own a company or work for a company?
Research in this directions: Query2Box and Multi-hop Reasoning [Ren ICLR 2020, Lin EMNLP 2018]
Covid context
Generic context
Bottom line: Most state of the art Deep learning approaches are not integrated
with prior knowledge. This tutorial is about strategies for doing so.
[David Cox] [Marcus 2018]
https://www.digitaltrends.com/cool-tec
h/neuro-symbolic-ai-the-future/](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-17-2048.jpg)
![Why Knowledge Graphs: Shortcomings of DL
● Graph Convolutional Neural Networks (GCN) are blind to relation types. For example:
<shelter-in-place causes anxiety> and <shelter-in-place prevents anxiety> have similar
representations in GCN.
● Deep Clustering over unlabeled data exploits the inherent latent semantics to generate
diverse and cohesive clusters. But, interpretability of the clusters requires Knowledge Graphs.
18
ODKG: Opioid
Drug Knowledge
Graph
[Kamdar 2019]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-18-2048.jpg)
![Why Knowledge Graphs : NLP/NLU Challenges
19
● Natural Language Processing Challenges:
○ How do you learn quickly from small amount of data?
○ How do you mine (varied) relationships from existing text?
○ How do you reliably classify entities into known ontology?
○ Better contextualization of words
● Natural Language Understanding Challenges:
○ Query Interpretation or Understanding the user question
○ Answering the question with Trust and Transparency
○ How to measure “reasonability” and “meaningfulness” of the response to
a question?
○ How much context is needed to provide a precise response?
[Stanford Knowledge Graph Seminar 2020, Amit Prakash , Leilani Gilpin]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-19-2048.jpg)
![20
[Image from Talukdar]
KG in Conversational AI
● Get same/similar
answers
based on trusted
knowledge
● Personalization
● Contextualization](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-20-2048.jpg)

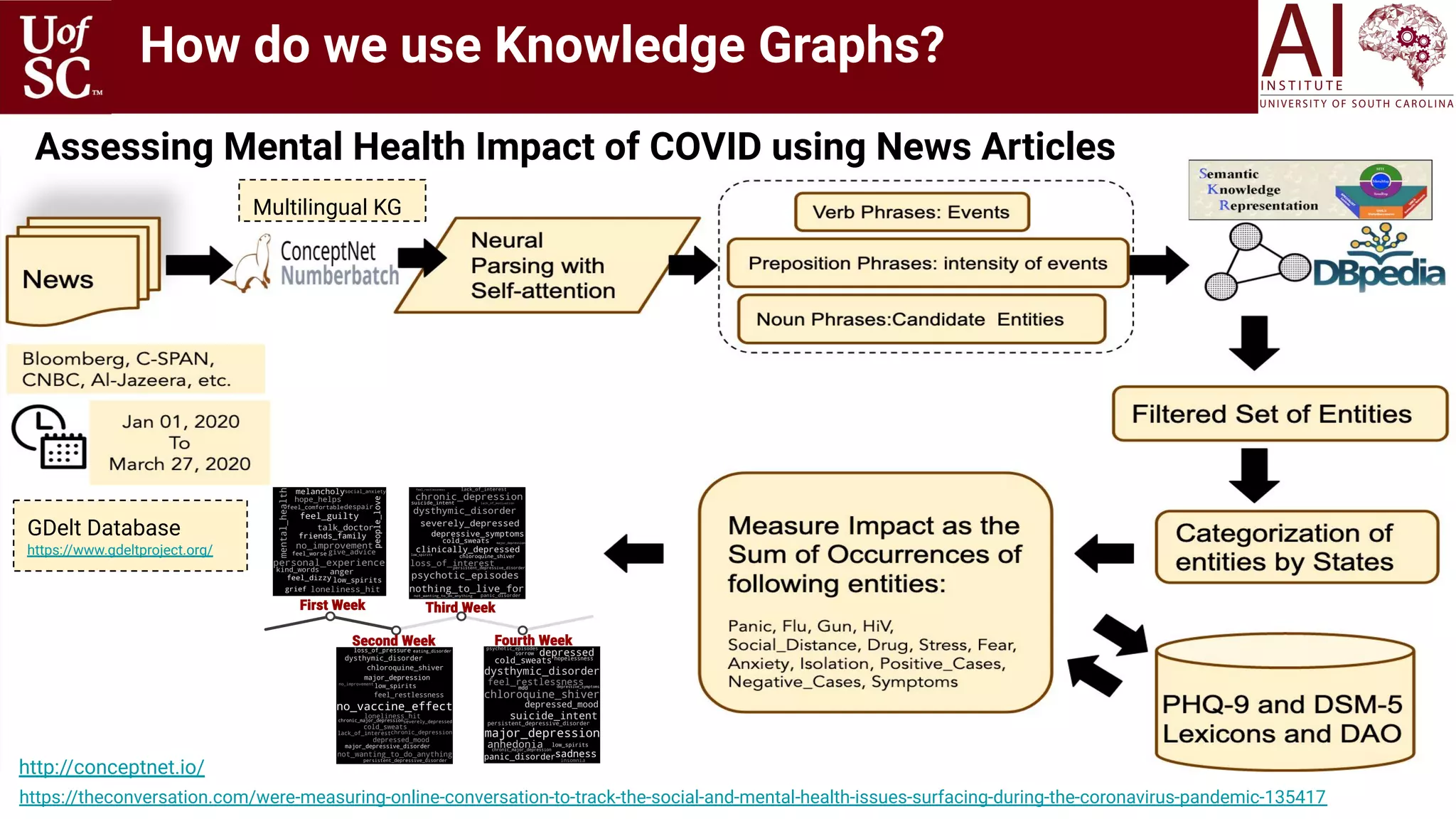
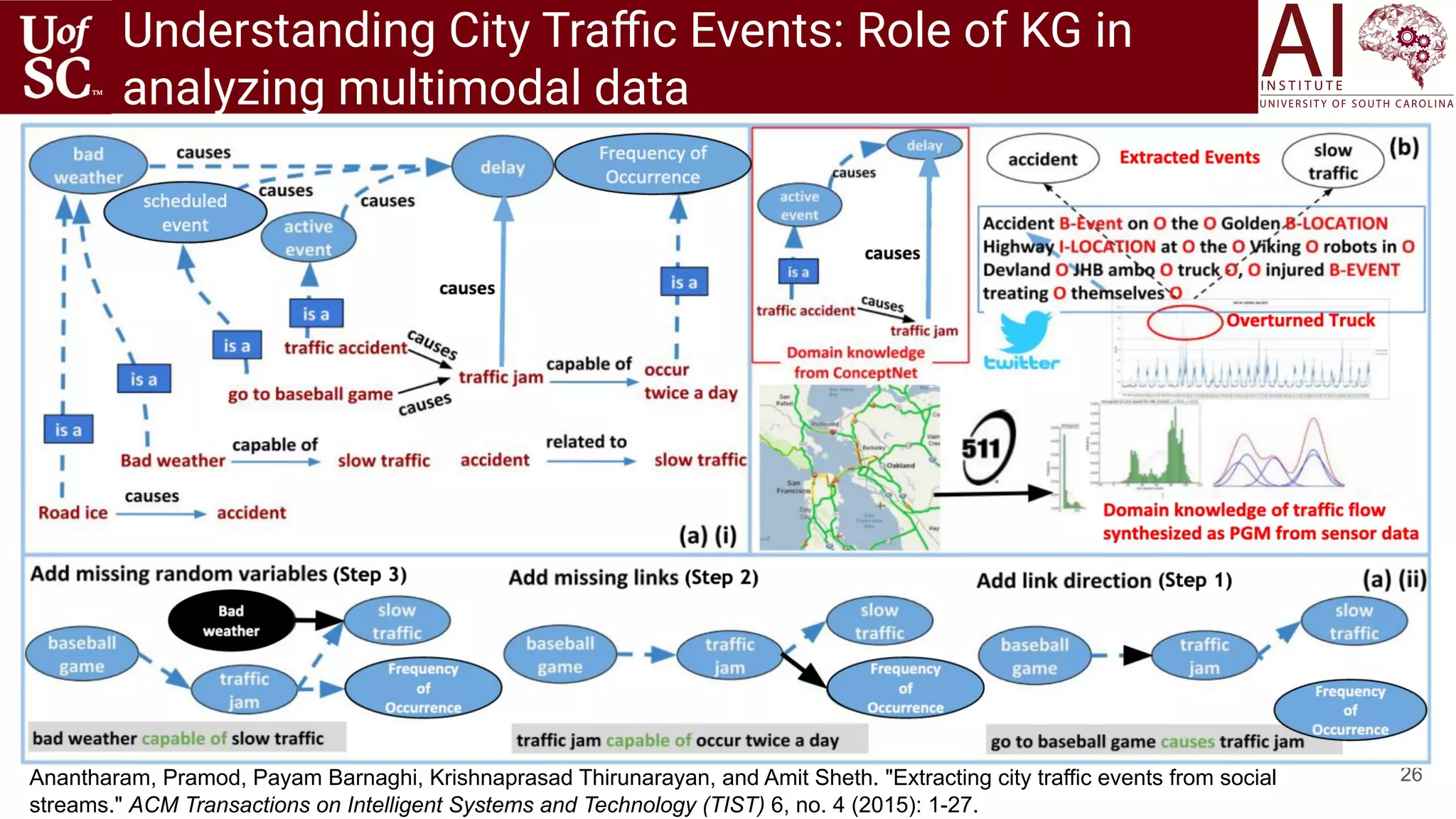
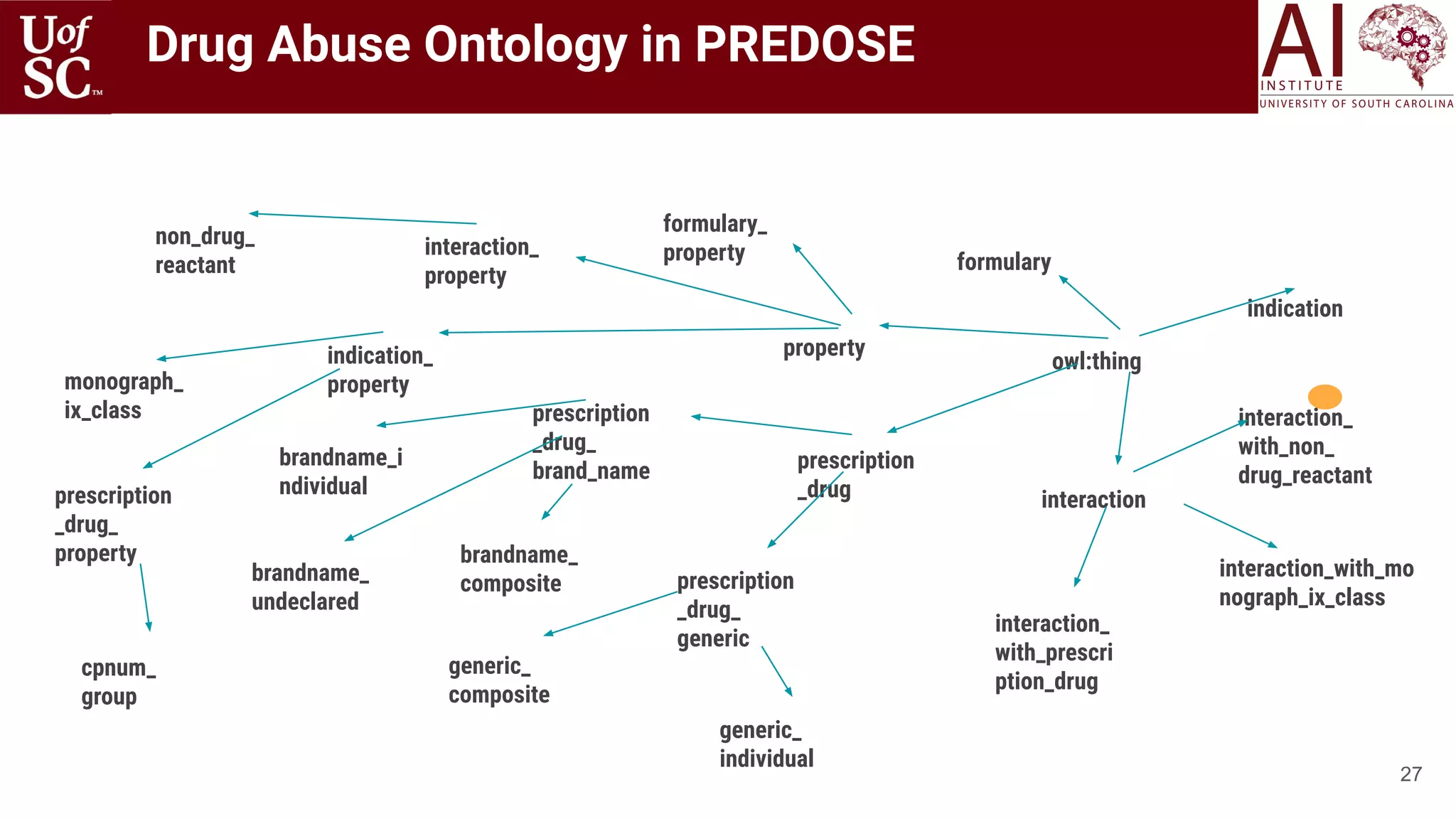
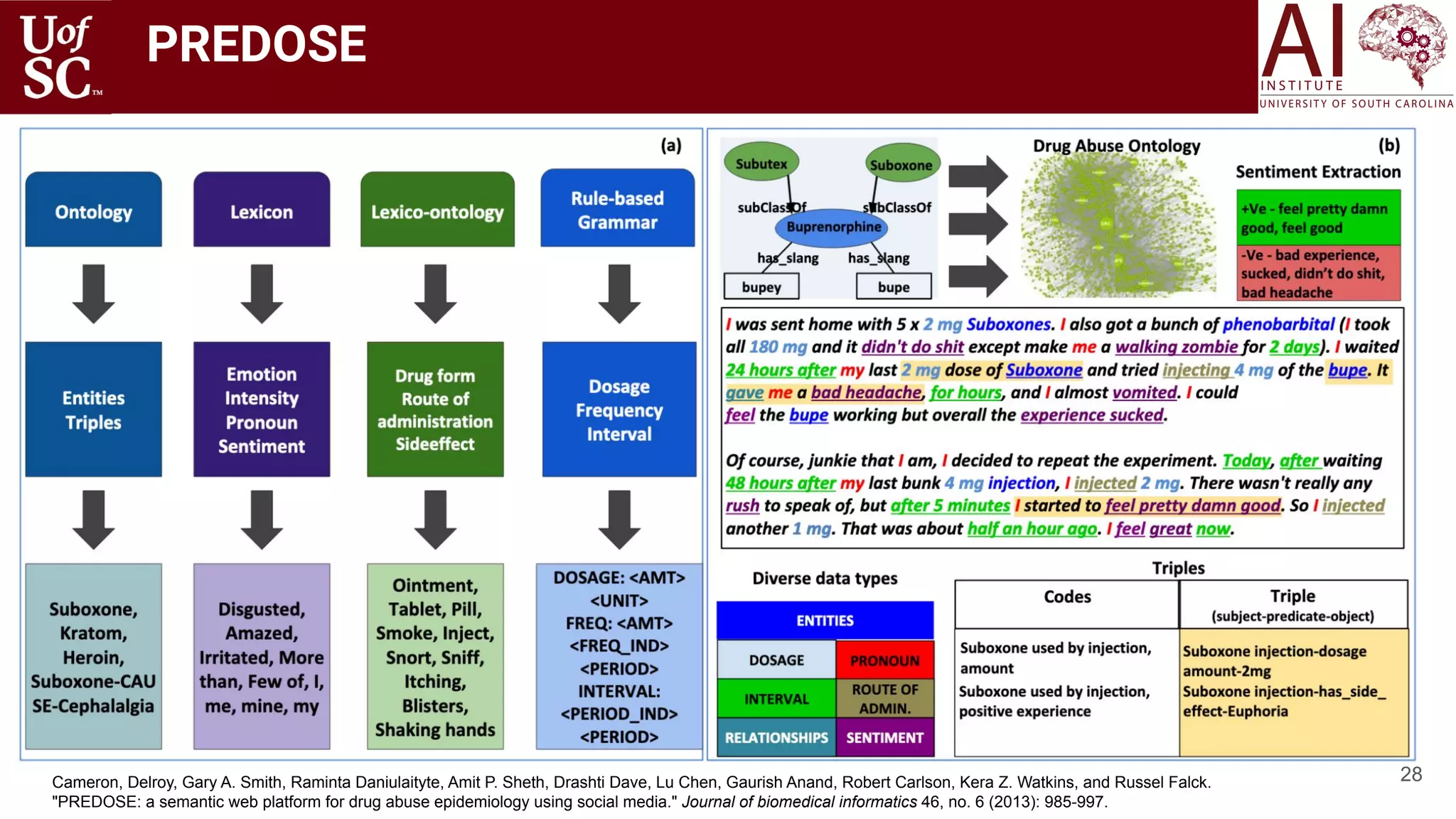
![22
How do we use Knowledge Graphs?
Health
Knowledge
Graph
[Shah and Sheth
US patent 2015]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-22-2048.jpg)
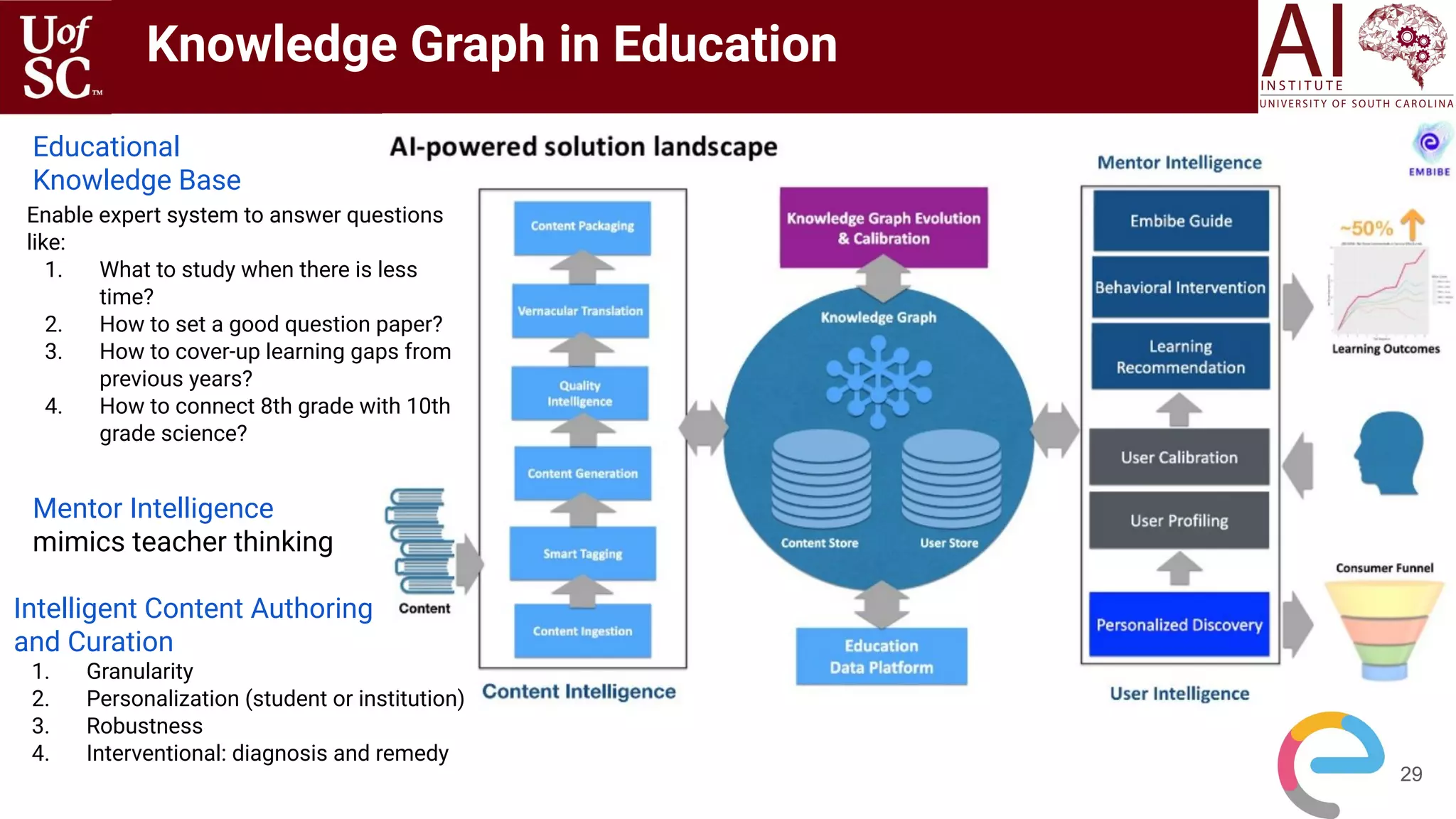

