Download as PDF, PPTX


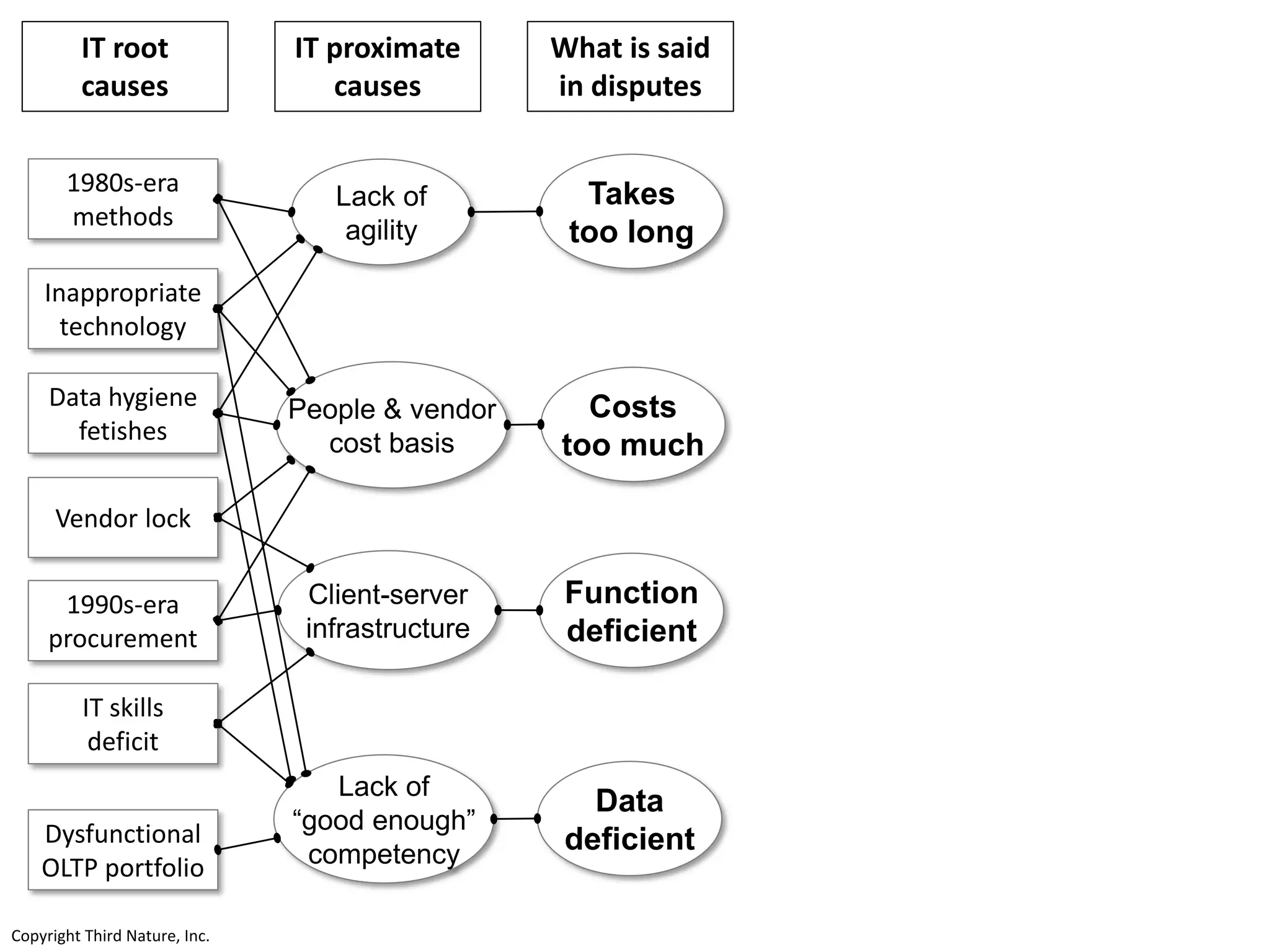
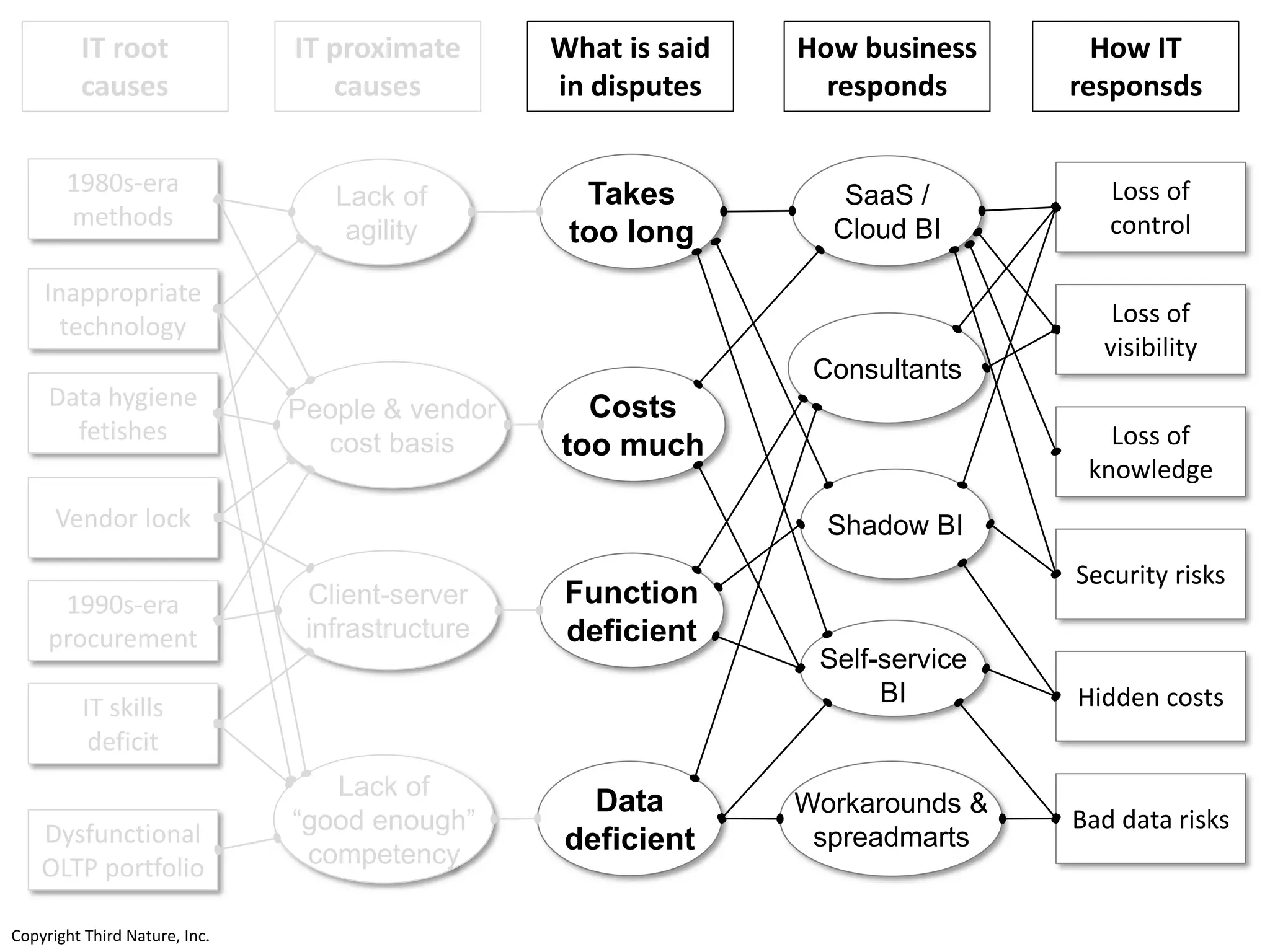
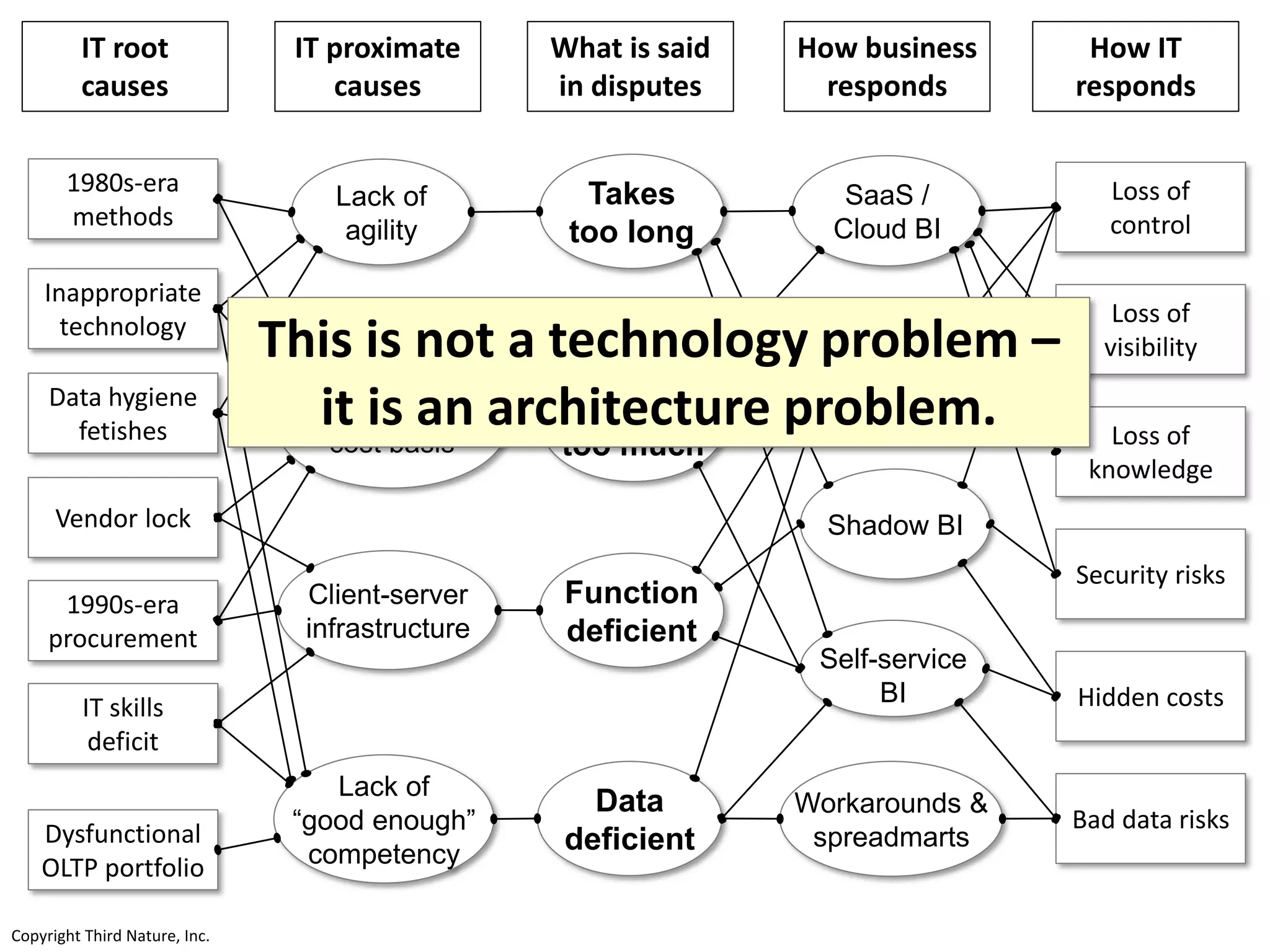








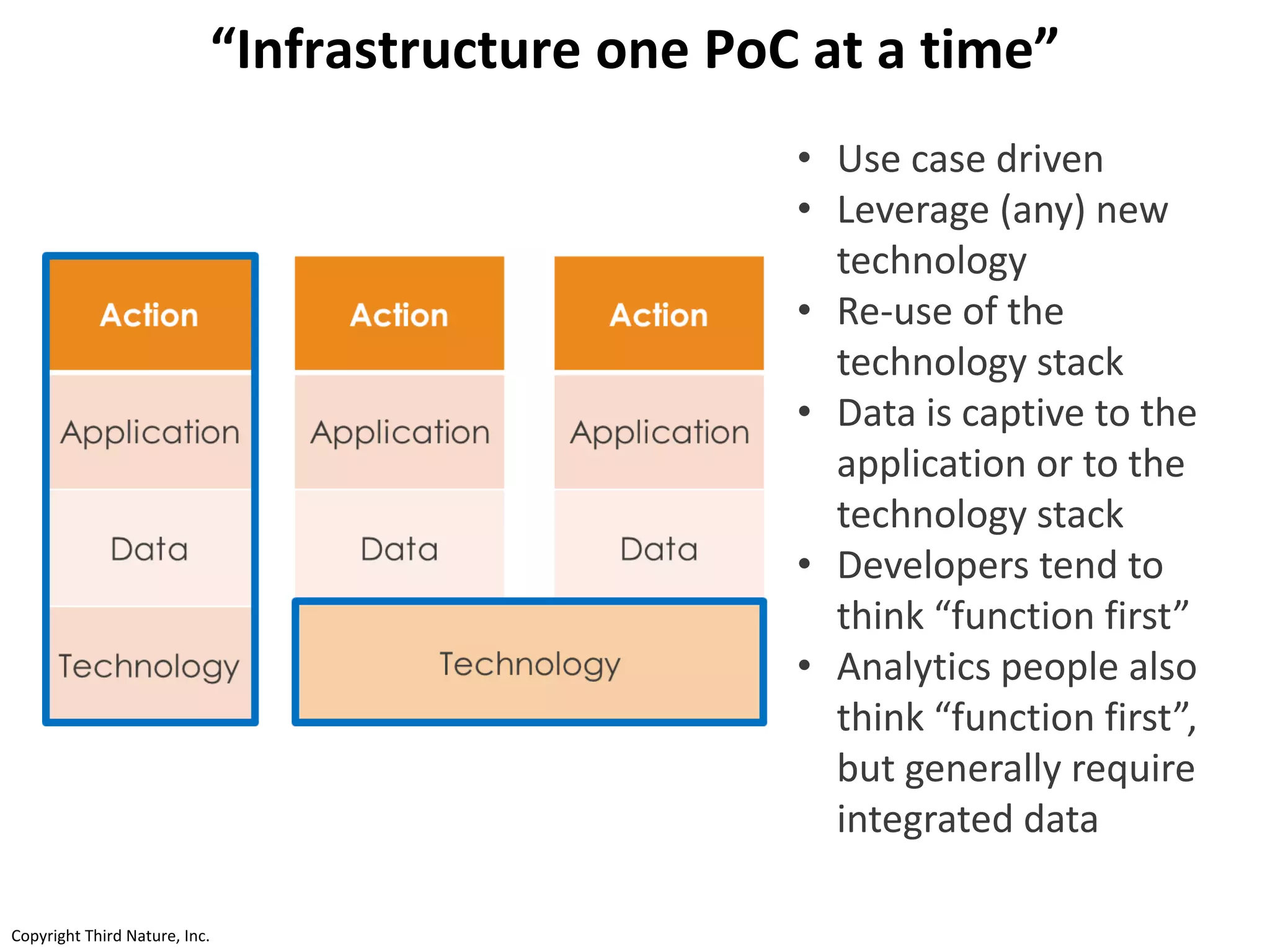
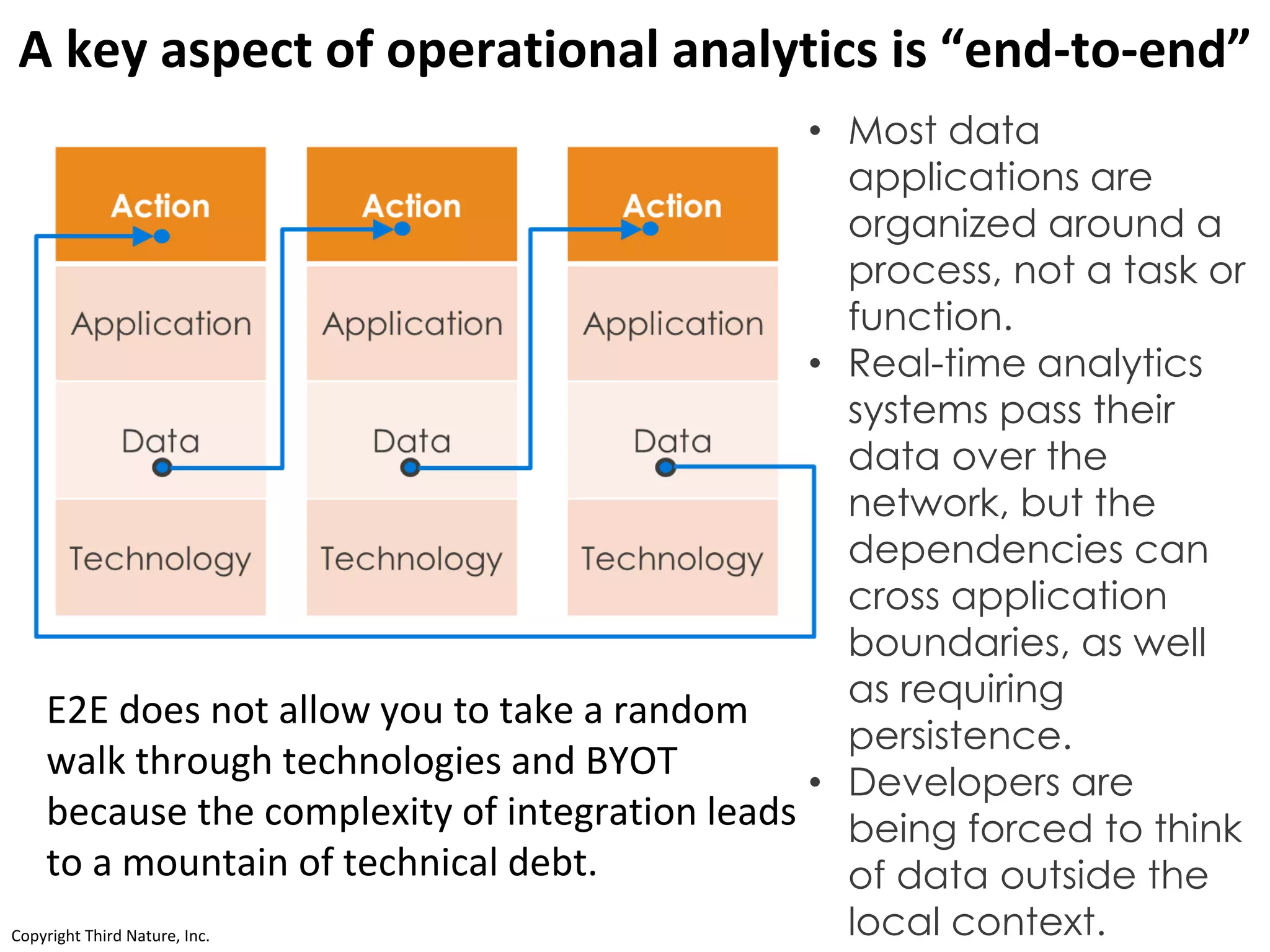







