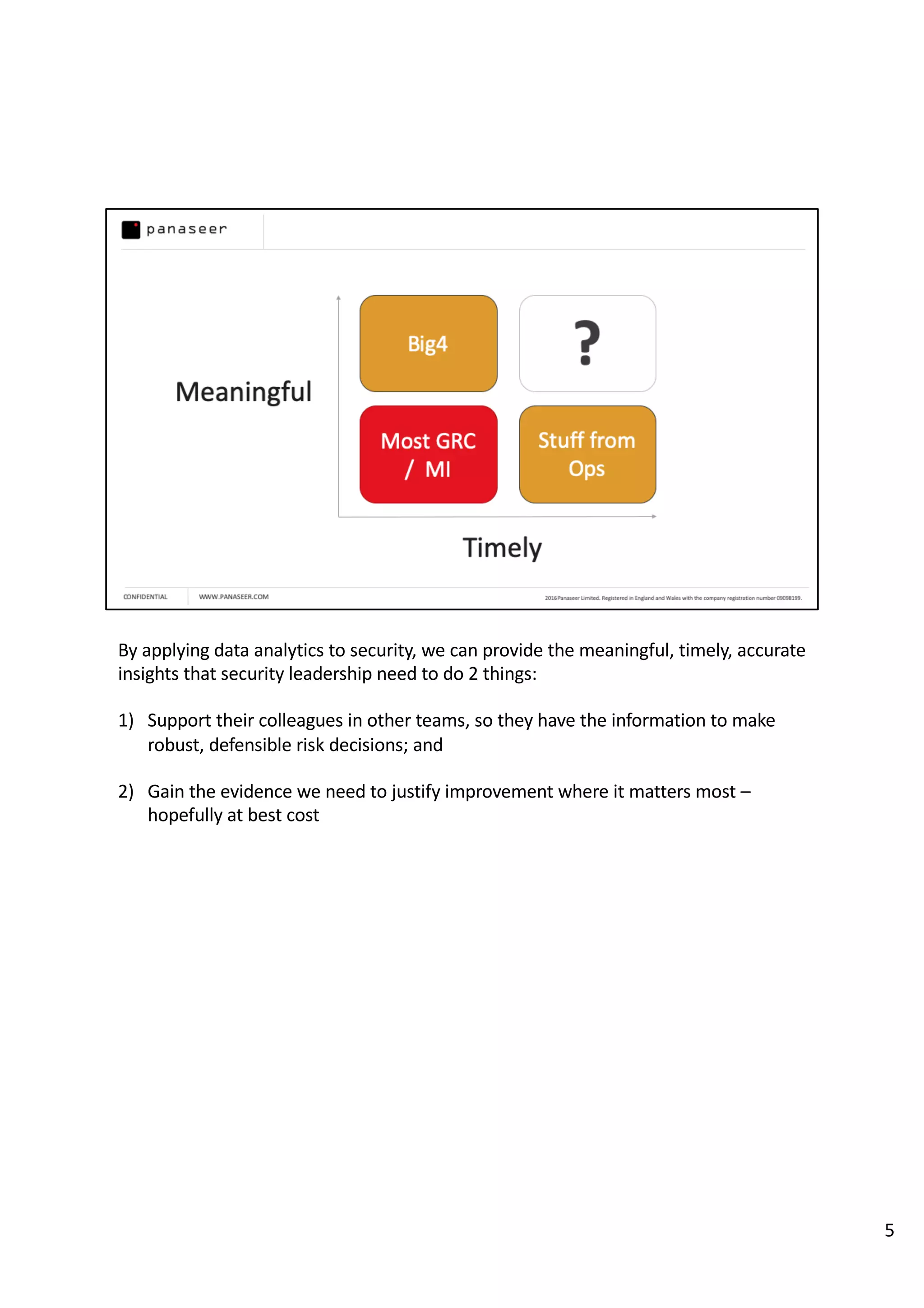
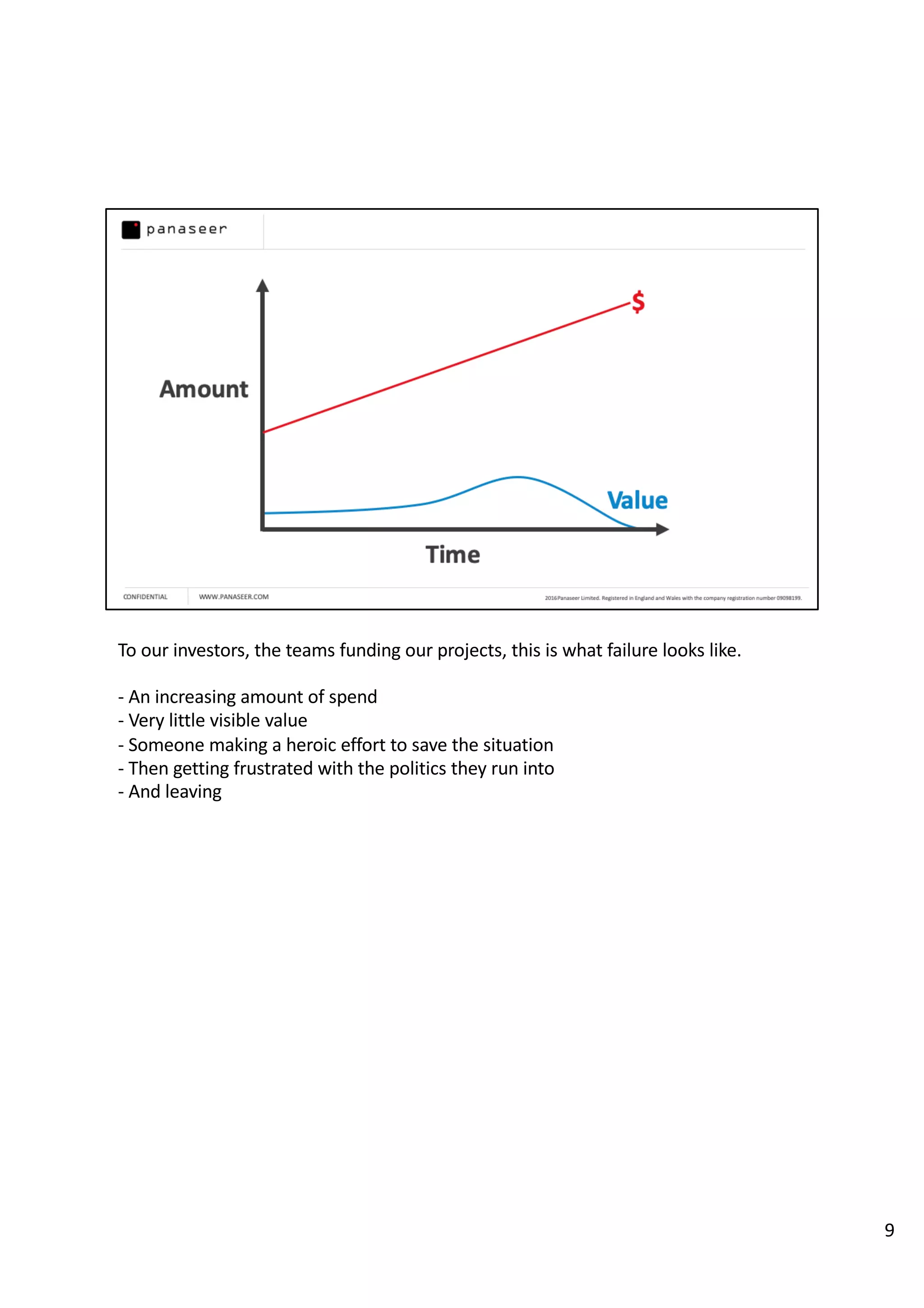
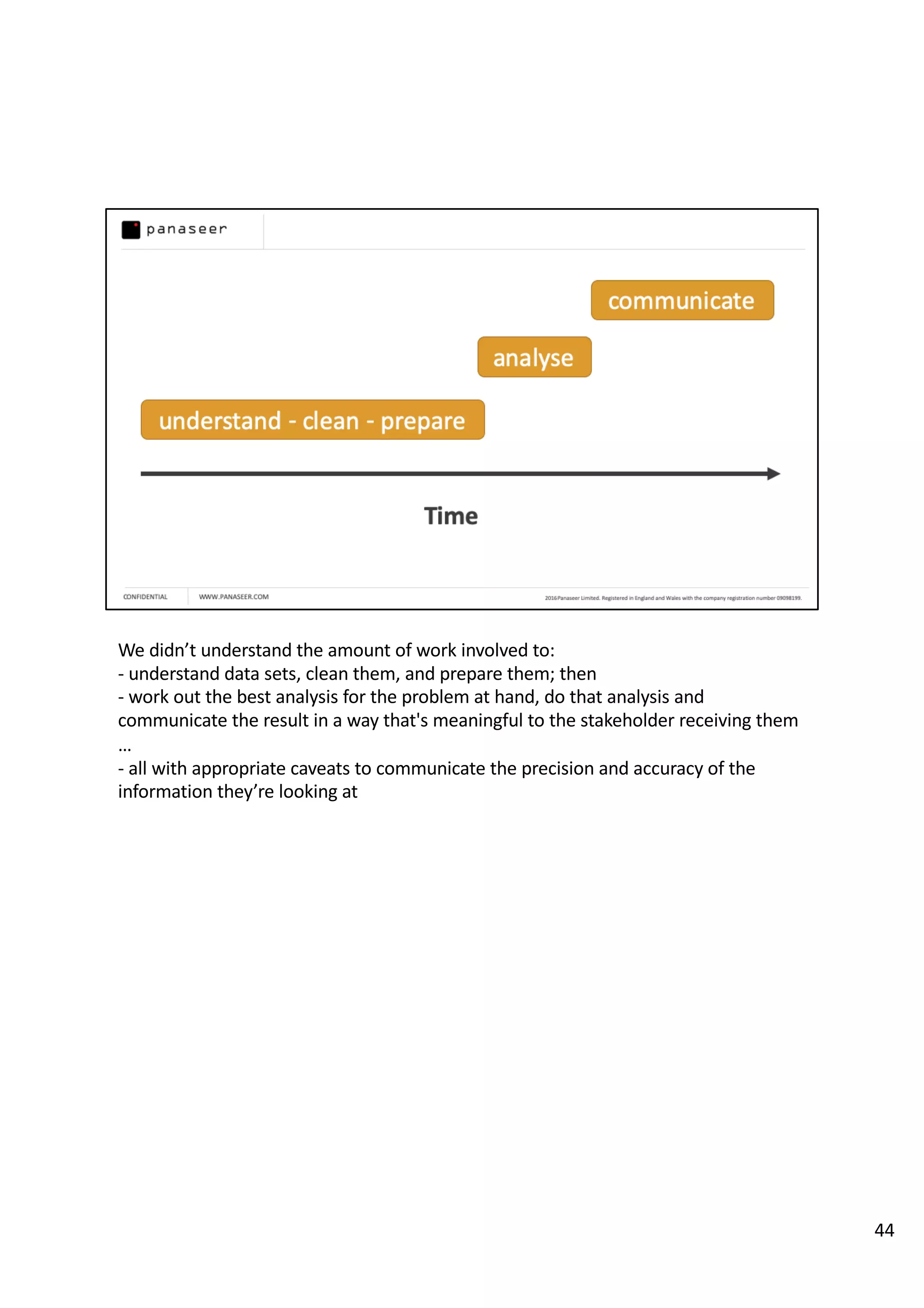
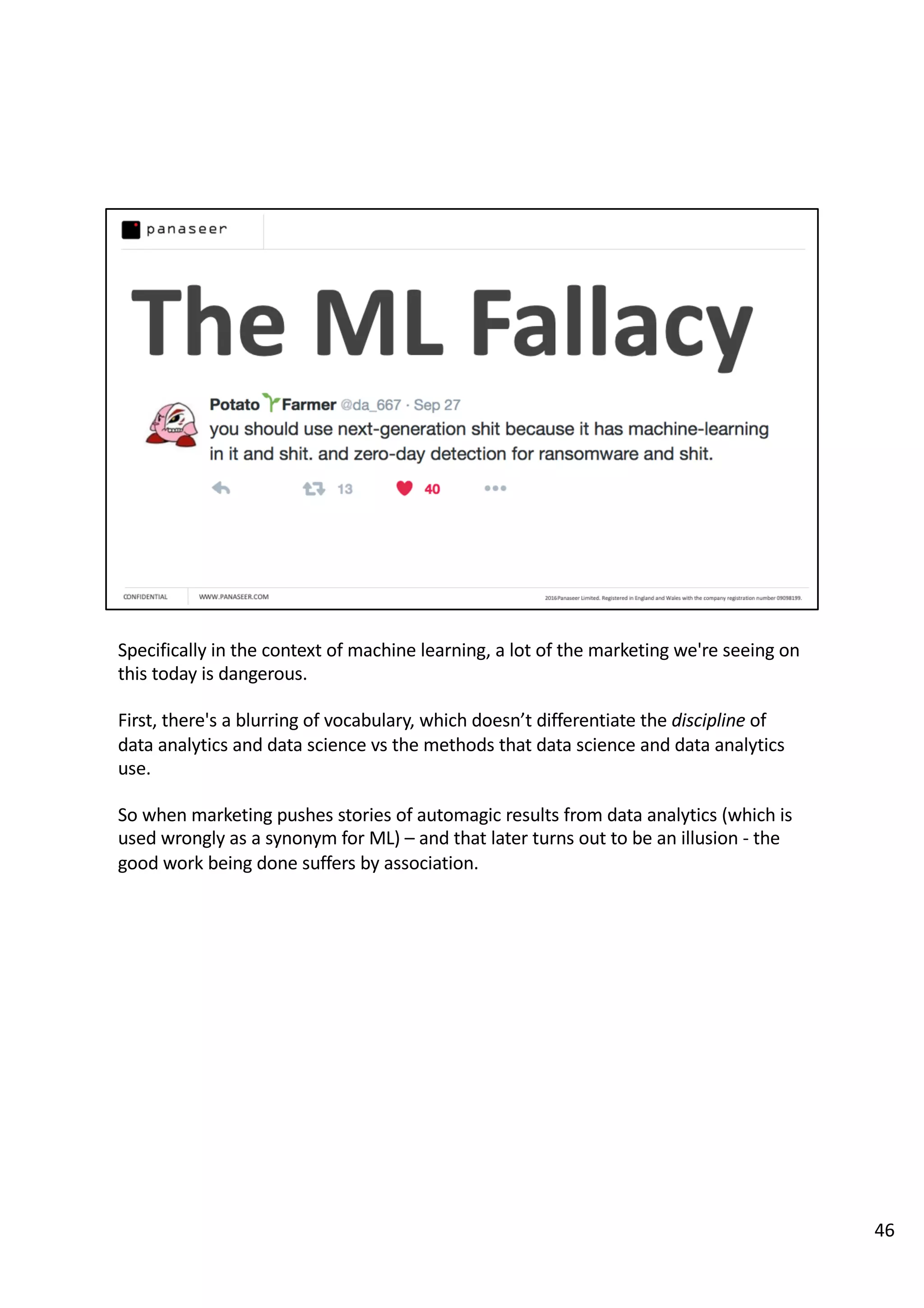
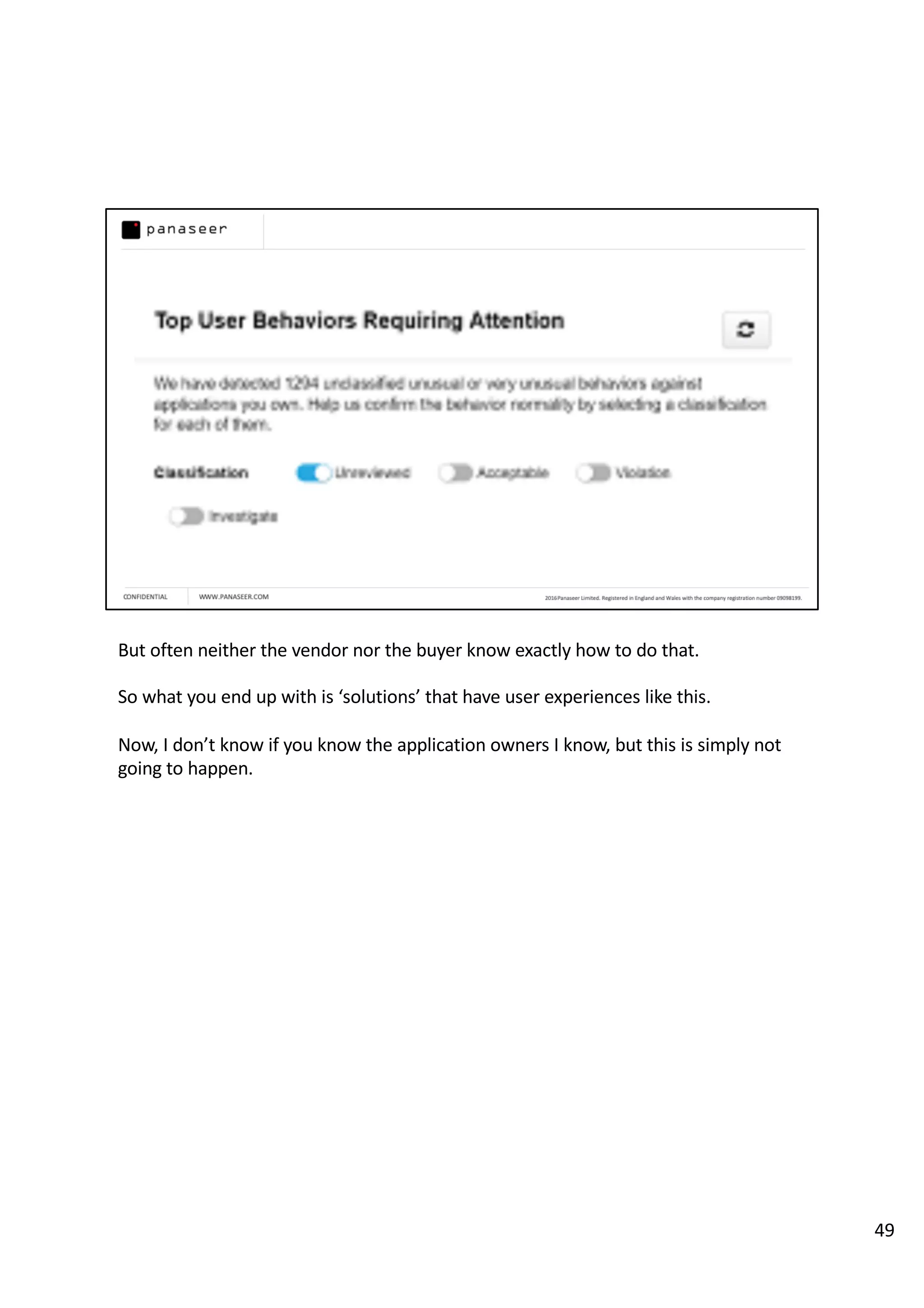
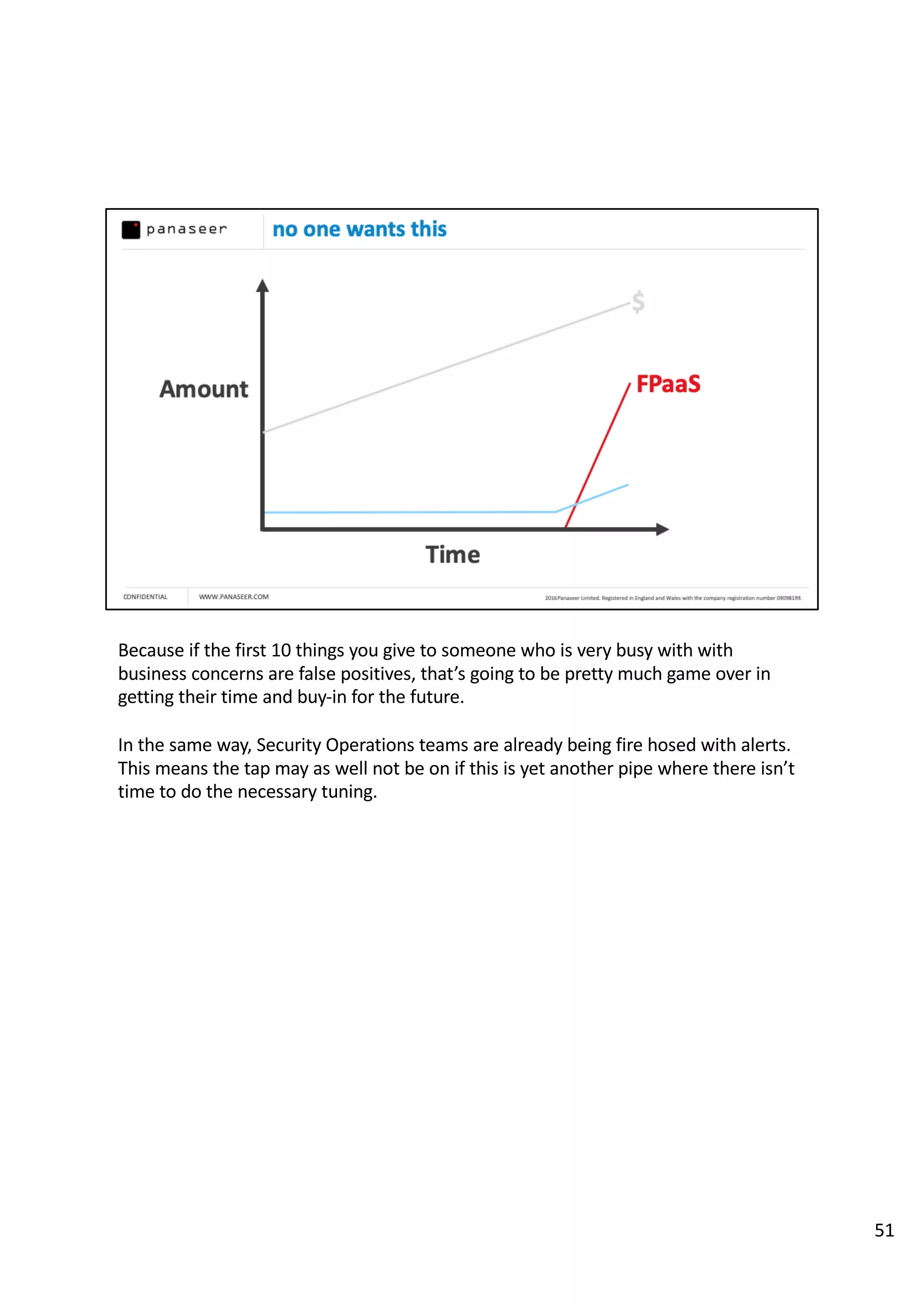