![31
Experiences or
Factual Knowledge
Abstract Knowledge
1. Continuum of Knowledge
2. relationship mapping:
NLU through and knowledge
transfer across domains
Analogical Generalization
Applicable to new situation via
analogy
[Forbus and Gentner 1997, Gentner
and Medina 1998]
Mapping between Enzyme Kinetics
and Musical Chairs [Ongoing]
Mapping between two Conceptual Frames in
similar domain (Physics)](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-31-2048.jpg)
![ML and Knowledge Graphs: Pipeline
32
Knowledge
Extraction
Knowledge
Alignment
Knowledge
Cleaning
Knowledge Mining &
Knowledge-based QA
Data Extraction
(NLP, Web)
Wrapper Induction
(DB, DM-Data
Mining)
Web Tables (DB)
Text Mining (DM)
Entity and
Relationship Linking
[Perera 2016]
Schema Mapping
and Ontology
Mapping
[Jain 2010]
Universal Schema
[Sheth 1990]
Data Cleaning
[Jadhav 2016]
Anomaly Detection
[Anantharam 2012,
2016]
Knowledge Fusion
[Sheth 2020,
Kapanipathi 2020,
Gaur 2018,
Kursuncu 2020]
Graph Mining [Lalithsena
2016, 2017, 2018]
Knowledge Embedding
[Wickramarachchi 2020,
Gaur 2018]
Search [Sheth 2003,
Cheekula 2015, Kho
2019]
QA [Alambo 2019,
Shekarpour 2017]
[Stanford Knowledge Graph Seminar 2020, Luna Dong]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-32-2048.jpg)
![33
More Applications and Domains that use KG+DL
Pharmacy
[Futia 2020,
Gentile 2019]
Personalized
mHealth
[ Sheth 2017, 2018a,
2018b, 2019]
Public Health
[Yazdavar 2017,
Gaur 2018,
Daniulaityte 2016]
Question Answering/
Dialog System
[Alambo 2019,
Shekarpour 2017, 2015 ]
Hypothesis Generation to find
association between Stress
and Colorectal cancer
[ Cameron 2015]
Chatbot with contextualized (e.g
asthma) knowledge is potentially more
personalized and engaging.](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-33-2048.jpg)
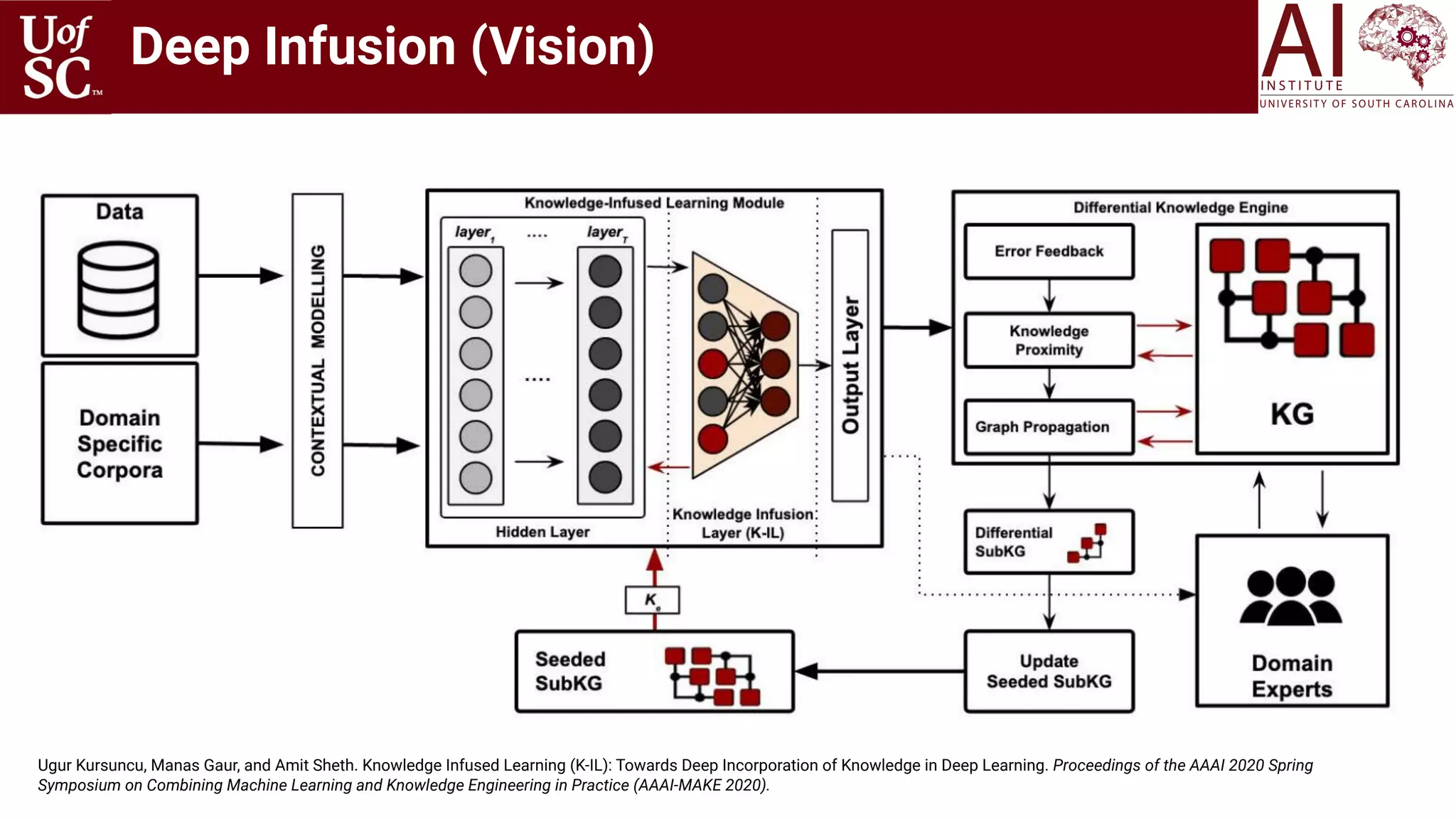
![34
Knowledge-infused
Learning Methods (Internet Computing’19, AAAI’20, CIKM’18, WWW’19, NAACL’18, ACL’17, ….)
Where are we
[Stanford Knowledge Graph Seminar 2020, Christopher Re]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-34-2048.jpg)



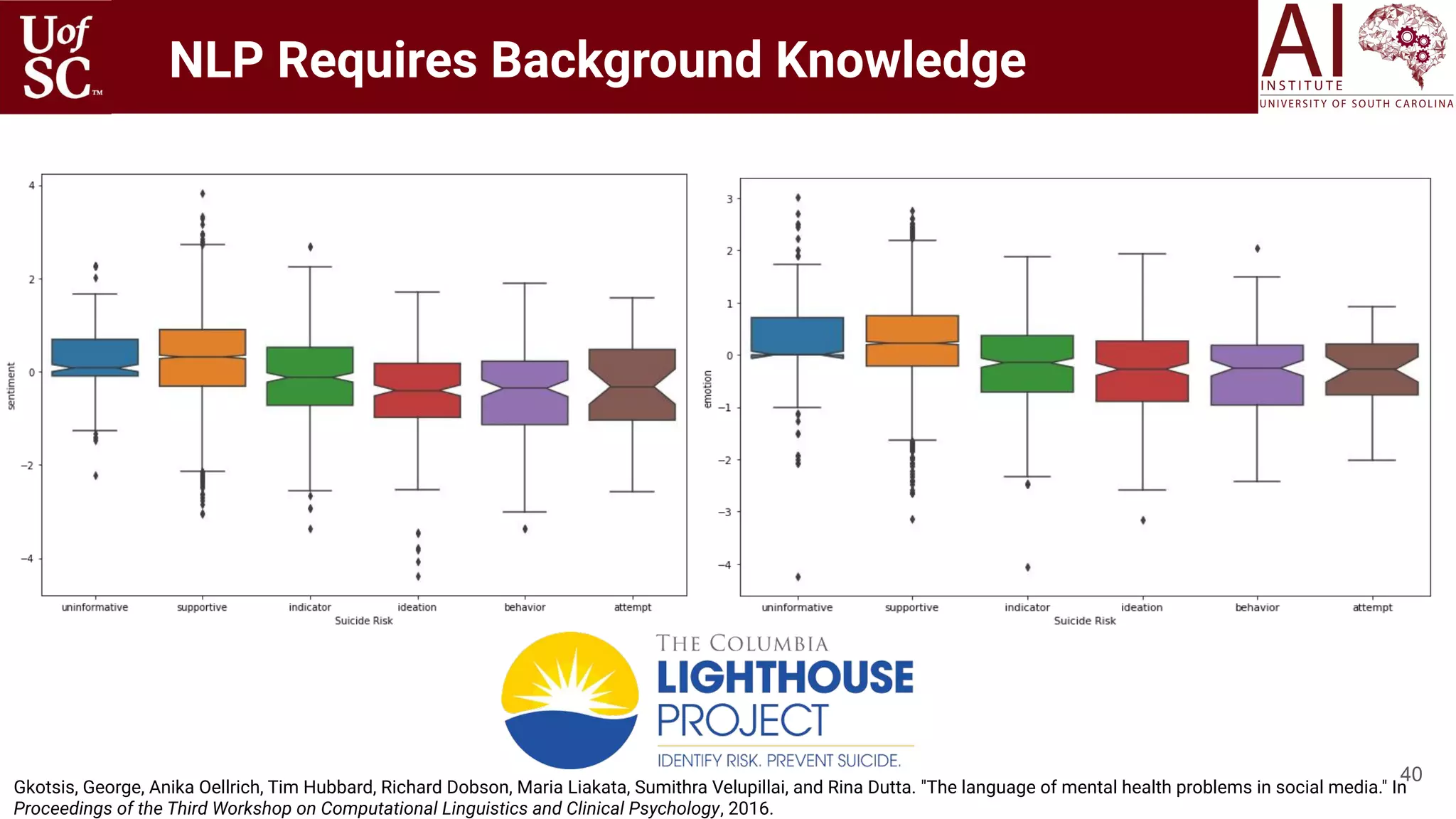
![39
Deep NLP Requires Background Knowledge
An excessive endogenous or exogenous
stimulations by estrogen induces adenomatous
hyperplasia of the endometrium
● adenomatous modifies hyperplasia
● An excessive endogenous or exogenous
stimulations modifies estrogen
● “adenomatous hyperplasia” and
“endometrium” occurs as “adenomatous
hyperplasia of the endometrium”
MeSH
Terms in
PubMed
Articles
[Ramakrishnan 2008]
[Gaur 2018, 2019, Limsopatham 2016 ]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-39-2048.jpg)

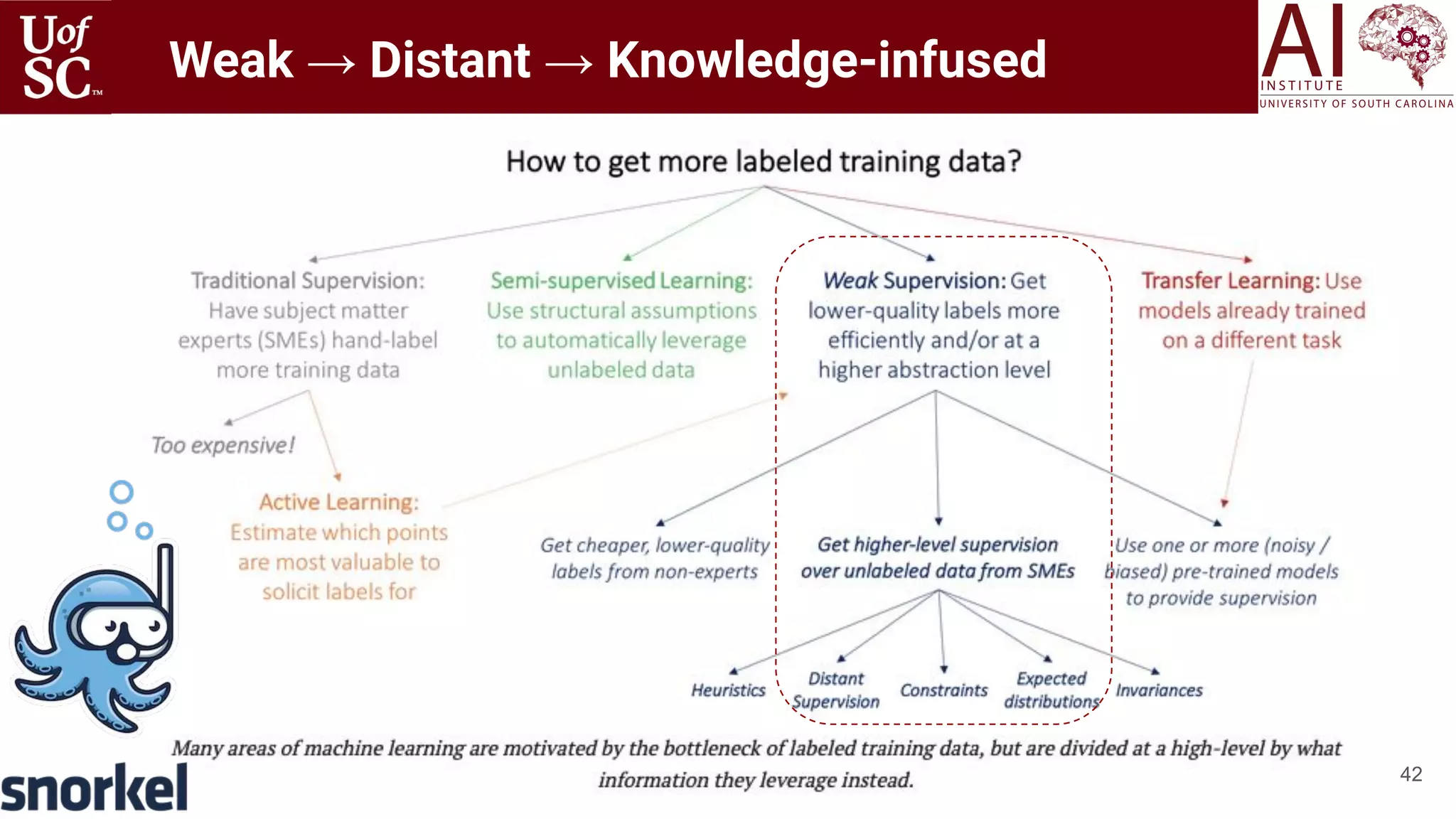
![43
Weak Supervision using SNORKEL
https://www.snorkel.org/
[Ratner 2017, Bach 2019]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-43-2048.jpg)



