Downloaded 22 times



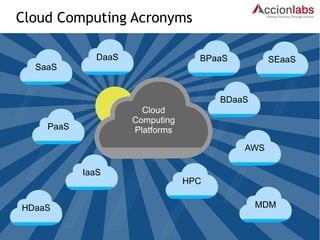
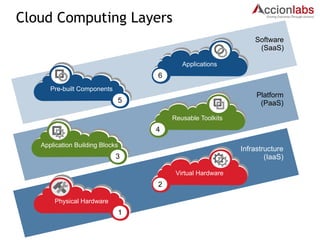
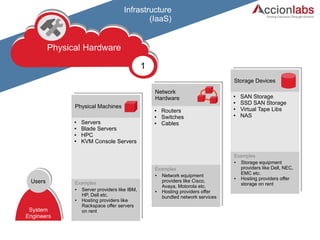
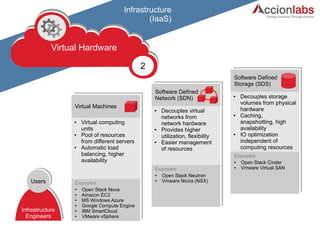
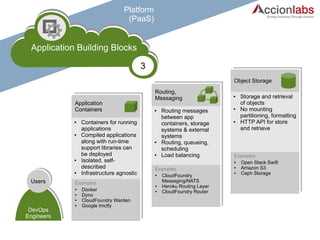
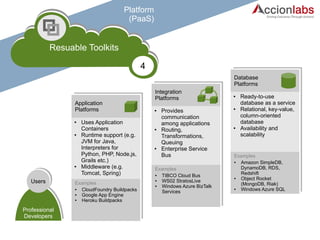
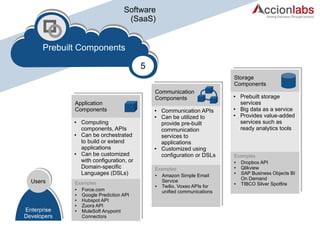
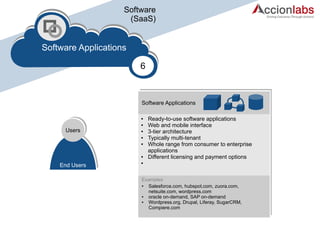

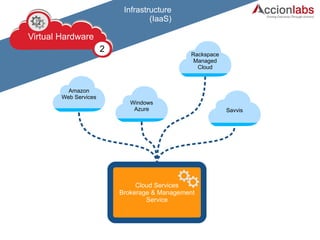



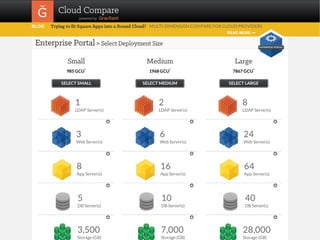
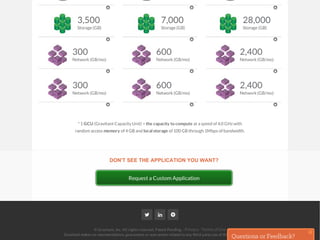
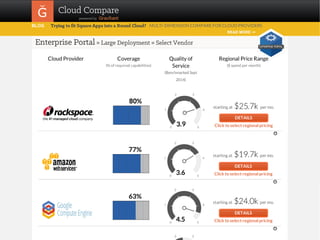
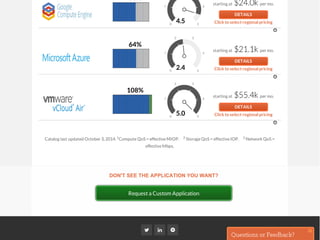

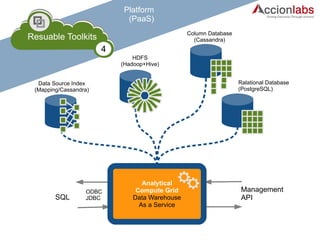

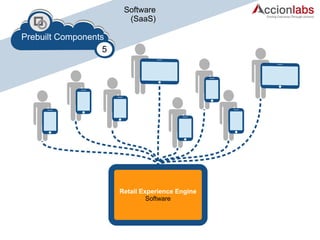



The document outlines a framework for classifying and comparing different cloud computing services, focusing on the layers of cloud computing: IaaS, PaaS, and SaaS. It provides examples of applications, tools, and technologies associated with each layer, detailing their functionalities and user bases. Additionally, the text discusses the infrastructure, platform, and software components of cloud computing services, emphasizing their practical applications and integration.