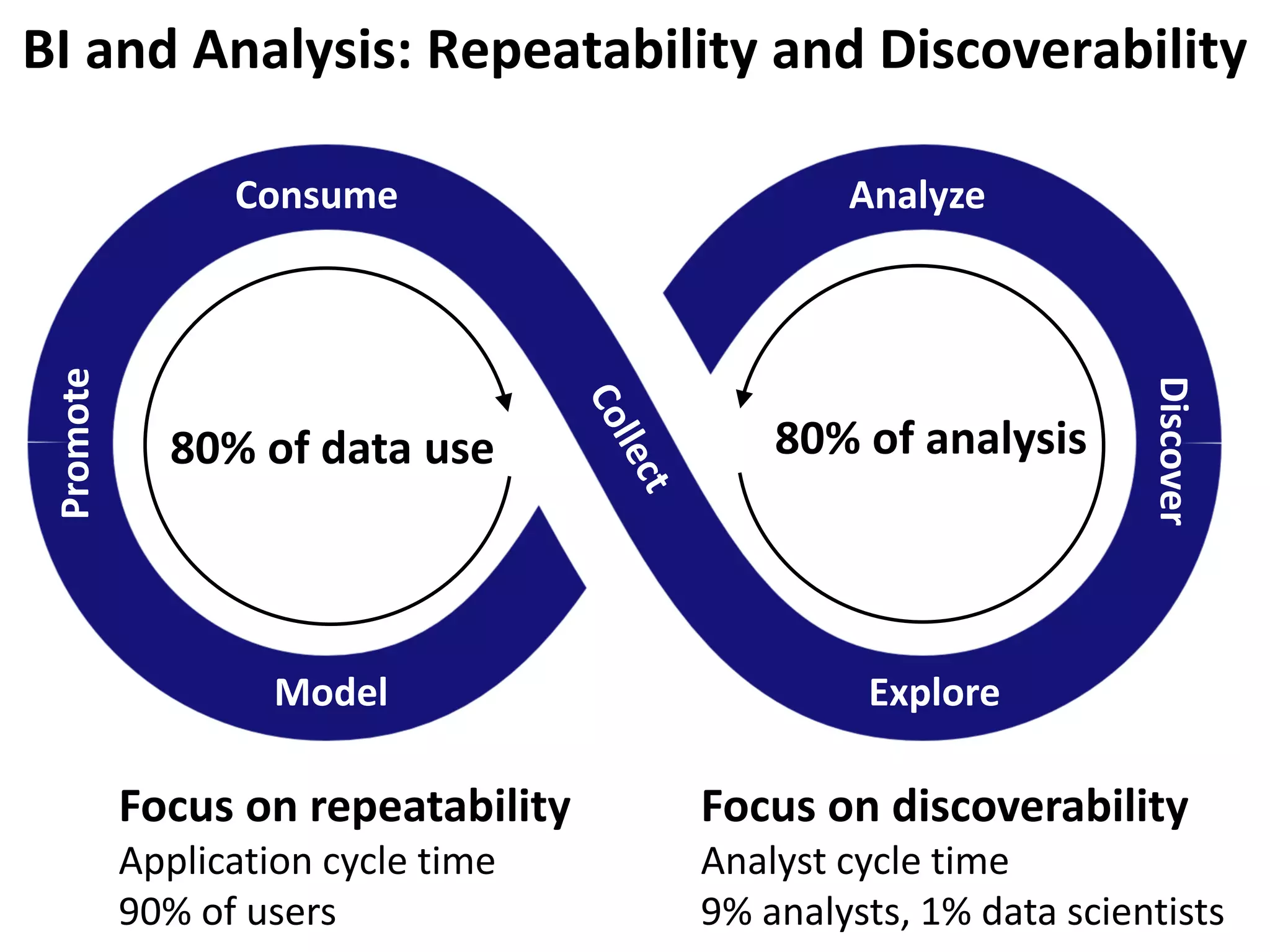




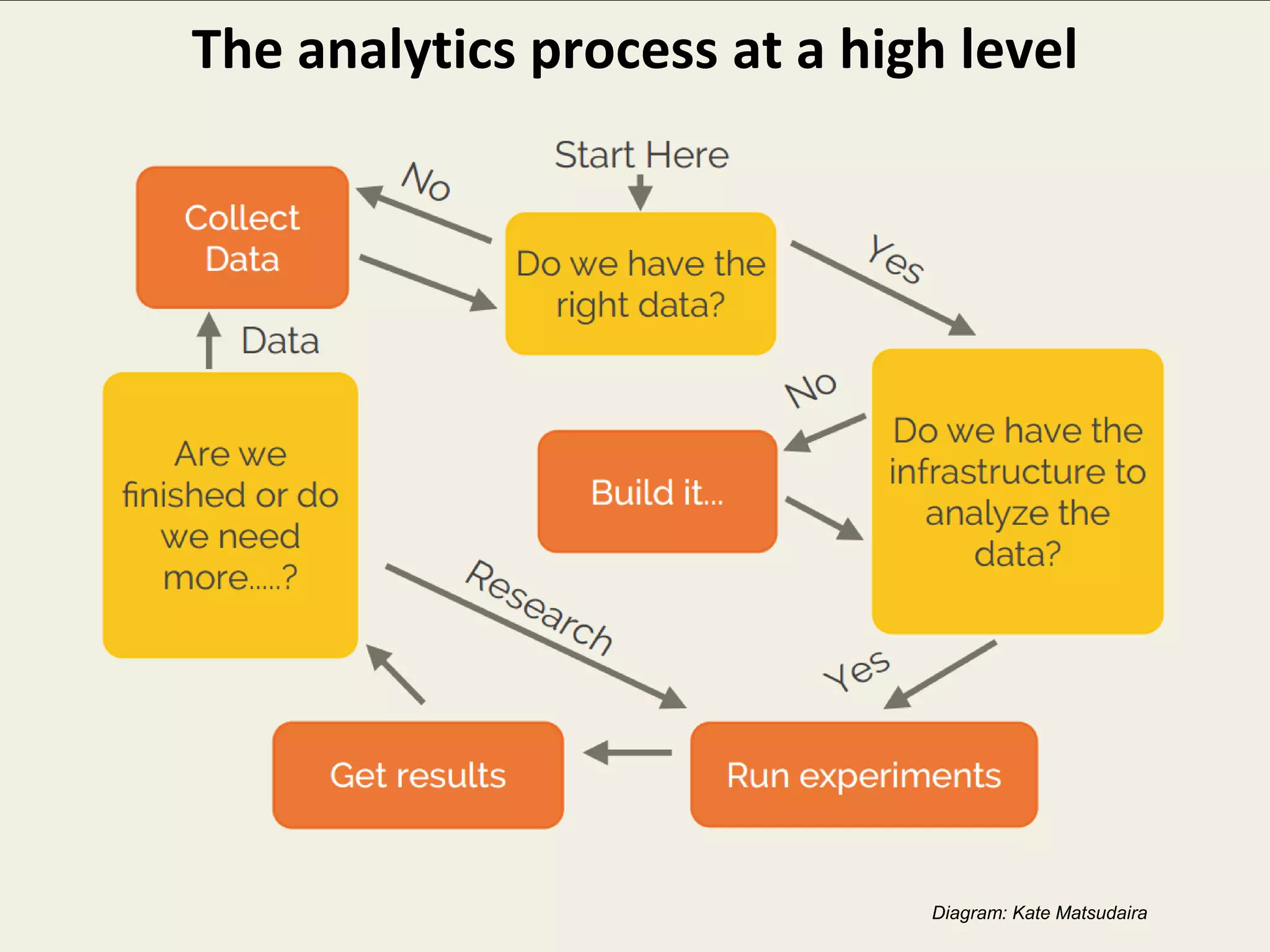
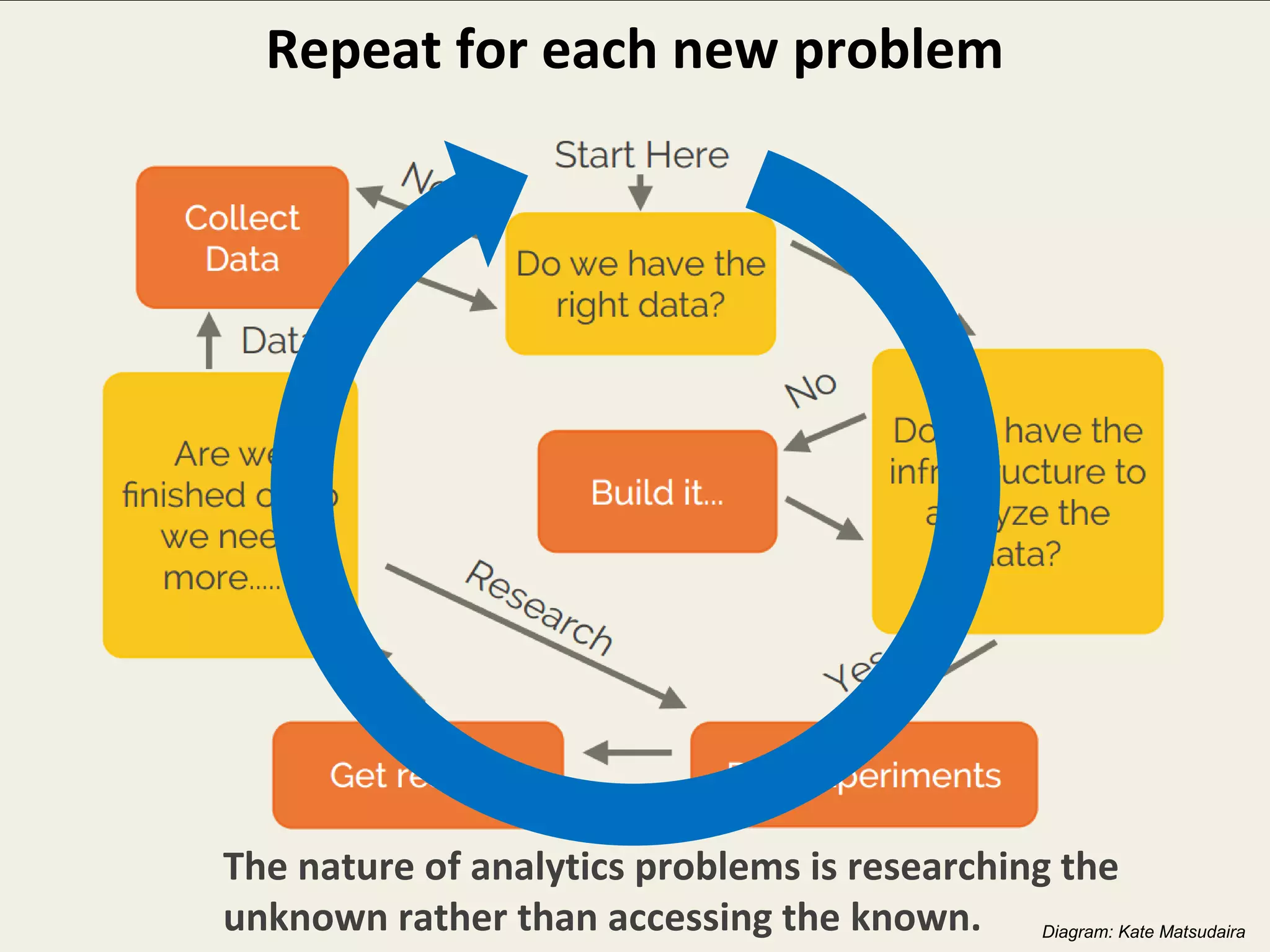