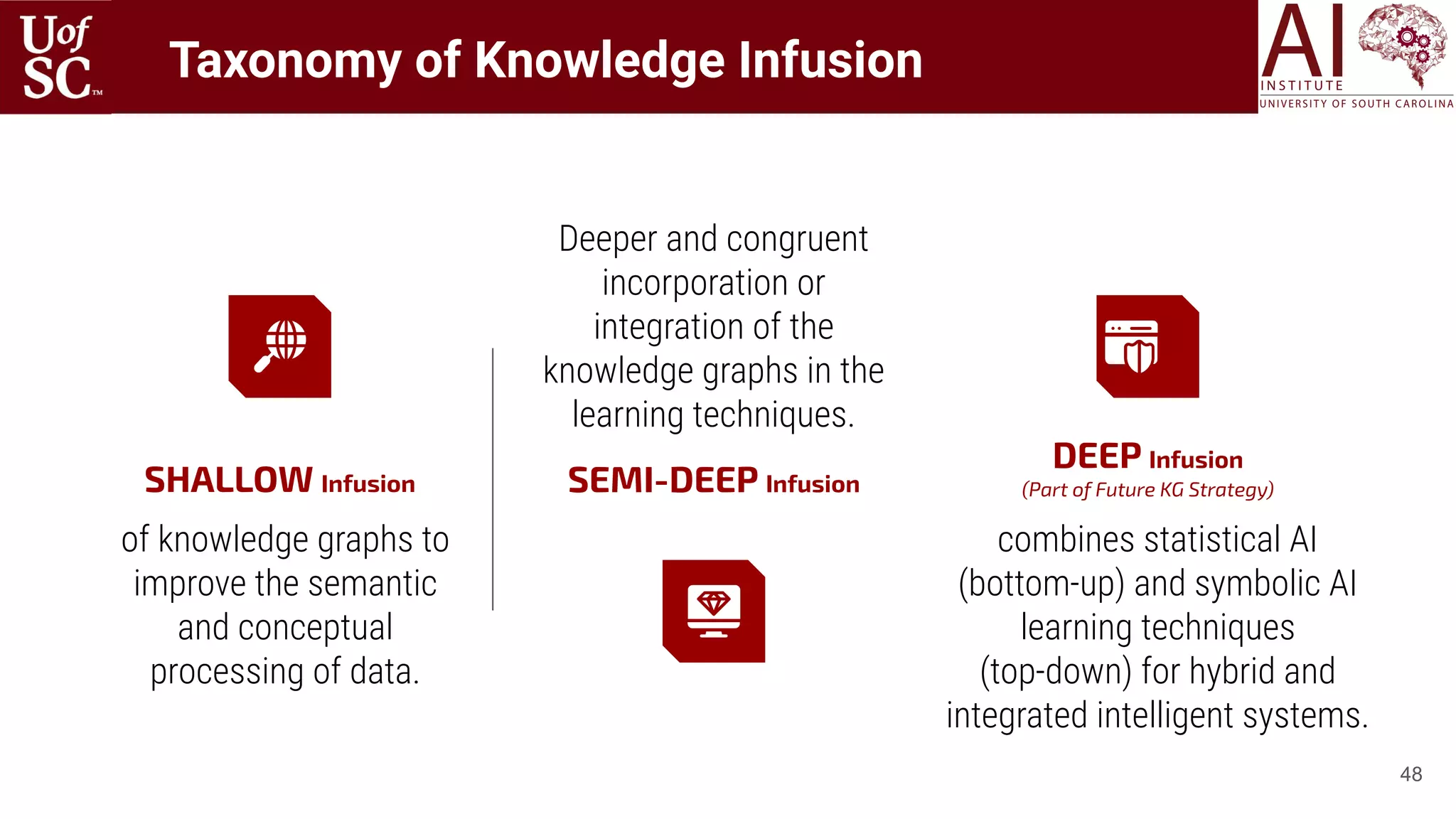
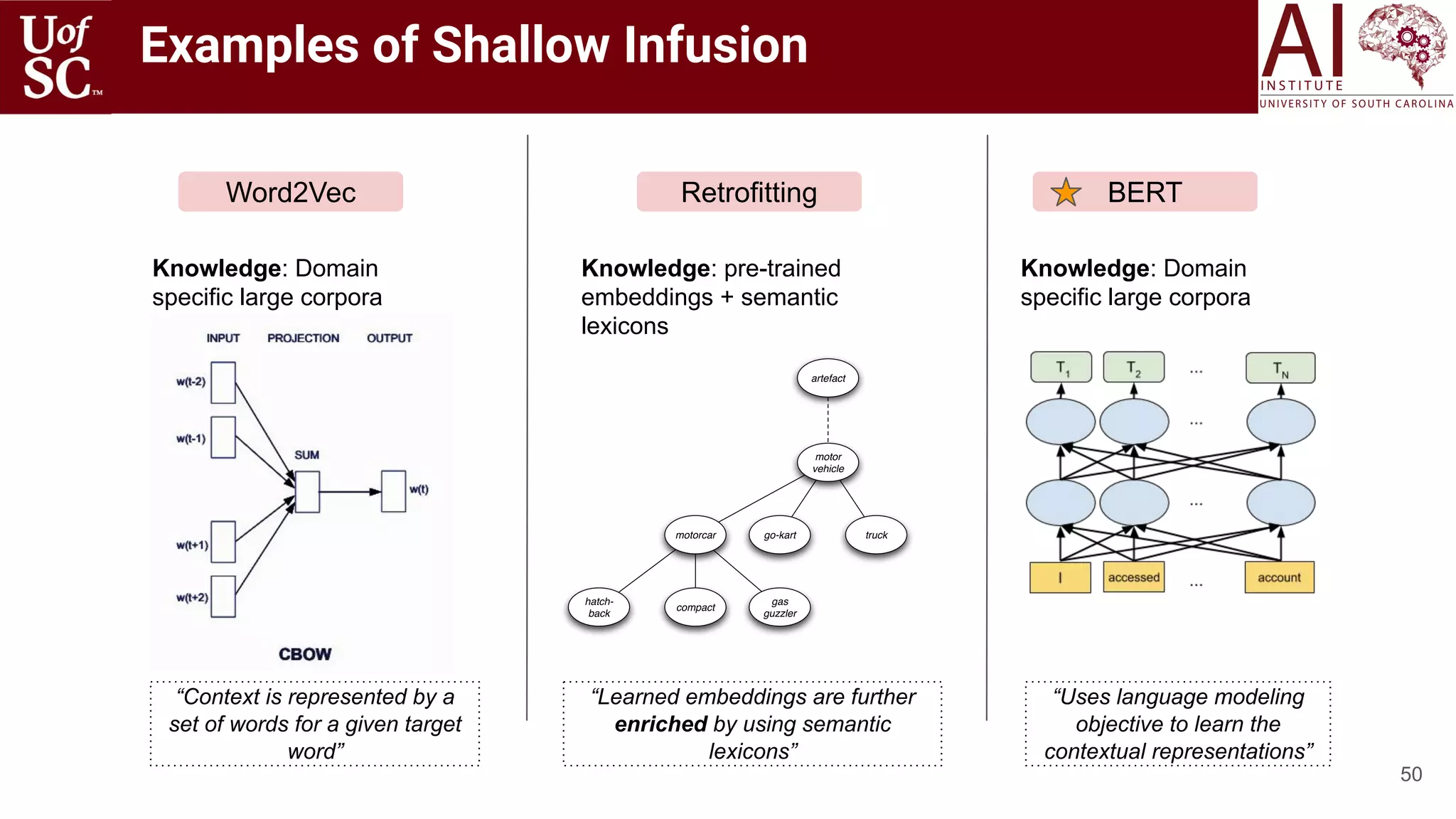
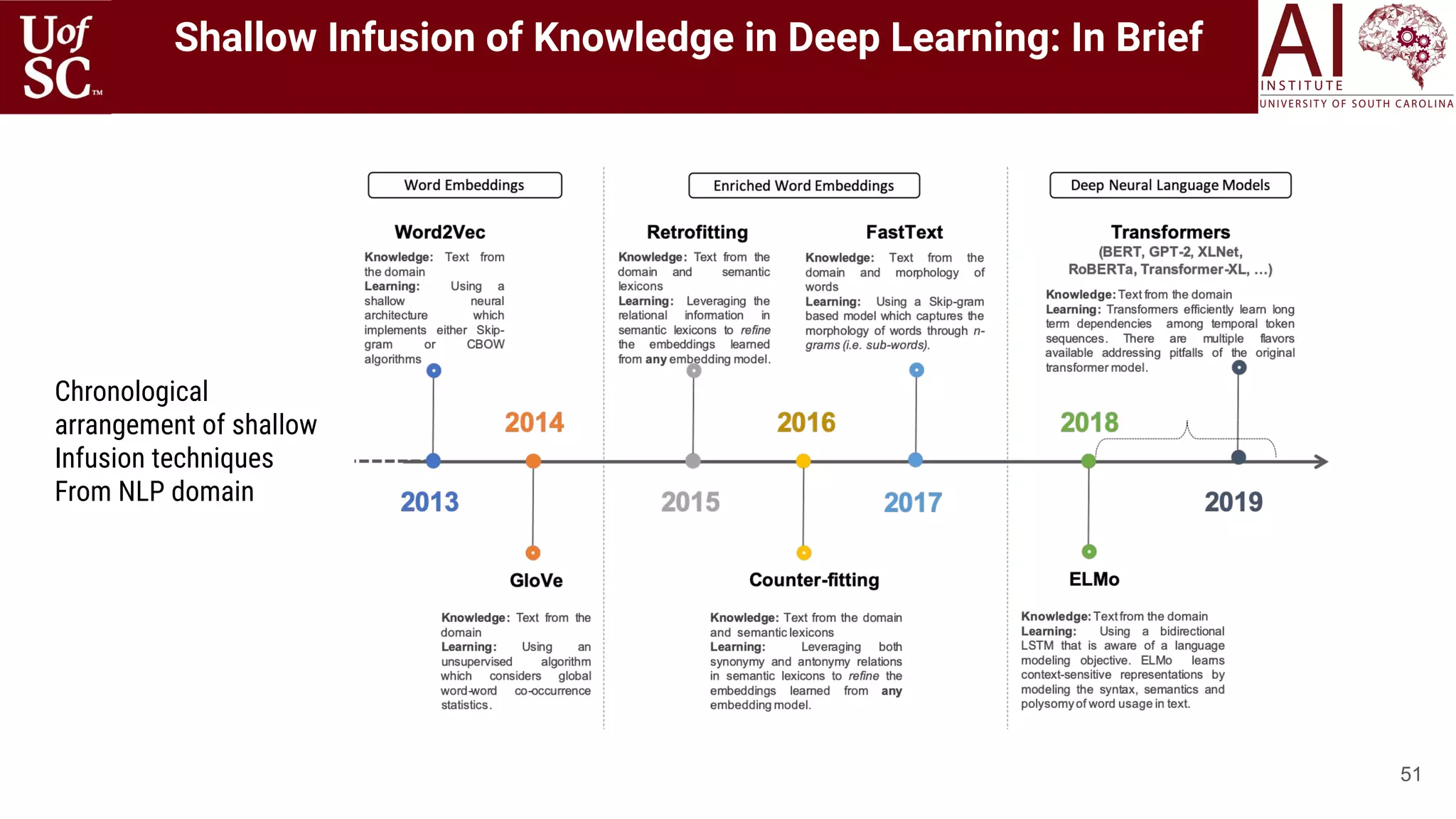
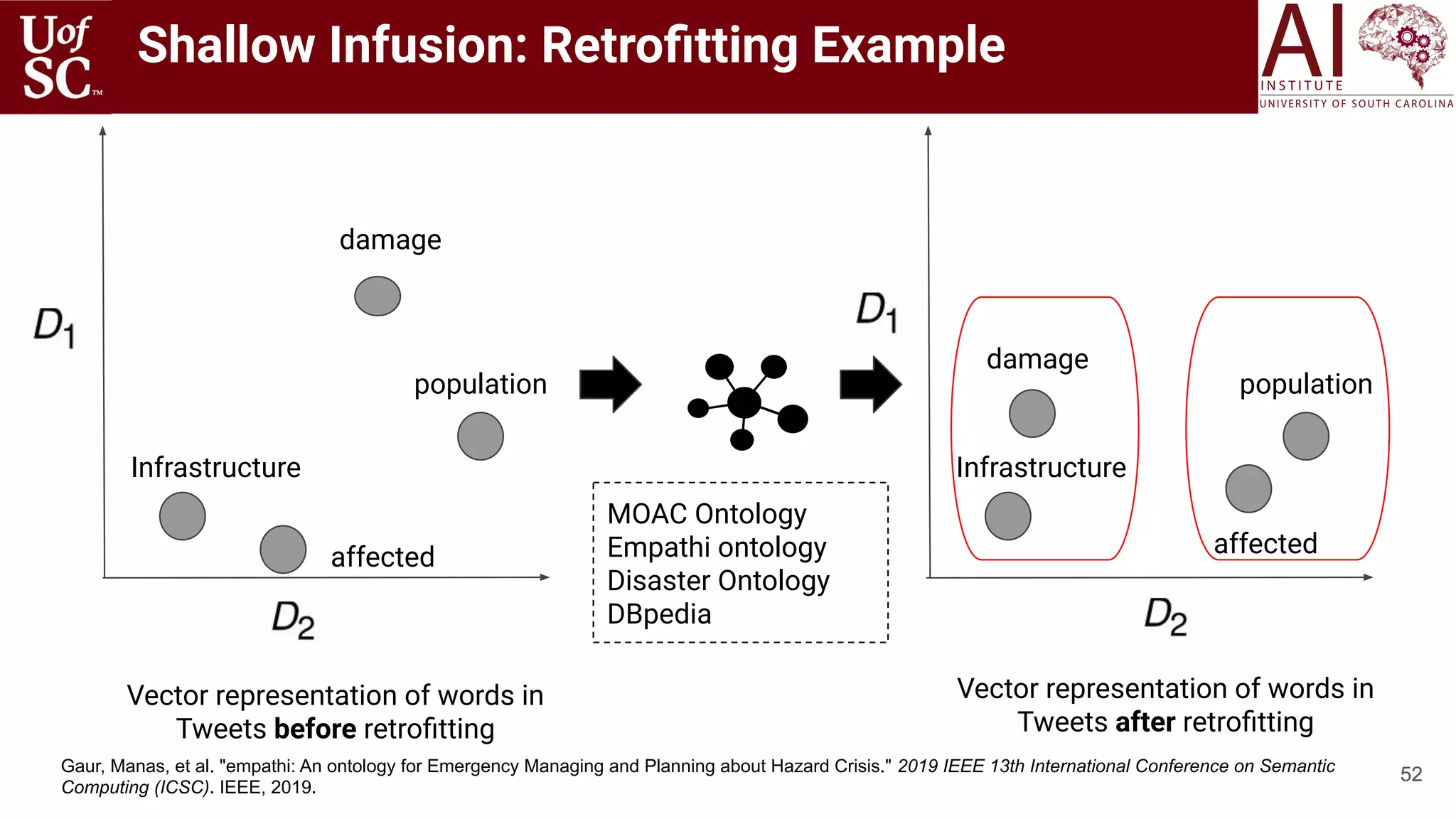
![49
Shallow external knowledge is described as those form of information which are extracted from
text based on some heuristics, often designed for task-specific problems:
○ Bag of Words/Phrases from Corpus [Hagoort 2004, Zhang 2019, Sun 2019]
○ Bag of Words/Phrases from Semantic Lexicons [Faruqui 2014, Mrkšić 2016]
○ Count of Nouns, Pronouns, Verbs [Gkotsis 2017, 2016]
○ Sentiment and Emotions of the sentence [Gaur 2019, Vedula 2017, Kursuncu 2019]
○ Latent topics describing the documents [Jiang 2016, Li 2016, Meng 2020]
○ Label assignment to words or phrases in sentence (Semantic Role Labeling):
Shallow Infusion
Mary sold the book to John
Agent ThemePredicate Recipient](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-49-2048.jpg)
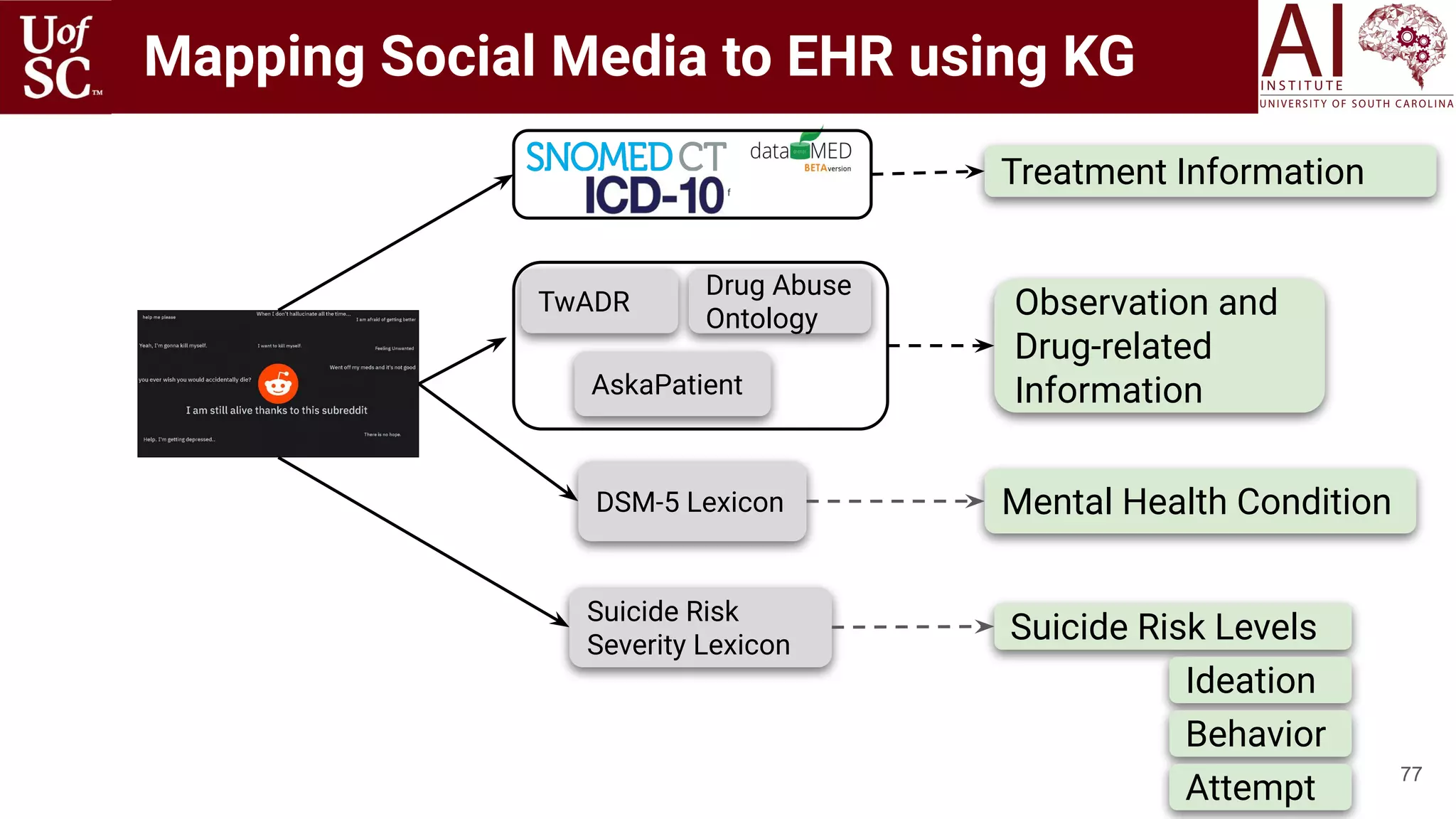
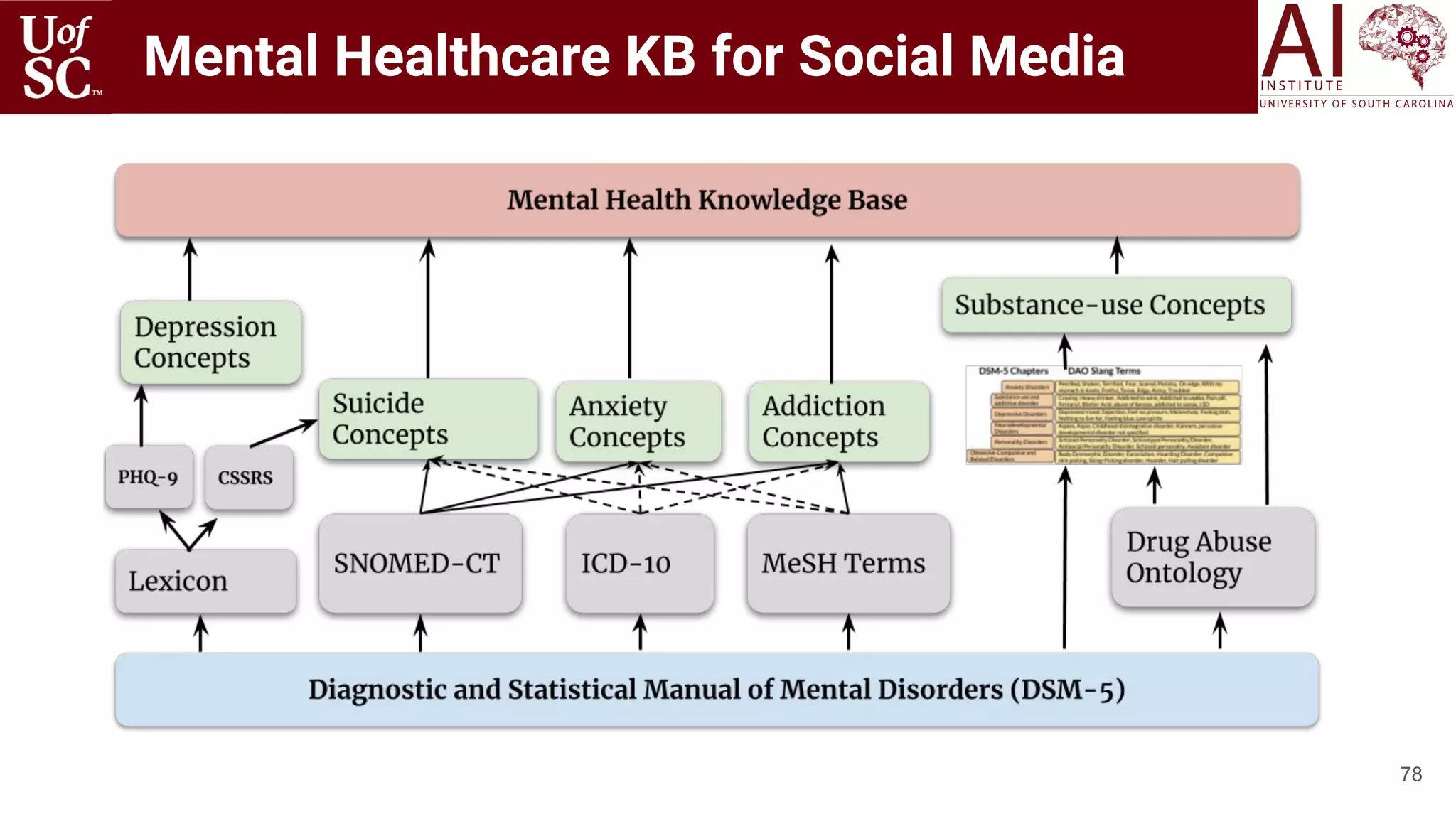
![53
SuicideWatch Subreddit
(93K Users)
NYC CDRN EHR (123K patients) Data specific to
Mental Health
Medical Knowledge Bases
We identified self-harm, depressive feelings, and suicide ideations as
latent topics expressed in Reddit and EHR data.
Both sources did not provide evidence of mentions or expressions of
impulsivity, family violence, and drug abuse.
Shallow Infusion: Association between Social Media
and EHR in Suicide-related Communications
[Gaur, Psychiatry Under Review 2020]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-53-2048.jpg)