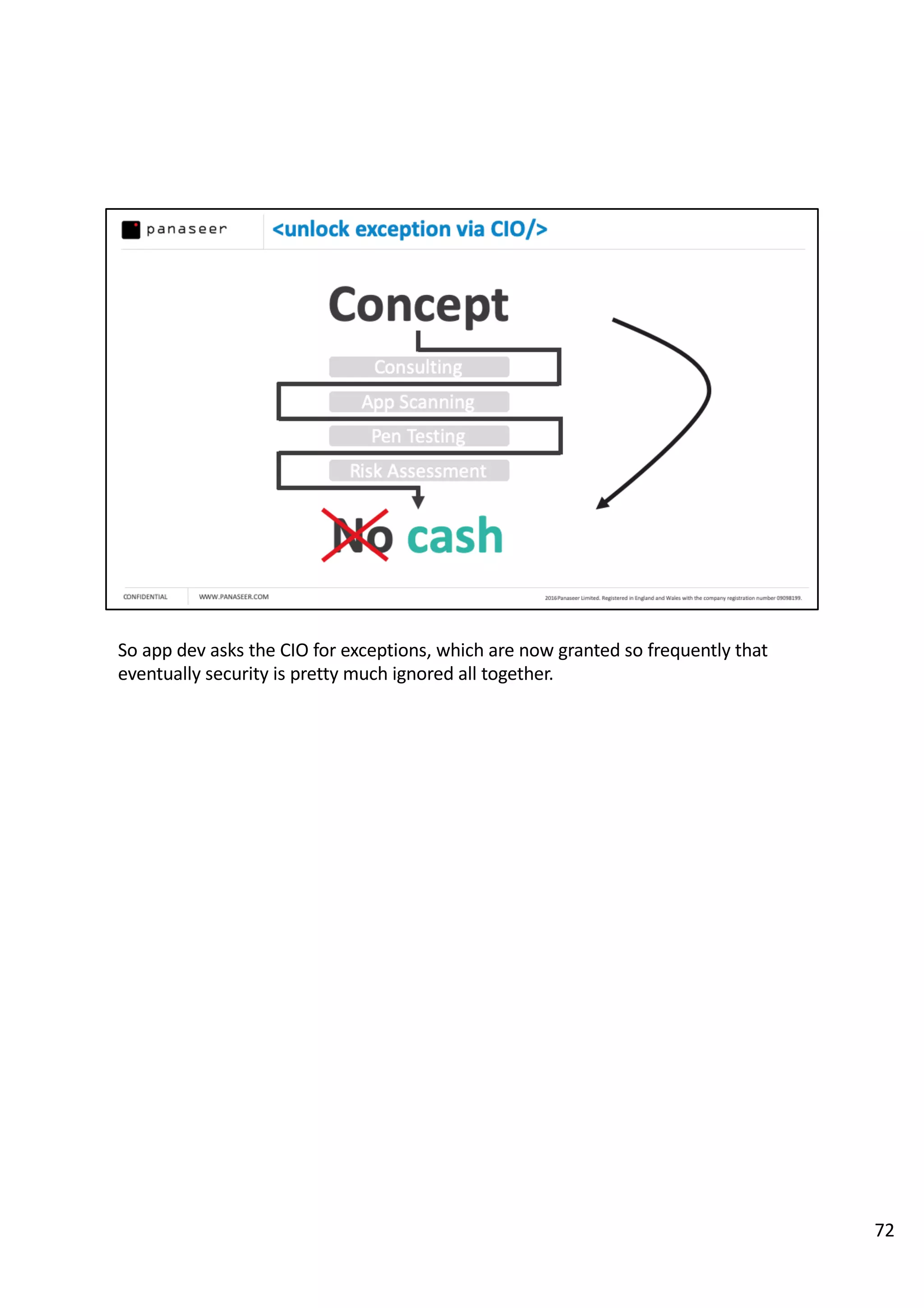
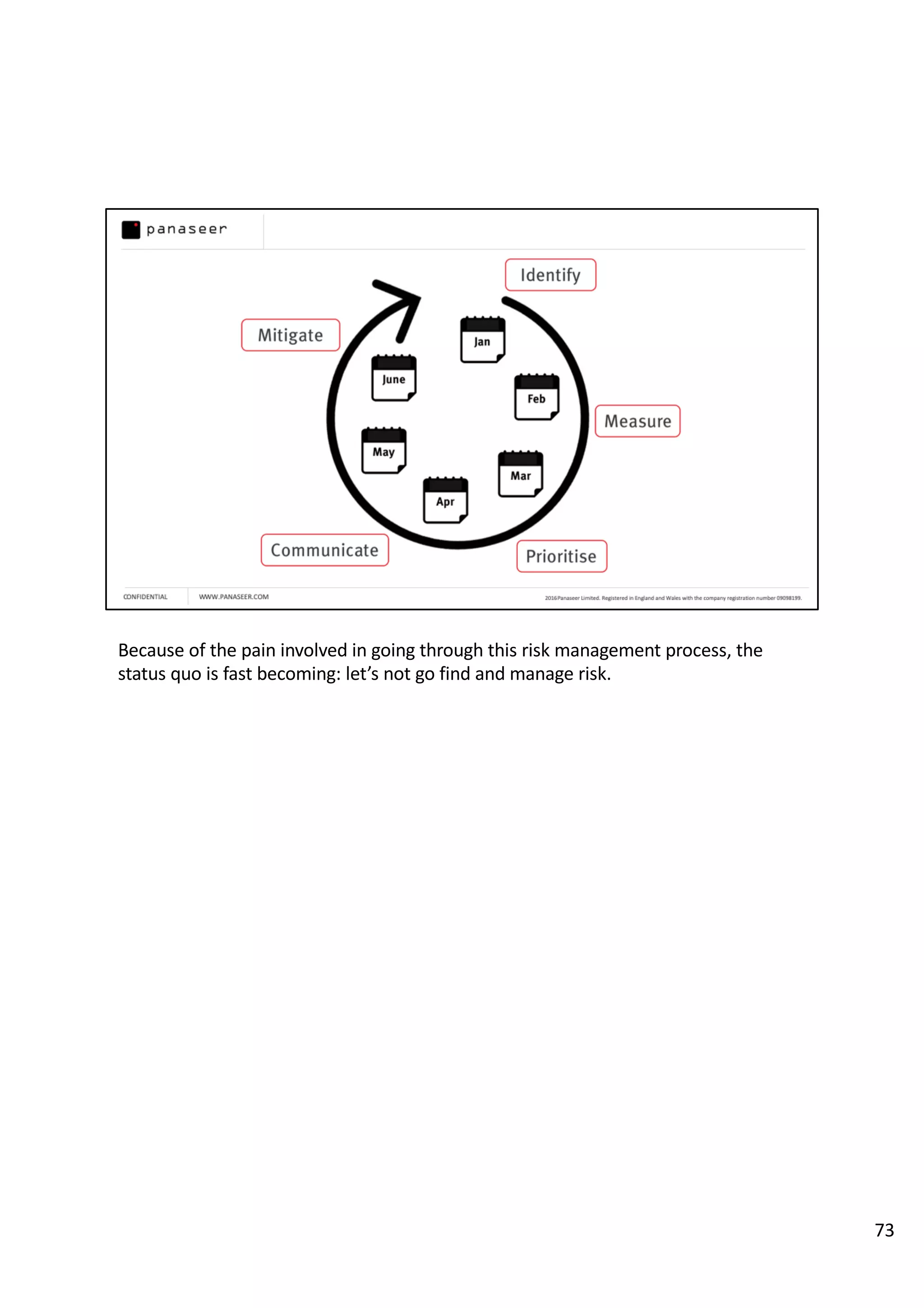
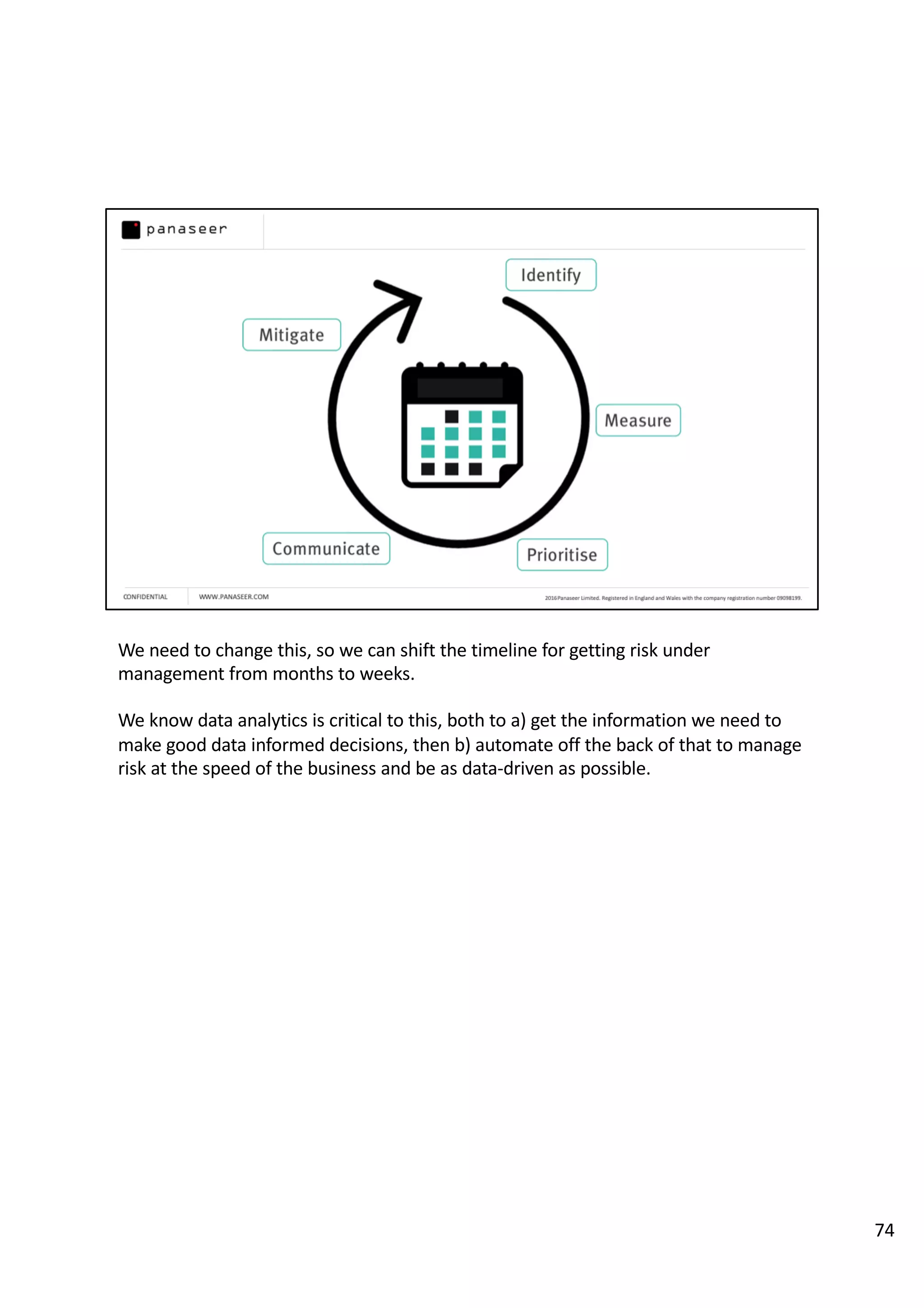
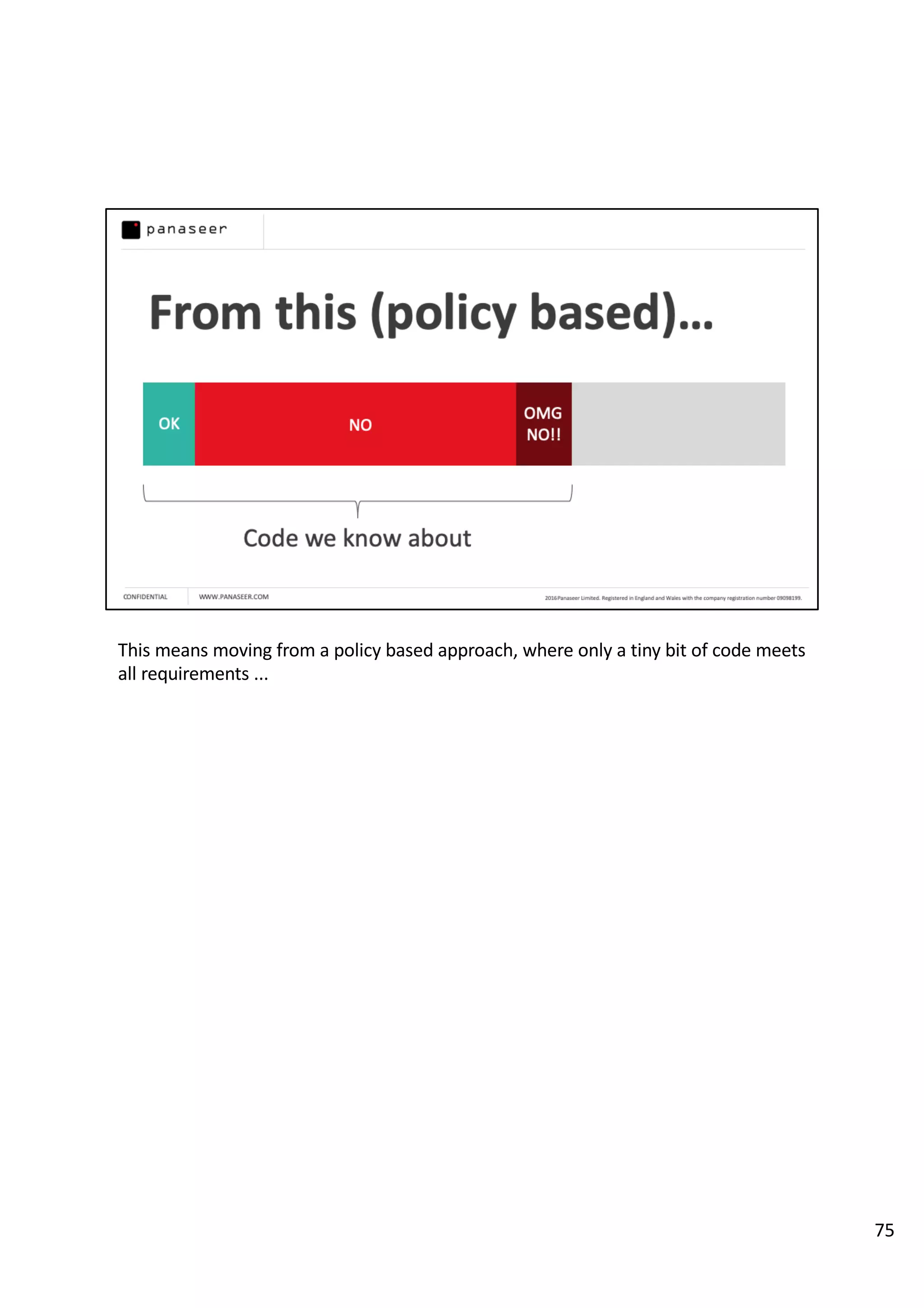
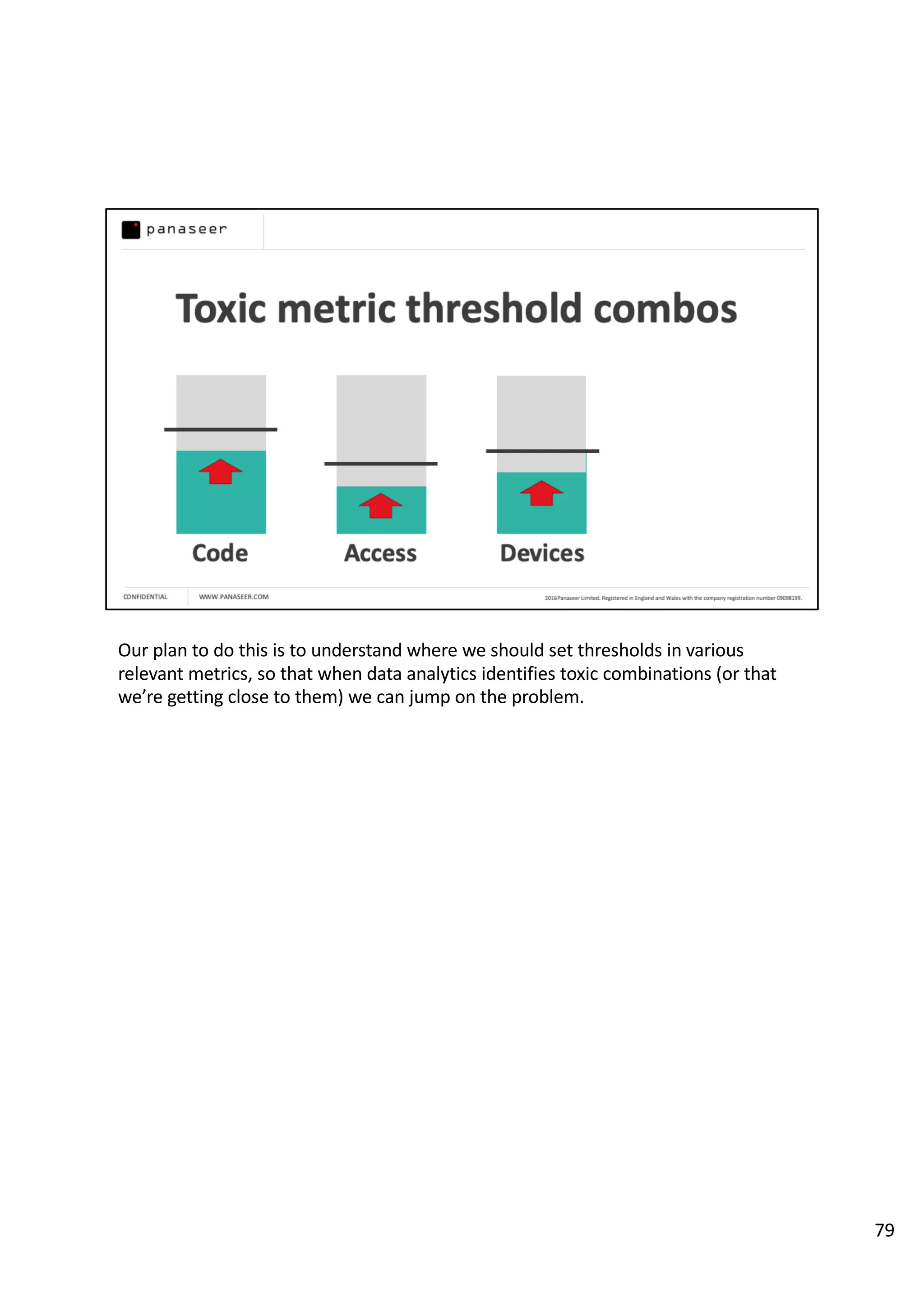
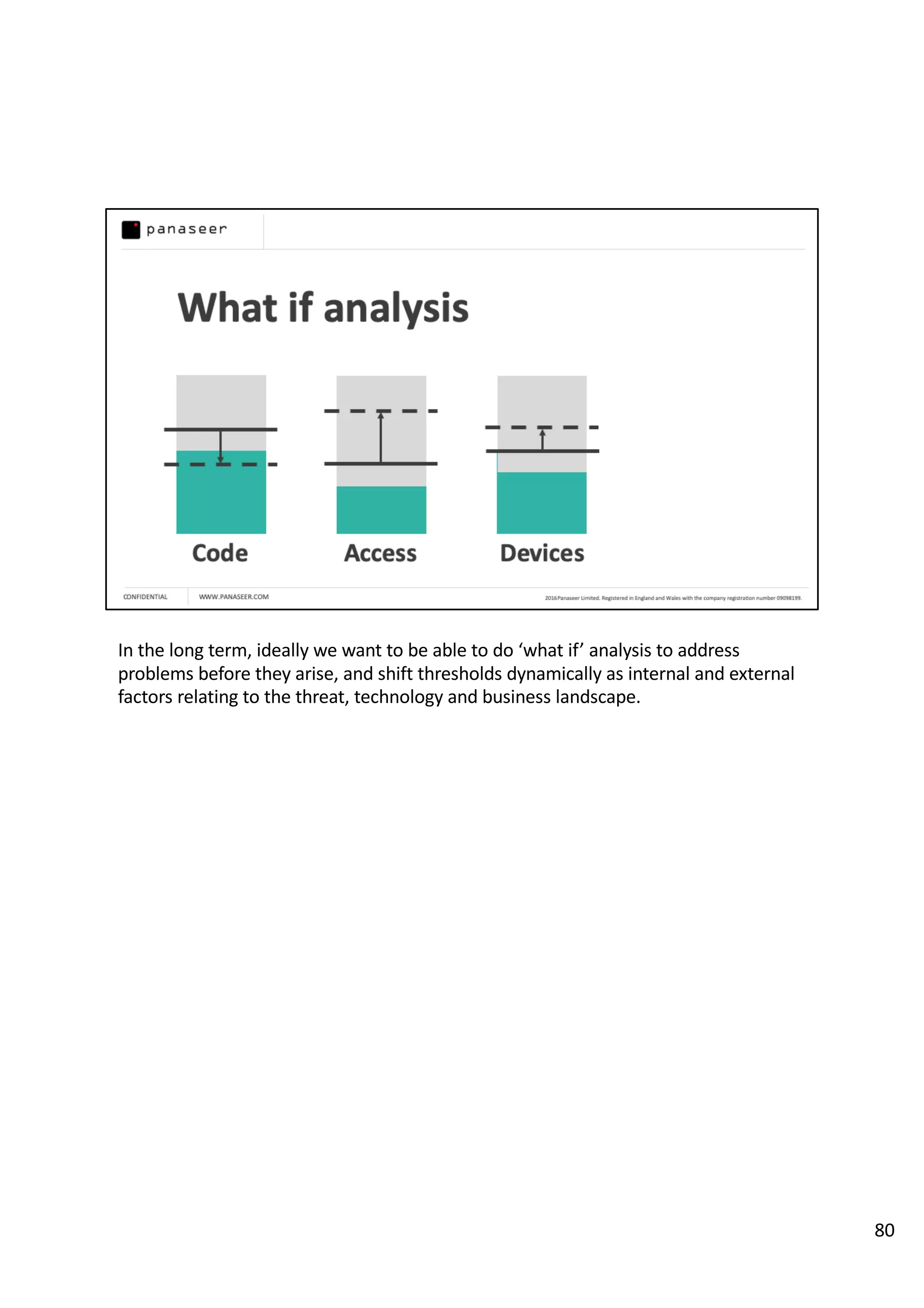