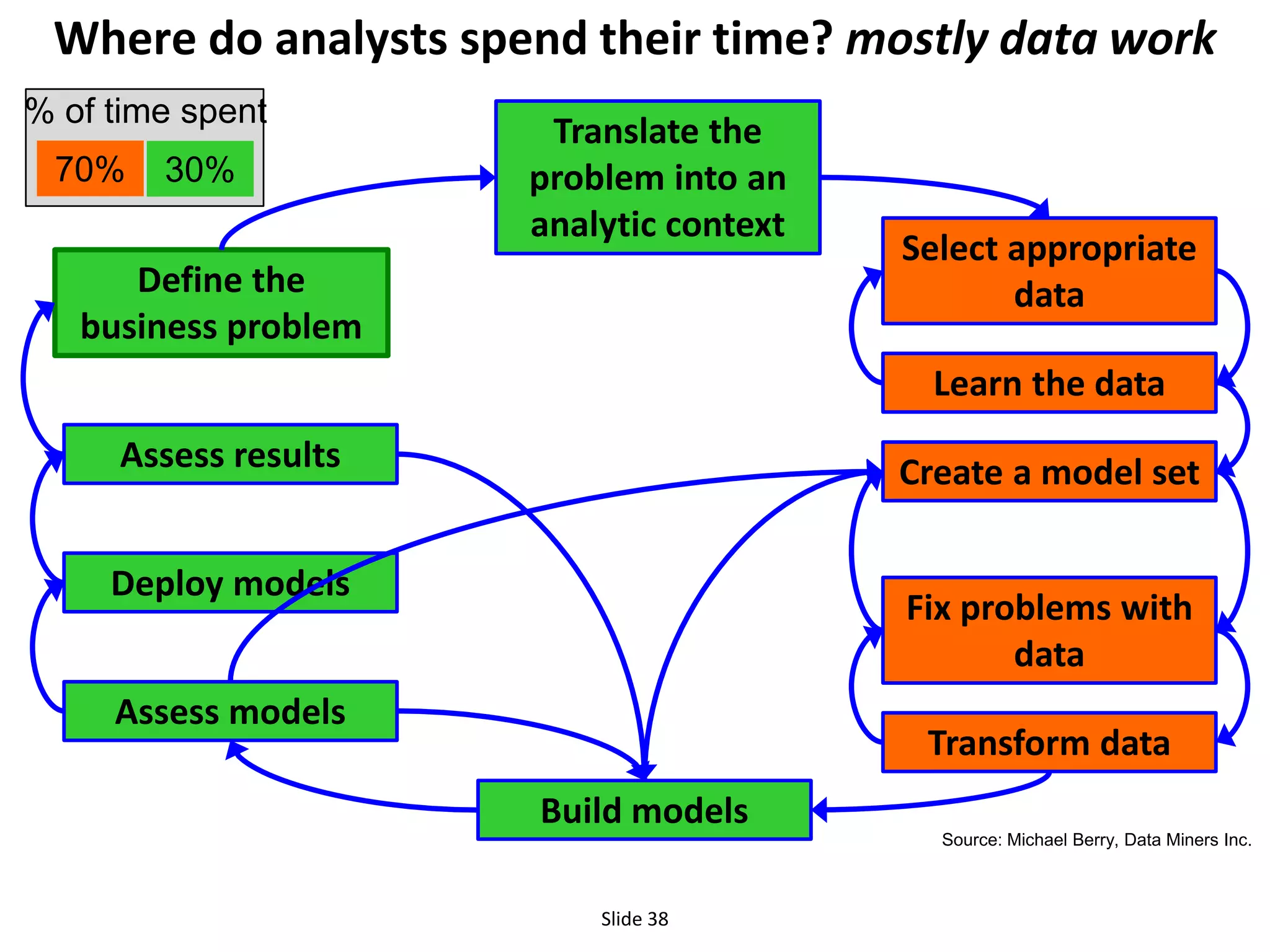





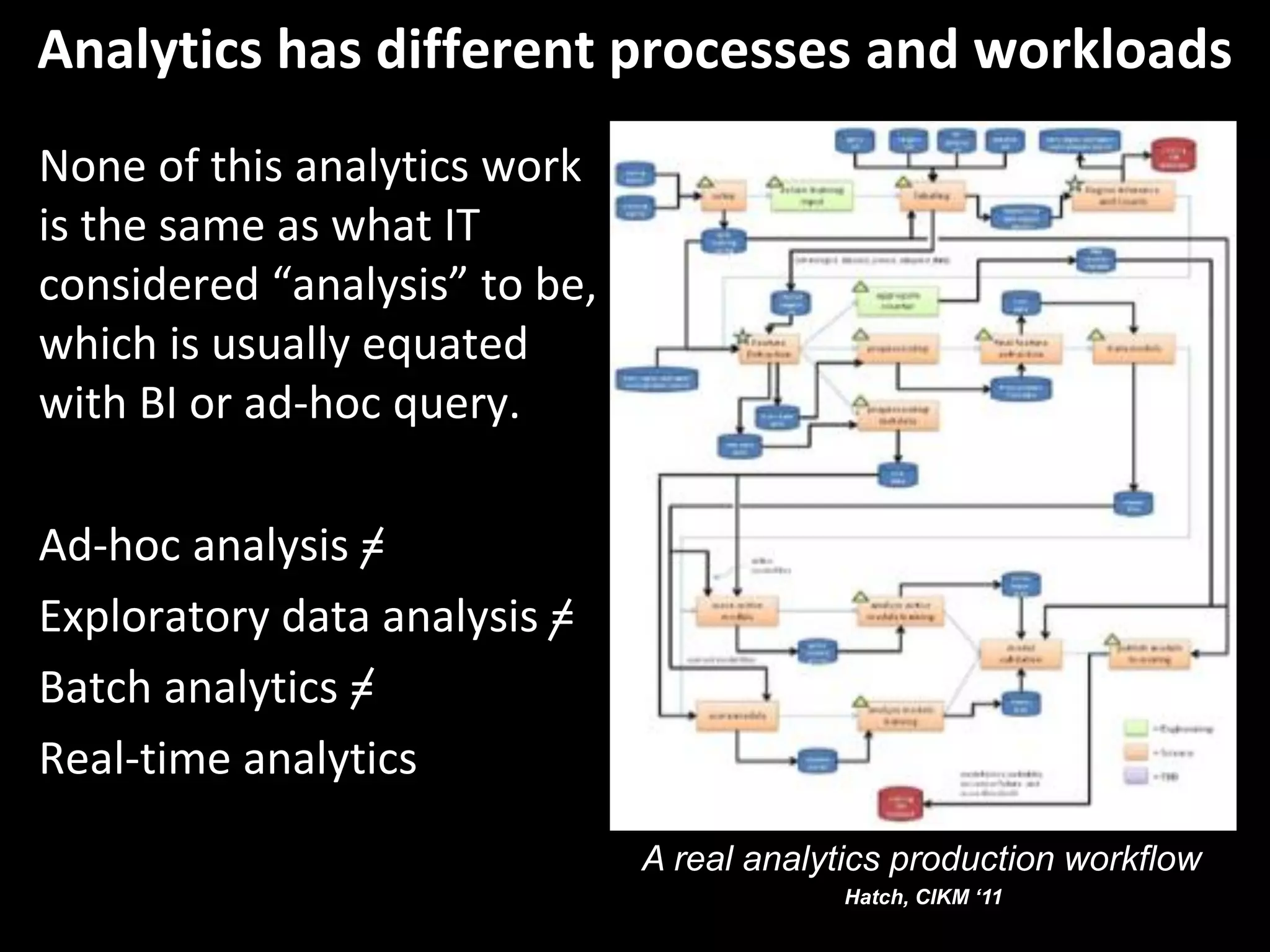







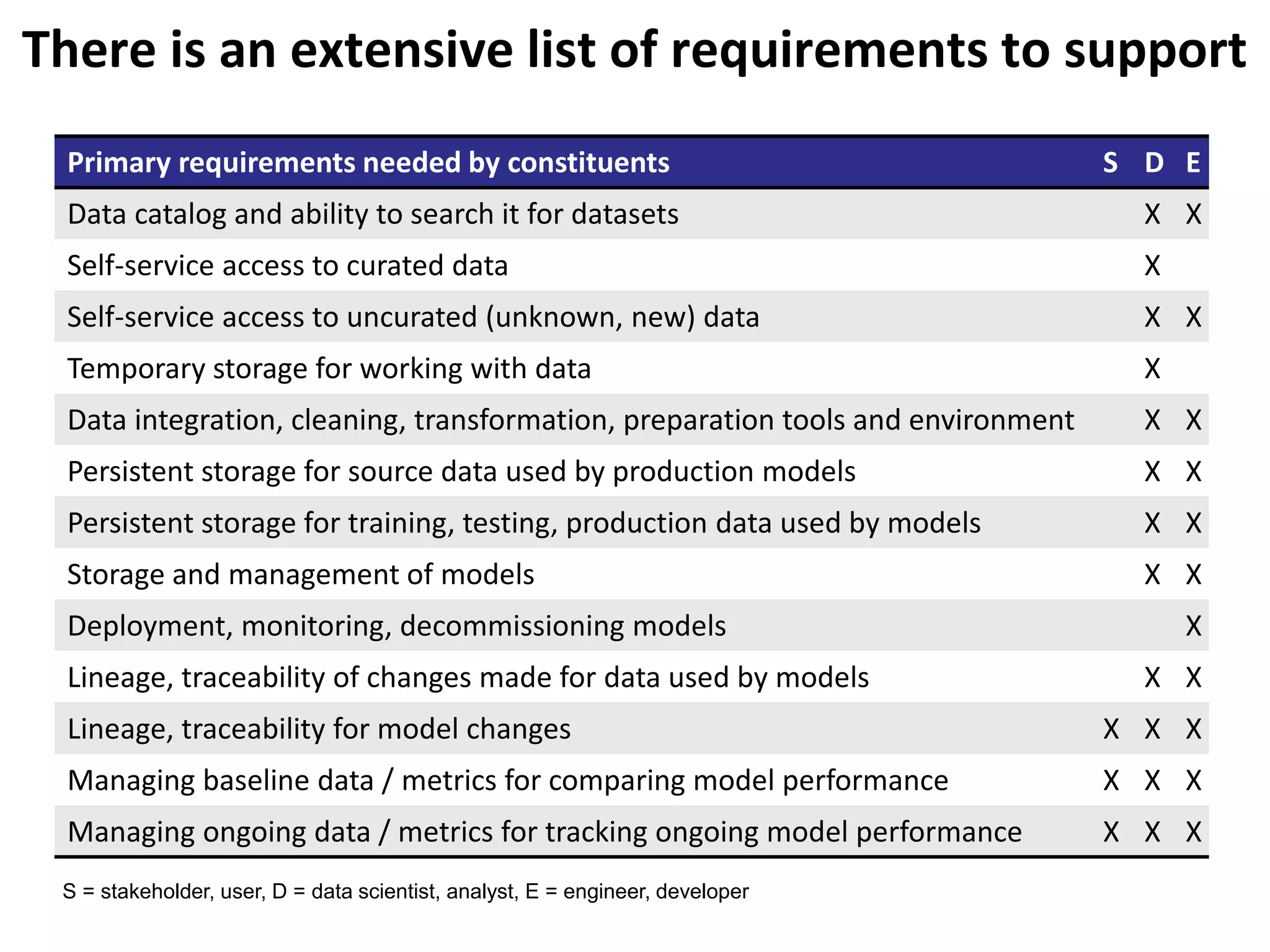

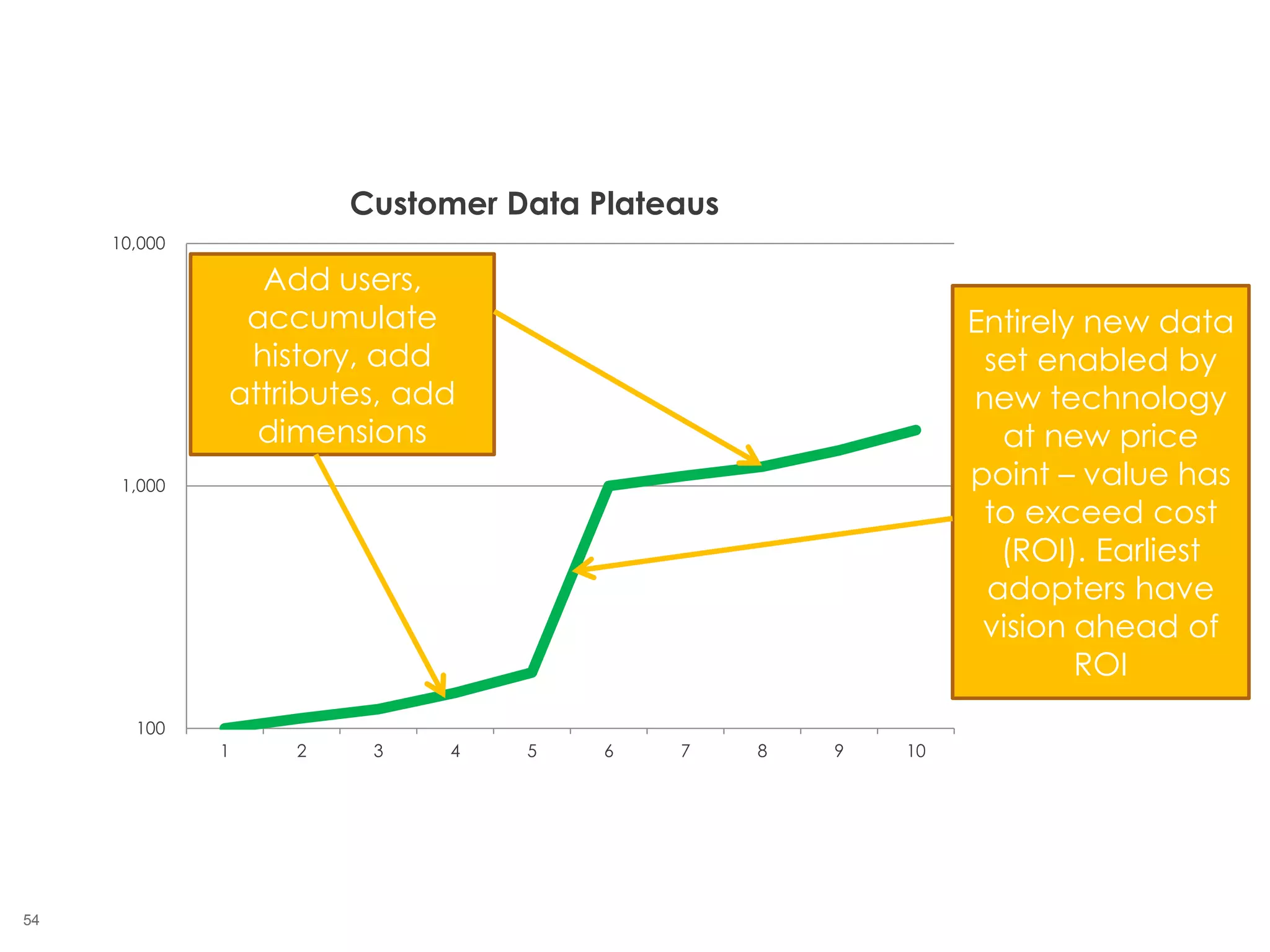
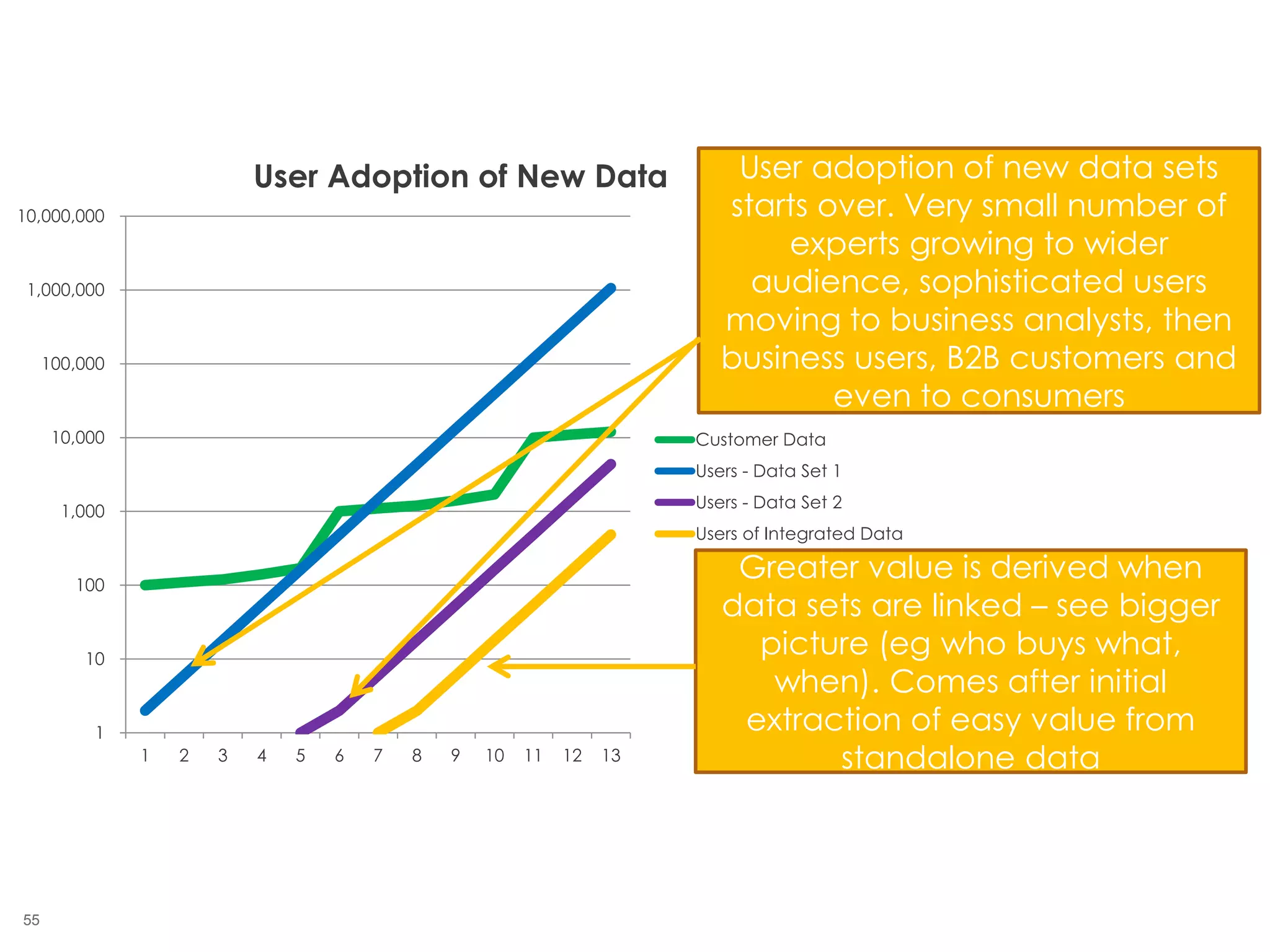
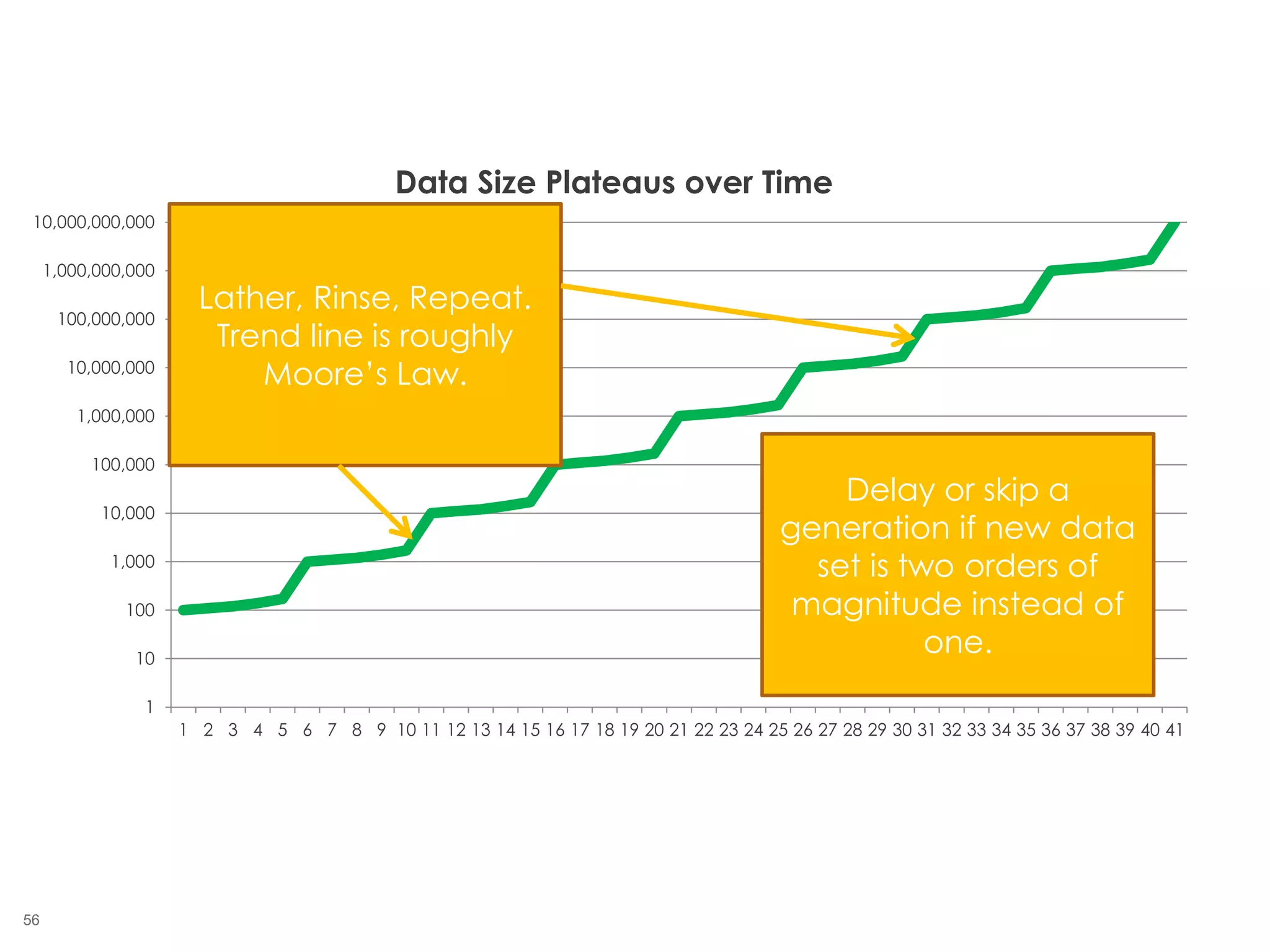
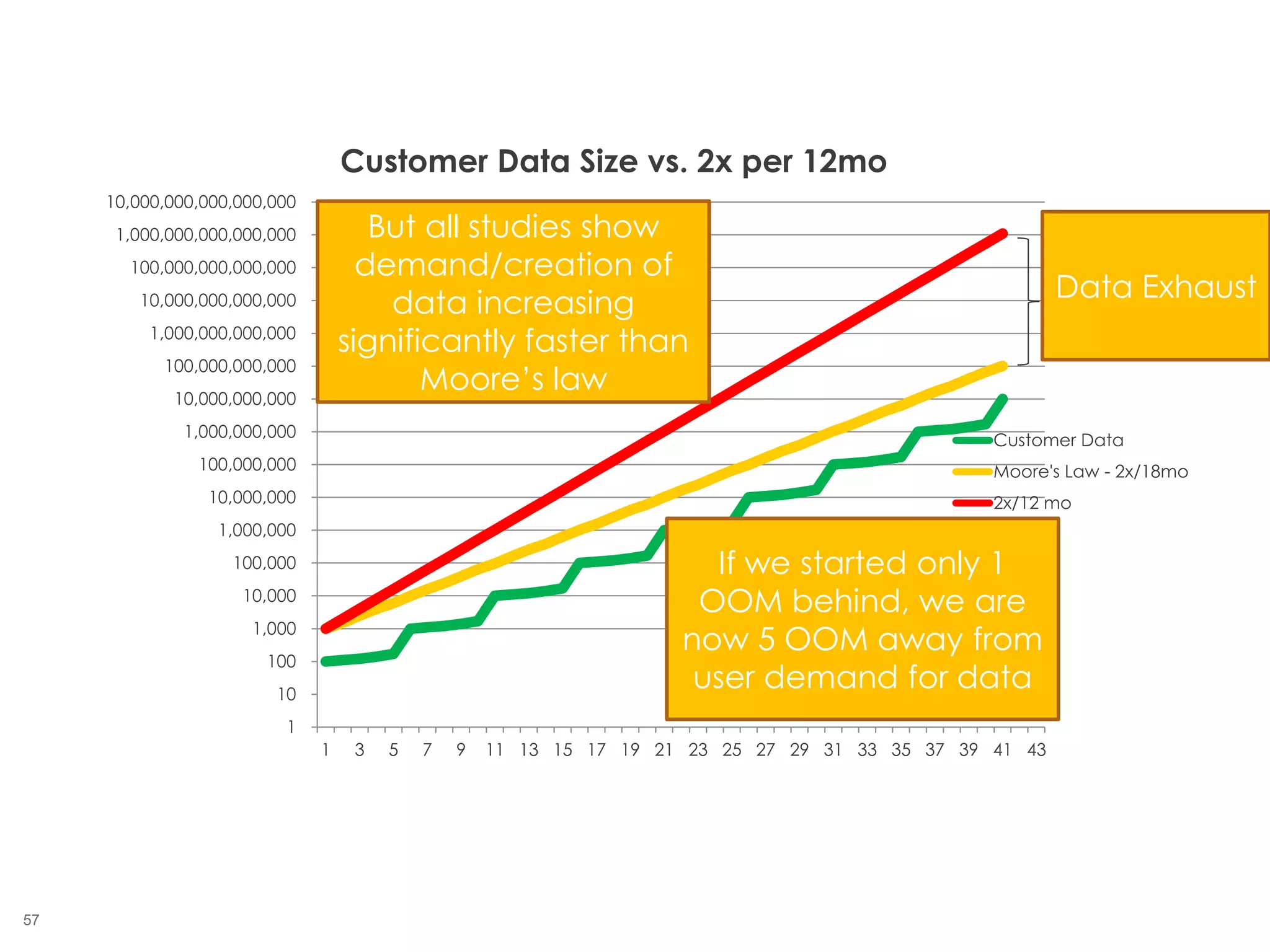
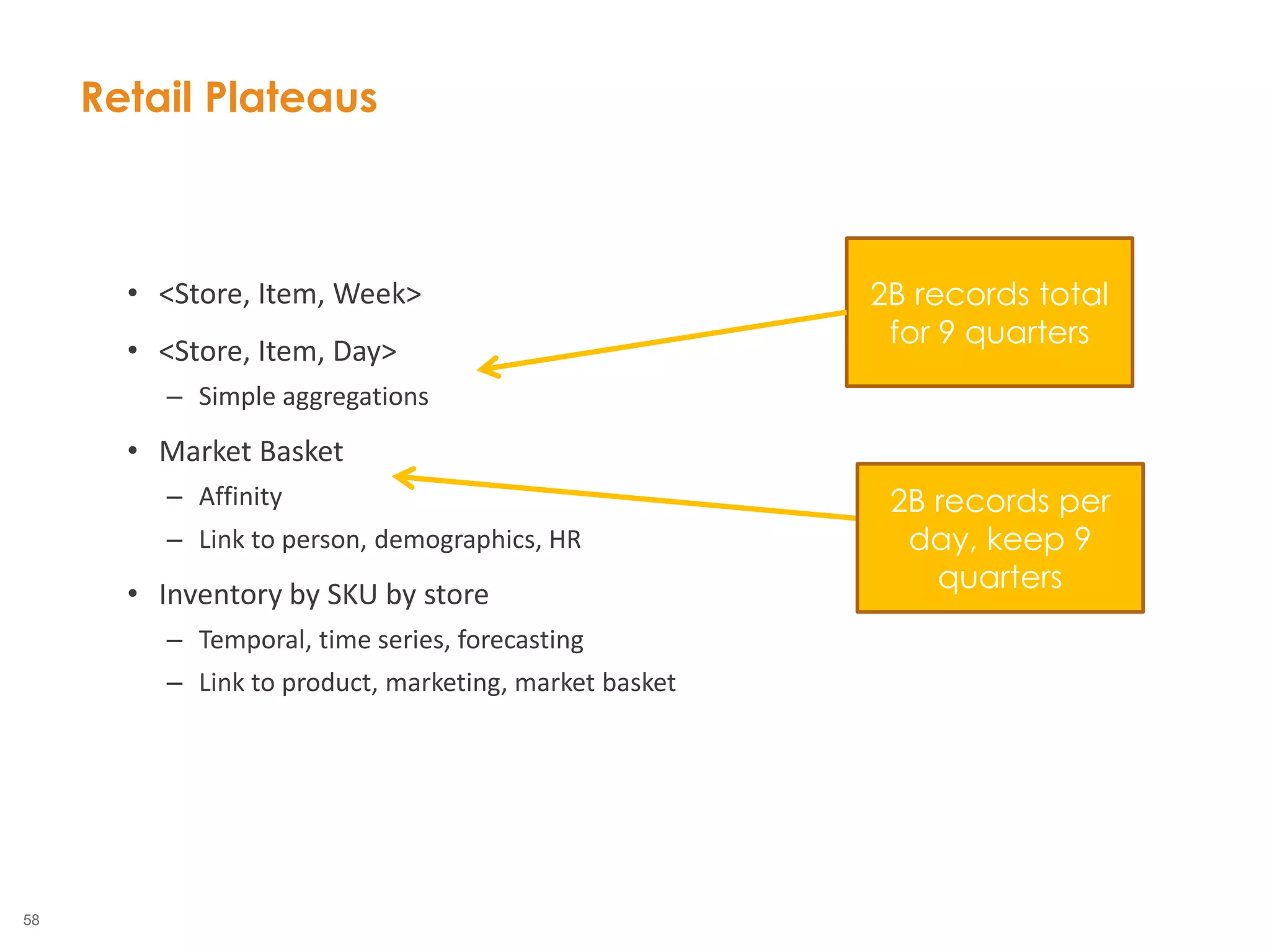