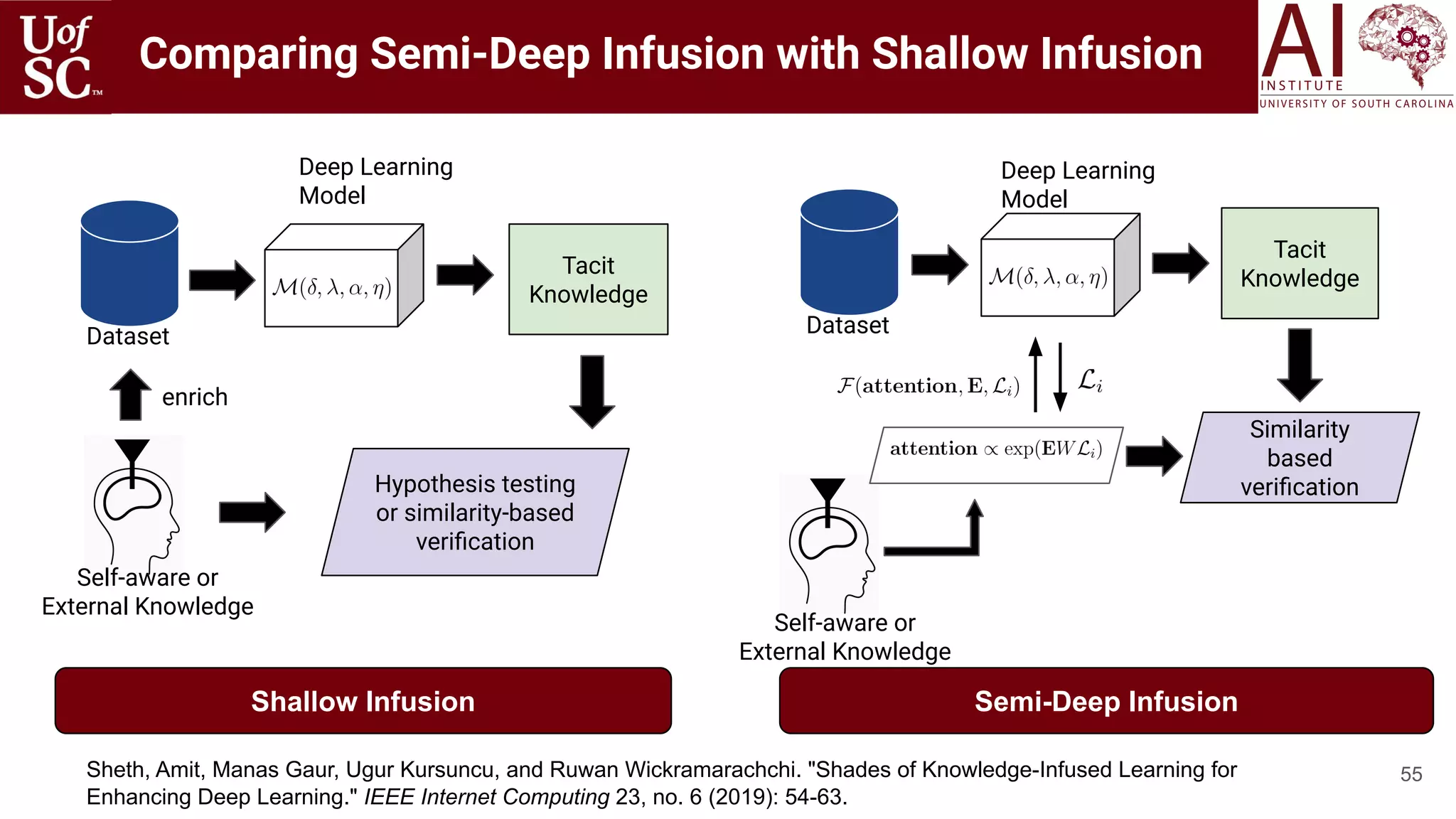


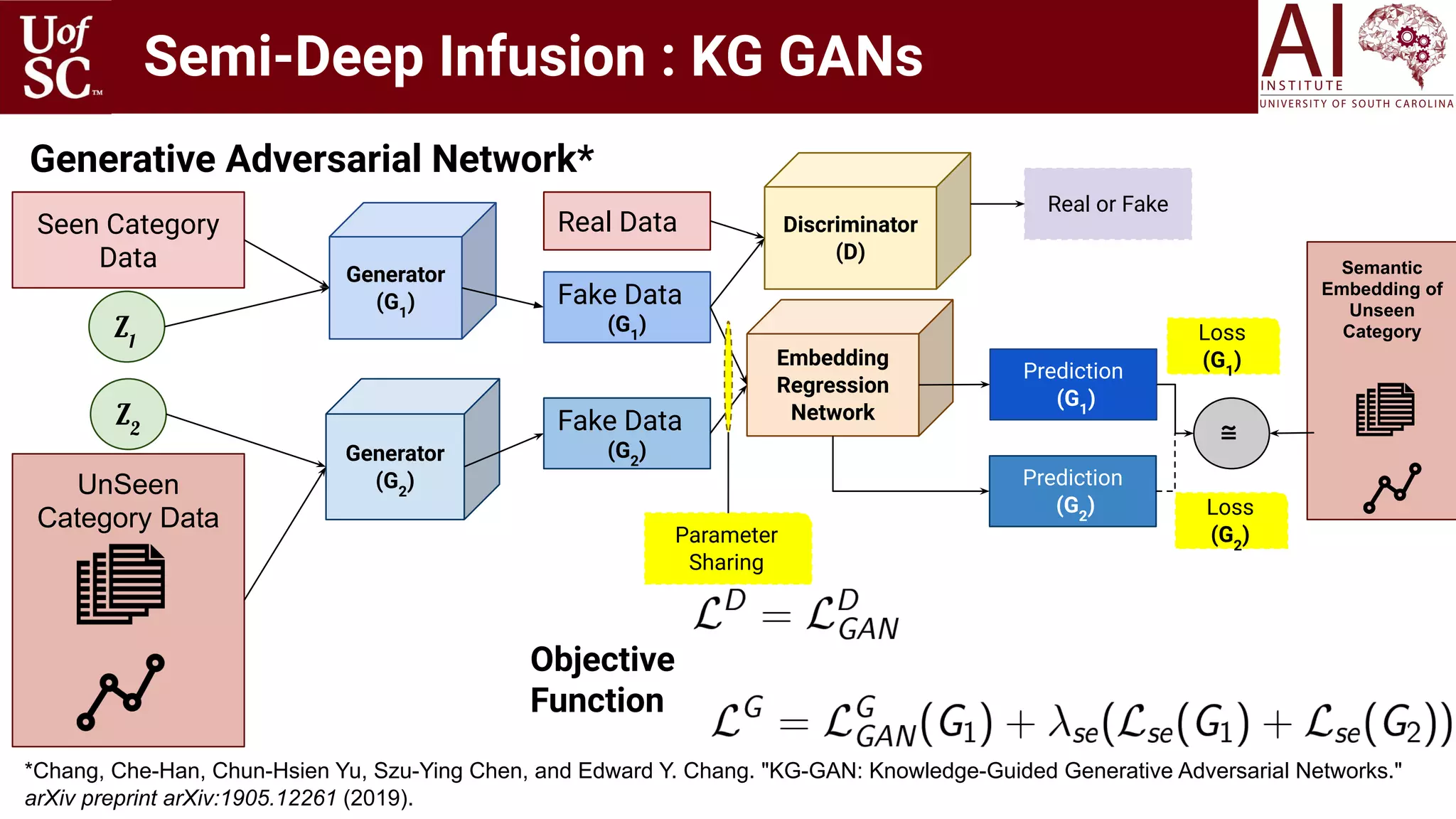
![Variants:
1. Knowledge base at each LSTM cell [1].
2. K-IL layer [2]:
a. 1D Convolutional Neural Network for mixing
b. Graph Convolutional Neural Network -- When
hierarchical structure of KG is important and
need to be preserved in representation.
c. Simple Multi-layer Perceptron.
[1] Yang, Bishan, and Tom Mitchell. Leveraging knowledge bases in lstms for improving machine reading. arXiv preprint arXiv:1902.09091 (2019).
[2] Ugur Kursuncu, Manas Gaur, and Amit Sheth. Knowledge Infused Learning (K-IL): Towards Deep Incorporation of Knowledge in Deep Learning. Proceedings of the AAAI 2020 Spring Symposium on
Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE 2020).
Semi-Deep Infusion : LSTMs](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-61-2048.jpg)