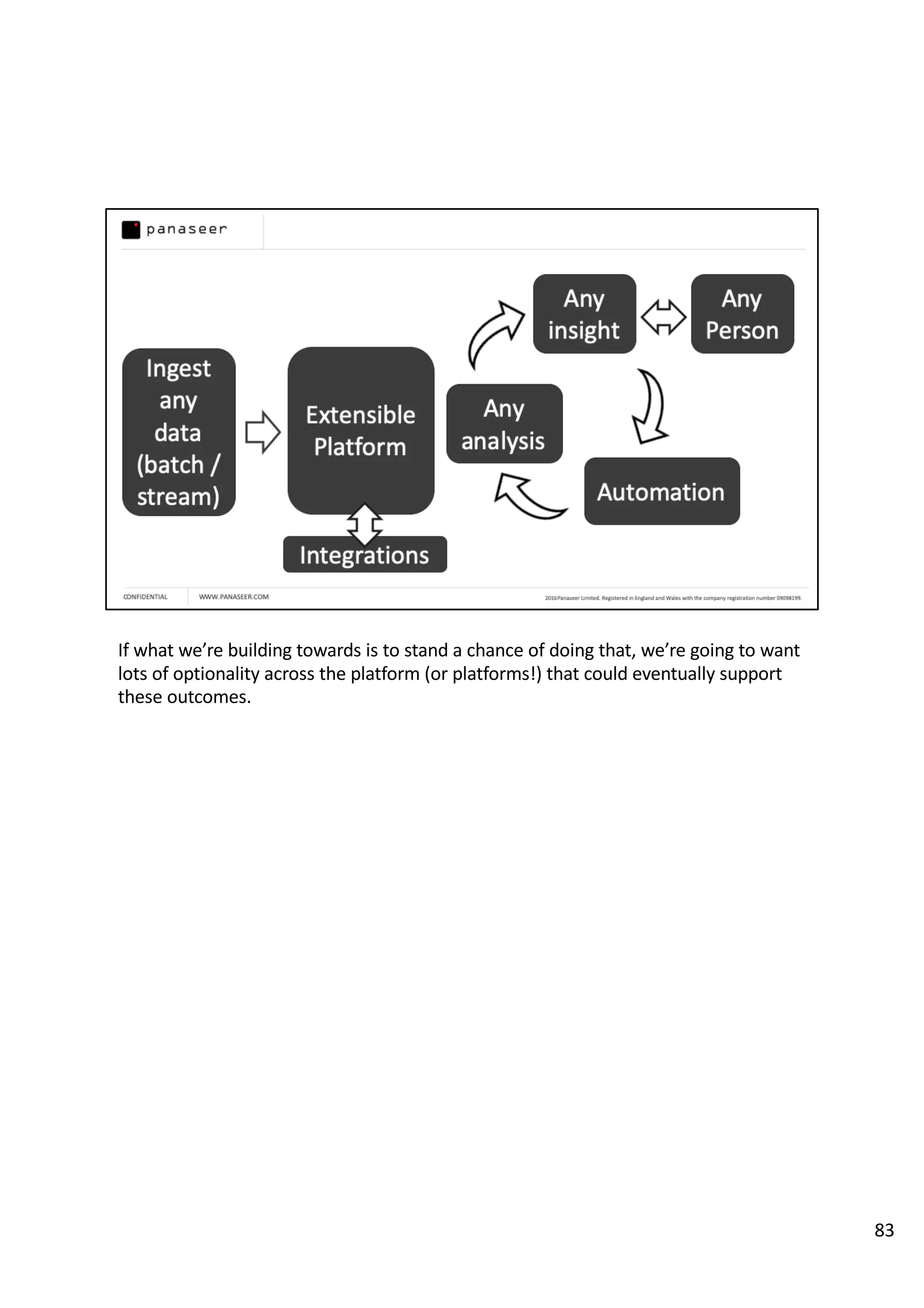
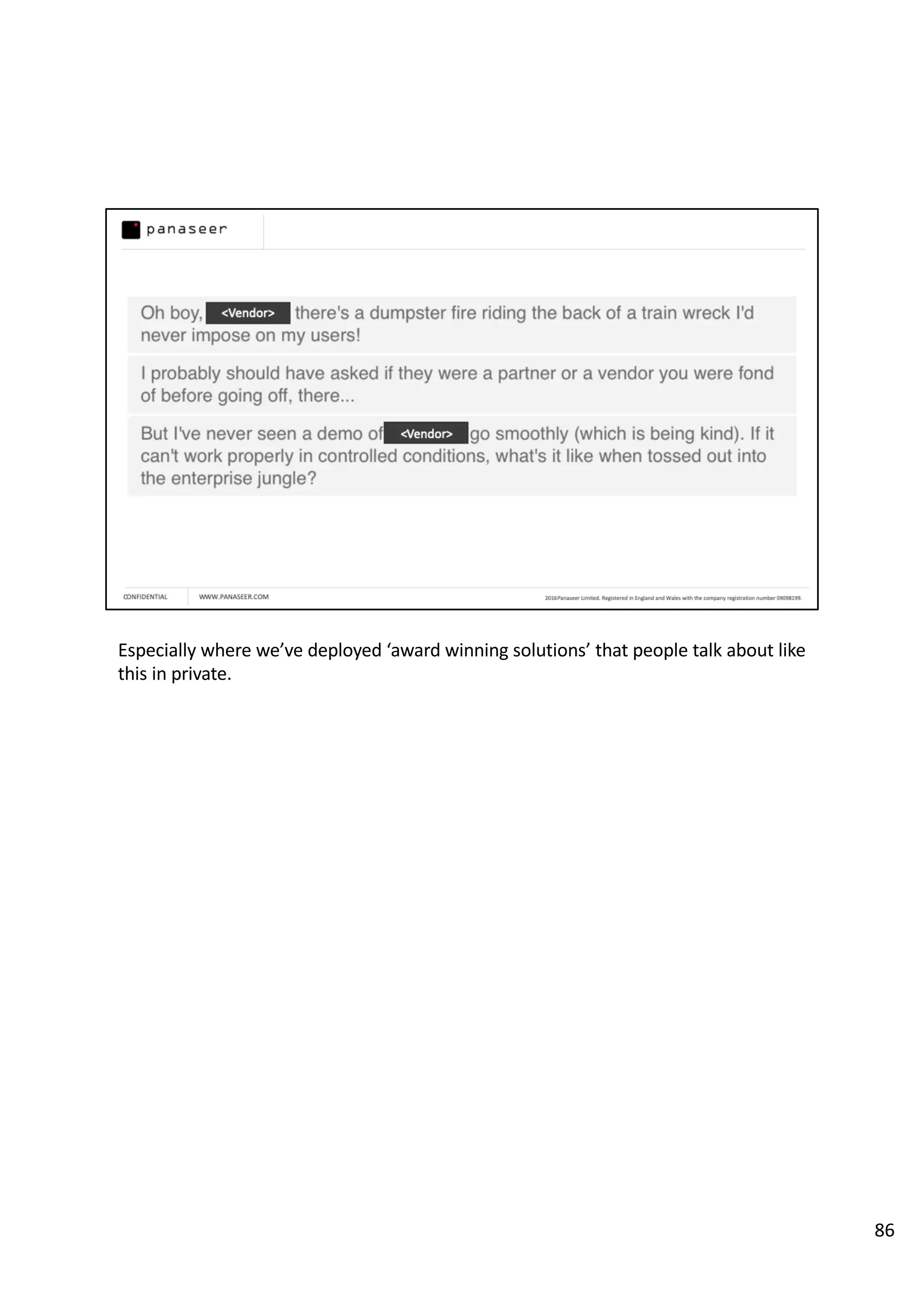
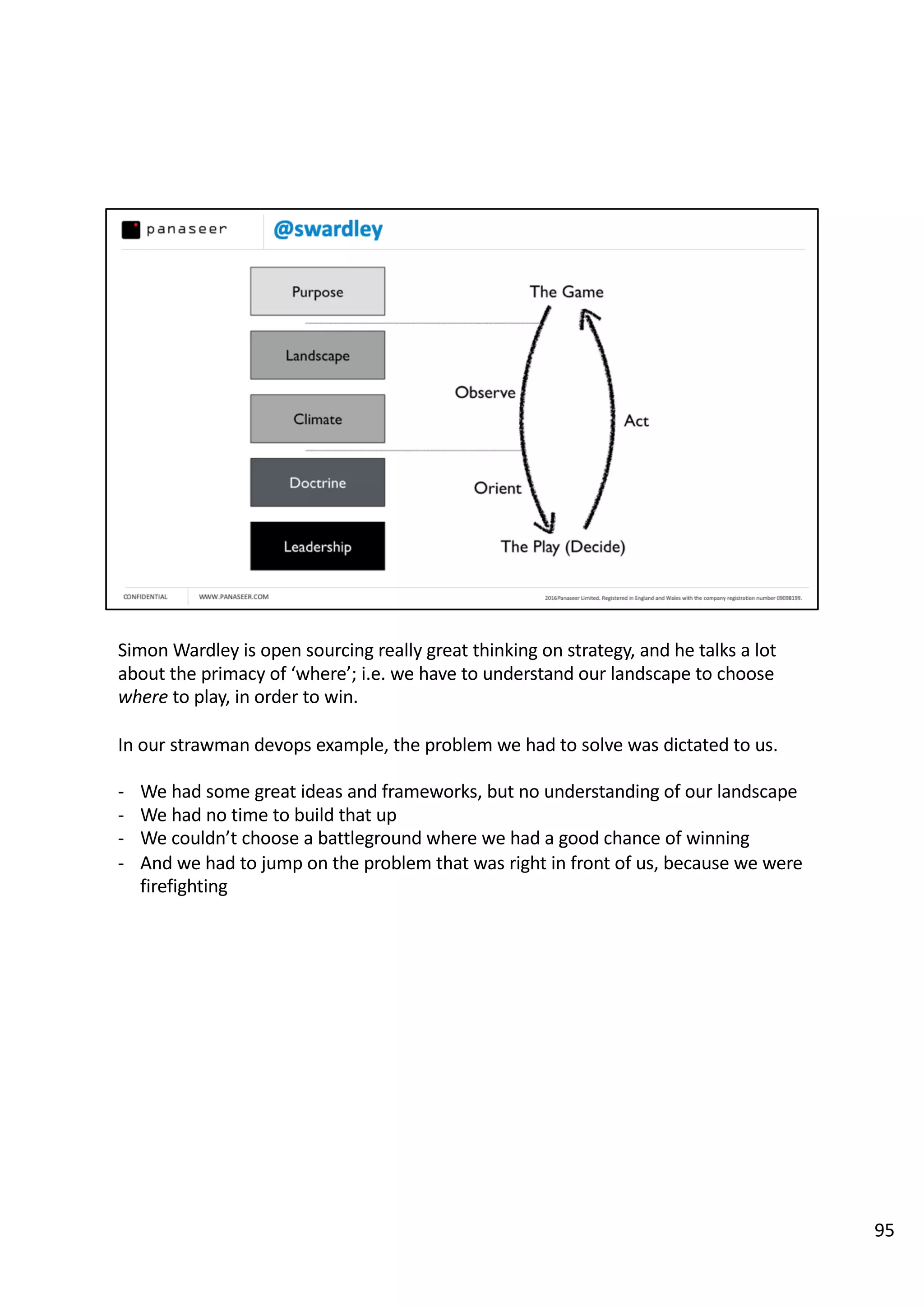
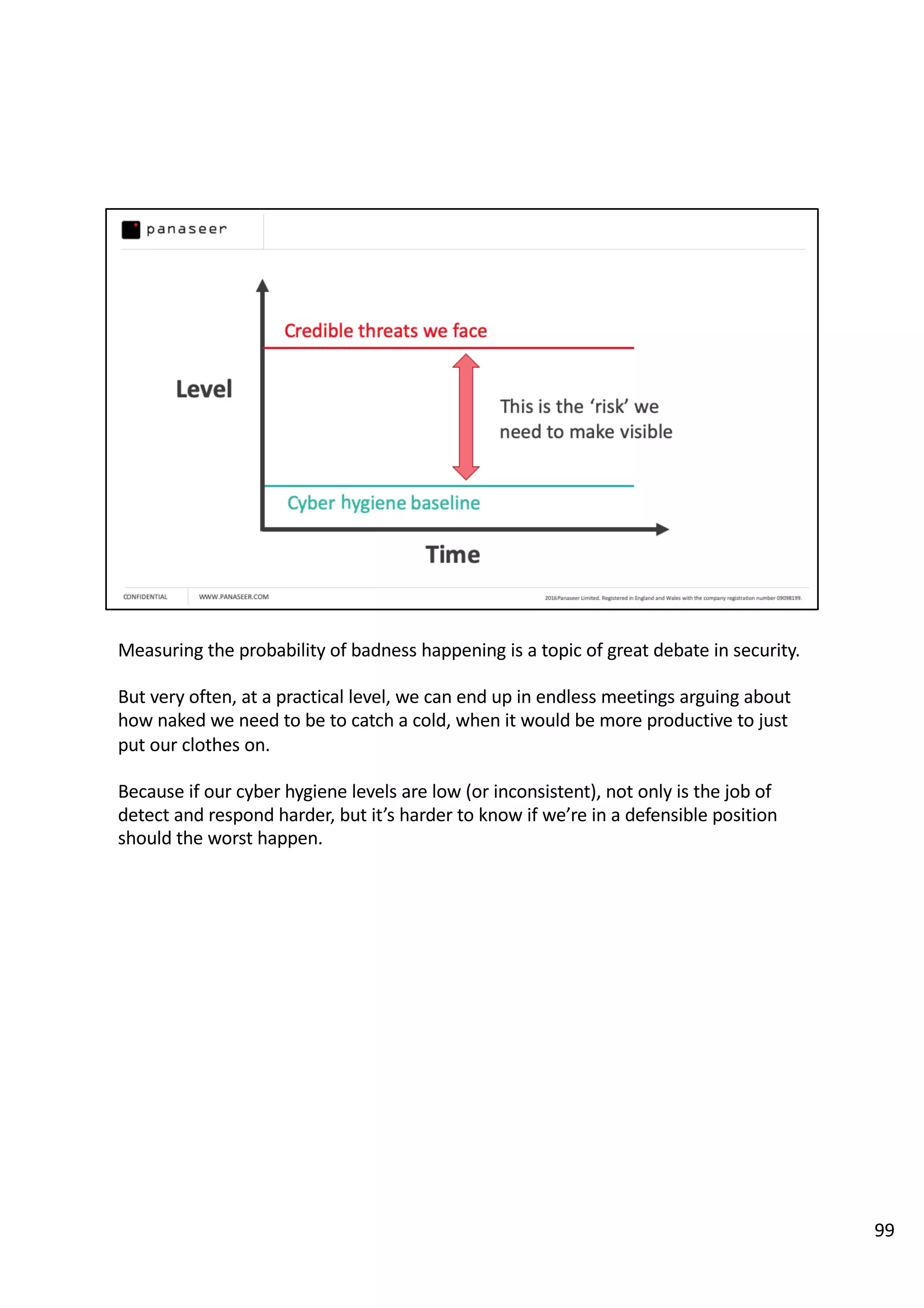
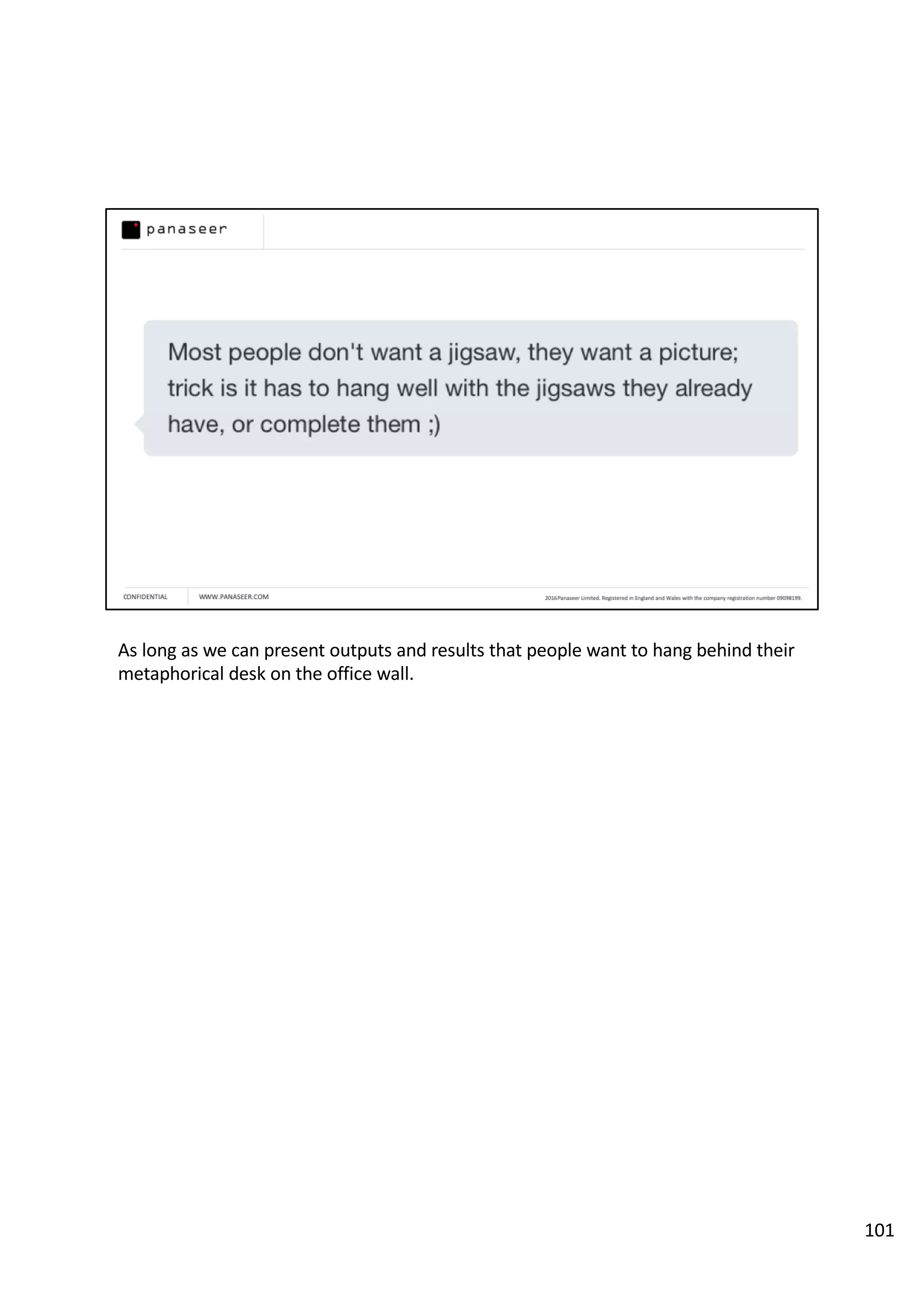