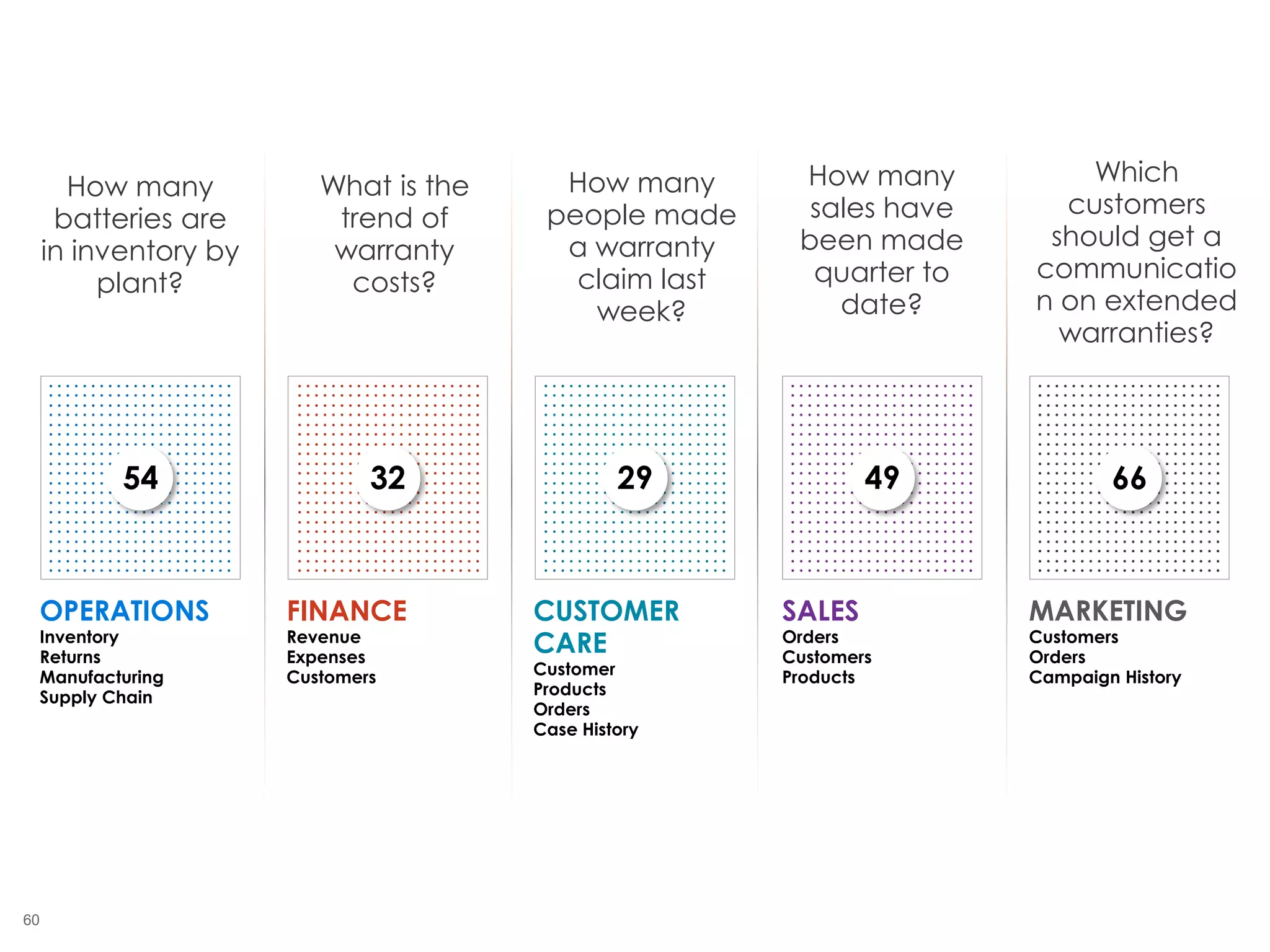

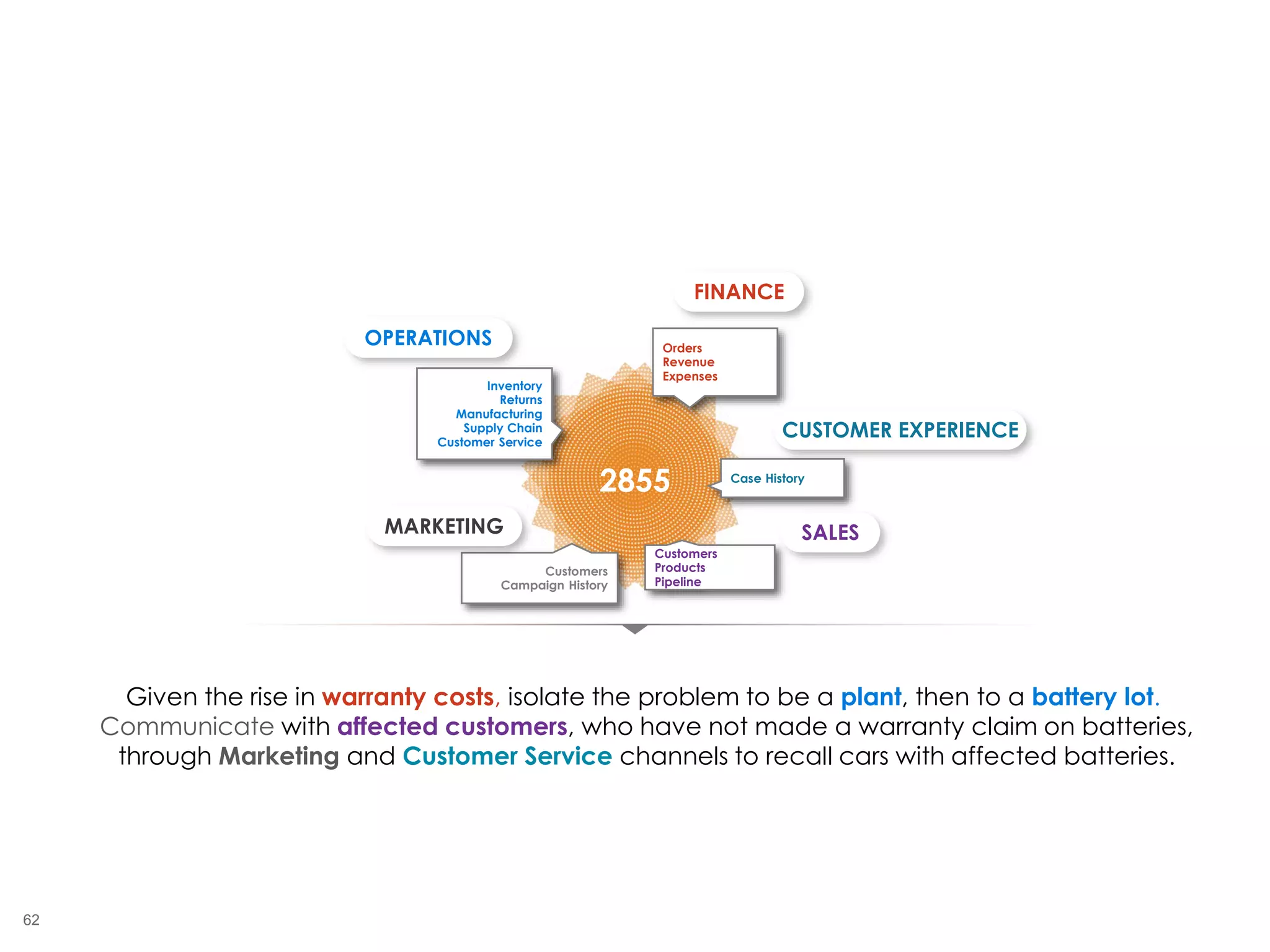
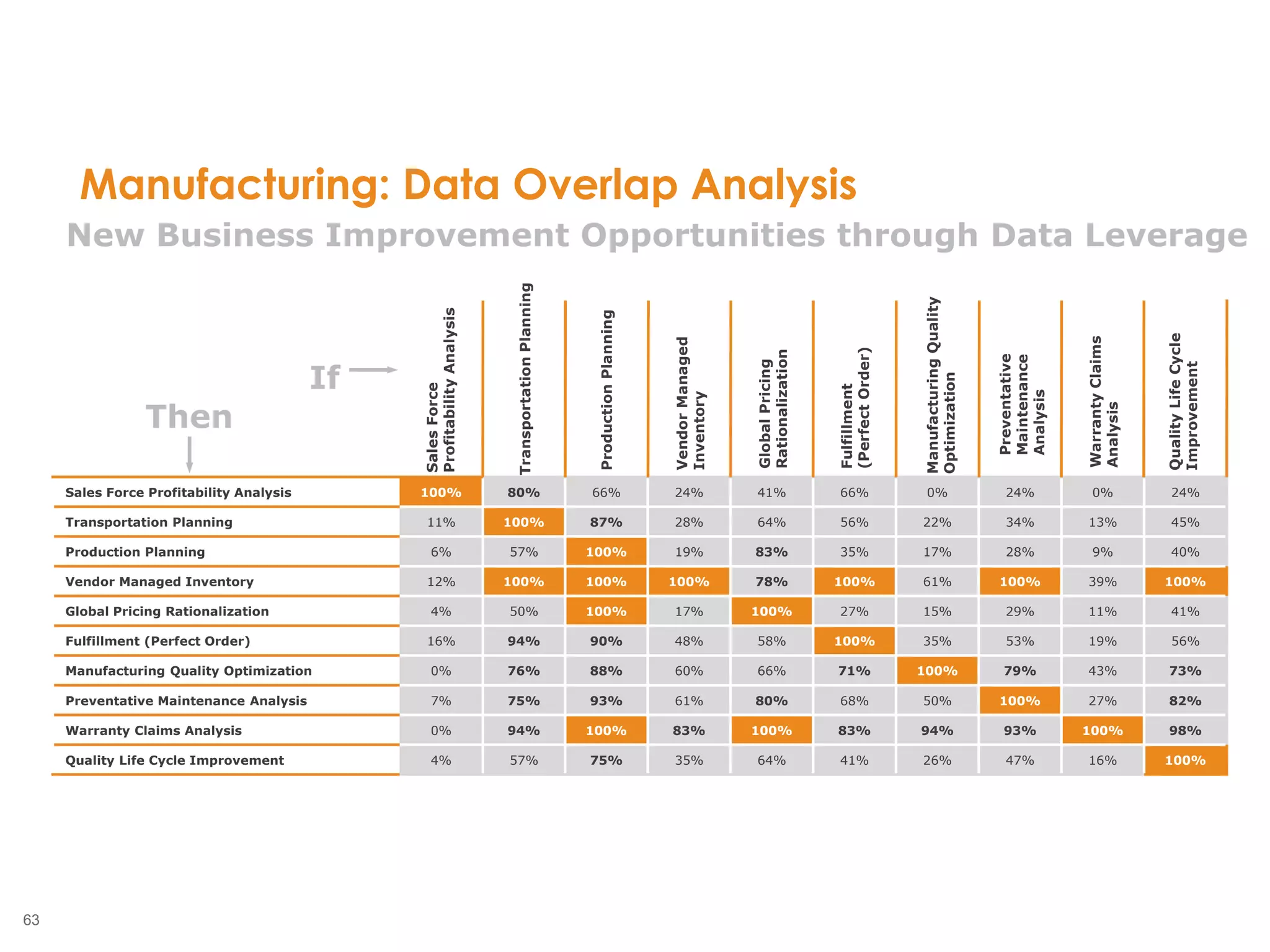