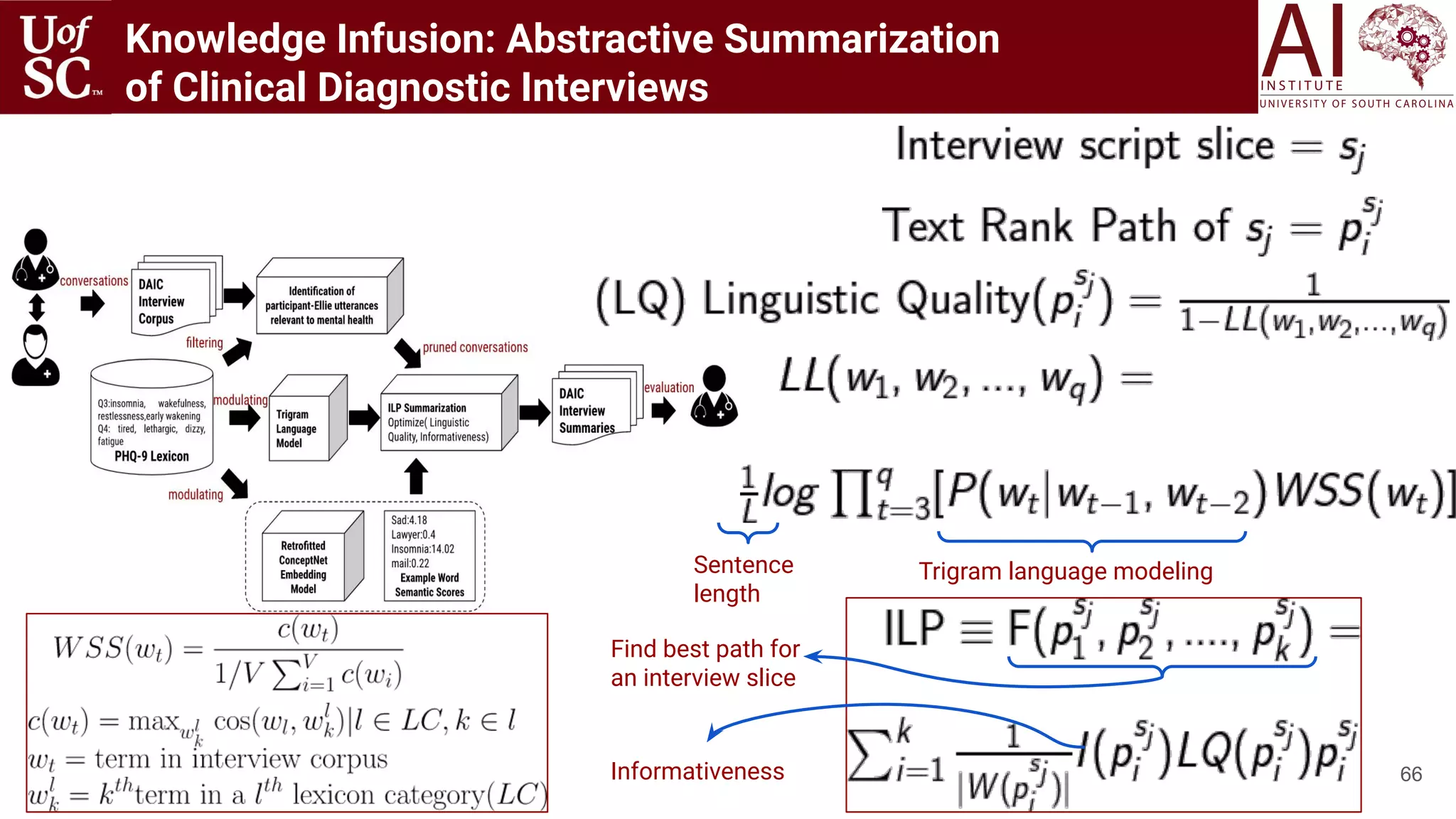
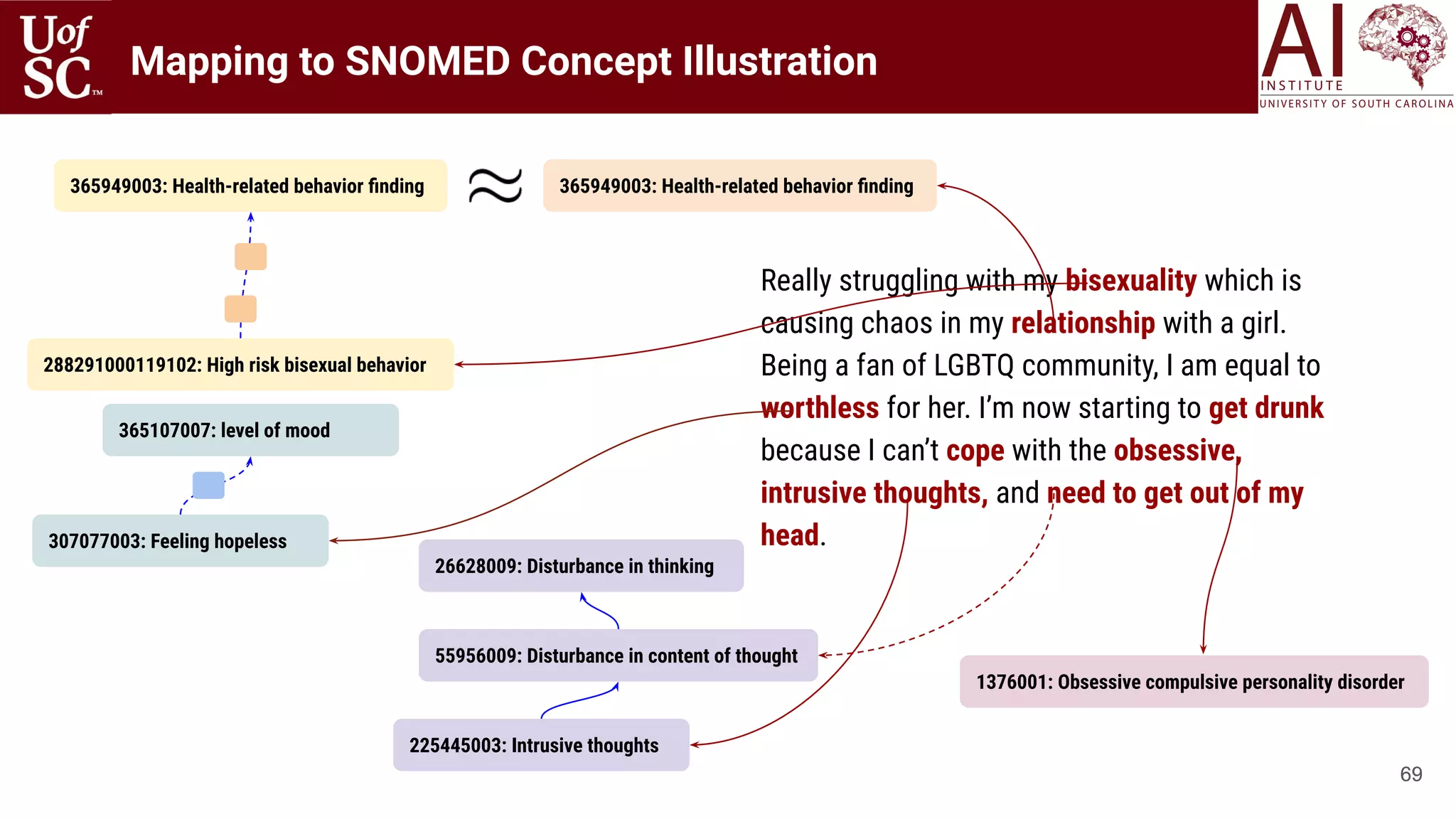
![6868
Really struggling with my bisexuality which is causing chaos in my relationship with a girl. Being
a fan of LGBTQ community, I am equal to worthless for her. I’m now starting to get drunk
because I can’t cope with the obsessive, intrusive thoughts, and need to get out of my head.
BPD
DICD PND SAD SBI OCD
Don’t want to live anymore. Sexually assault, ignorant family members and my never
ending loneliness brights up my path to death.
SCW
PND SBI SAD DPR DICD
DPR
I do have a potential to live a decent life but not with people who abandon me.
Hopelessness and feelings of betrayal have turned my nights to days. I am developing
insomnia because of my restlessness.
SBI DPR DICD
BPD
I just can’t take it anymore. Been abandoned yet again by someone I cared about. I've been
diagnosed with borderline for a while, and I’m just going to isolate myself and sleep forever.
SBI PND
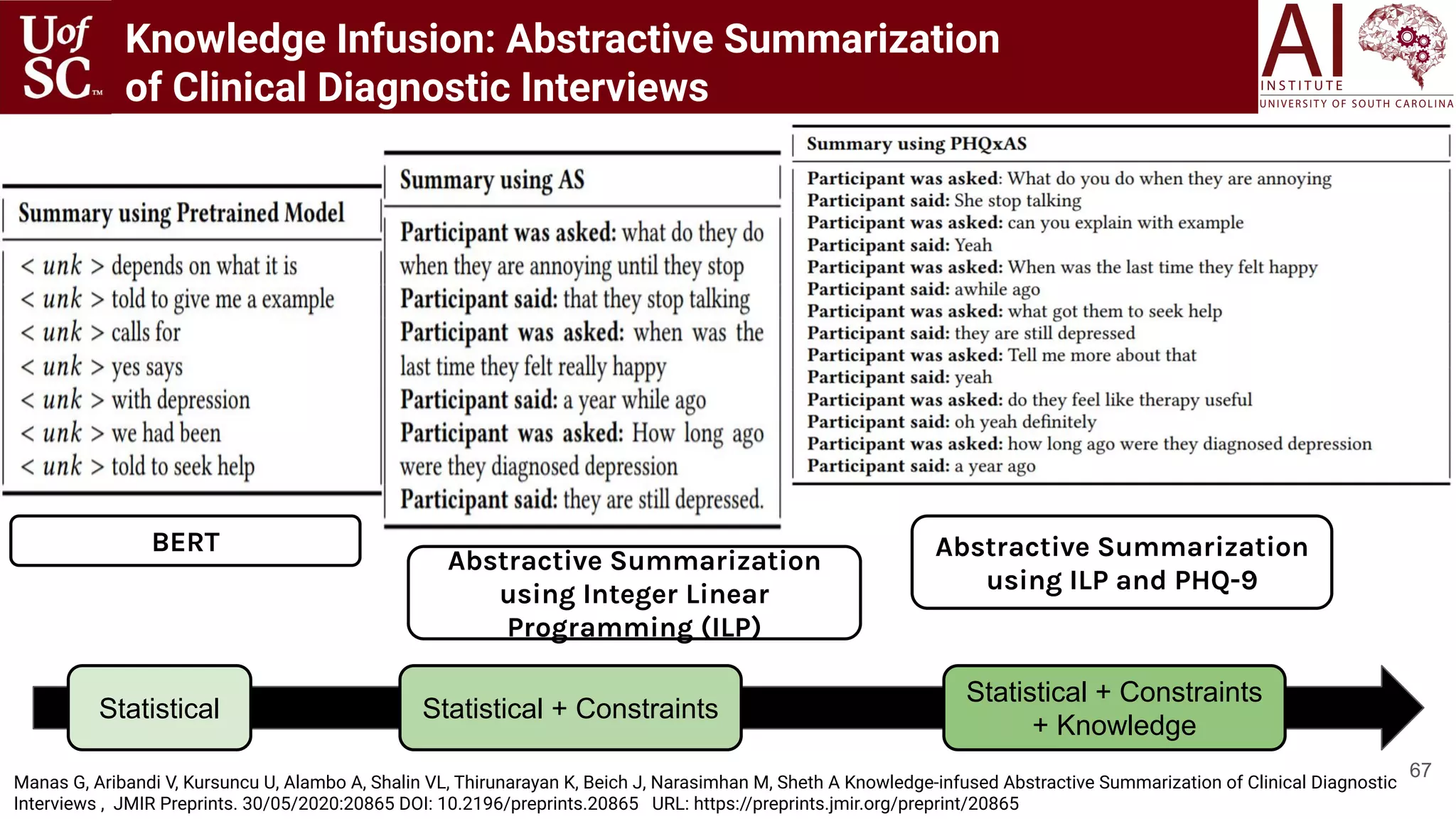
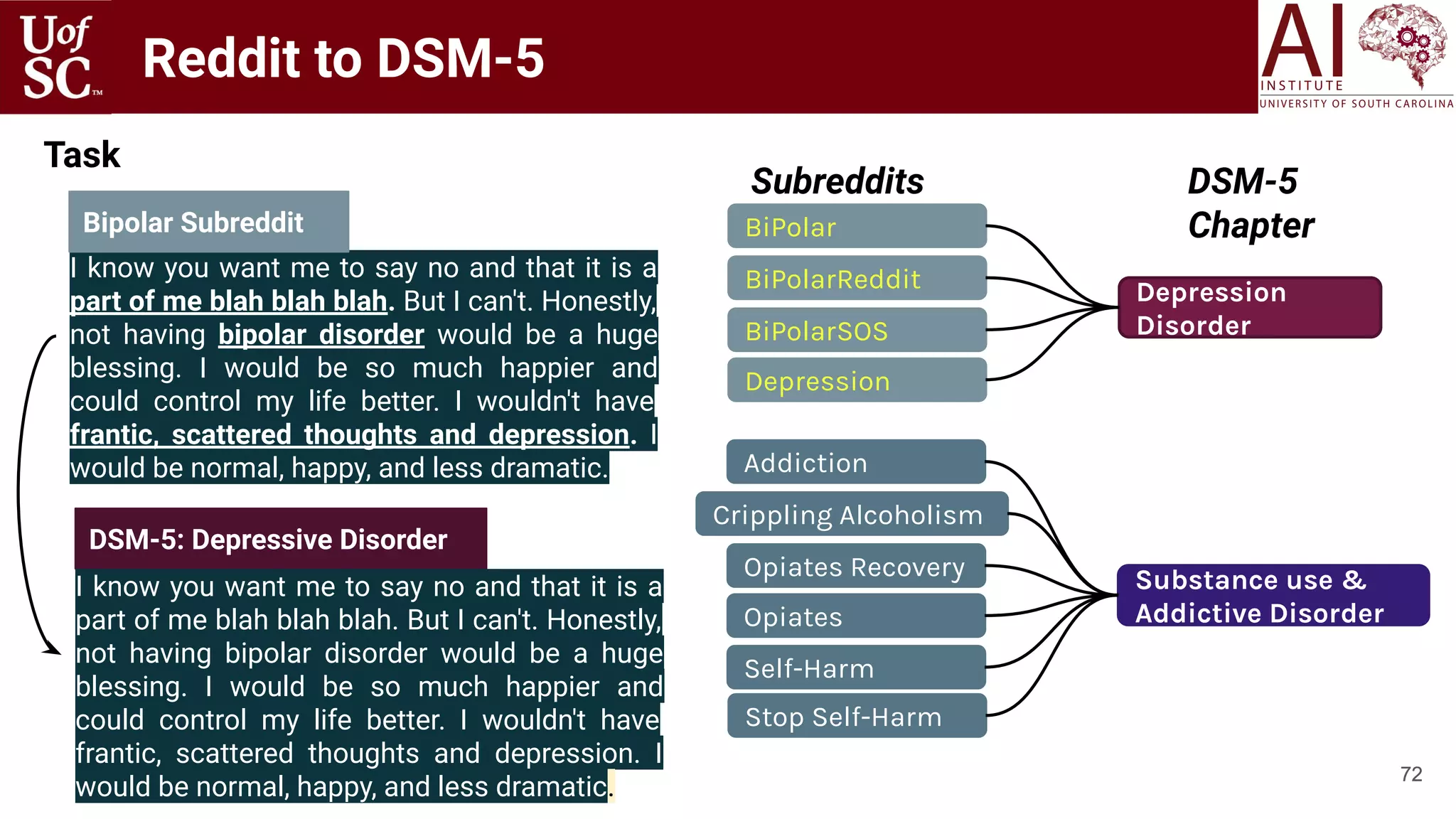
Linking Reddit to DSM-5 : Web-based Intervention
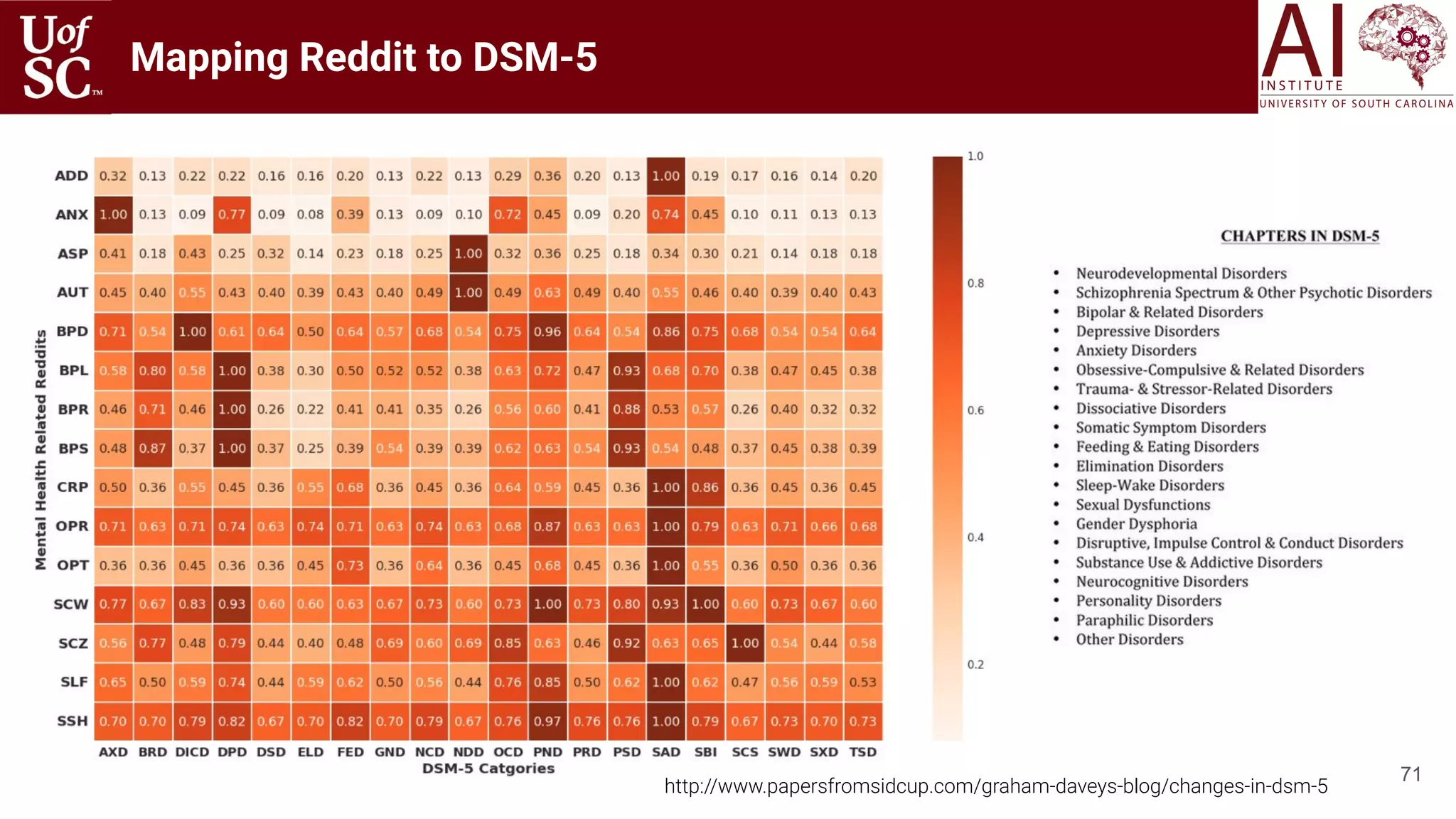
Reddit DSM-5 [Gaur 2018]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-68-2048.jpg)
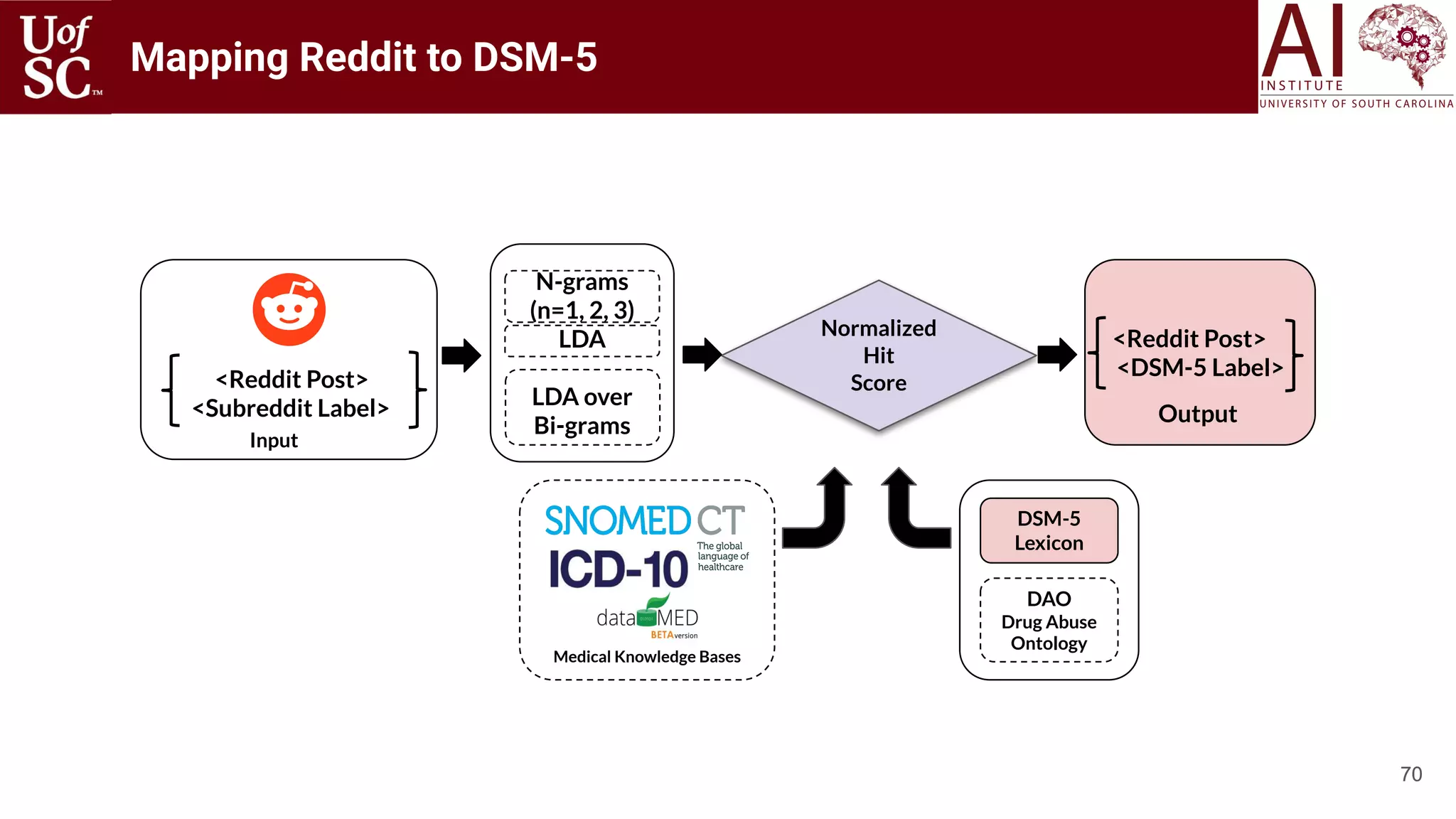
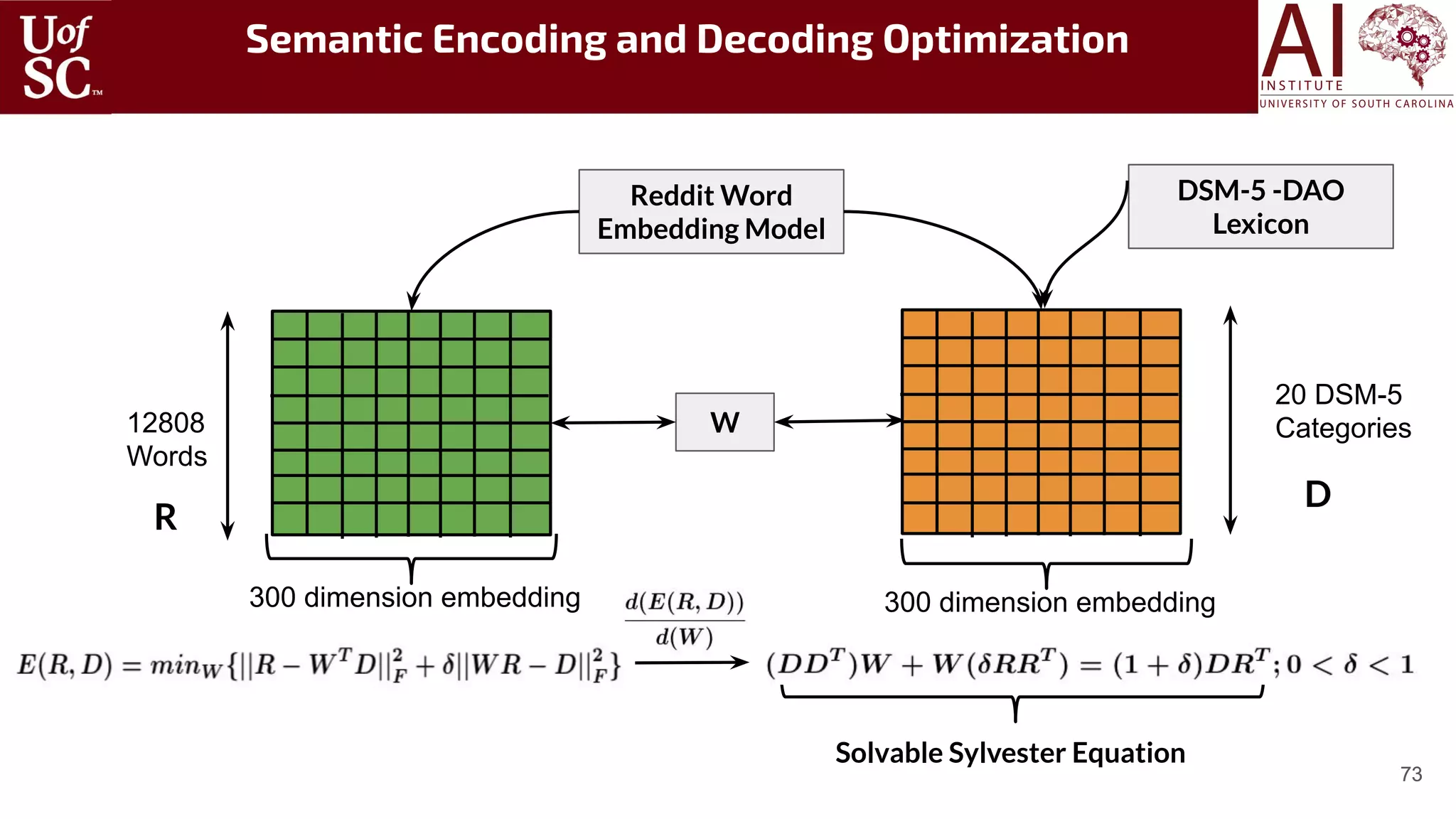