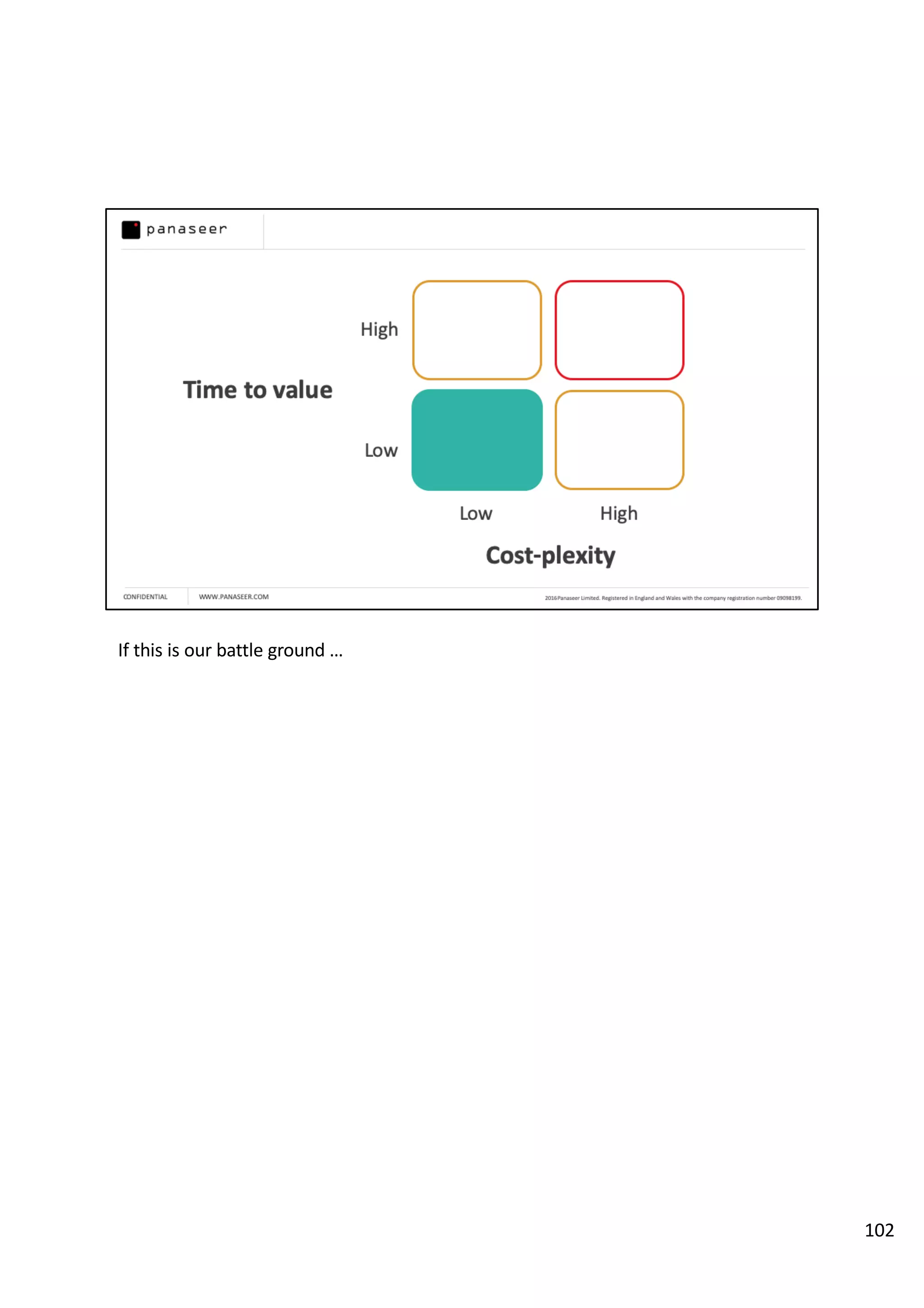
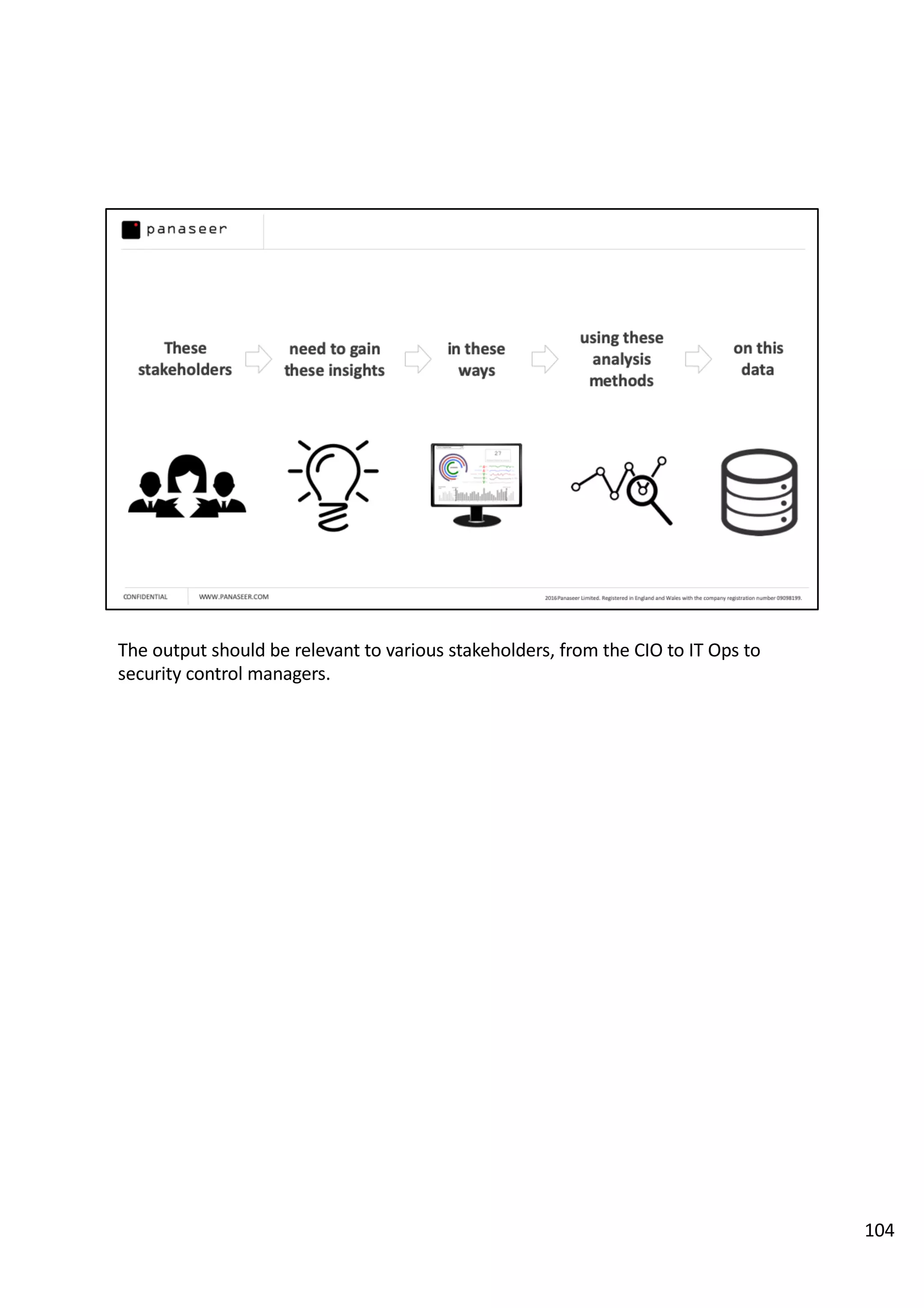
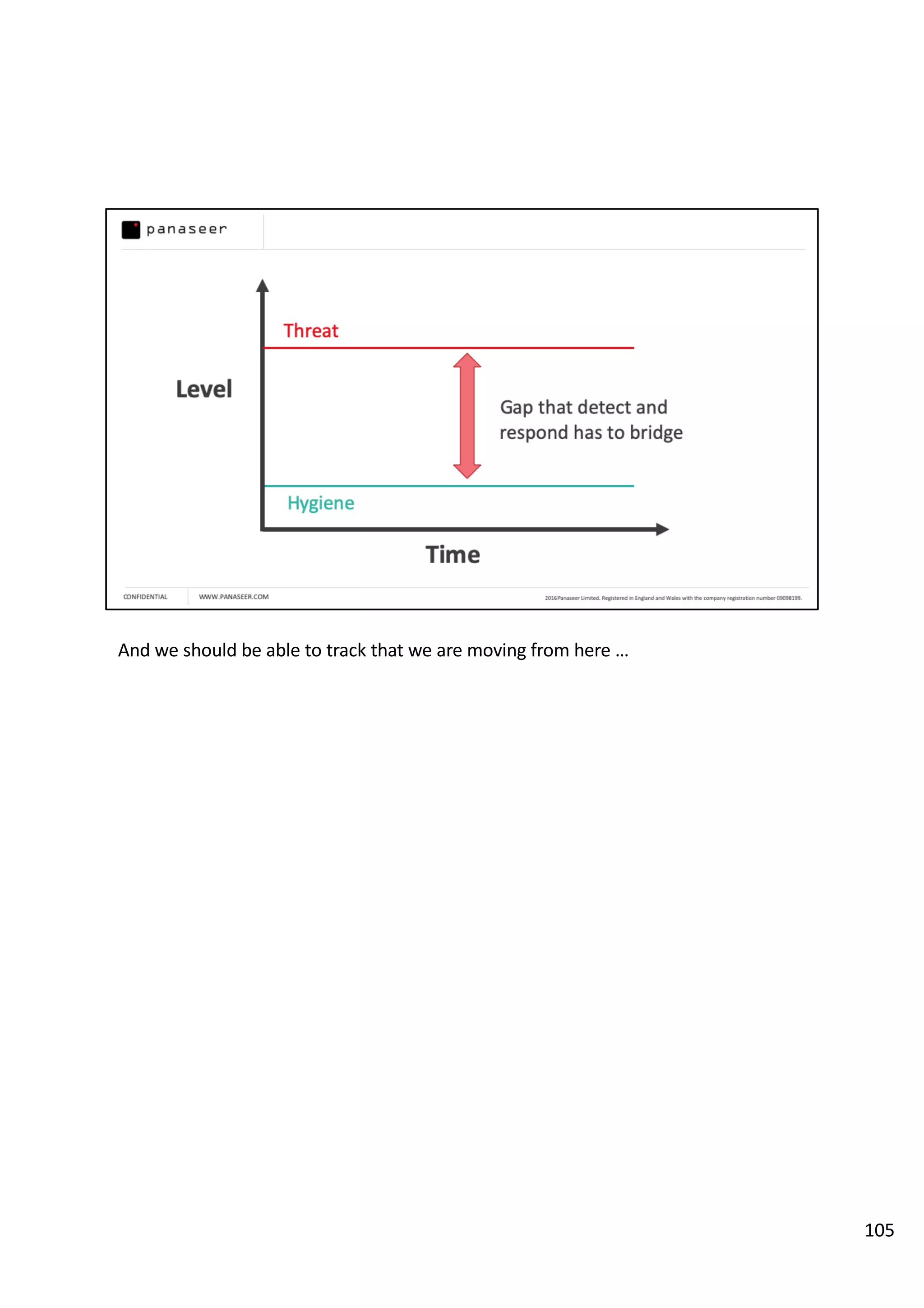
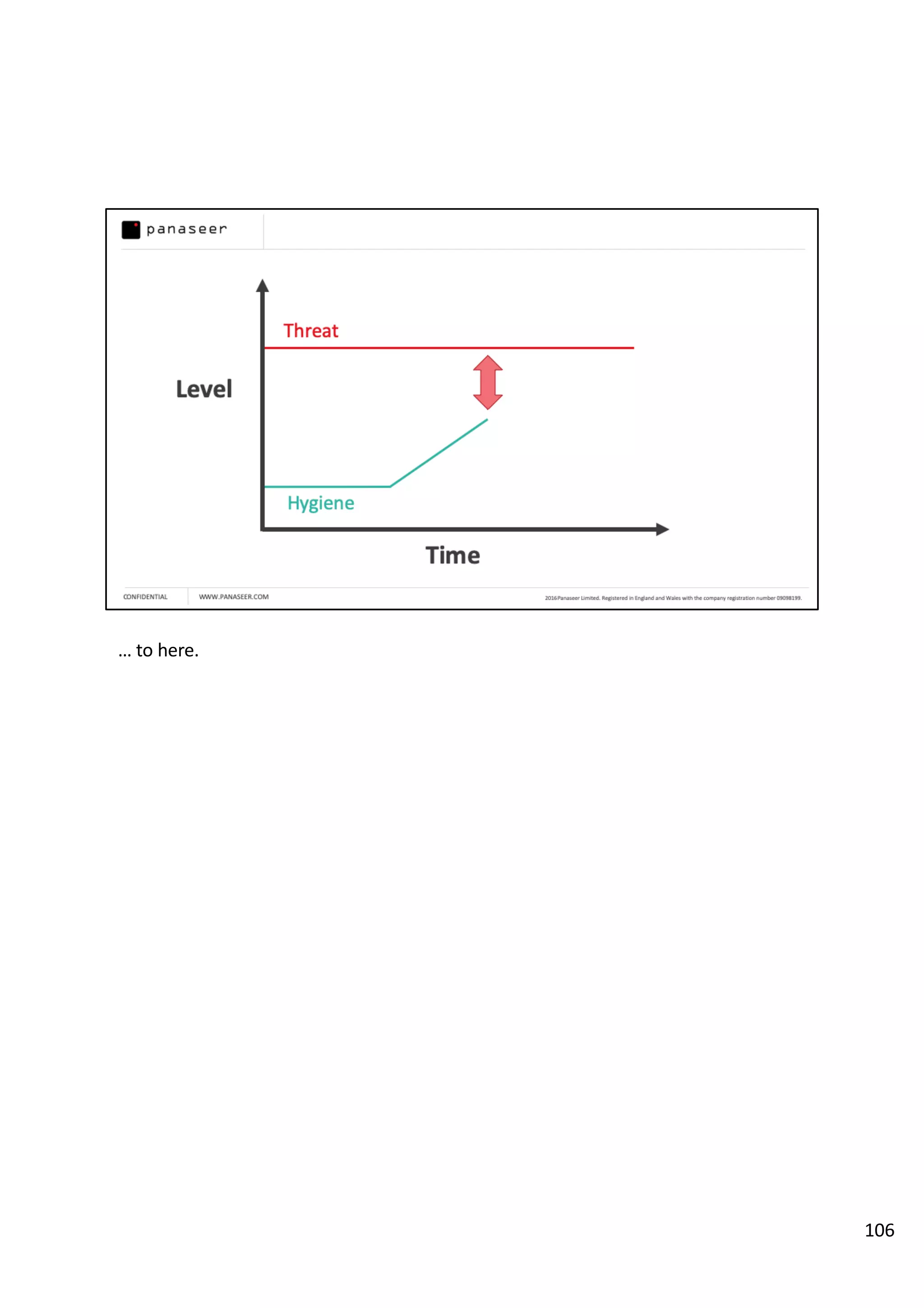
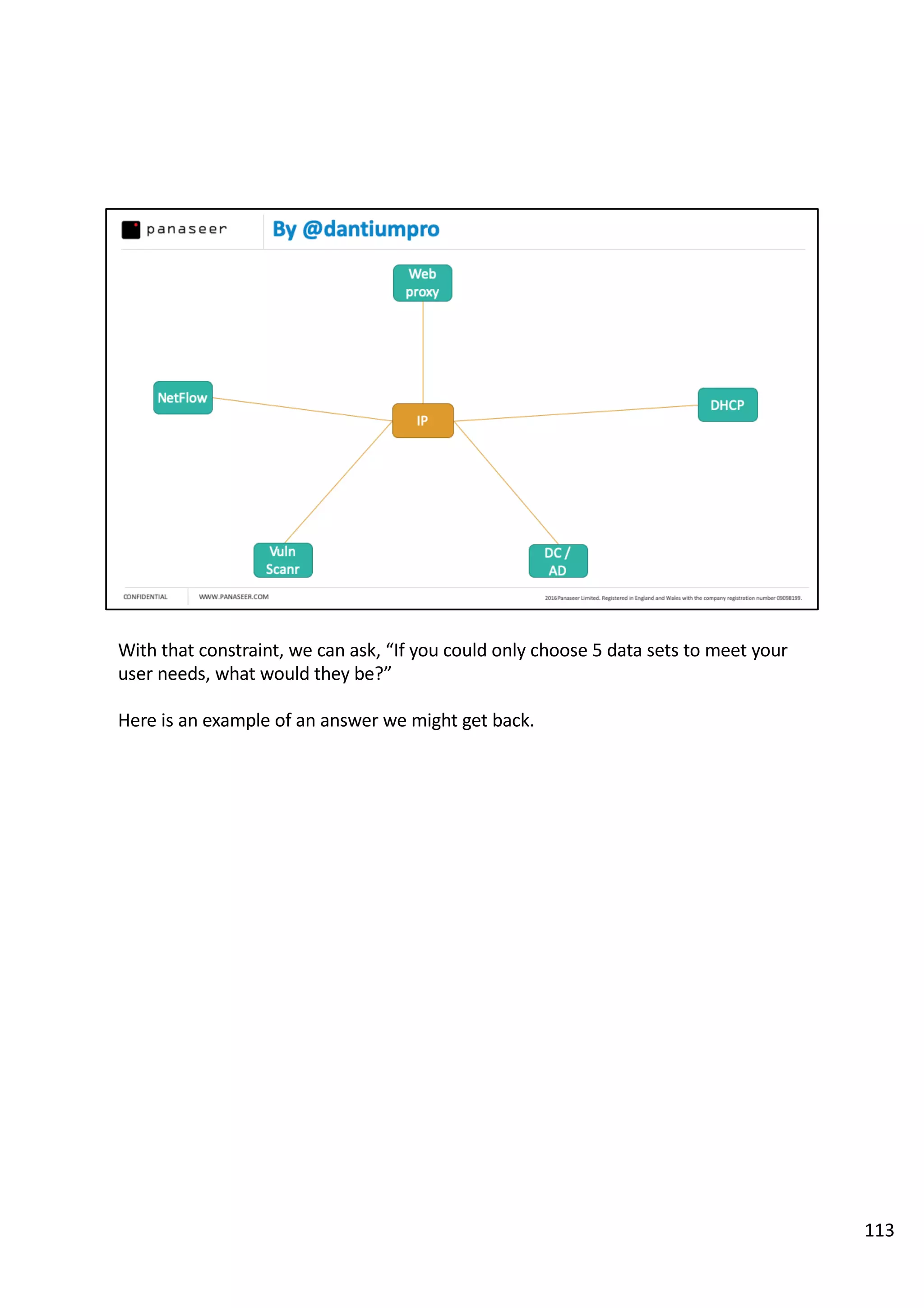
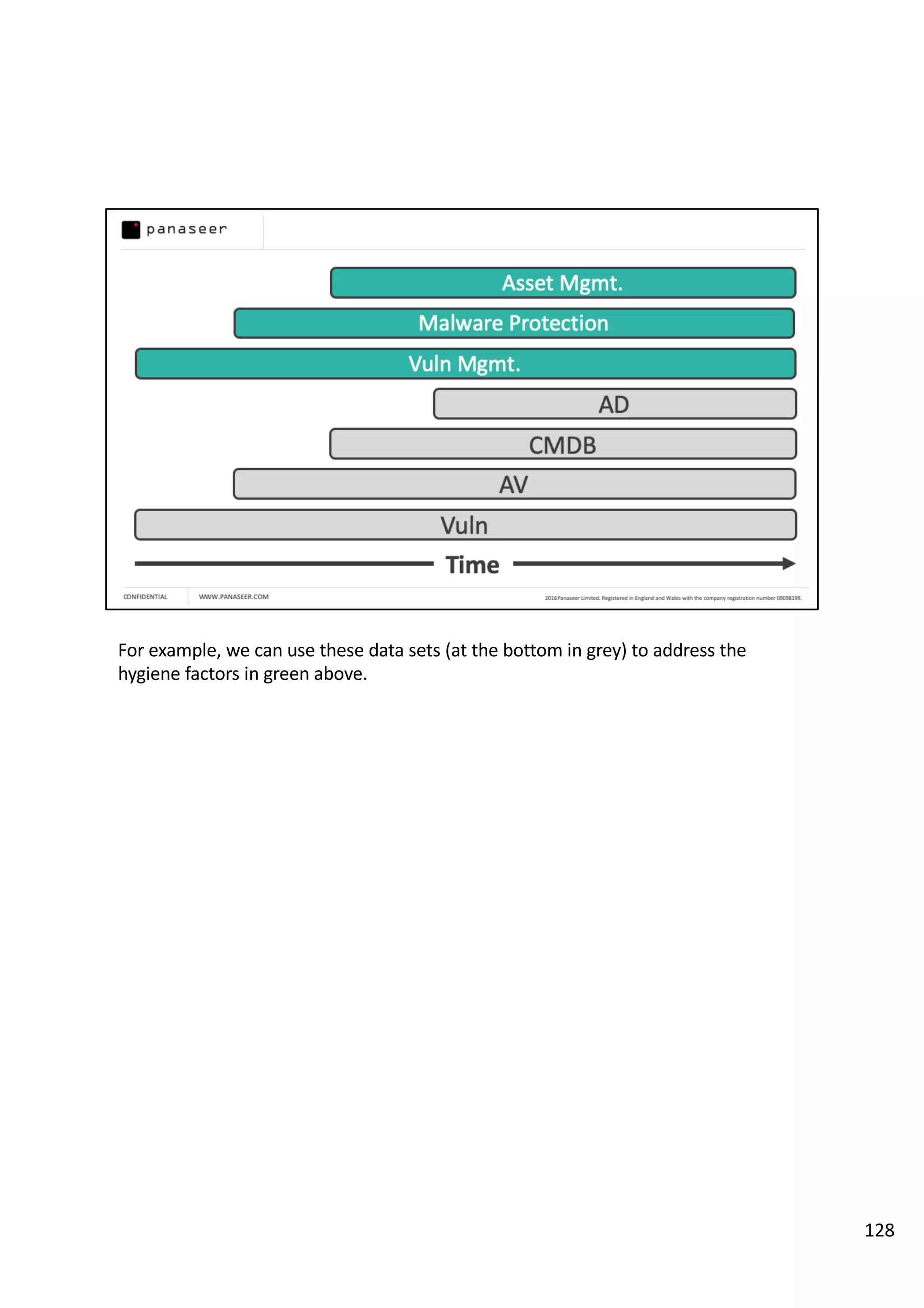