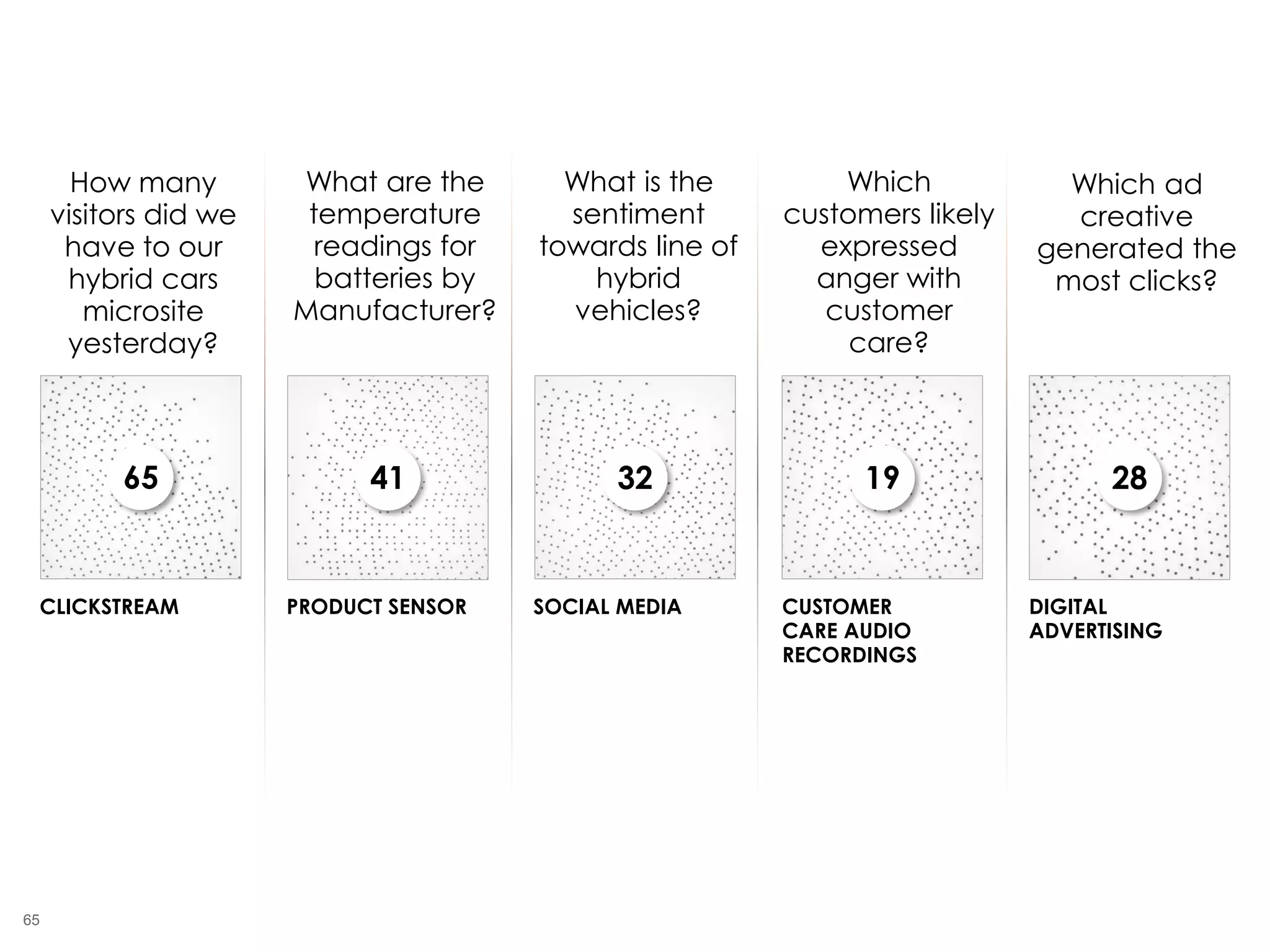
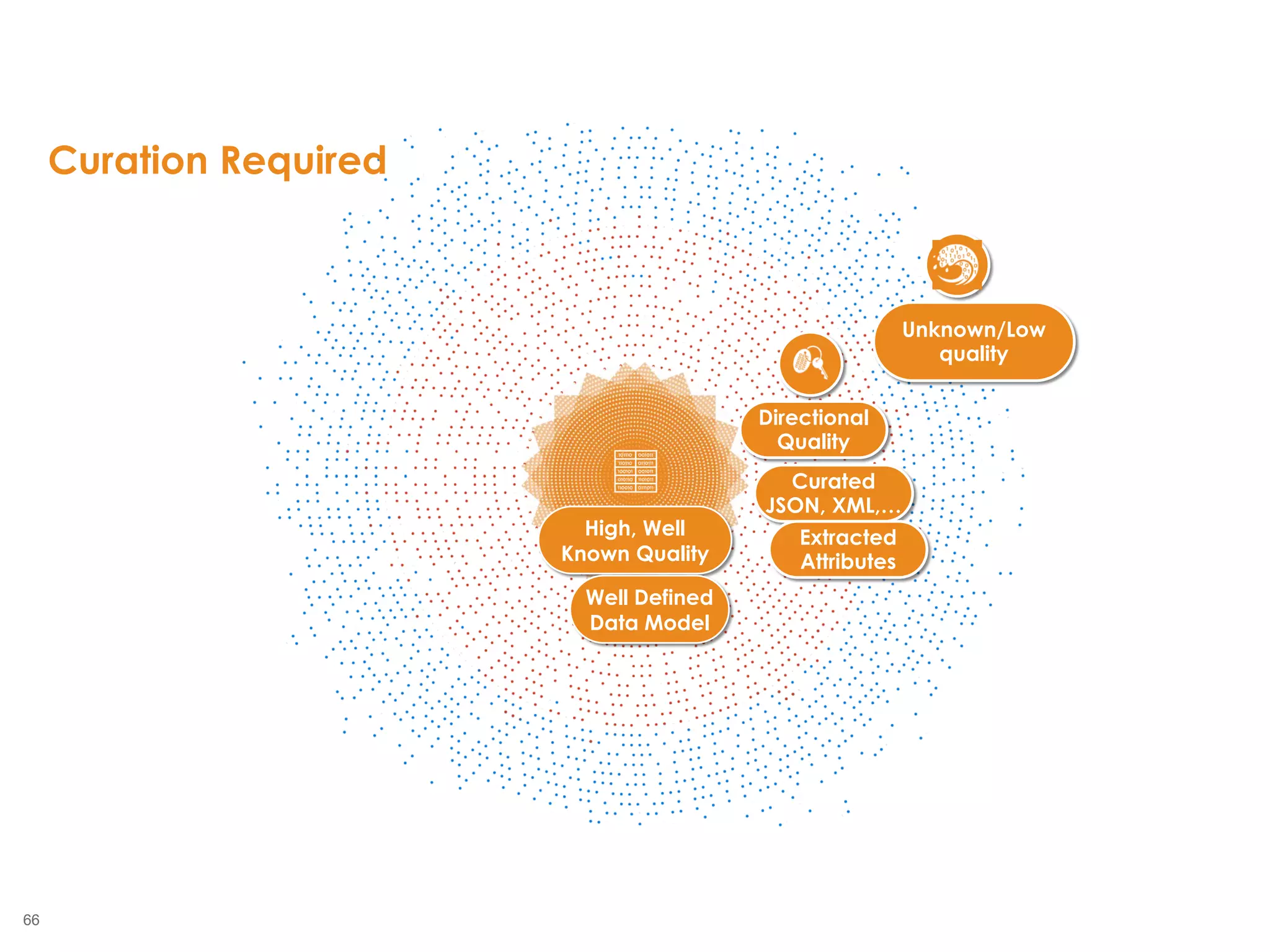
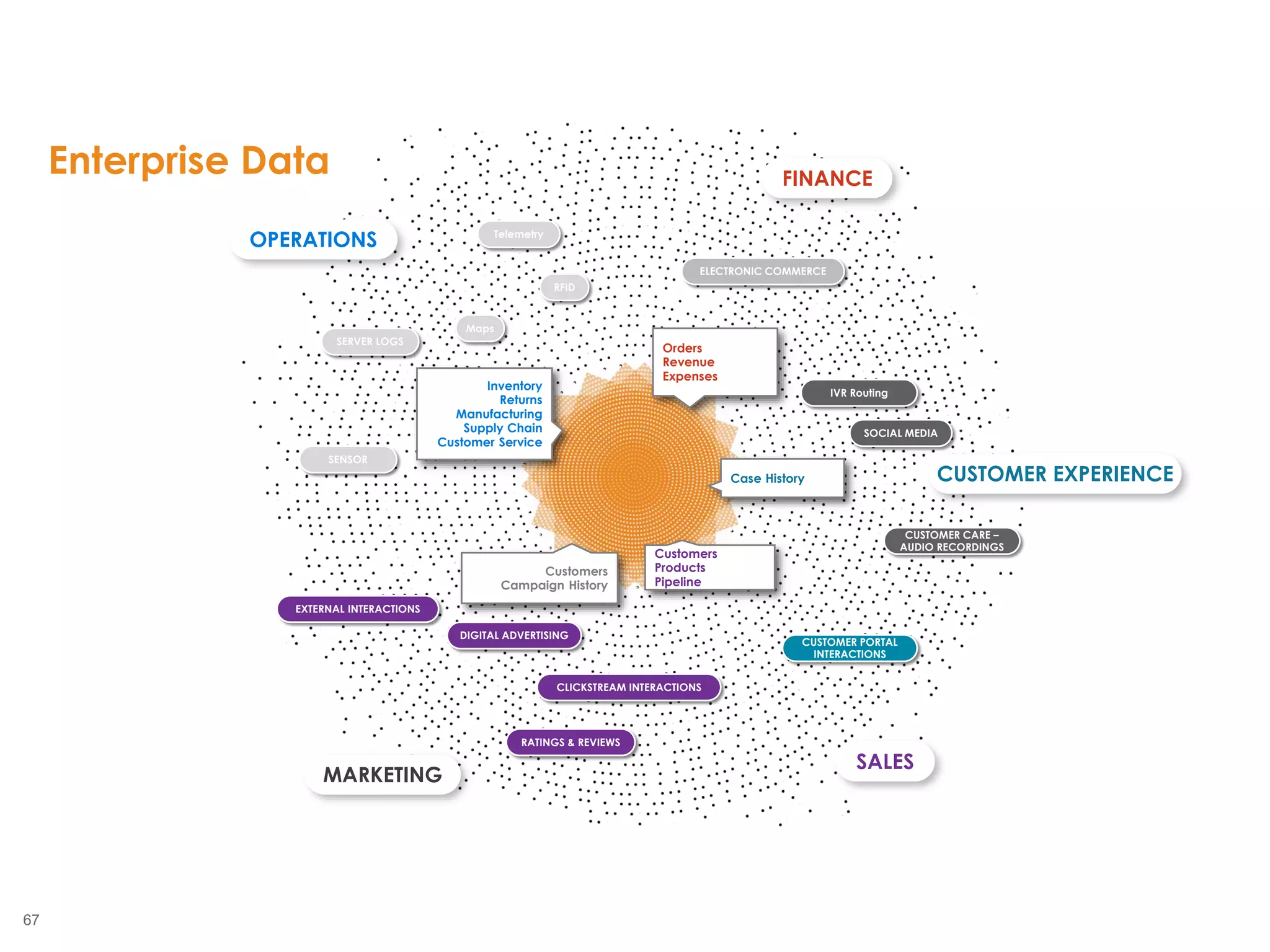
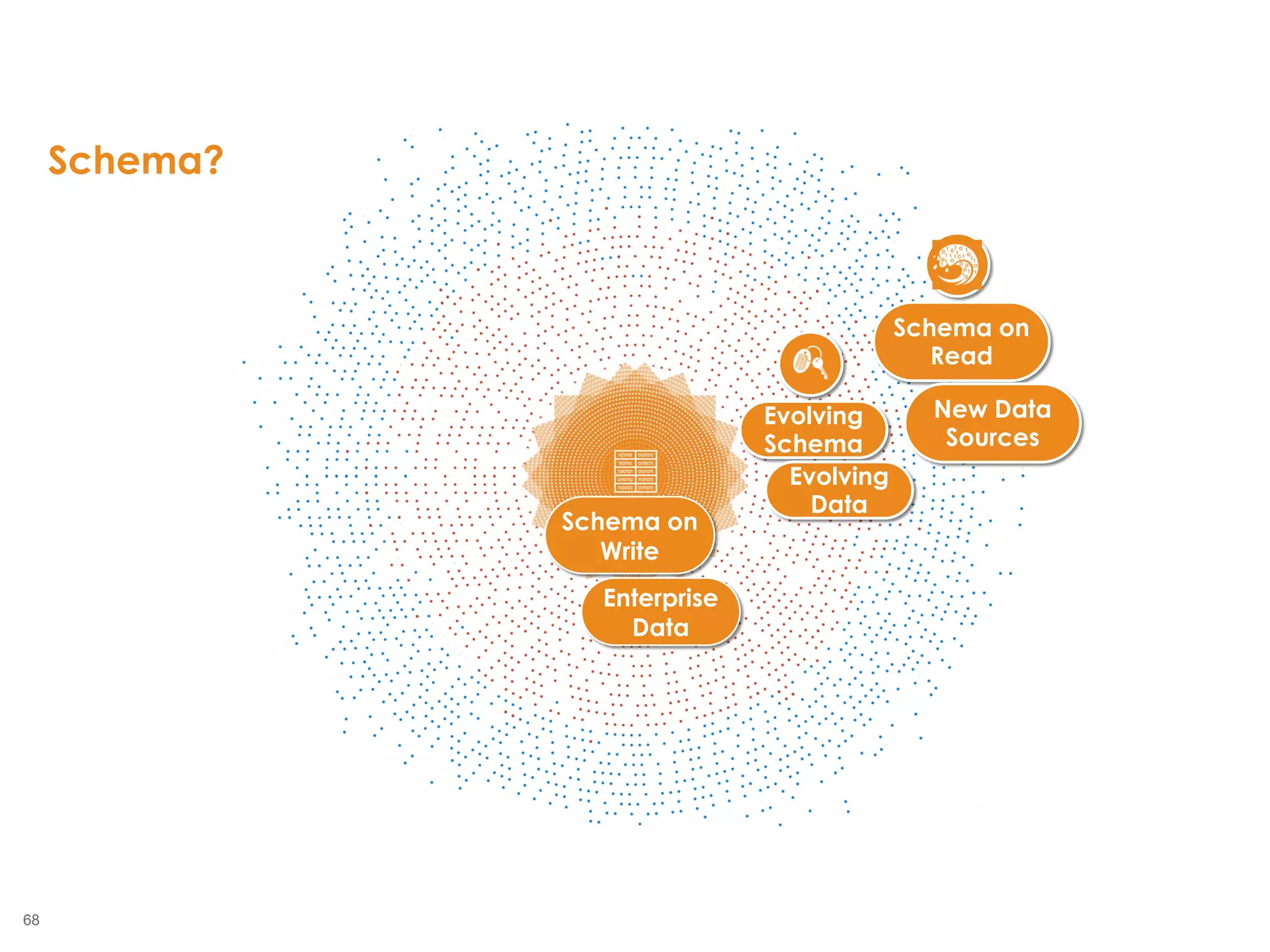
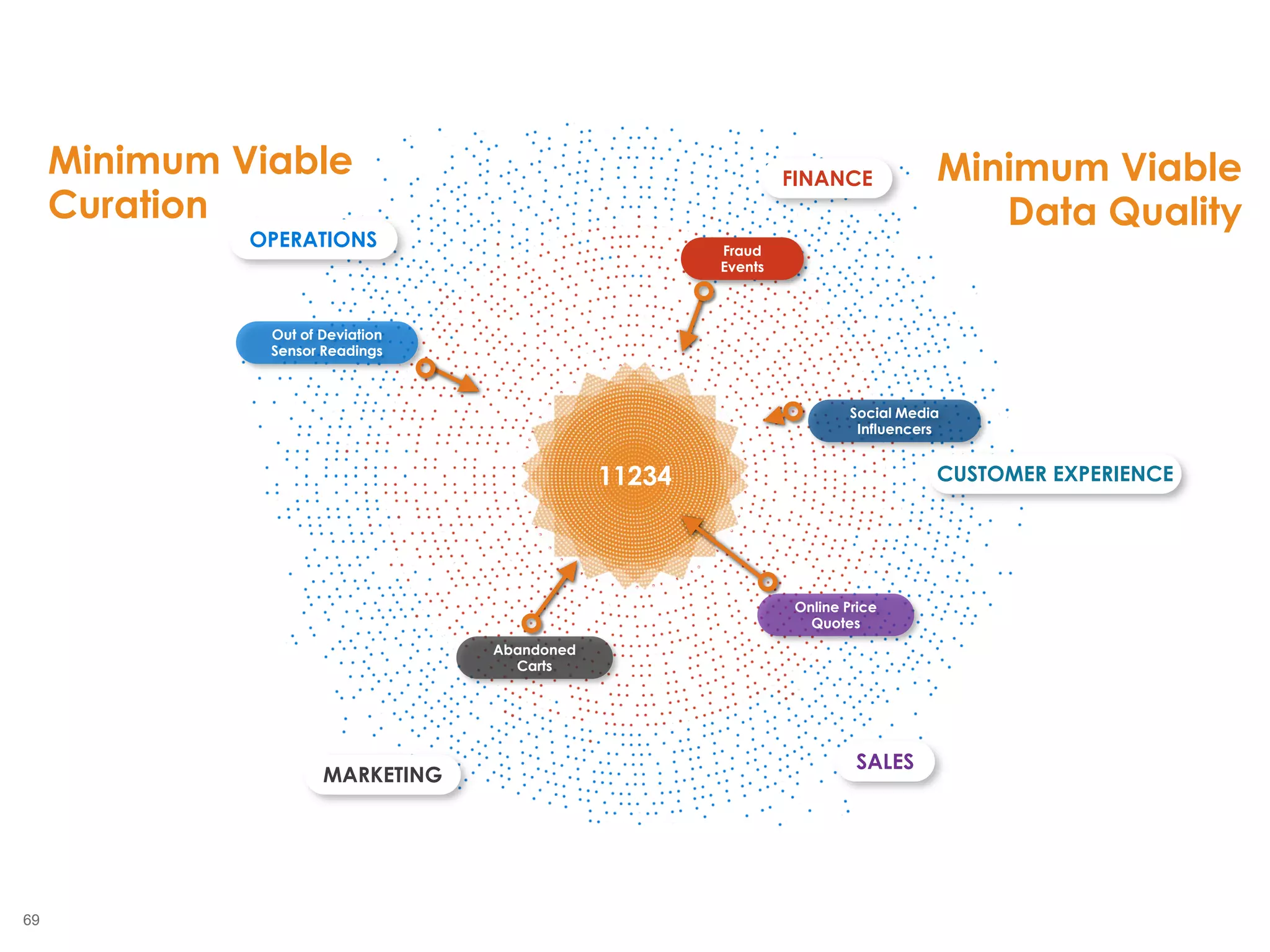
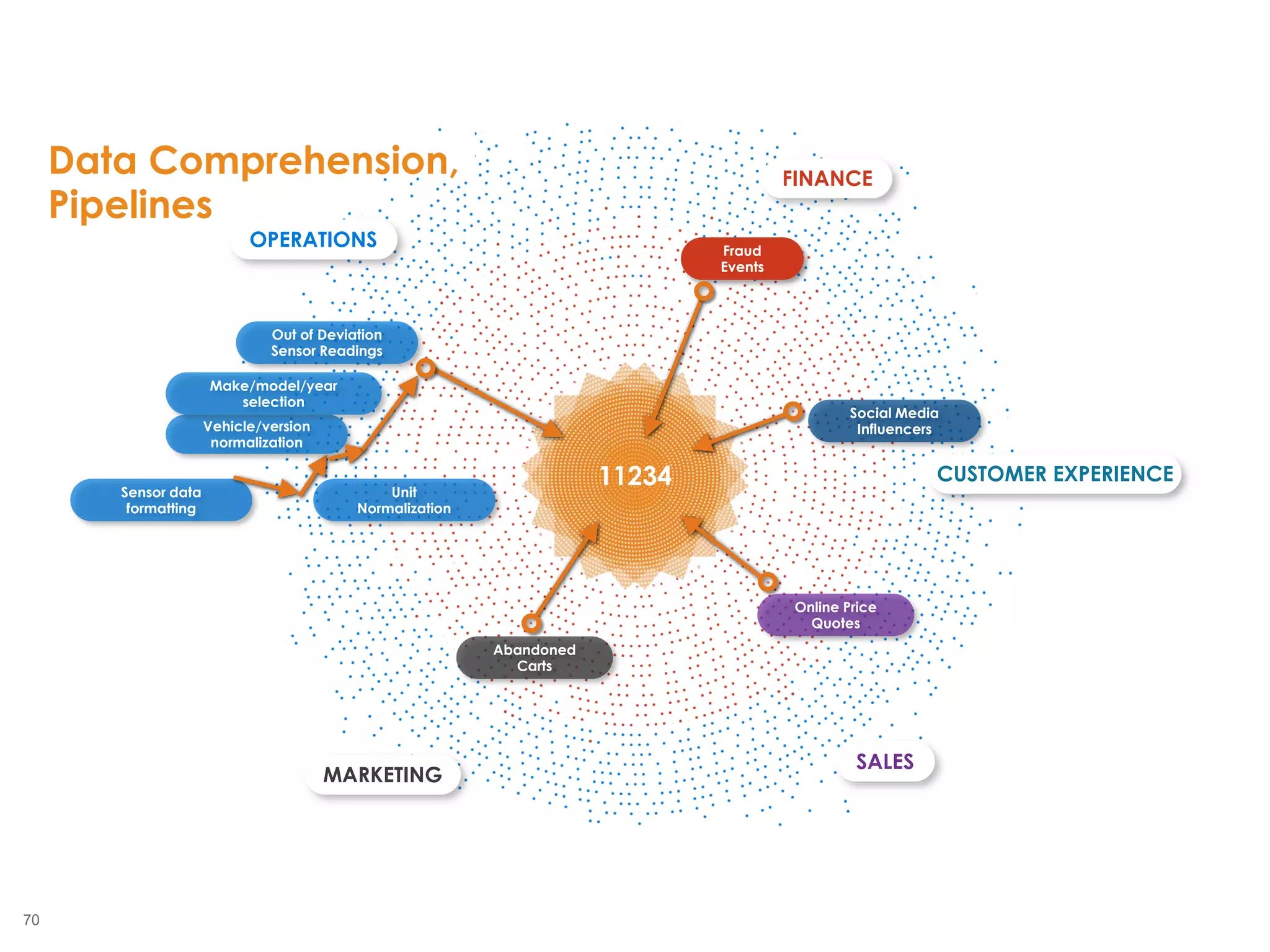
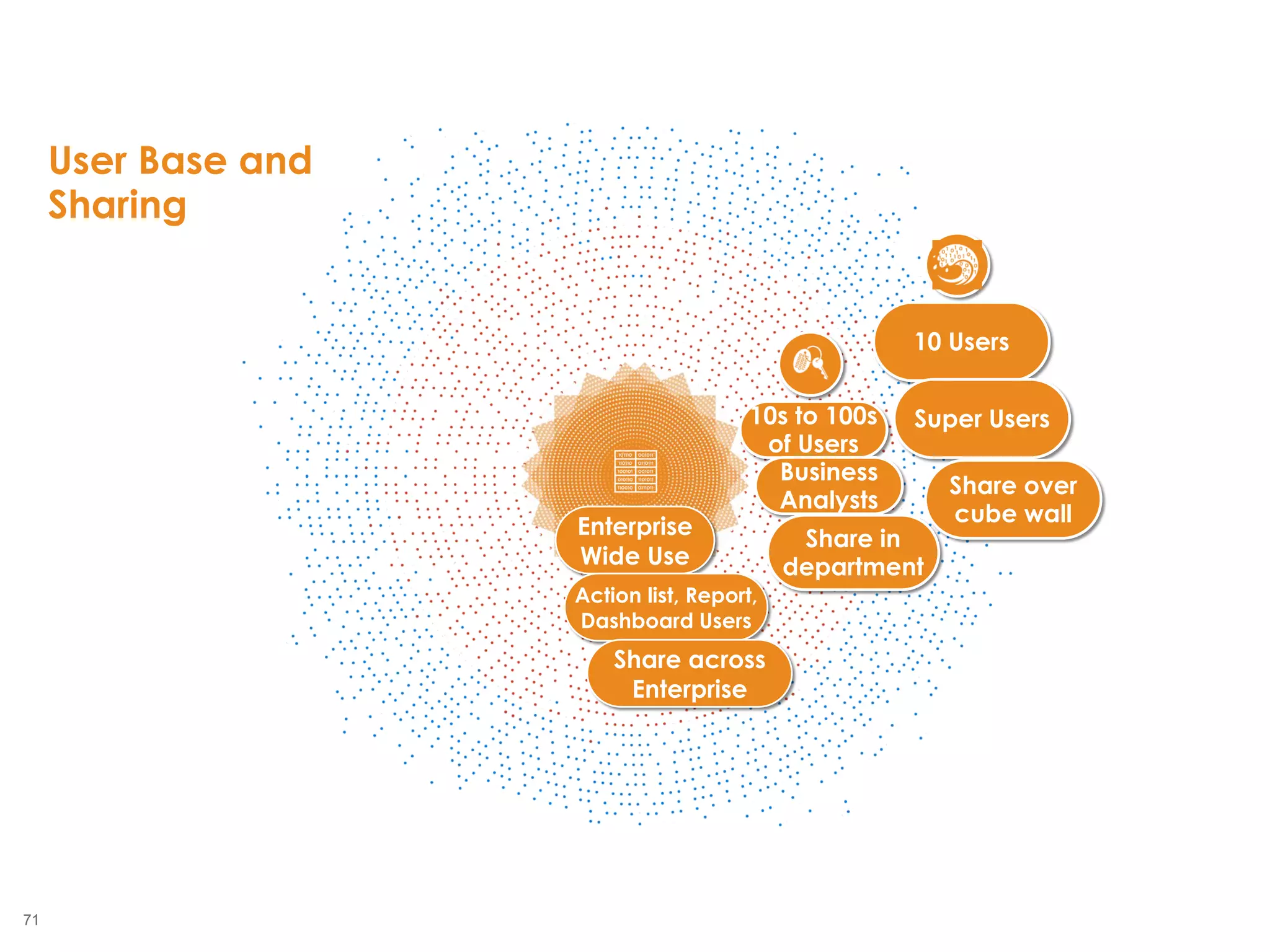
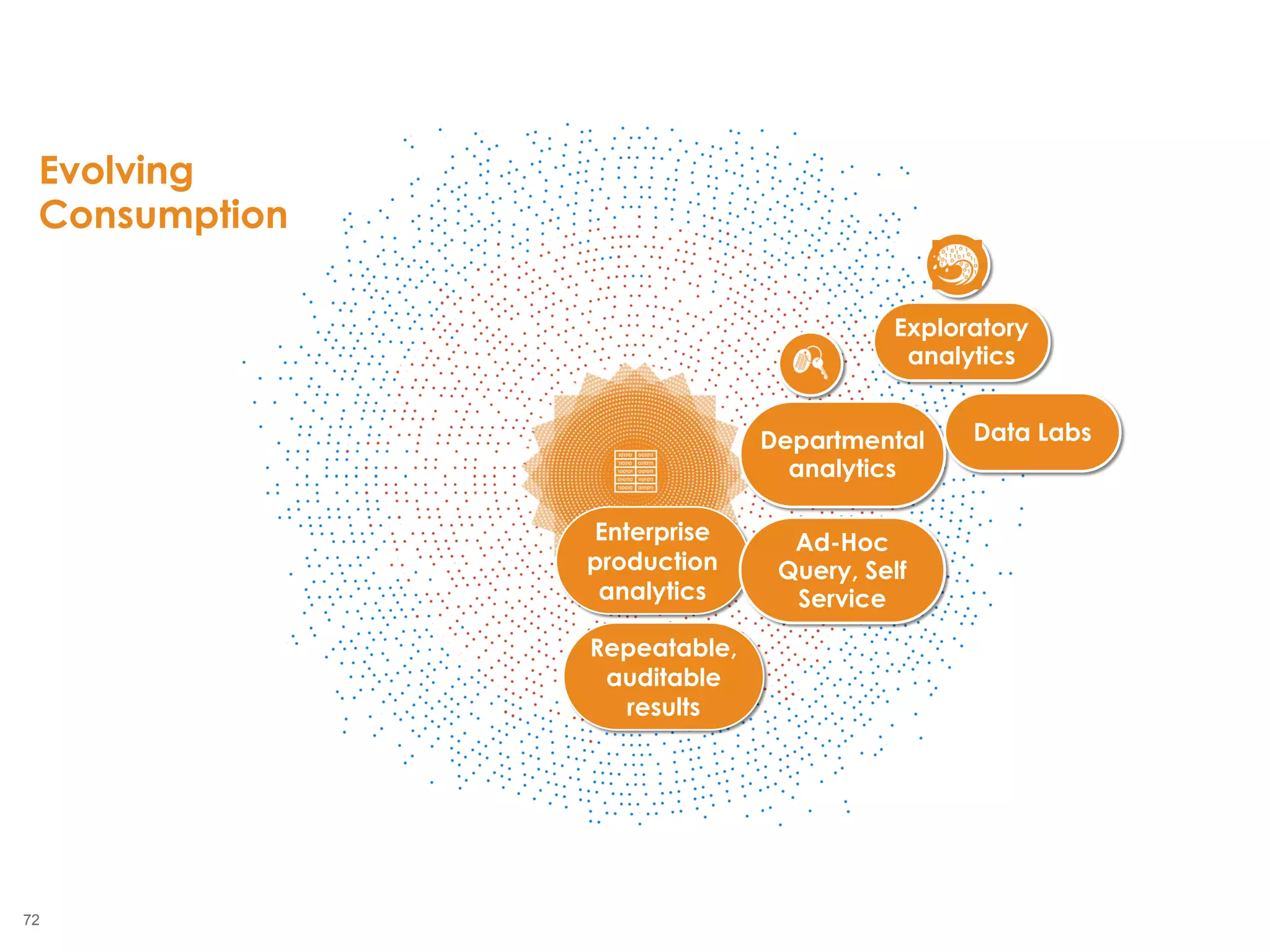
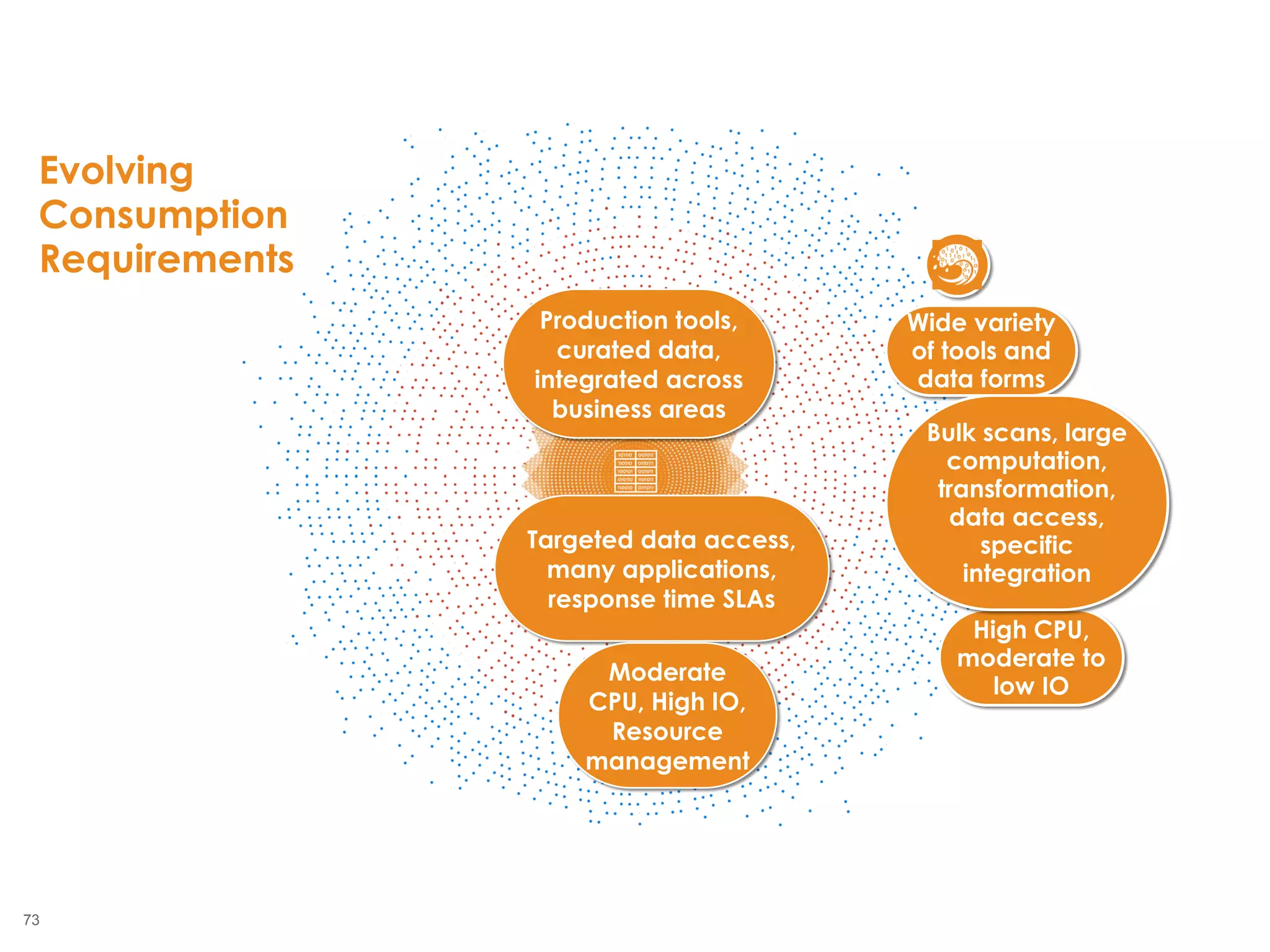
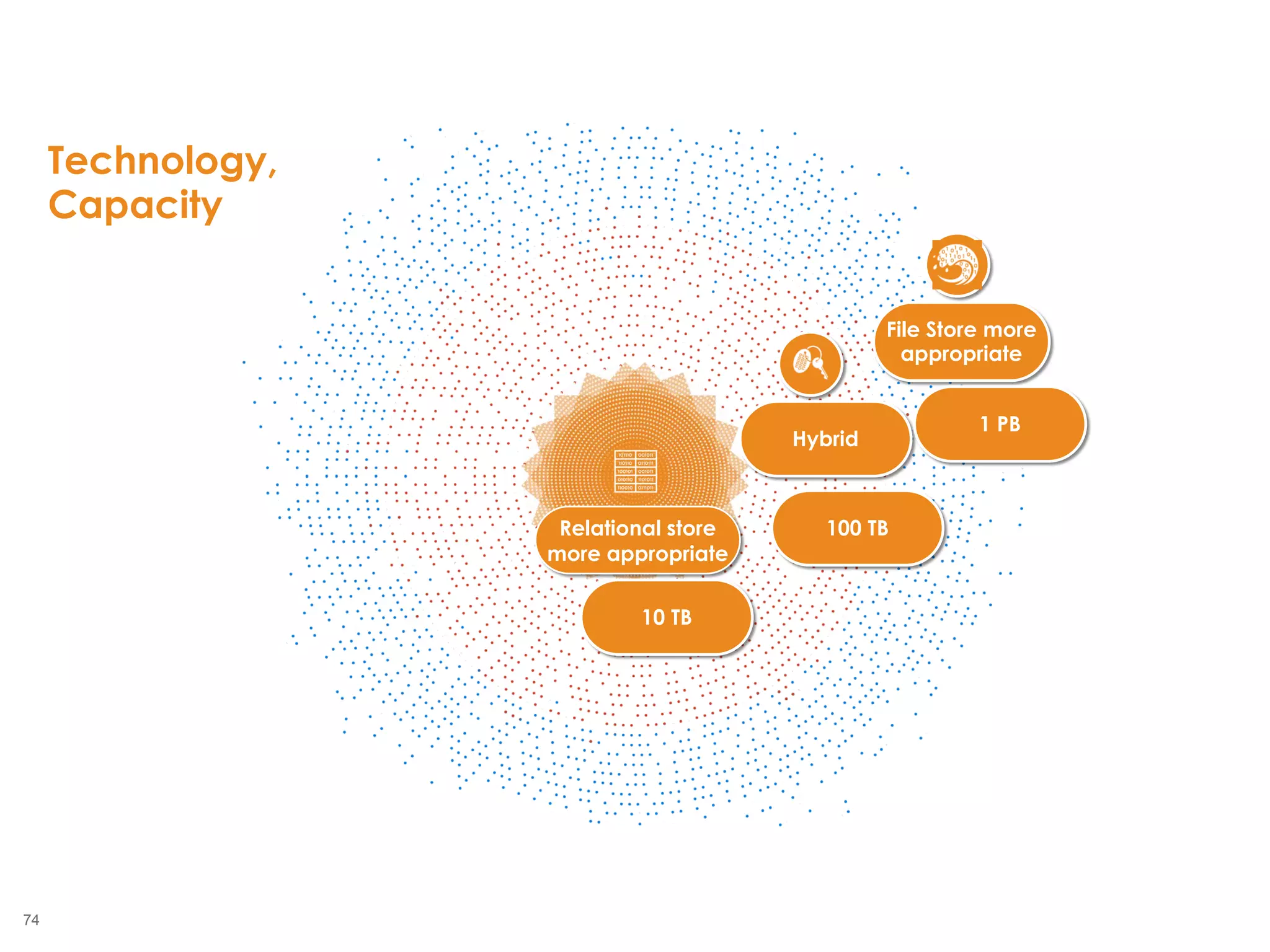
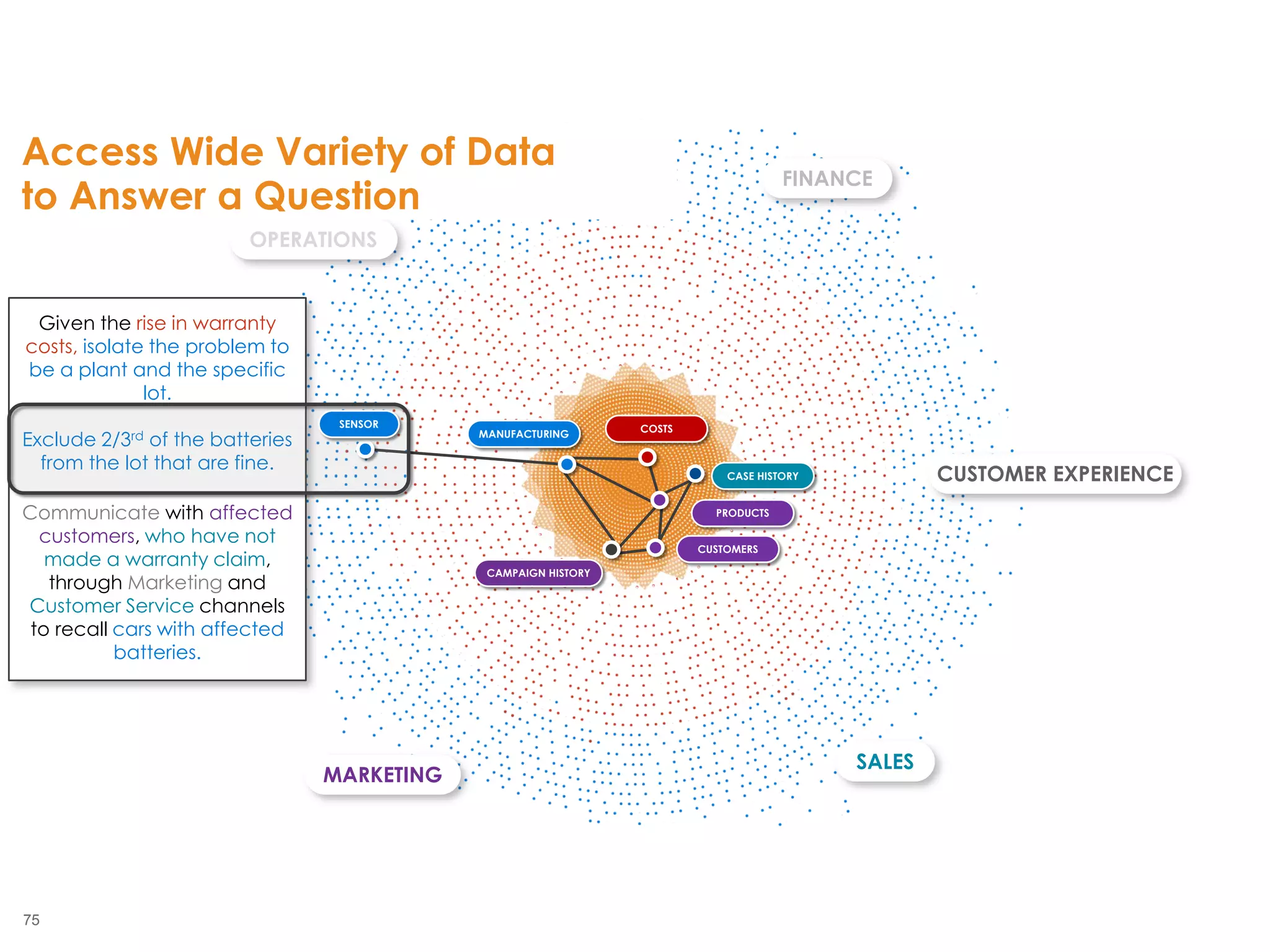