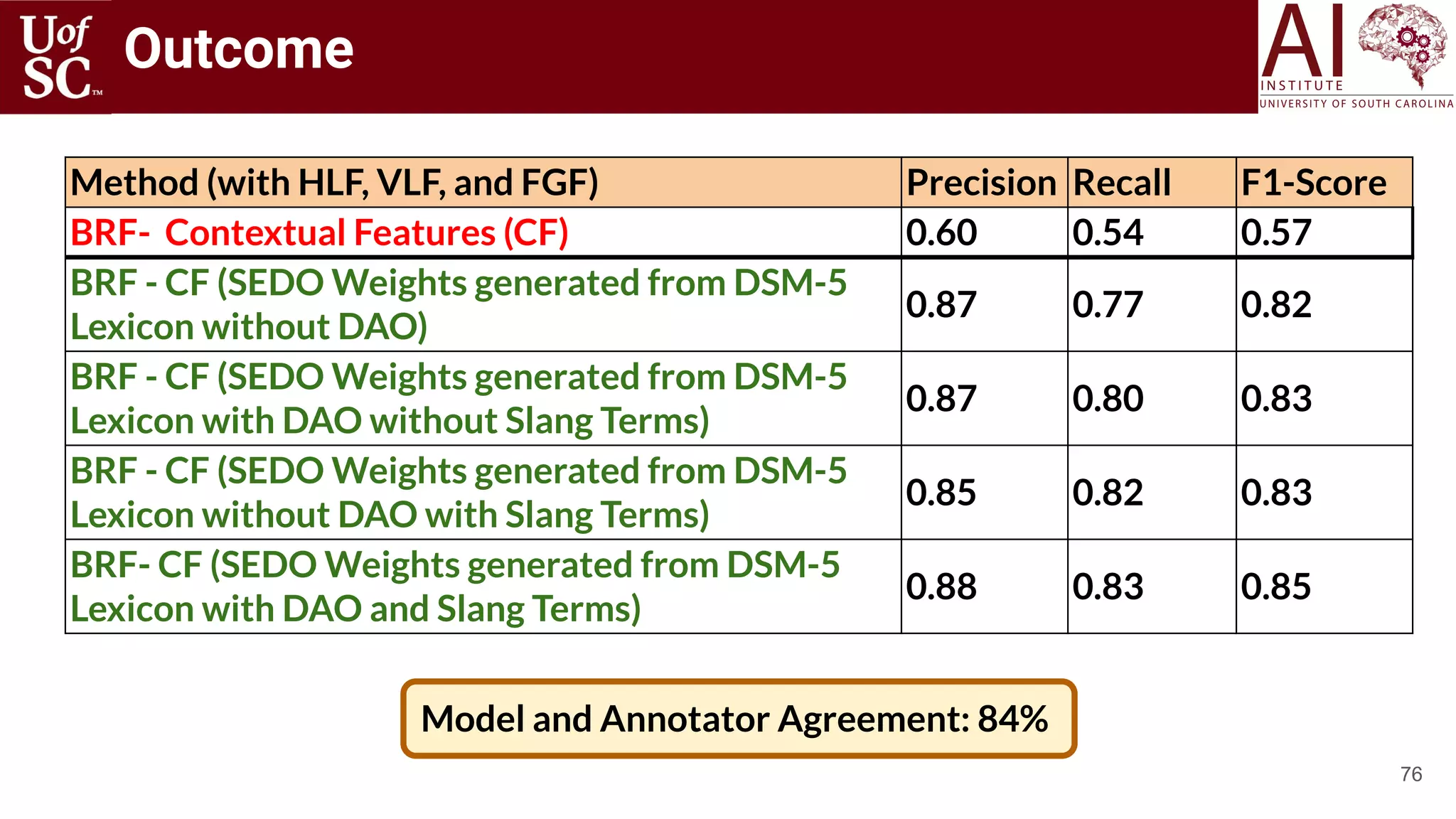
![75
Outcome
Domain-specific
Knowledge lowers
False Alarm Rates.
2005-2016
550K Users
8 Million
Conversations
15 Mental Health
Subreddits
[Gkotsis 2017][Saravia 2016]
[Park 2018]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-75-2048.jpg)




















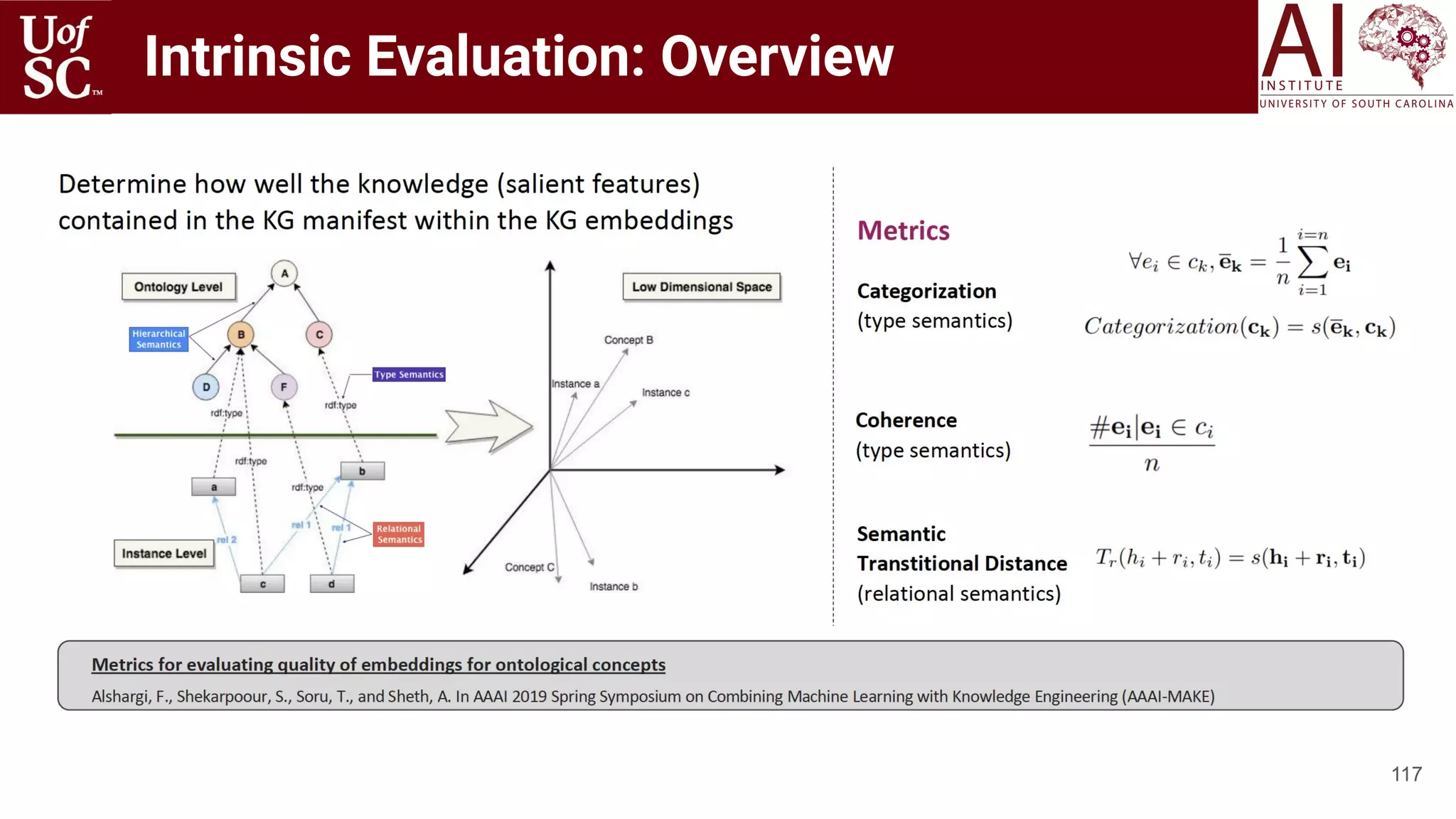
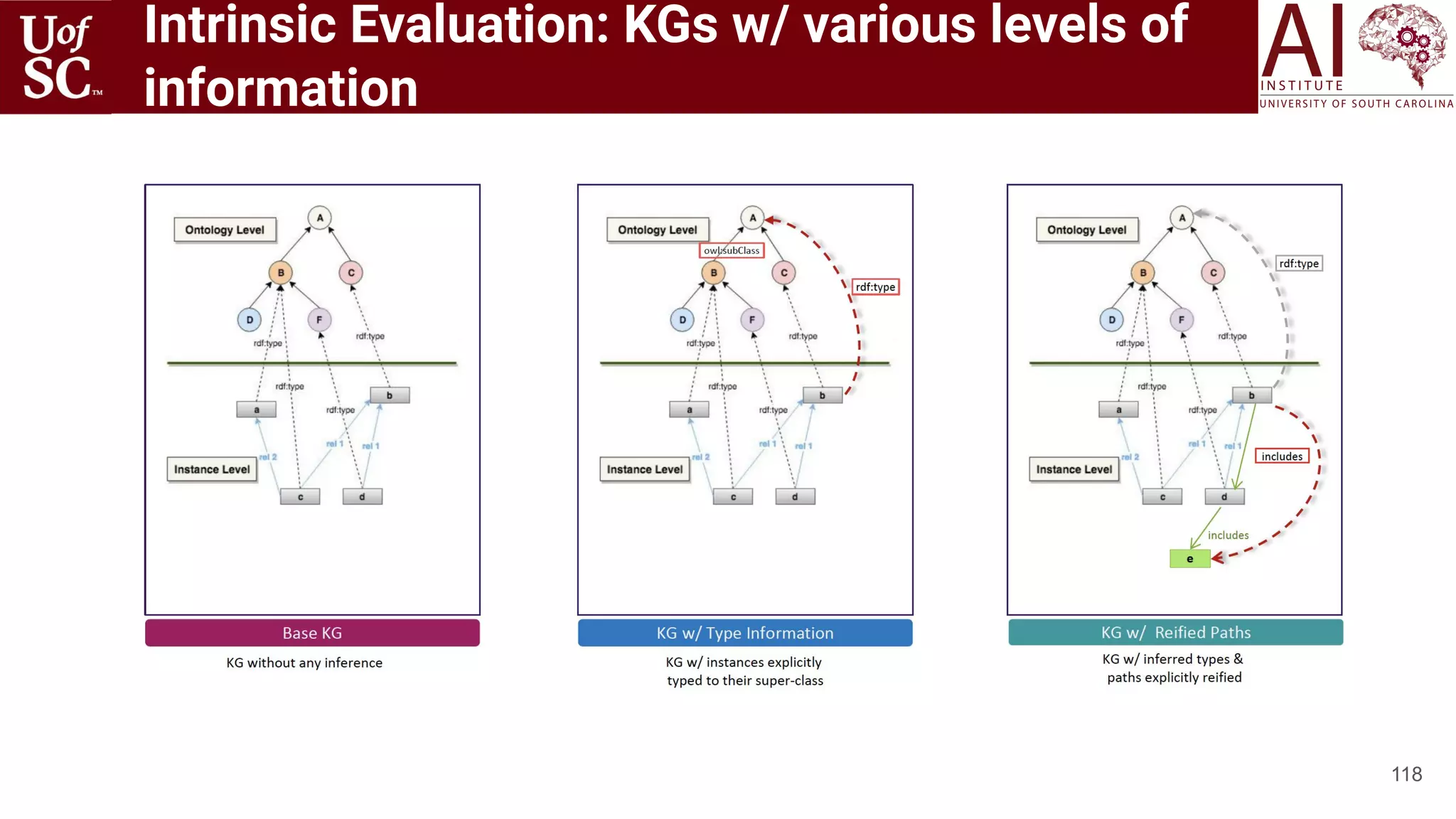
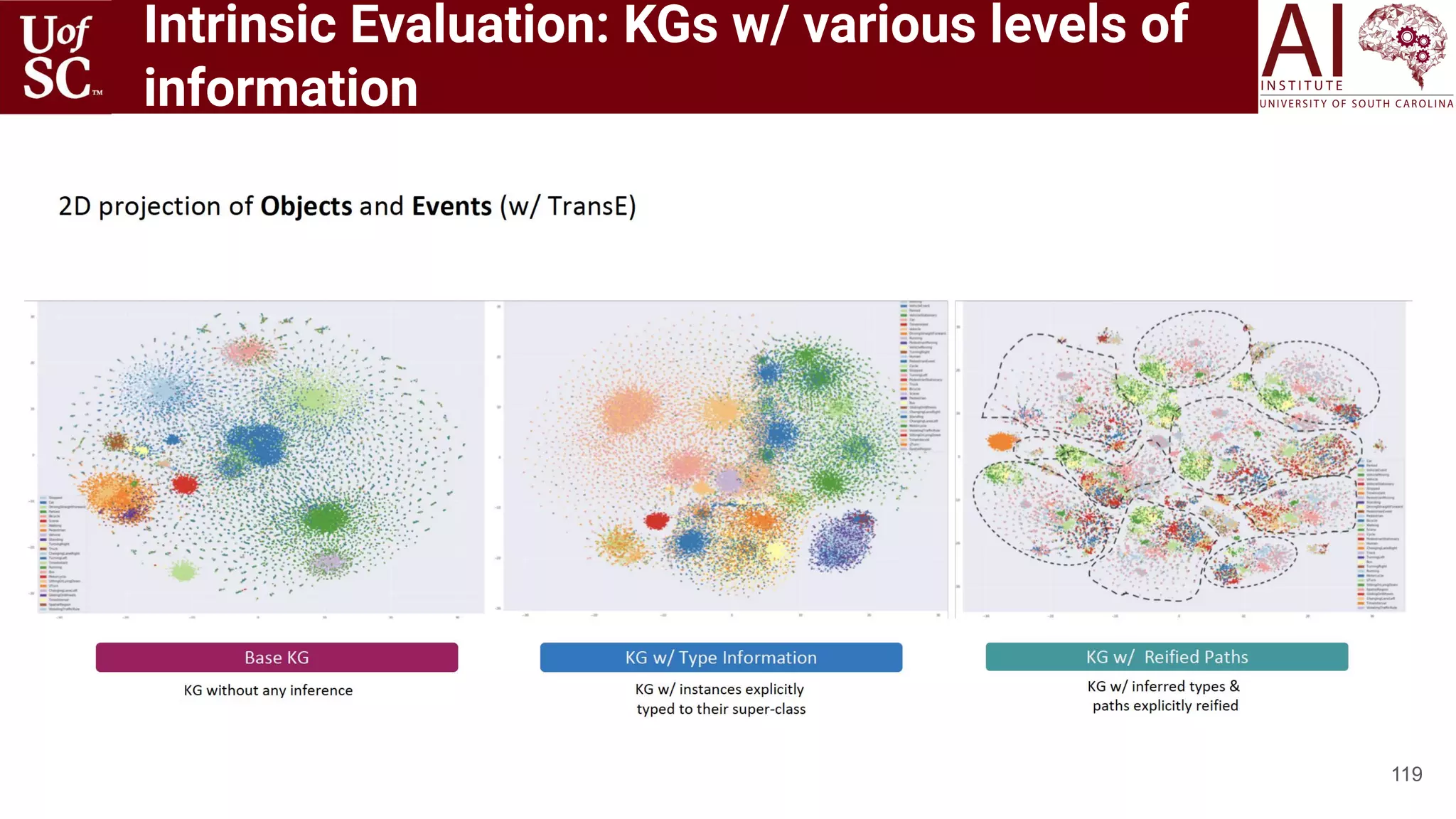
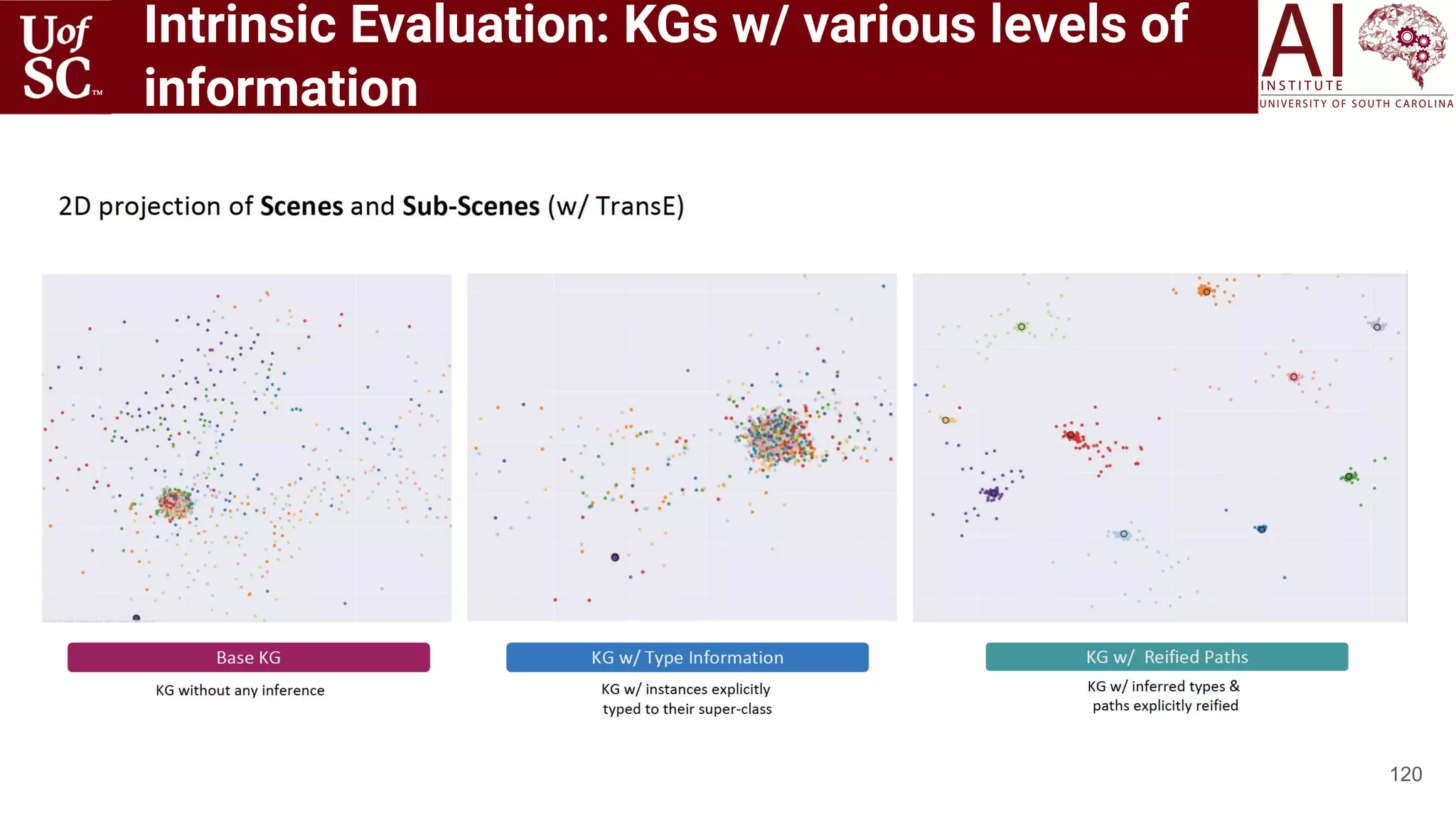
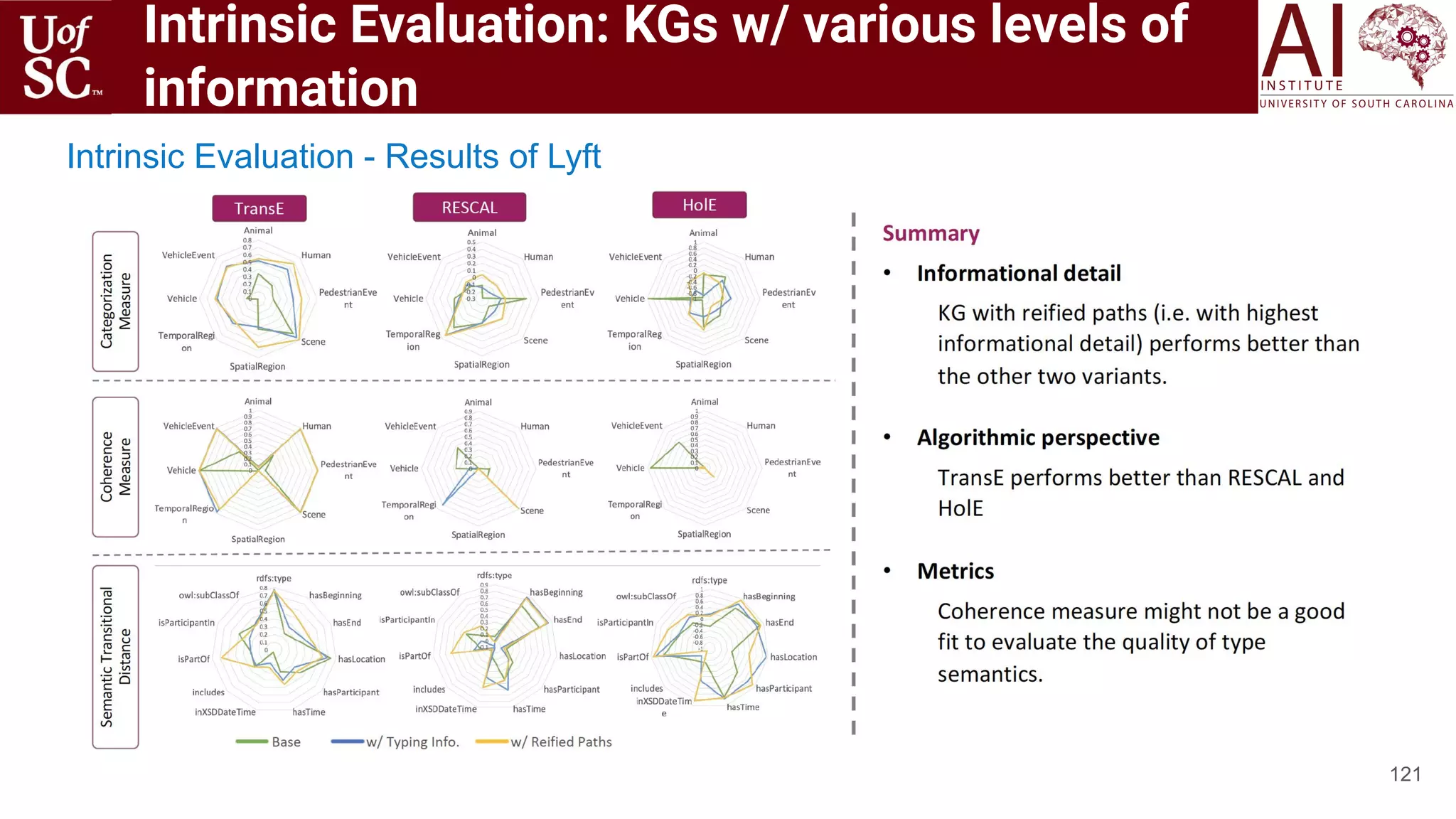