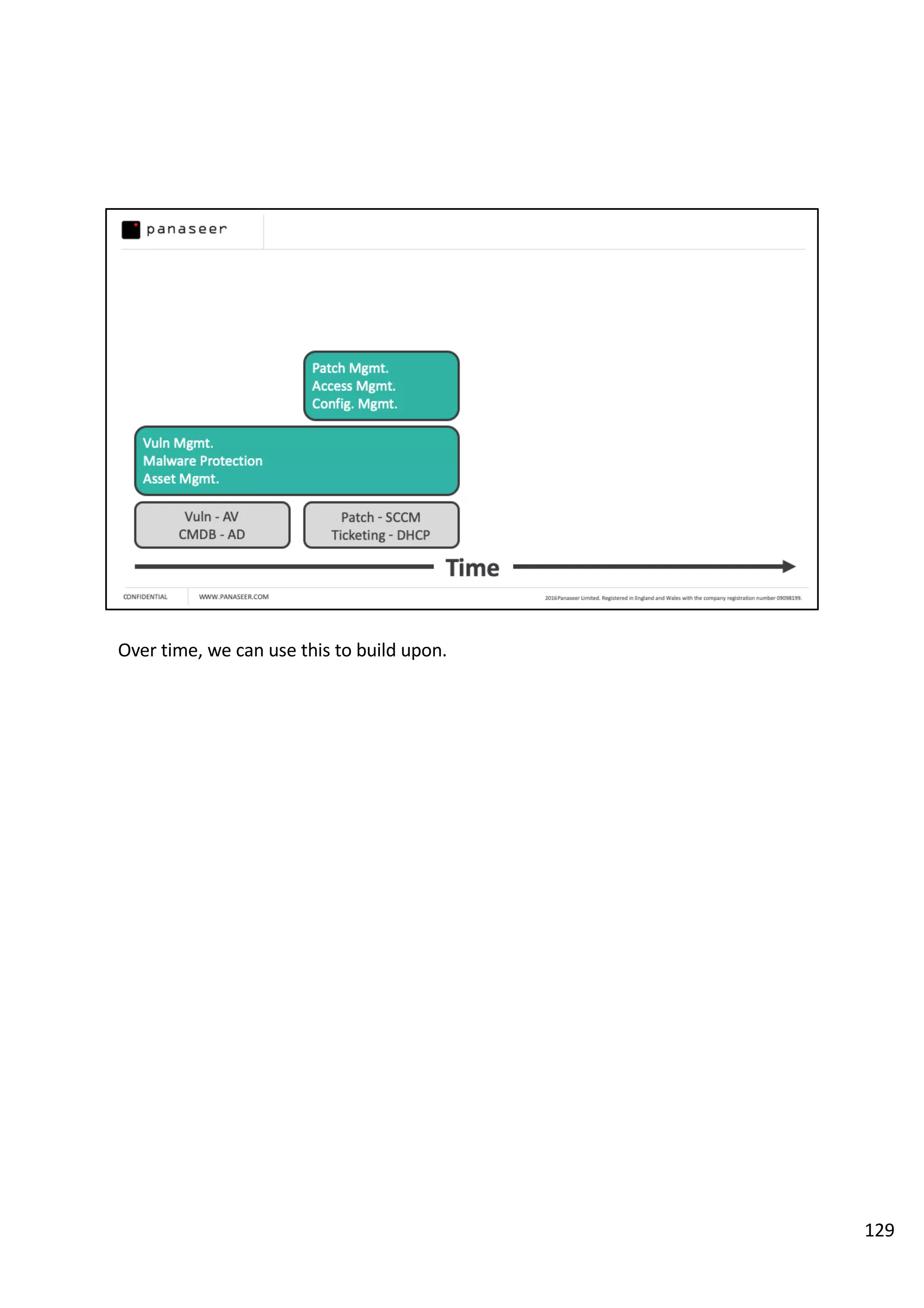
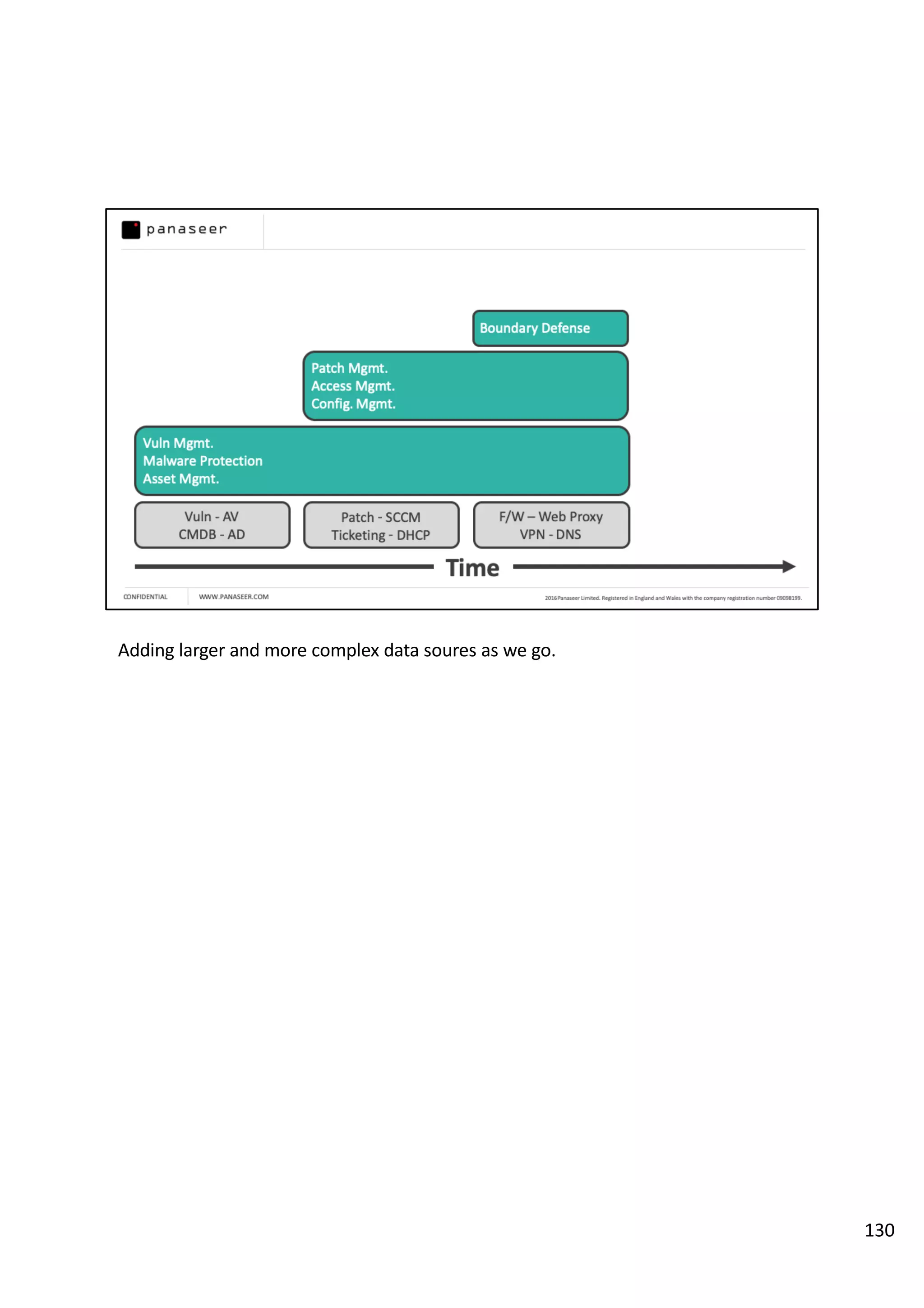
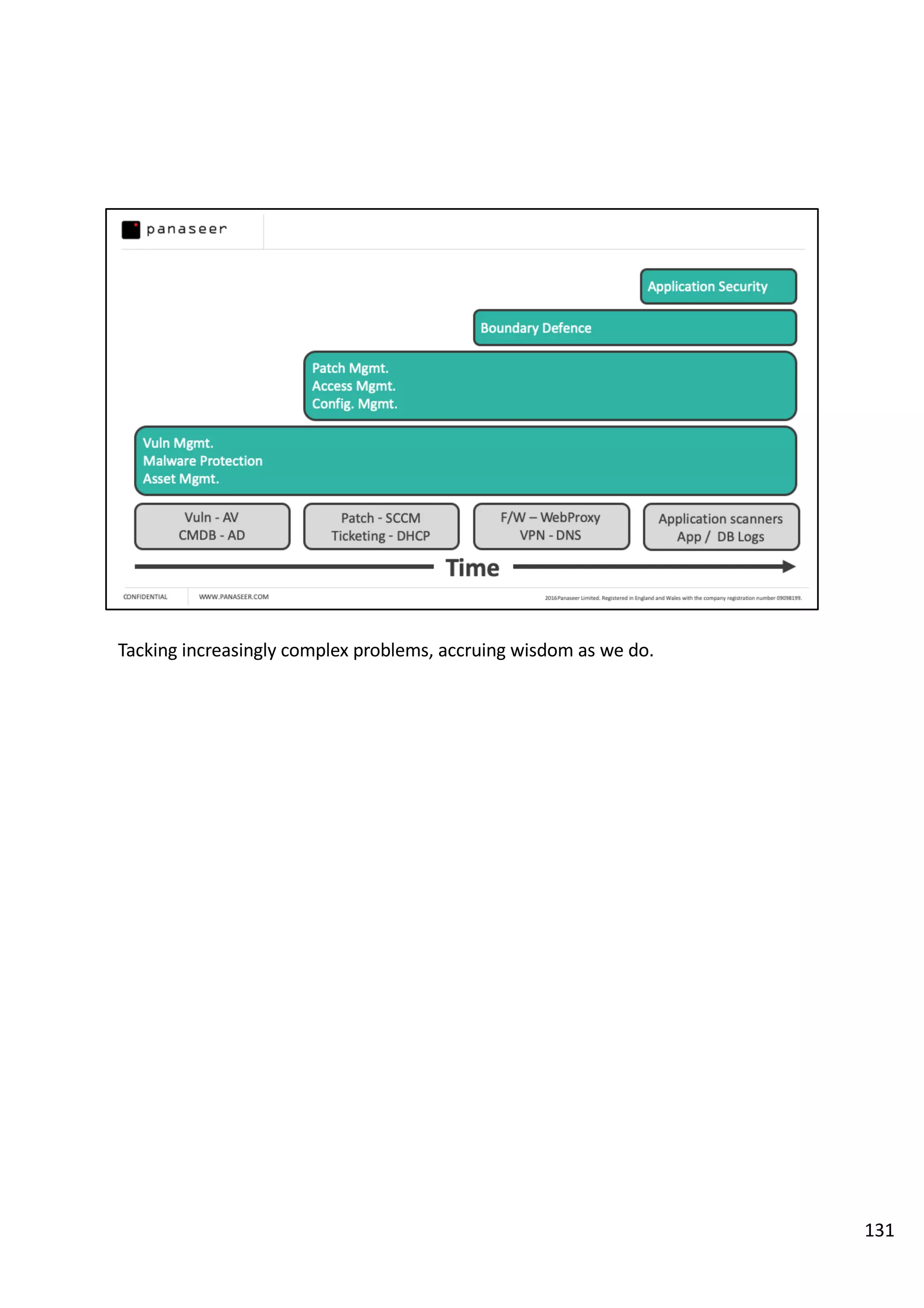
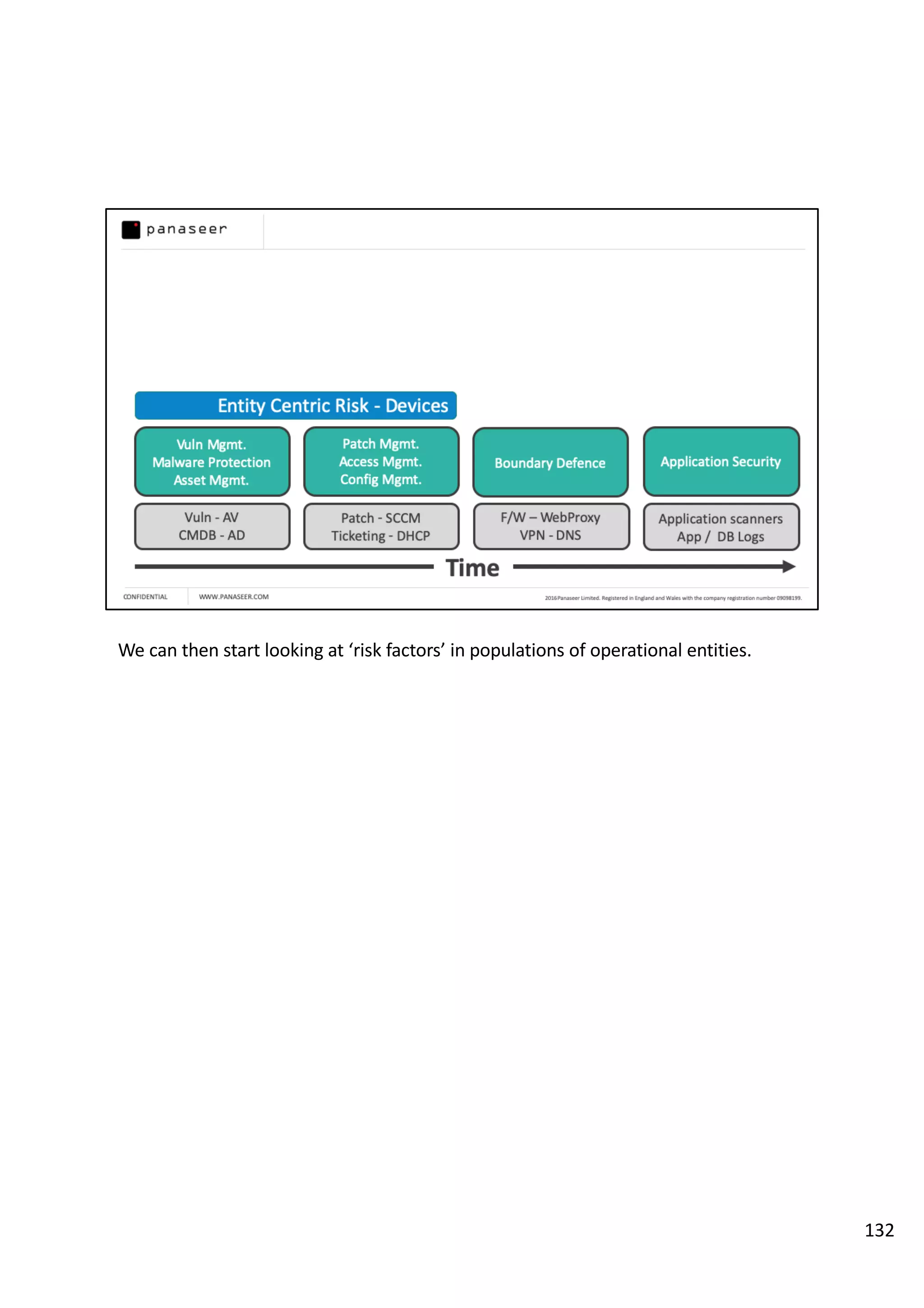
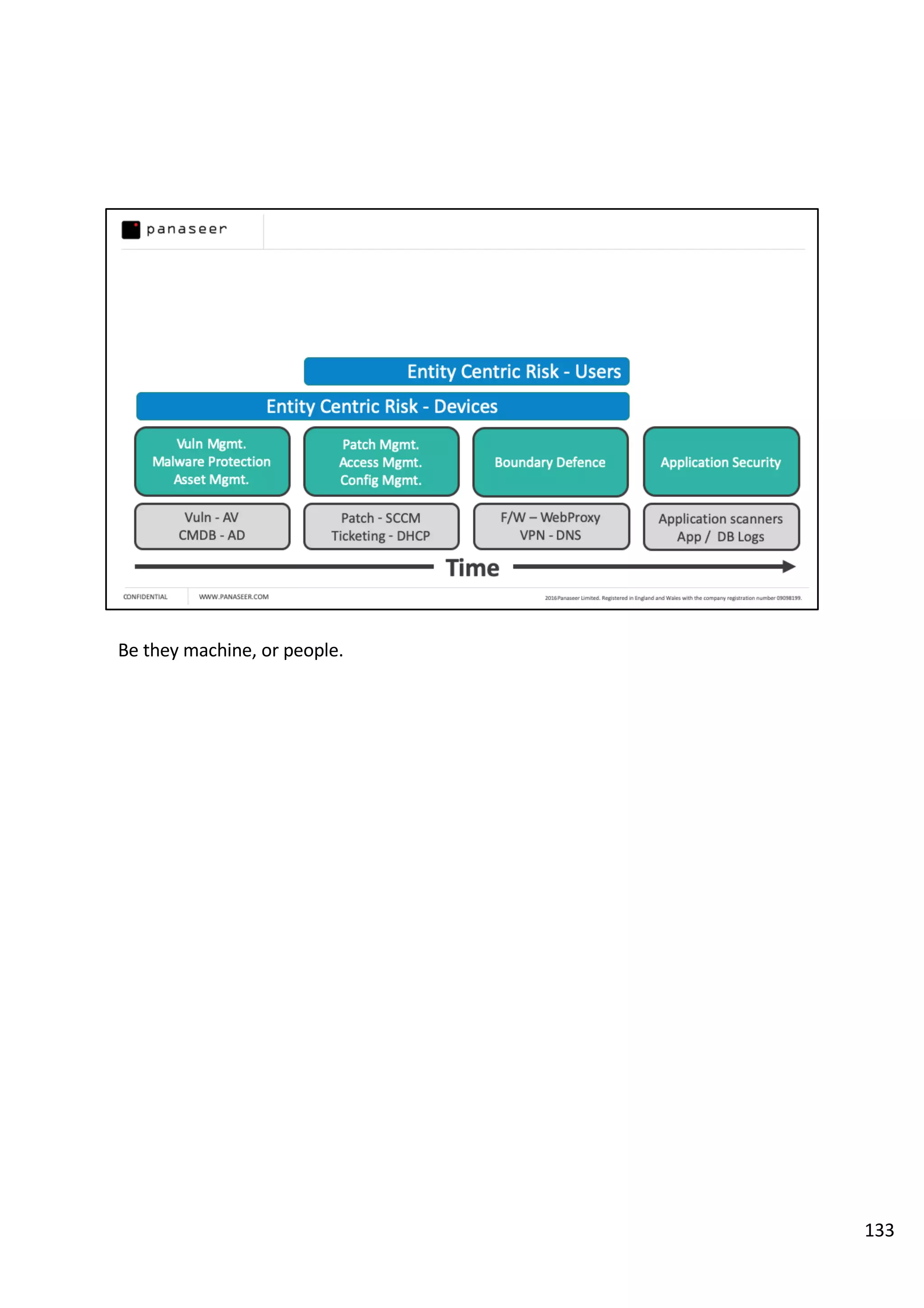
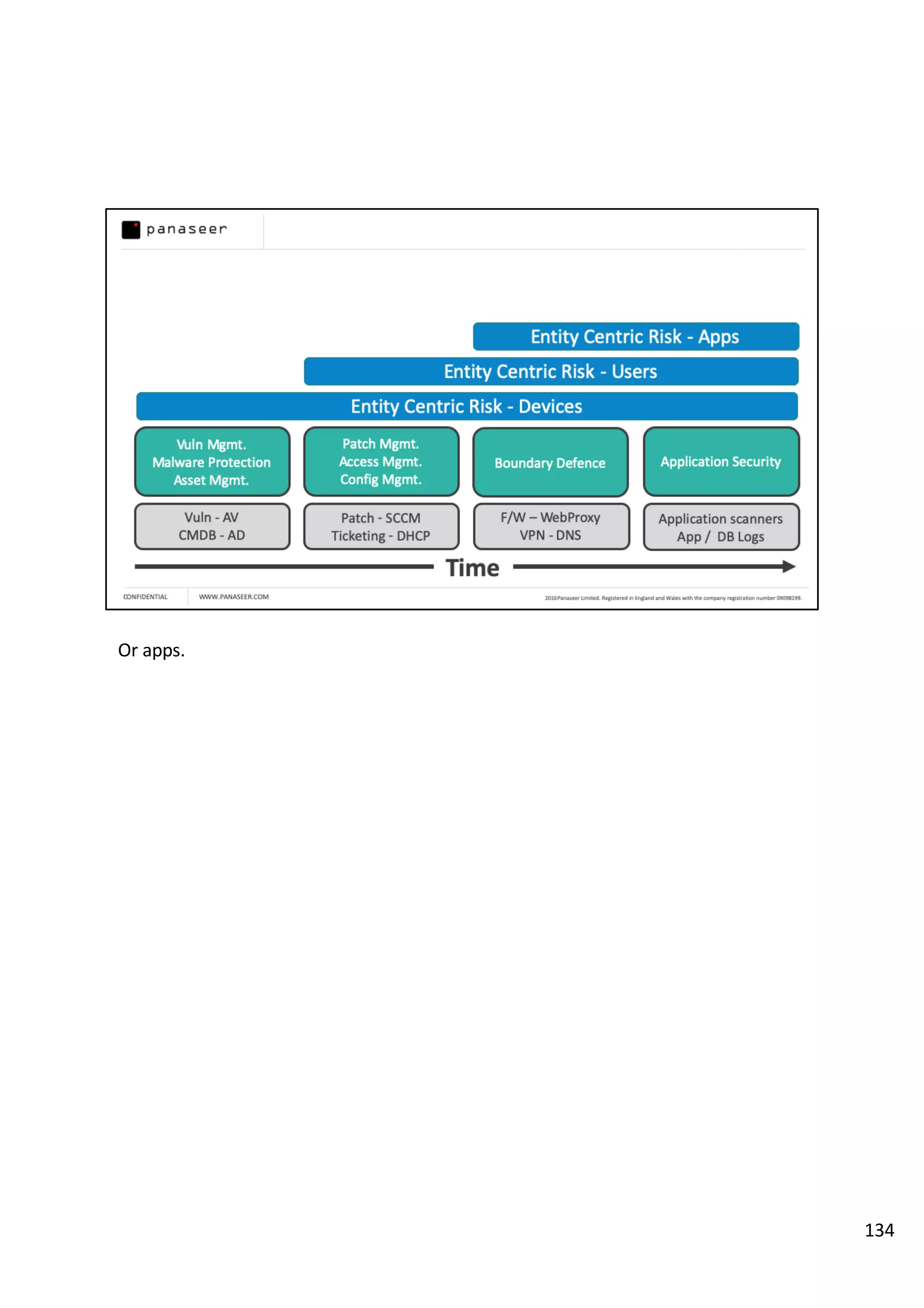