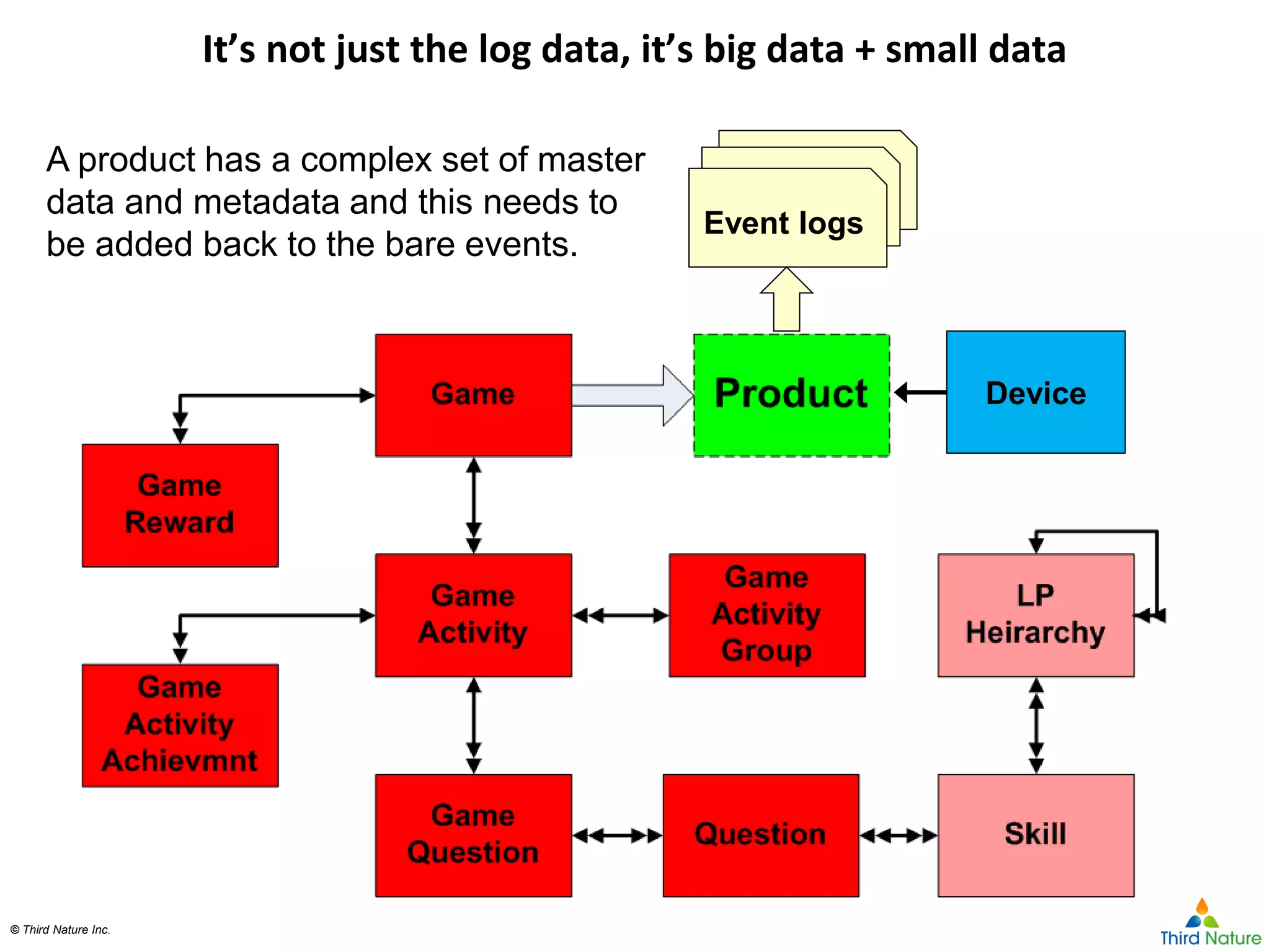
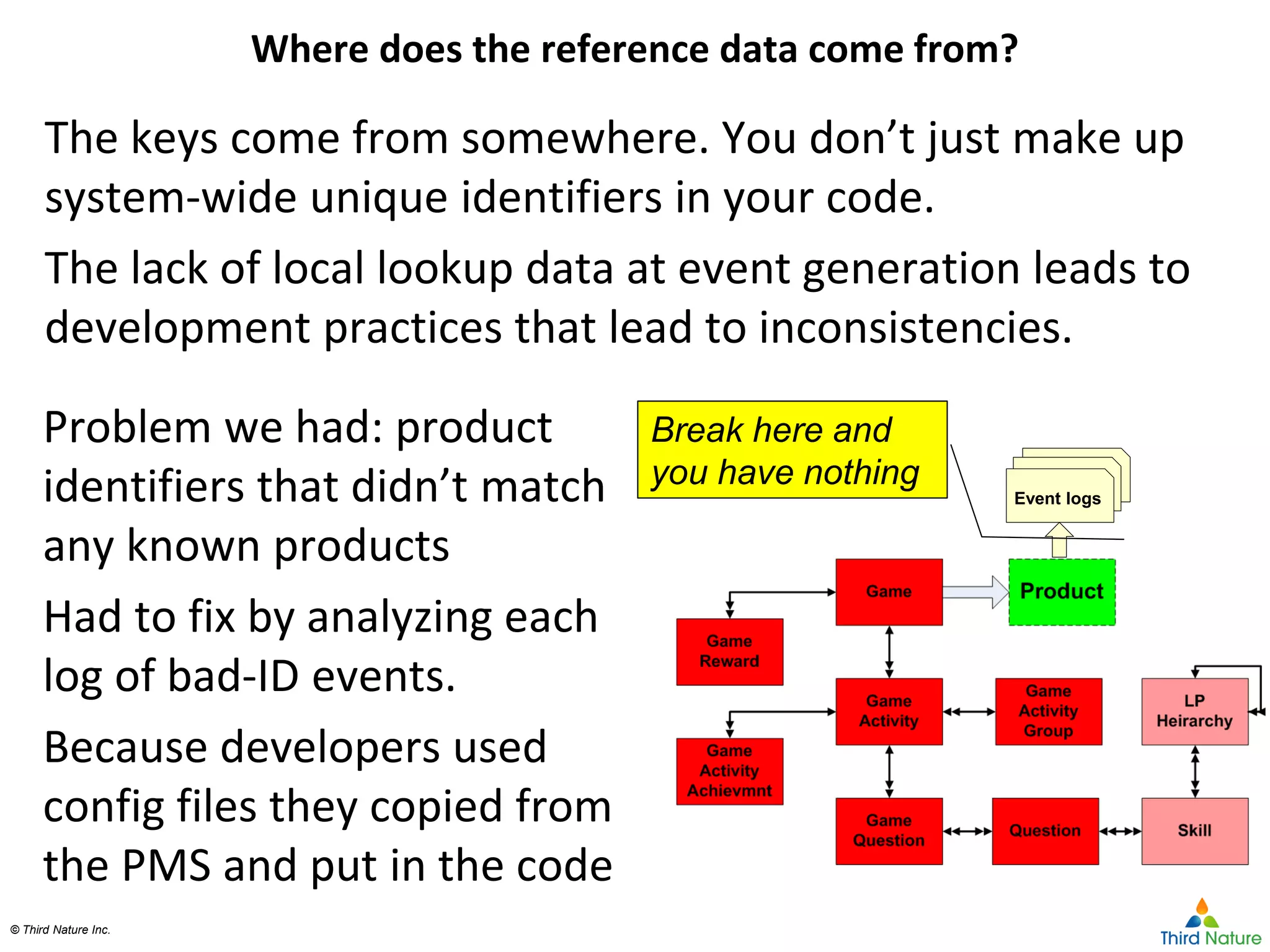




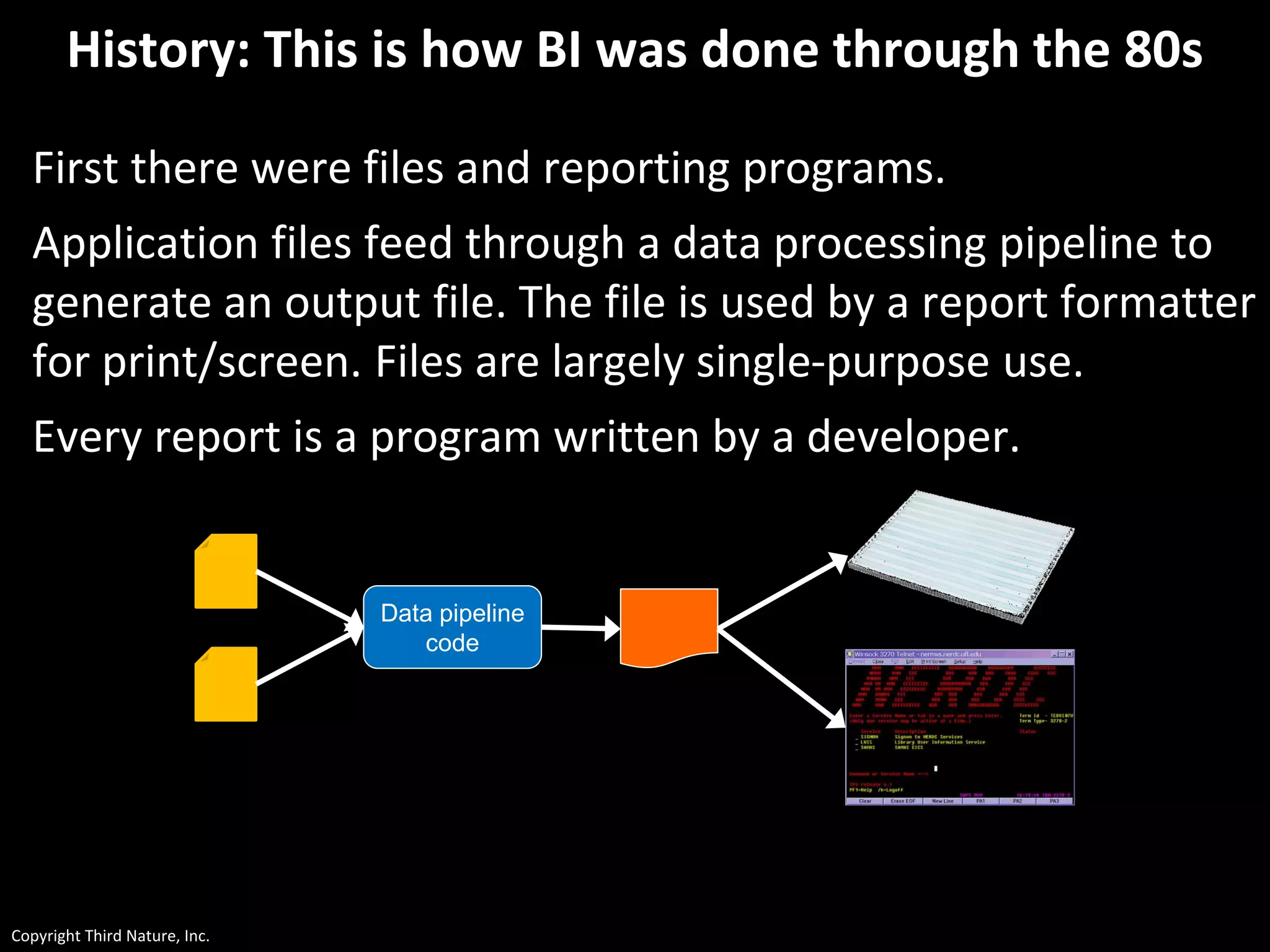
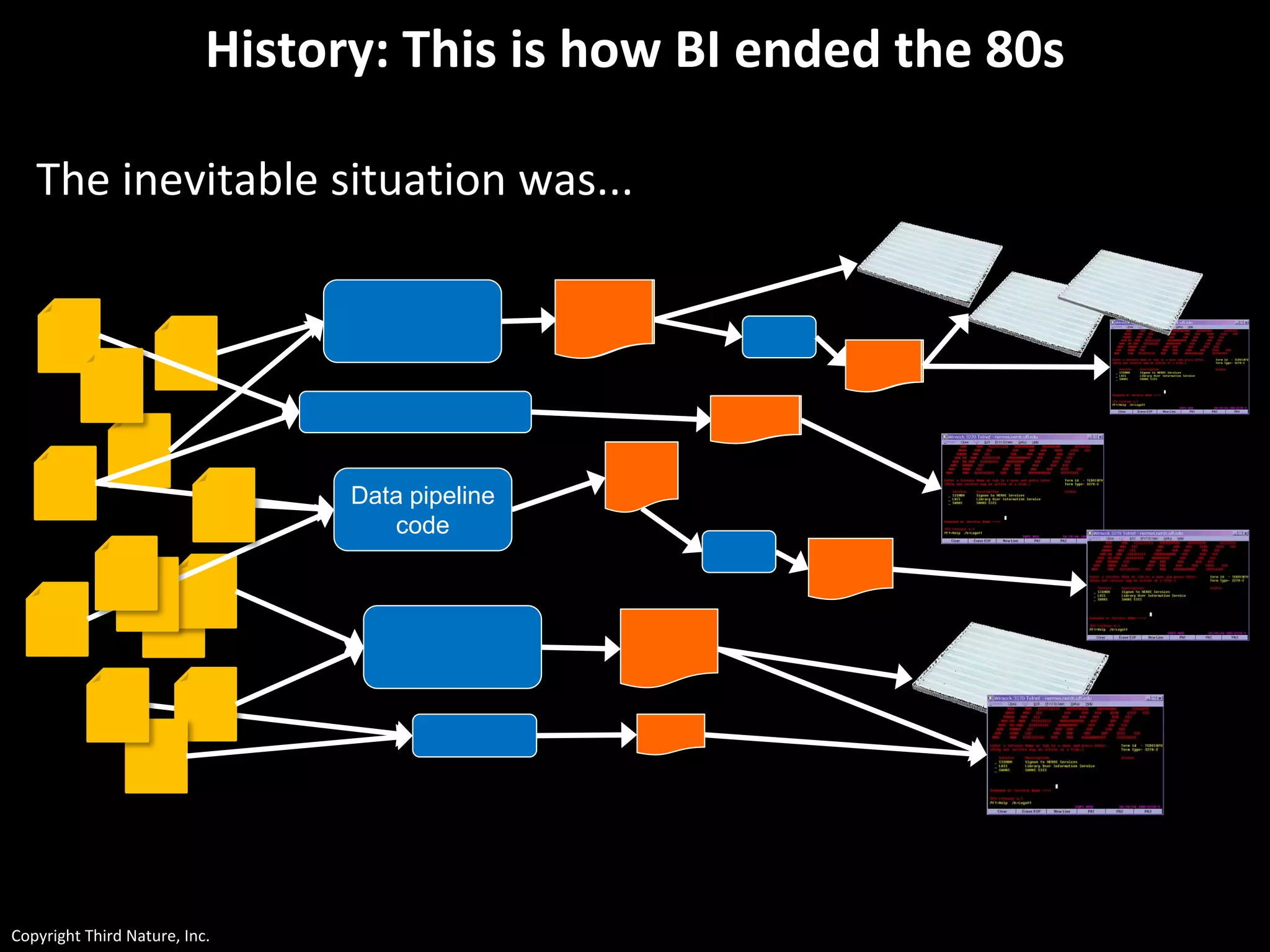
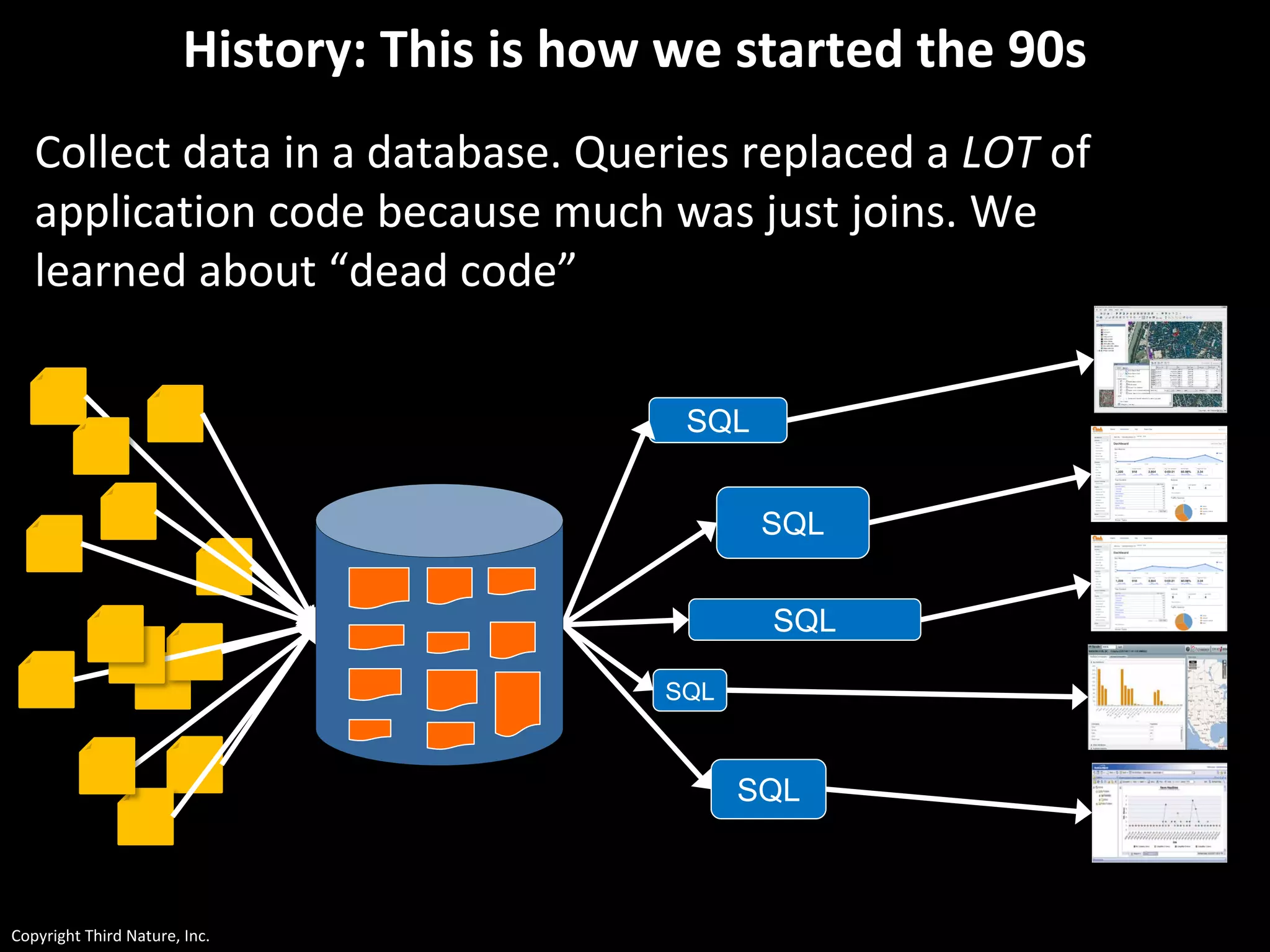