![Motivation
131
◉ Darknet markets have grown substantially even with government
interventions from 2013-2016 [1]
[1] Kristy Kruithof. 2016. Internet-facilitated drugs trade: An analysis of the size, scope and the role of the Netherlands. RAND.
Feature Growth
Total revenue 2x
Total number of transactions 3x
Total number of listings 5.5x
Total number of listings per vendor 2x
Incremental growth of the Darknet Market [1]](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-131-2048.jpg)


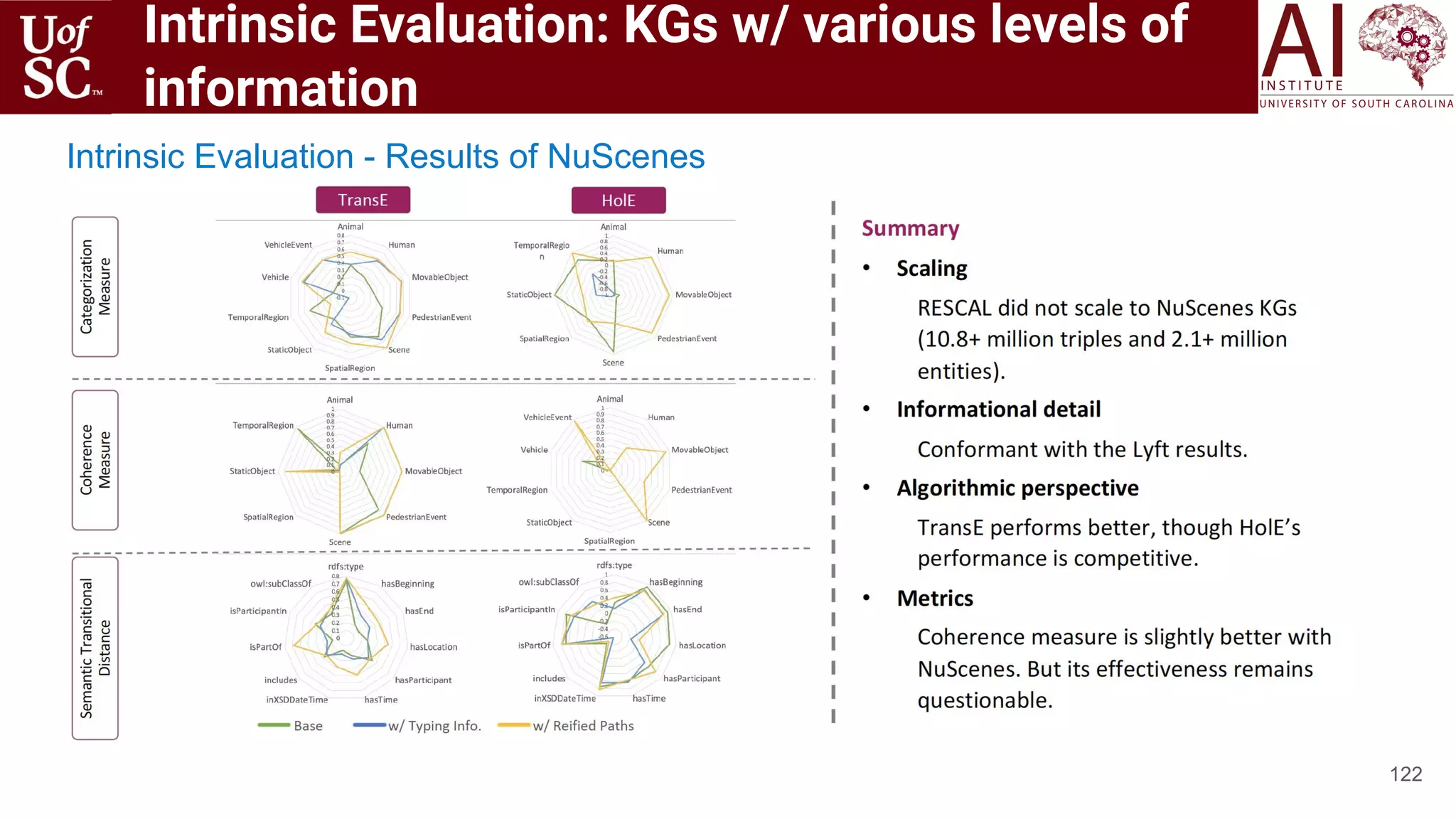
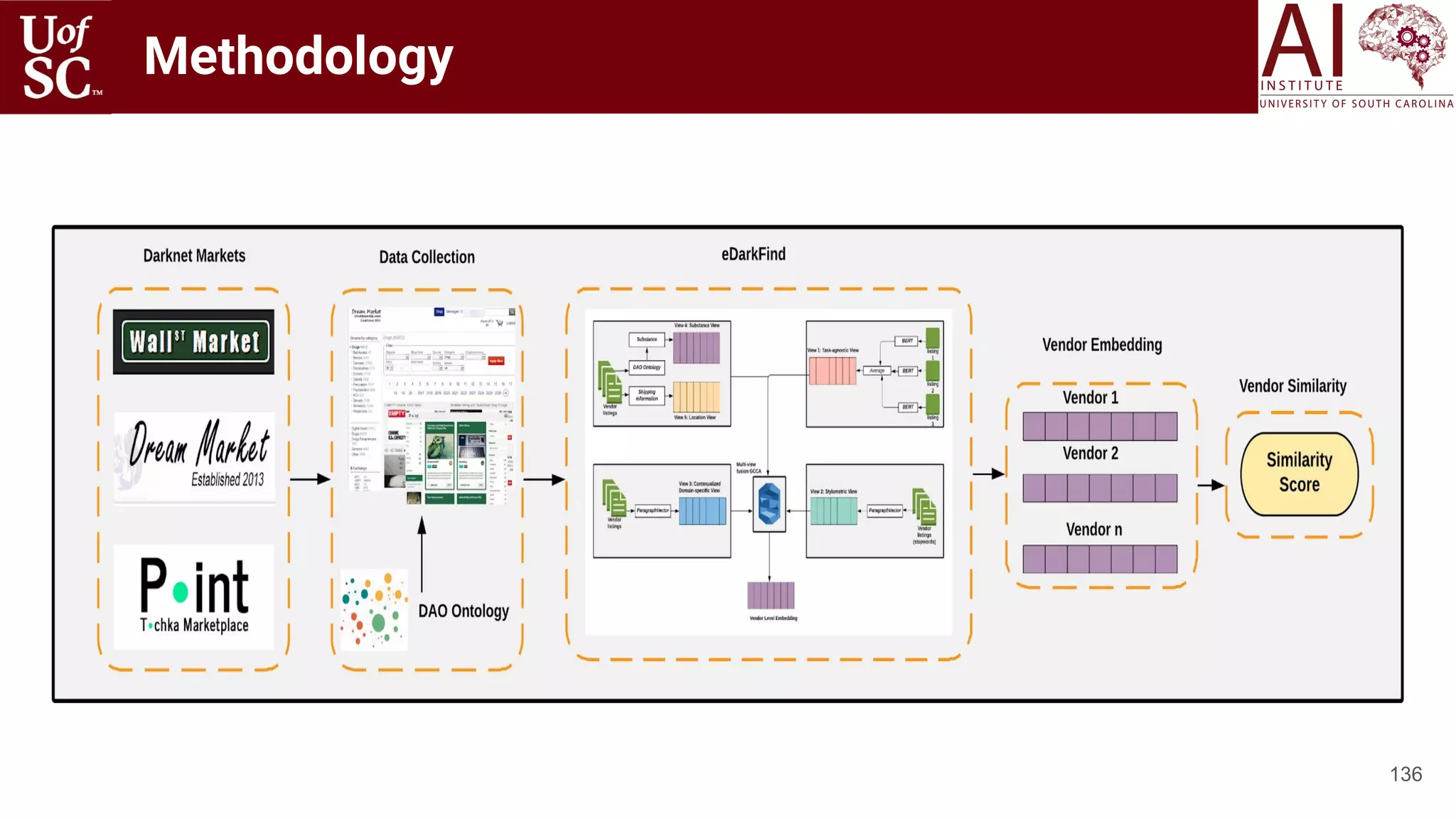
![Dataset Creation
135
◉ Data extracted using eDarkTrends platform [5] with 1992 unique vendors
collected over 3 different sites.
[5] Usha Lokala, Francois R Lamy, Raminta Daniulaityte, Amit Sheth, Ramzi W Nahhas, Jason I Roden, Shweta Yadav, and Robert G Carlson. 2019. Global trends, local harms:
availability of fentanyl-type drugs on the dark web and accidental overdoses in Ohio. Computational and Mathematical Organization Theory 25, 1 (2019), 48–59.
Dark Web Sites Dream Market Tochka Wall street All
Unique # Vendor names 1448 408 466 1992
Unique # Substance 852 313 290 1148
Unique # Location 356 44 29 389
Unique # Descriptions 16800 1829 1723 18472](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-135-2048.jpg)

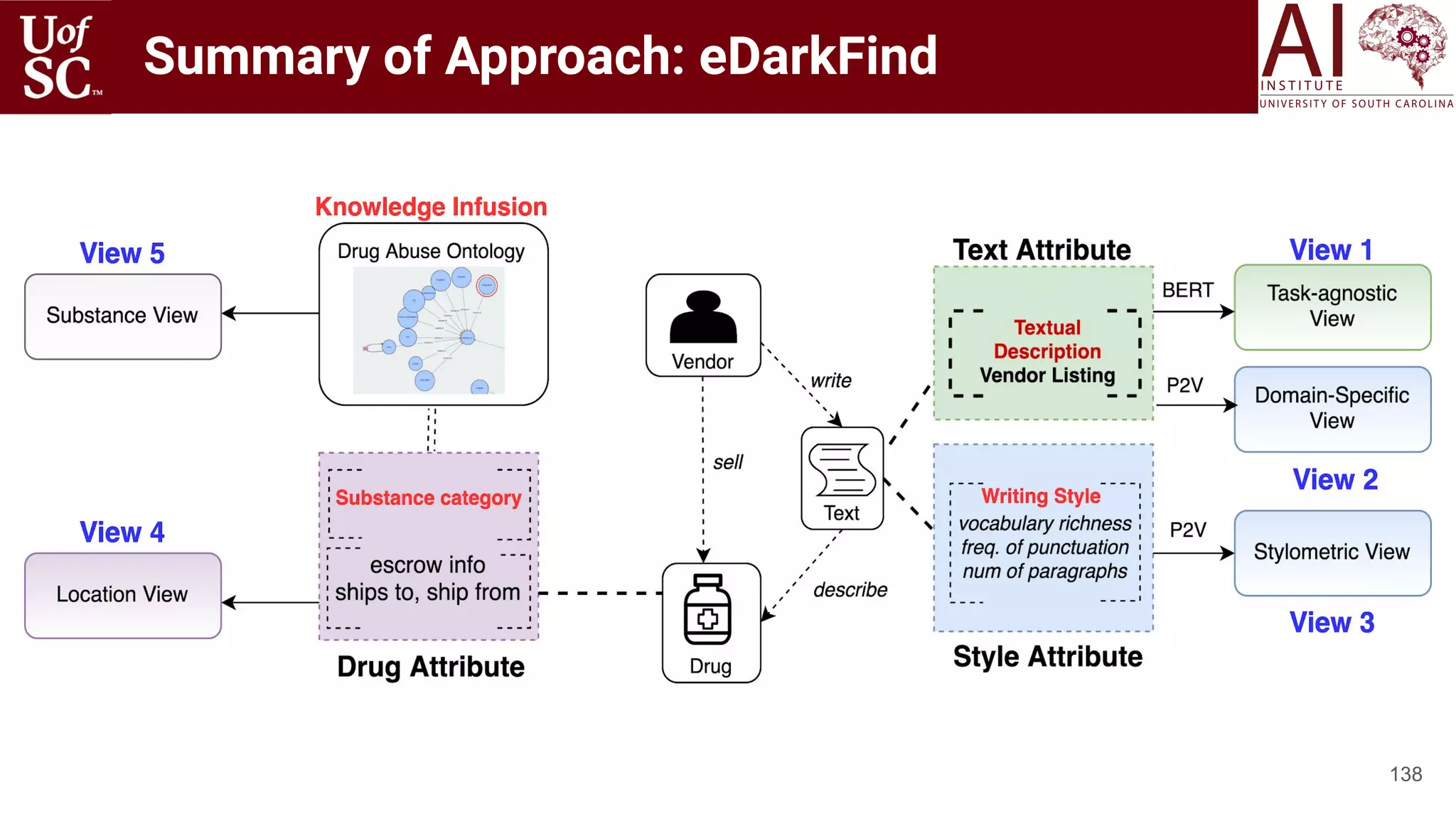


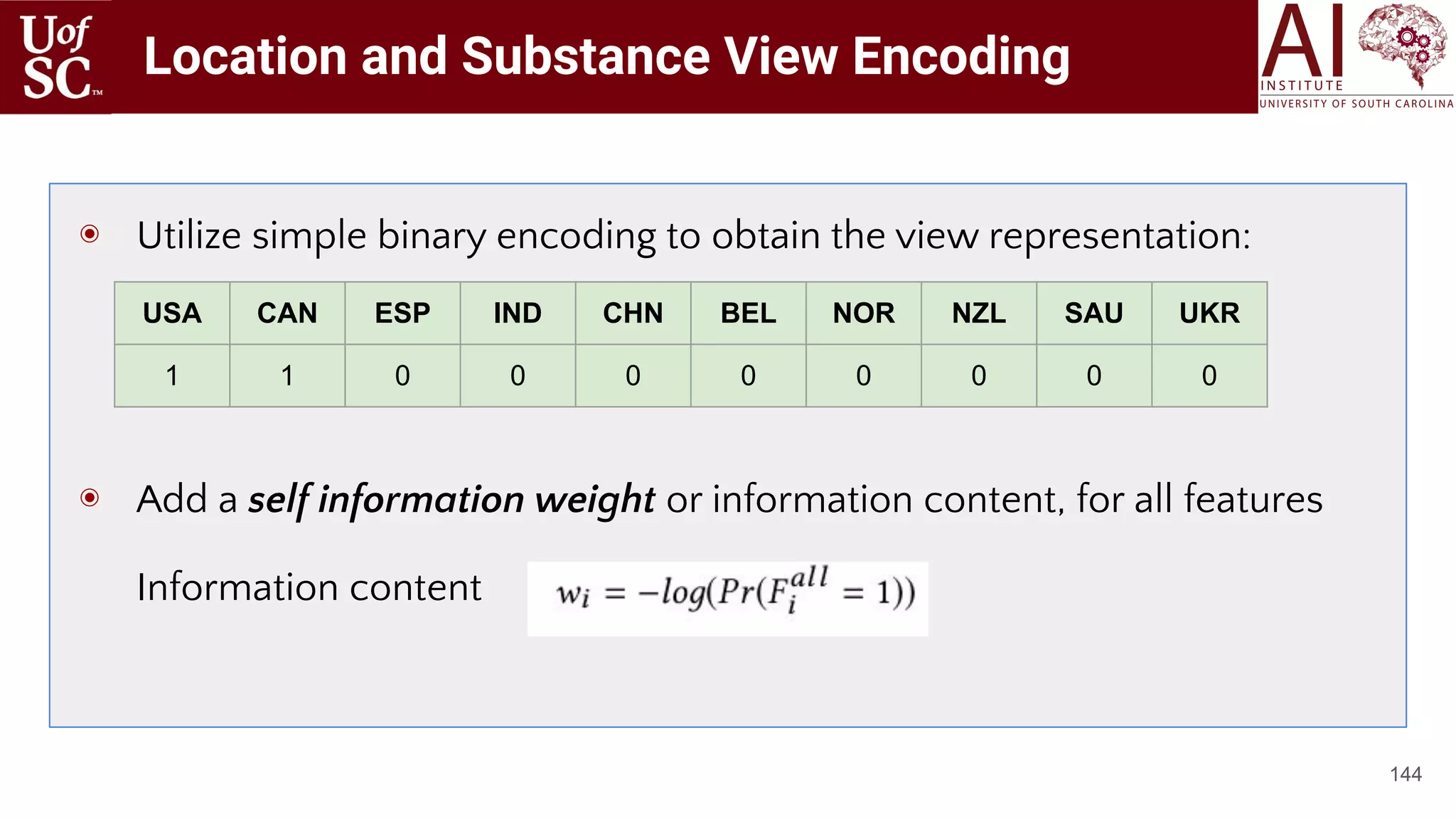
![Multi-view Fusion-Canonical Correlation
Analysis
145
◉ Cannot simply concatenate since each vector
may correspond to different modalities (image vs
text) or very different distributional properties
◉ These views are fused using CCA [9] to obtain a
single representation, which we call Vendor
embedding
◉ Allows us to infer information from cross
variance matrices
◉ Employ an extension called weighted generalized
CCA.
[9] Harold Hotelling. 1992. Relations between two sets of variates. In Breakthroughs in statistics. Springer, 162–190.](https://image.slidesharecdn.com/acmht20tutorialknowledge-infuseddeeplearningaiinstitute-200717021520/75/ACM-Hypertext-and-Social-Media-Conference-Tutorial-on-Knowledge-infused-Deep-Learning-145-2048.jpg)
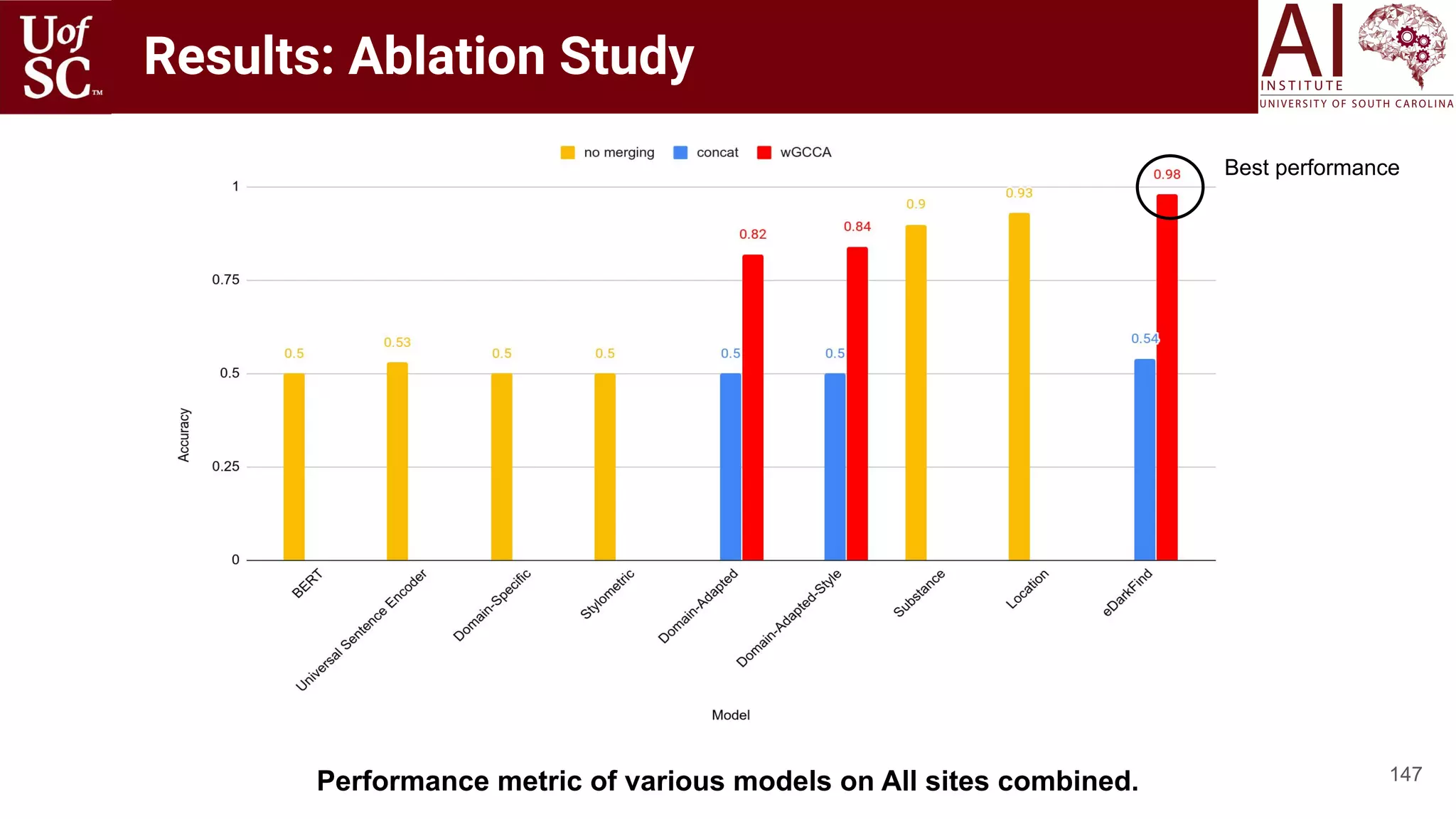