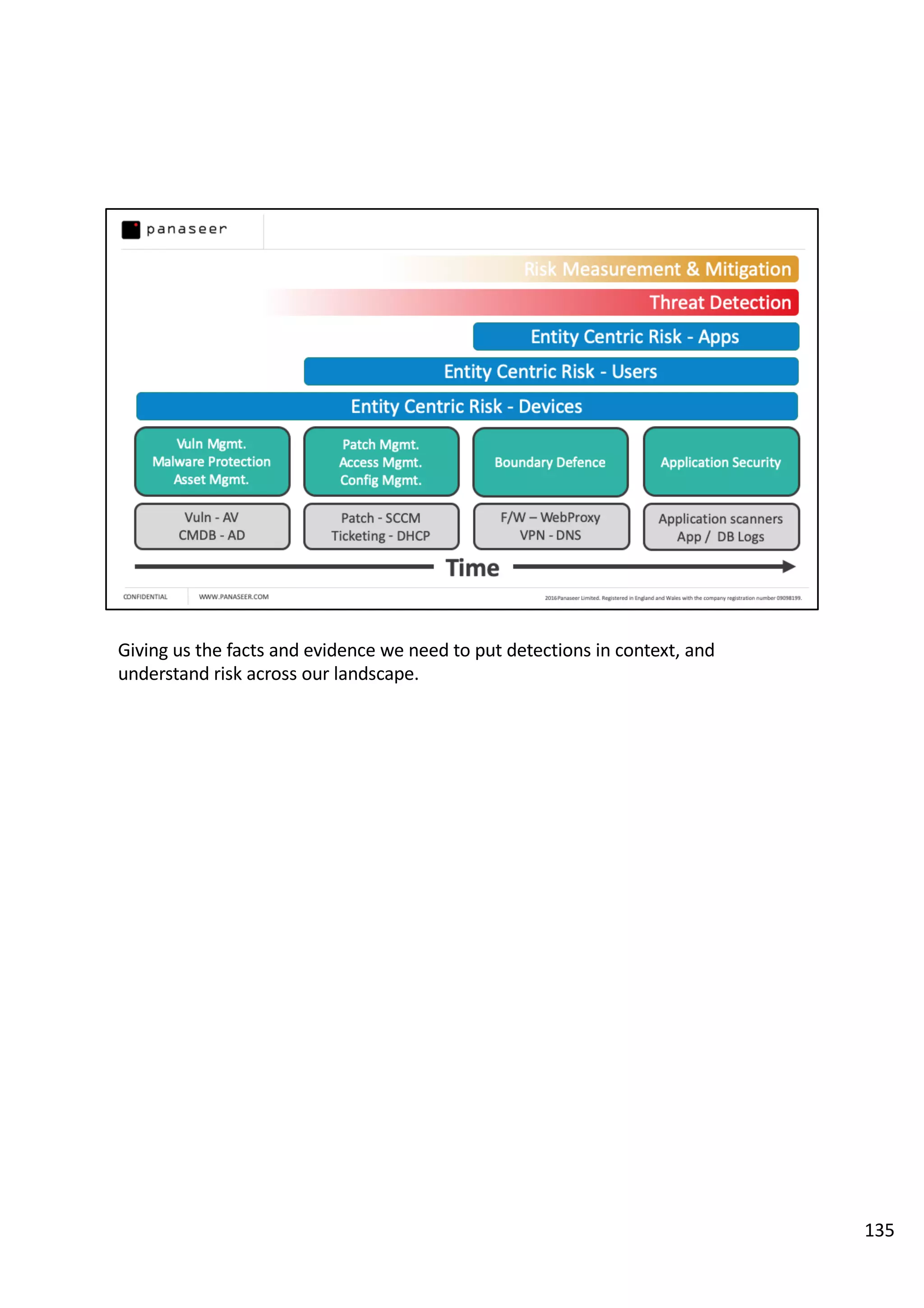
The document discusses the complexities and challenges of implementing data analytics in security environments, focusing on the need for a strategic approach to manage risks effectively. It highlights the importance of understanding data architecture, prioritizing relevant insights, and avoiding common pitfalls like 'death star projects' and 'artisanal data analytics.' To achieve better results, it emphasizes addressing problem sets systematically, utilizing minimum viable products, and reducing the time from insight delivery to actionable decisions.
































































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