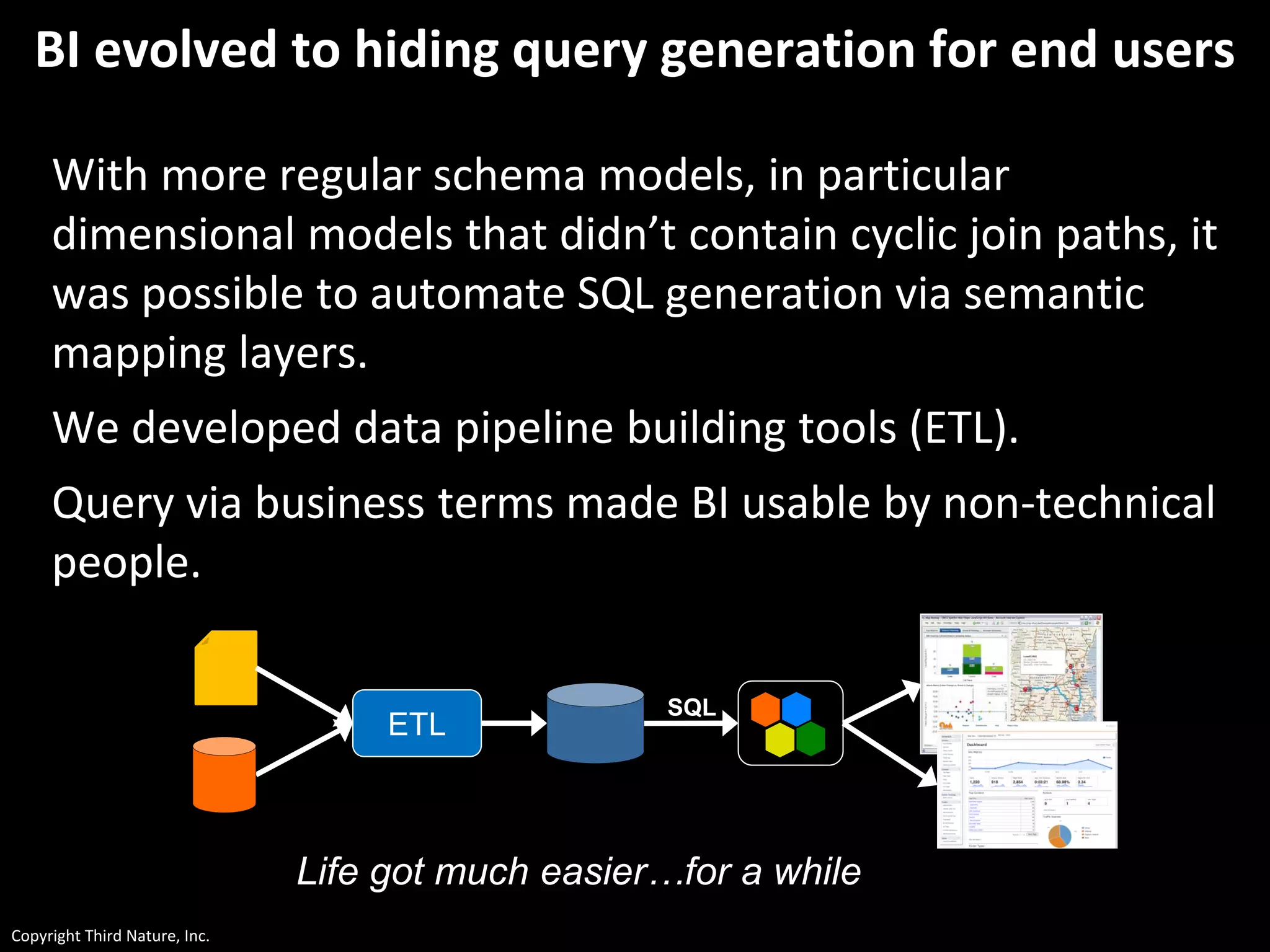
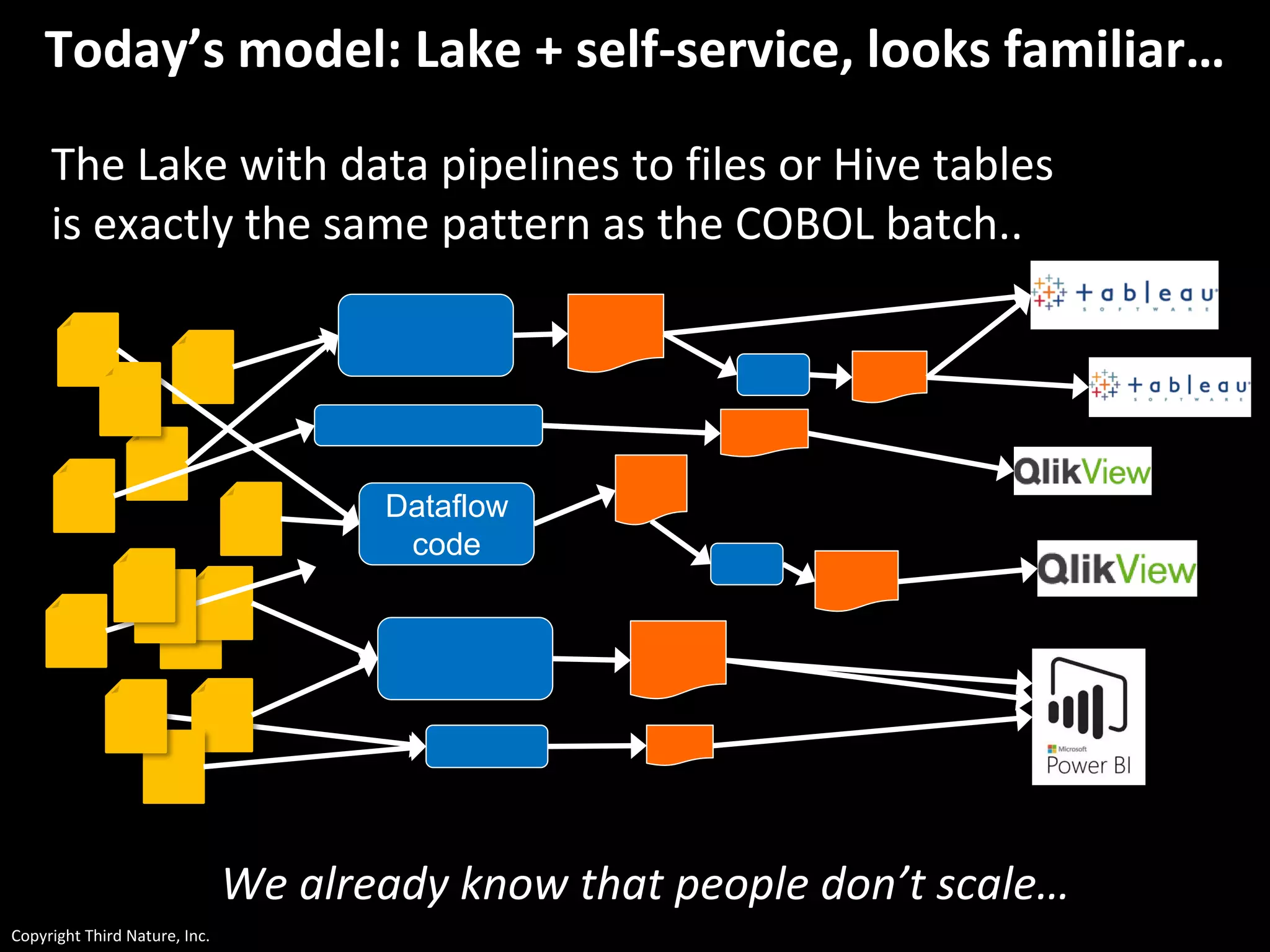