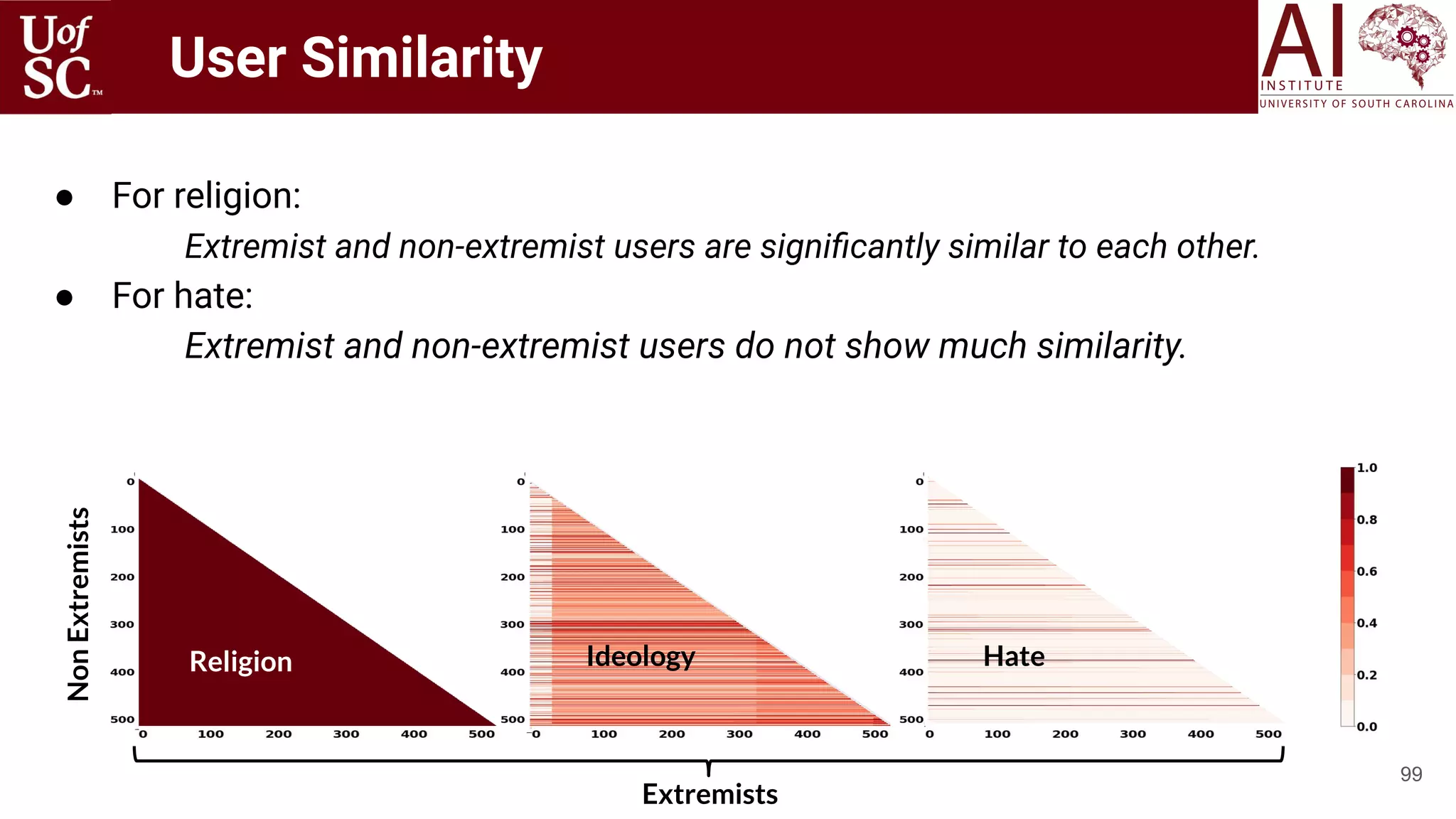
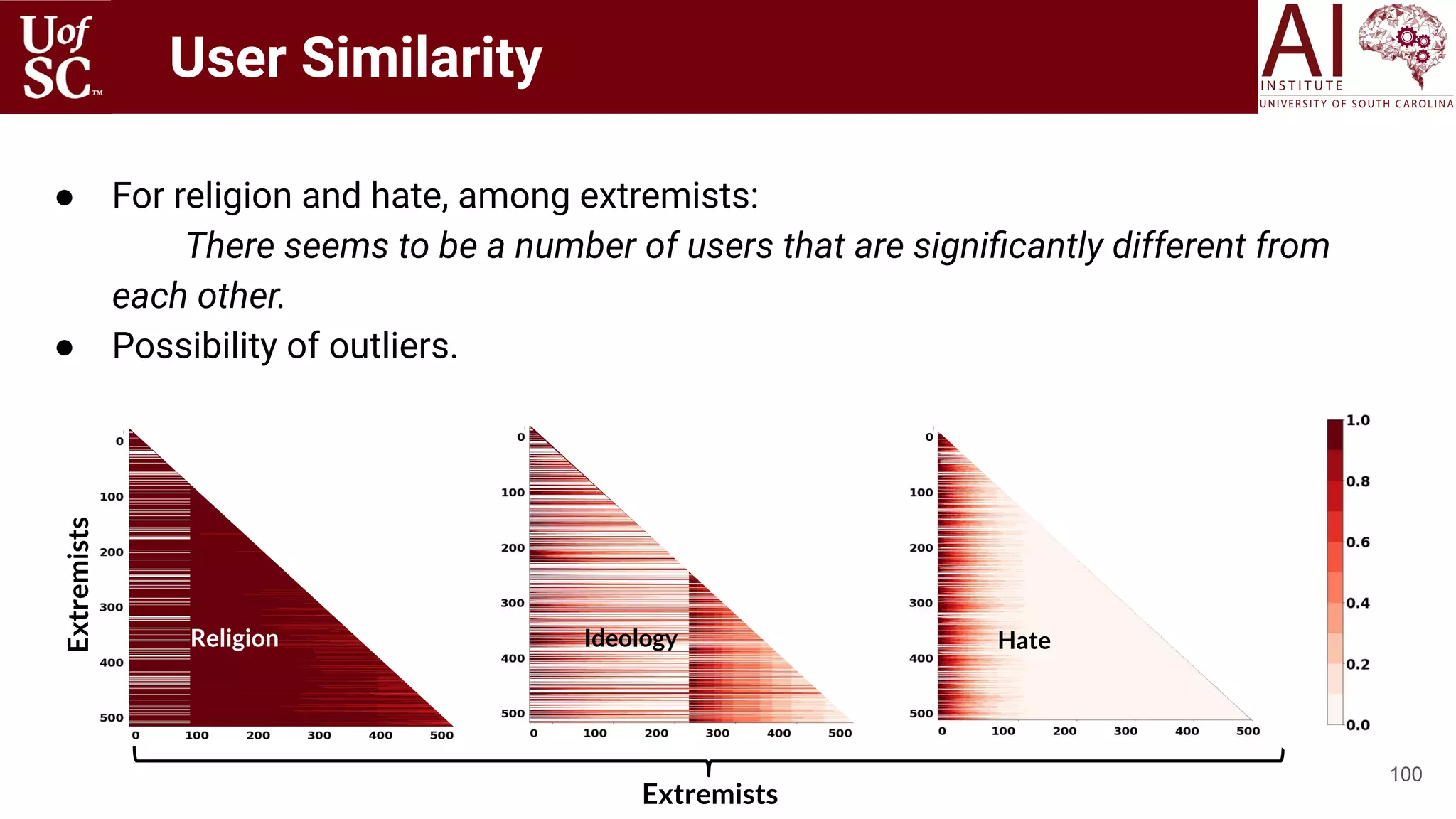
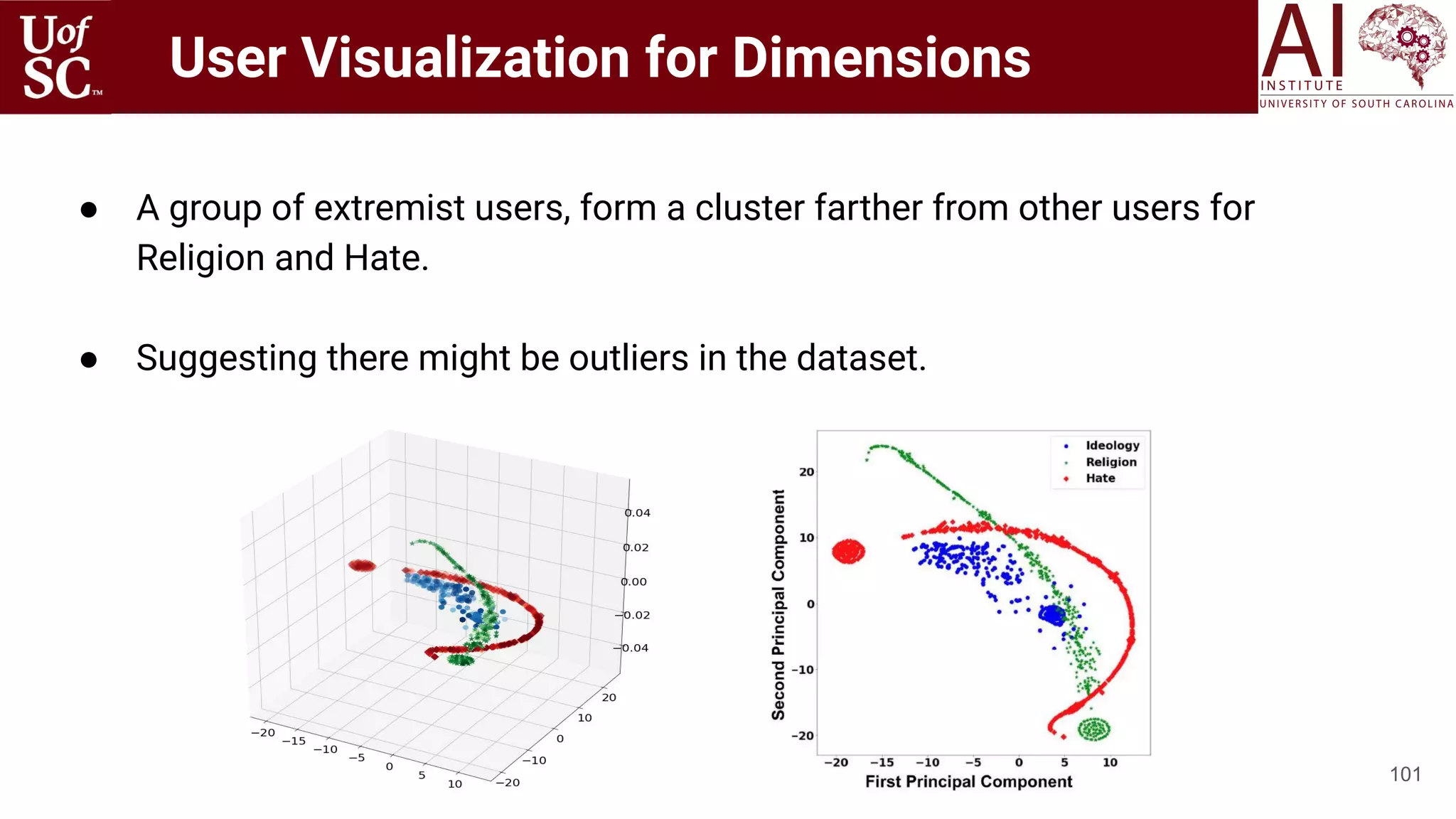
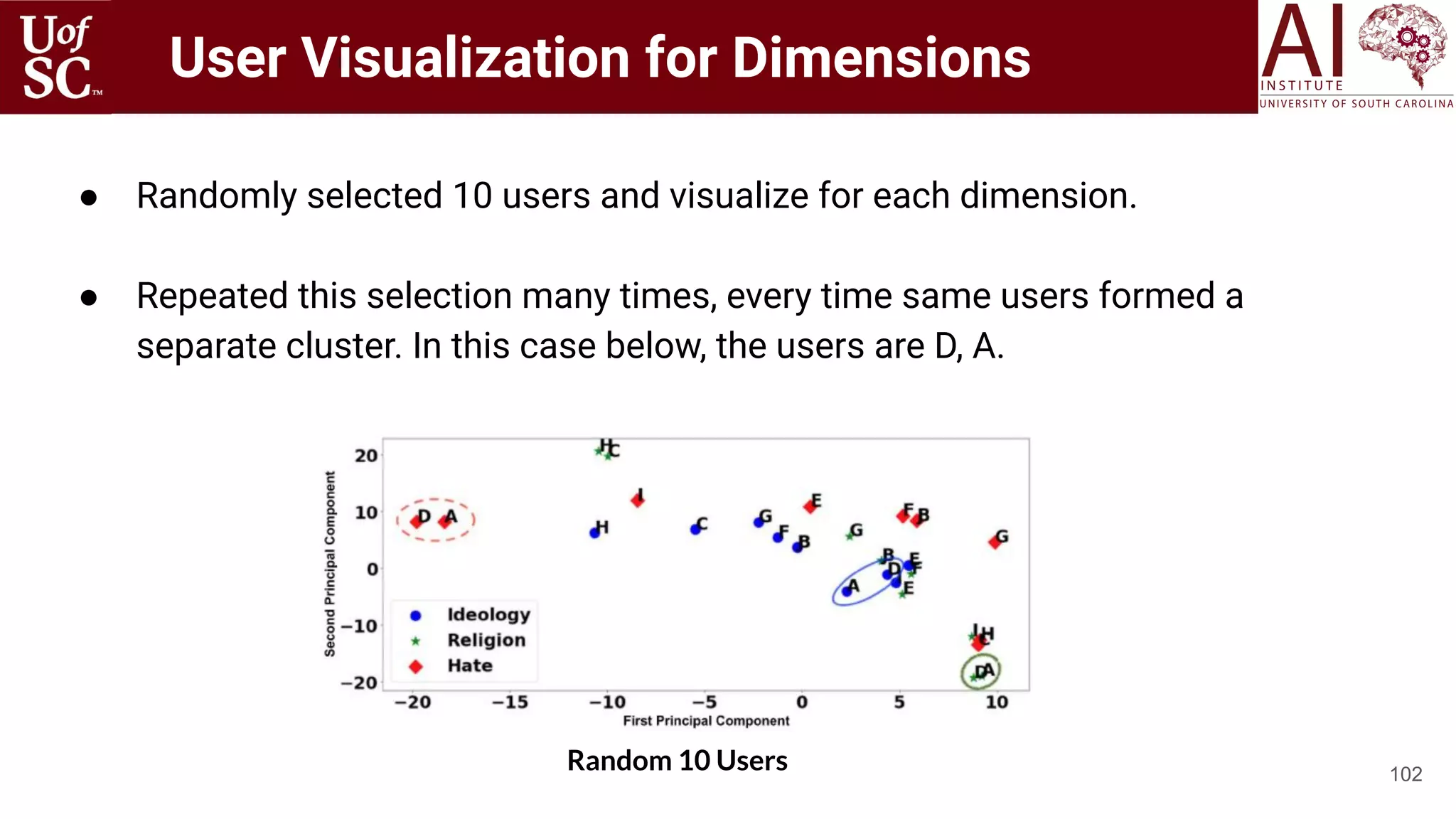
The document is a tutorial by experts from the Artificial Intelligence Institute at the University of South Carolina discussing knowledge-infused deep learning and the significance of knowledge graphs in enhancing machine understanding. It outlines how knowledge can improve artificial intelligence applications, particularly in natural language processing and machine learning, highlighting the challenges and strategies for integrating domain knowledge into these systems. Additionally, it explores various applications of knowledge graphs, including in healthcare, conversational AI, and educational technology.





















