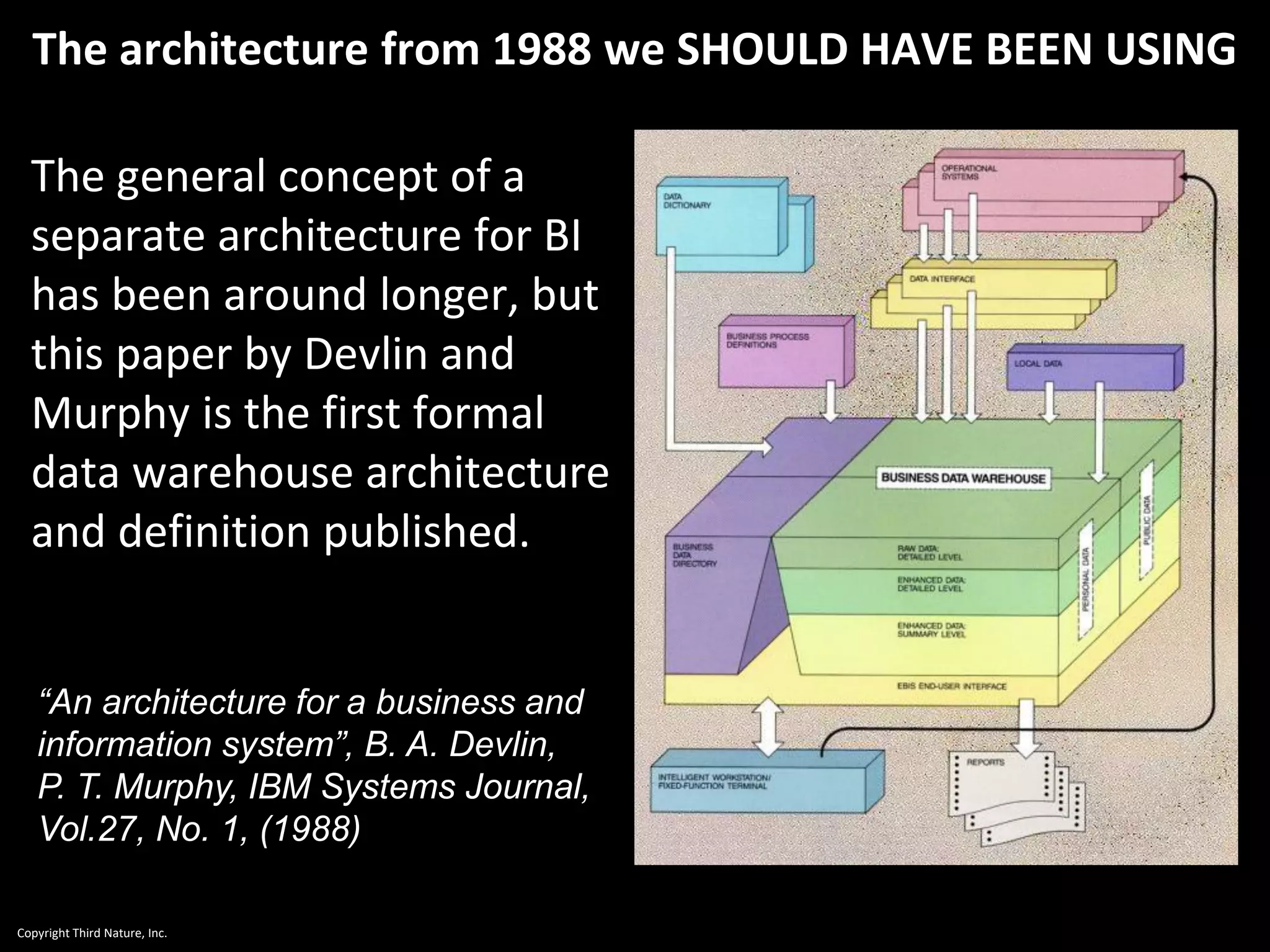
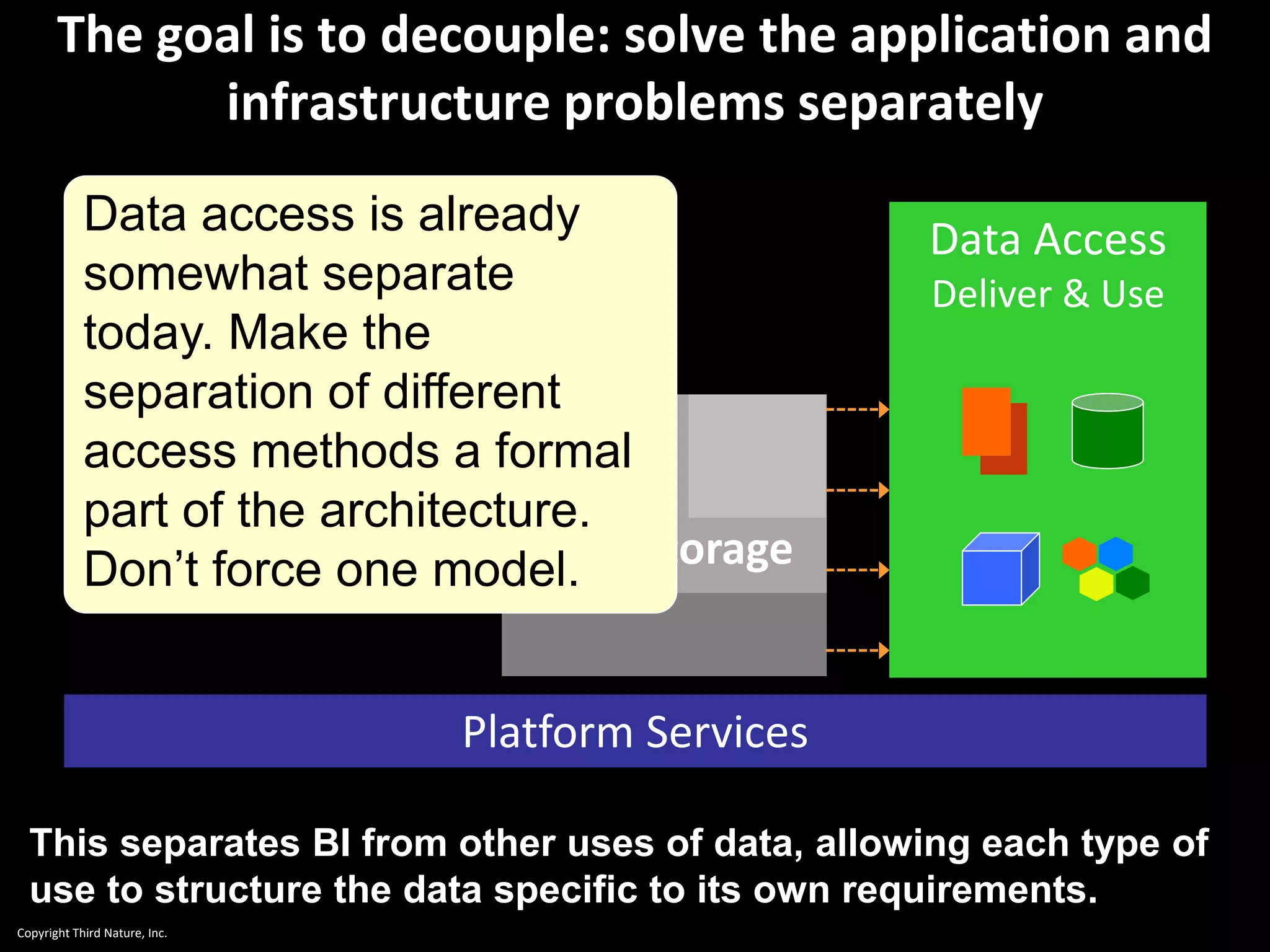
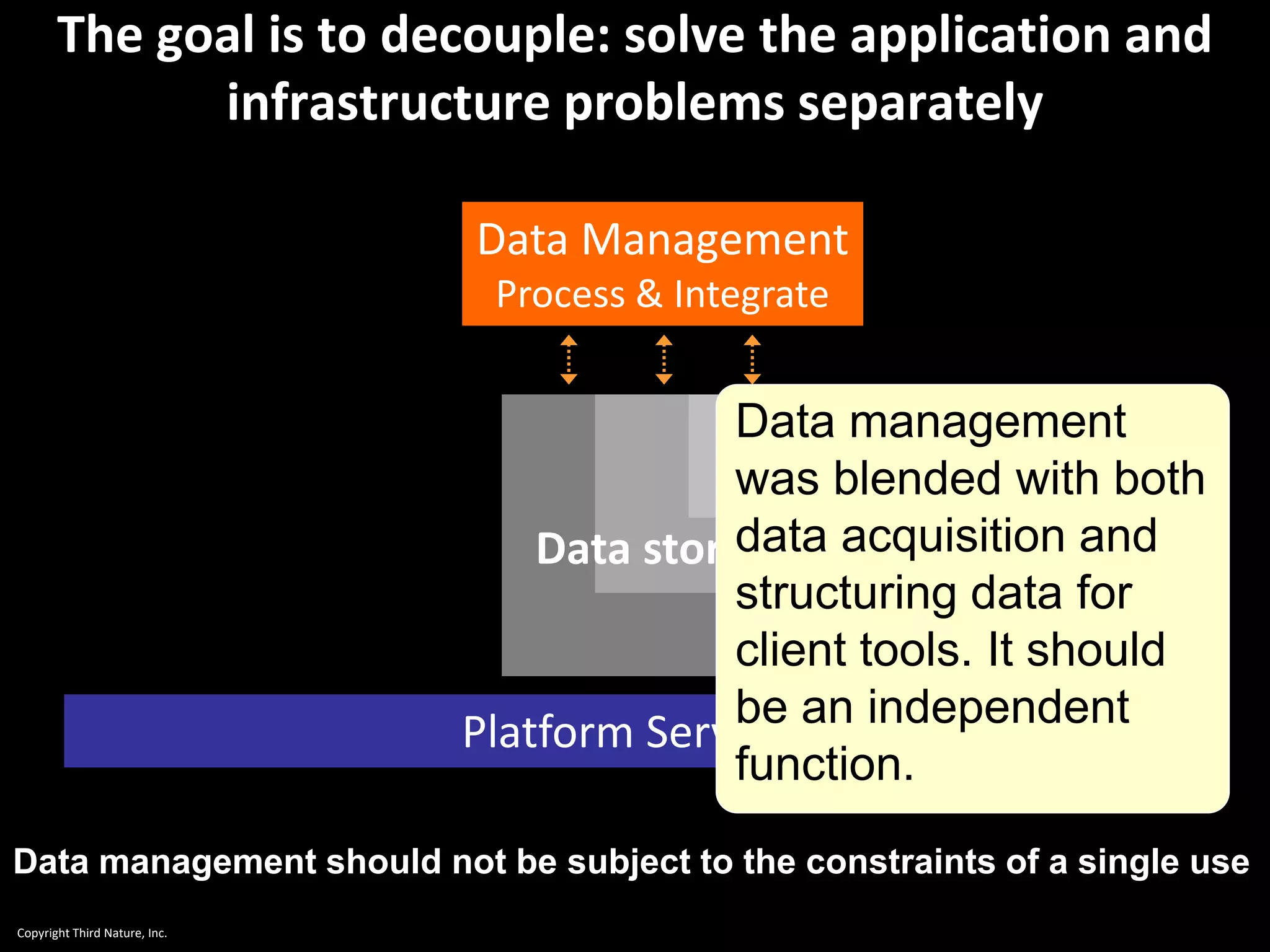
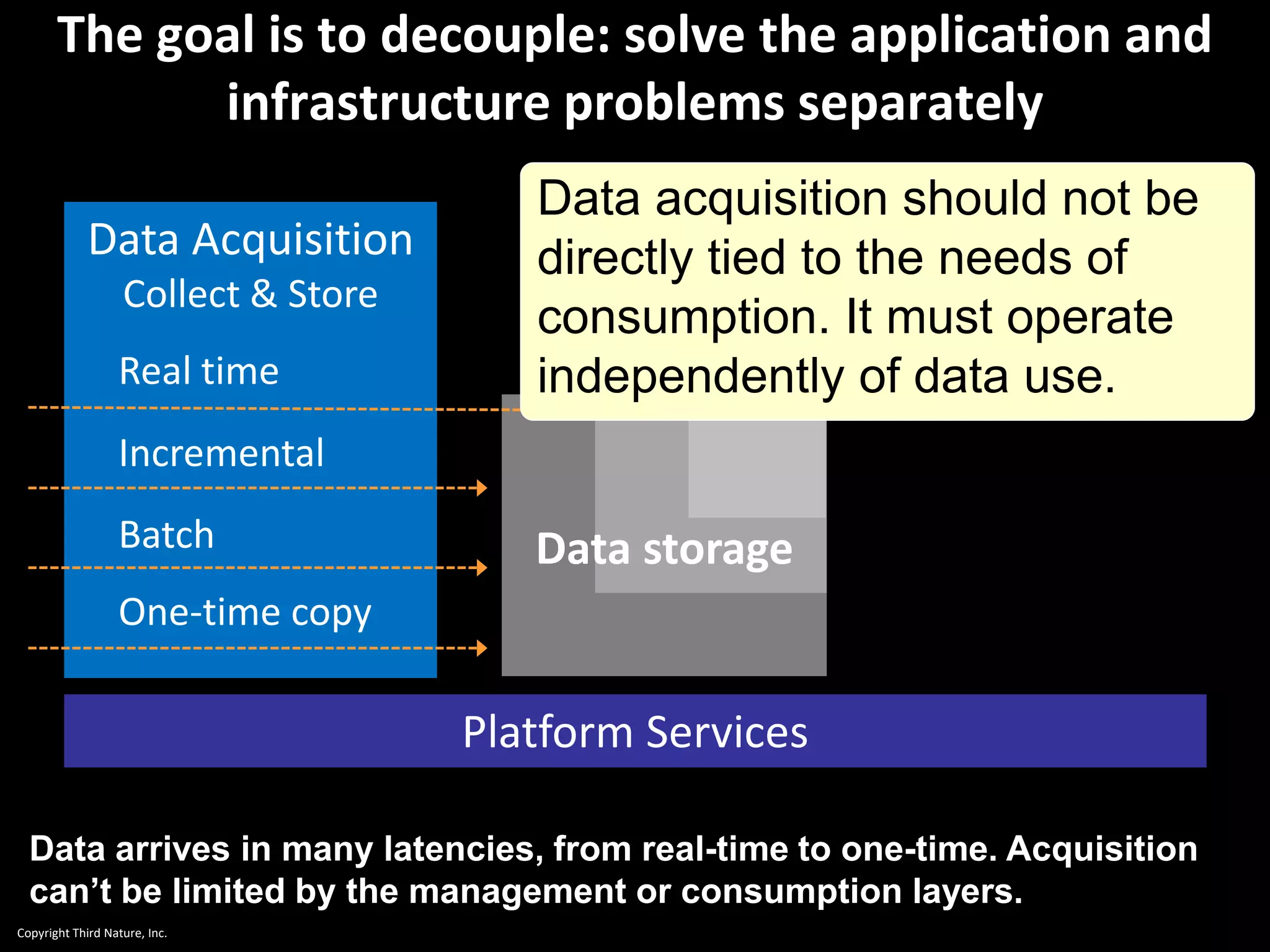
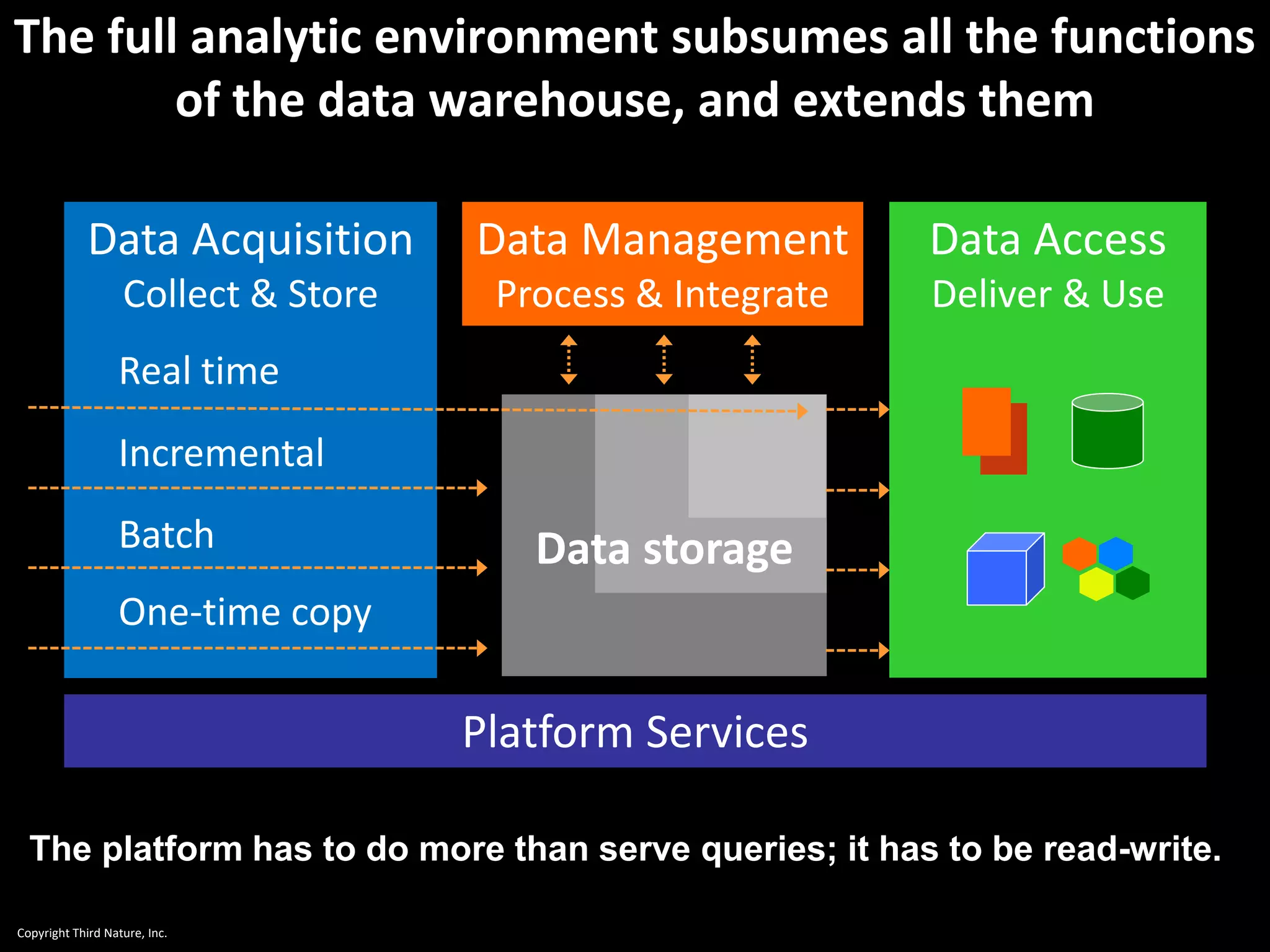
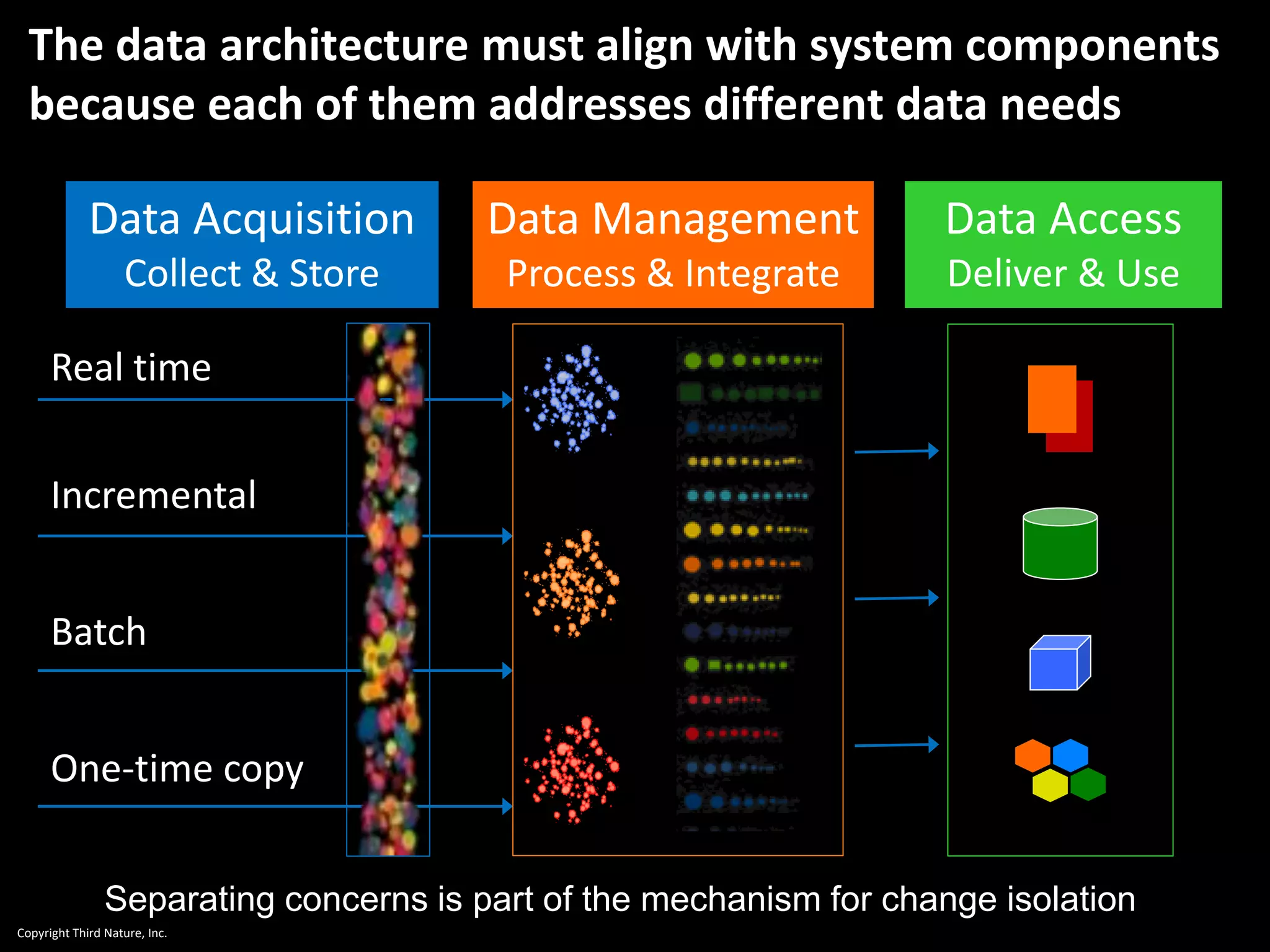

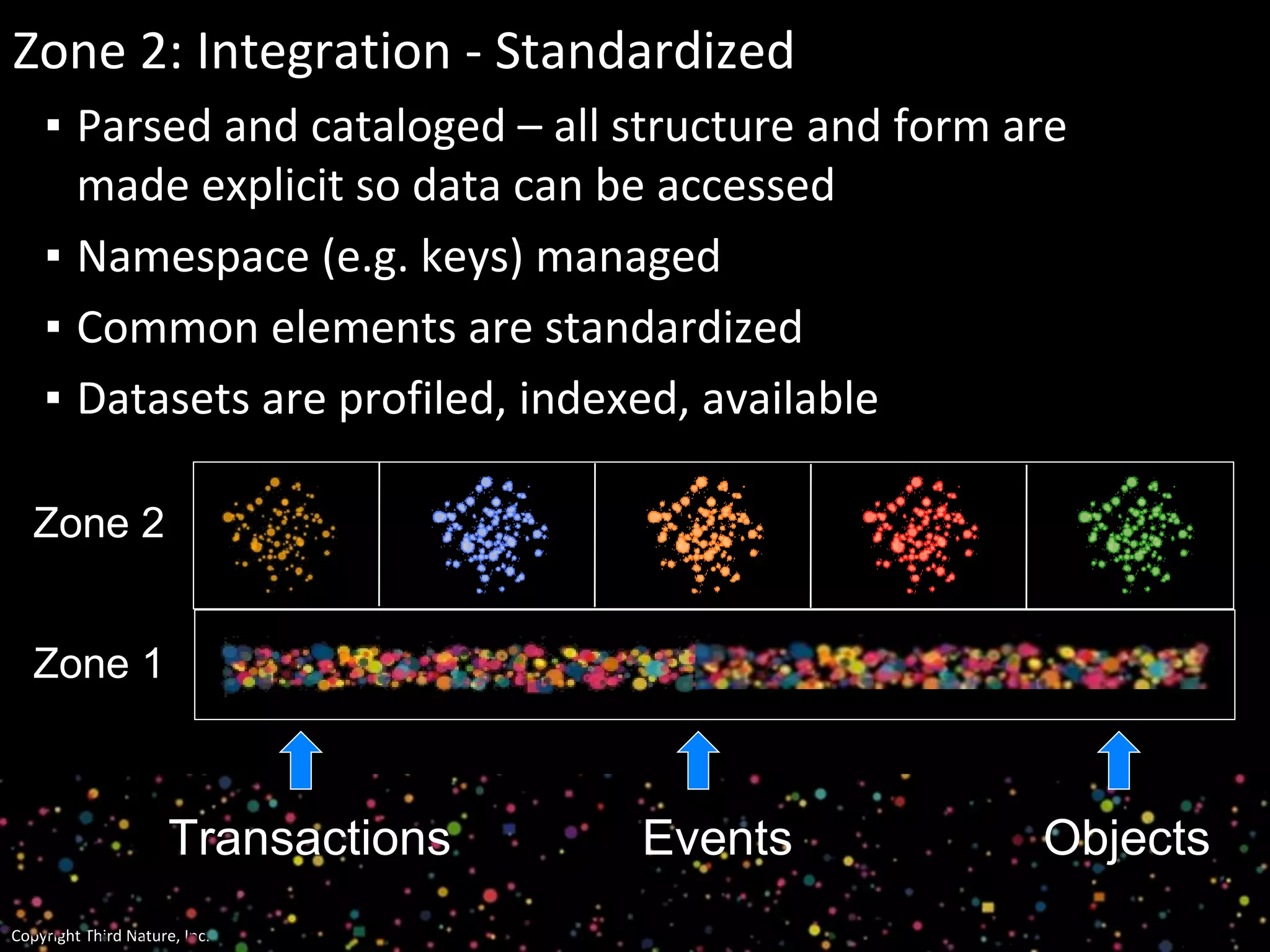
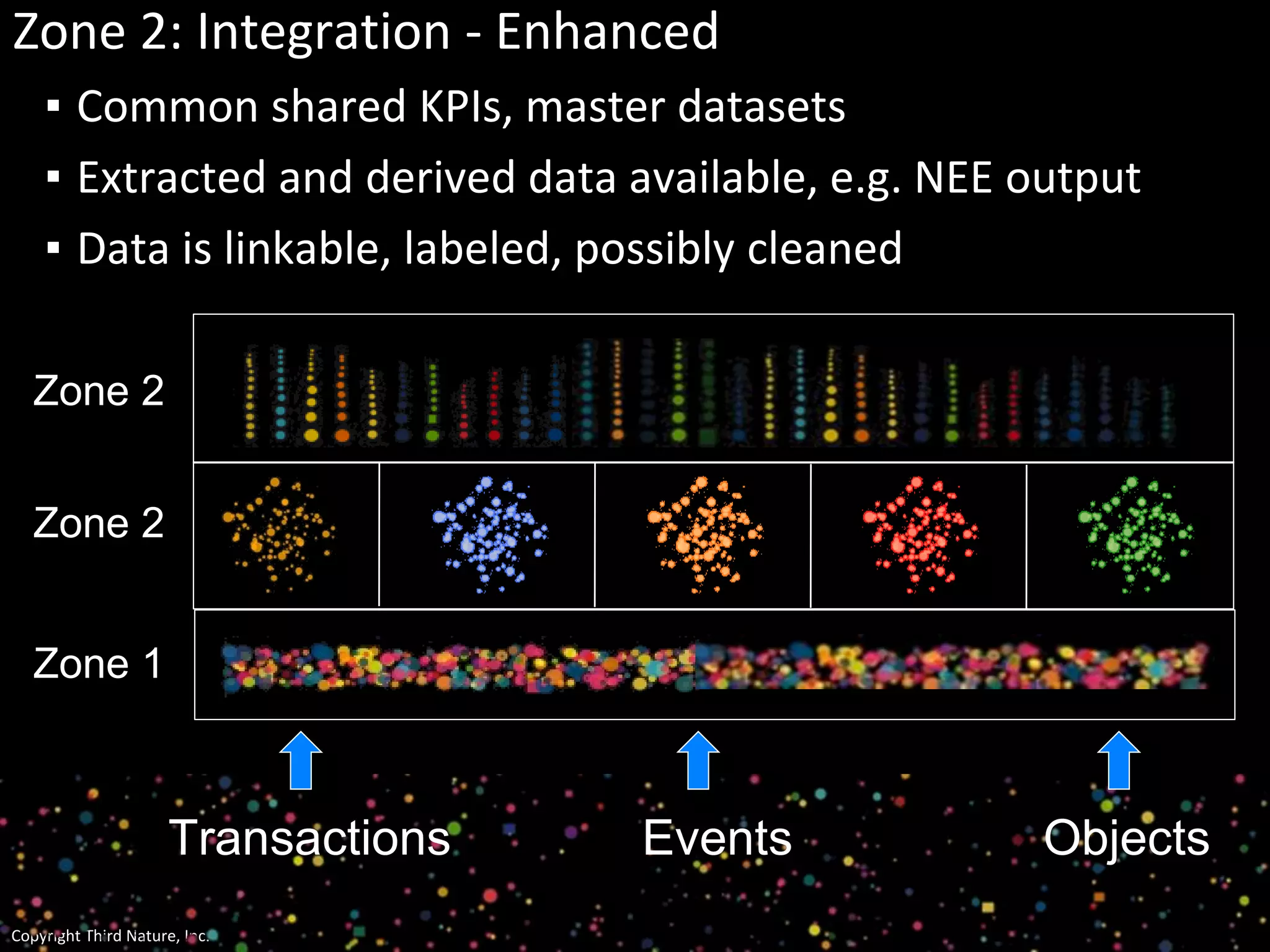
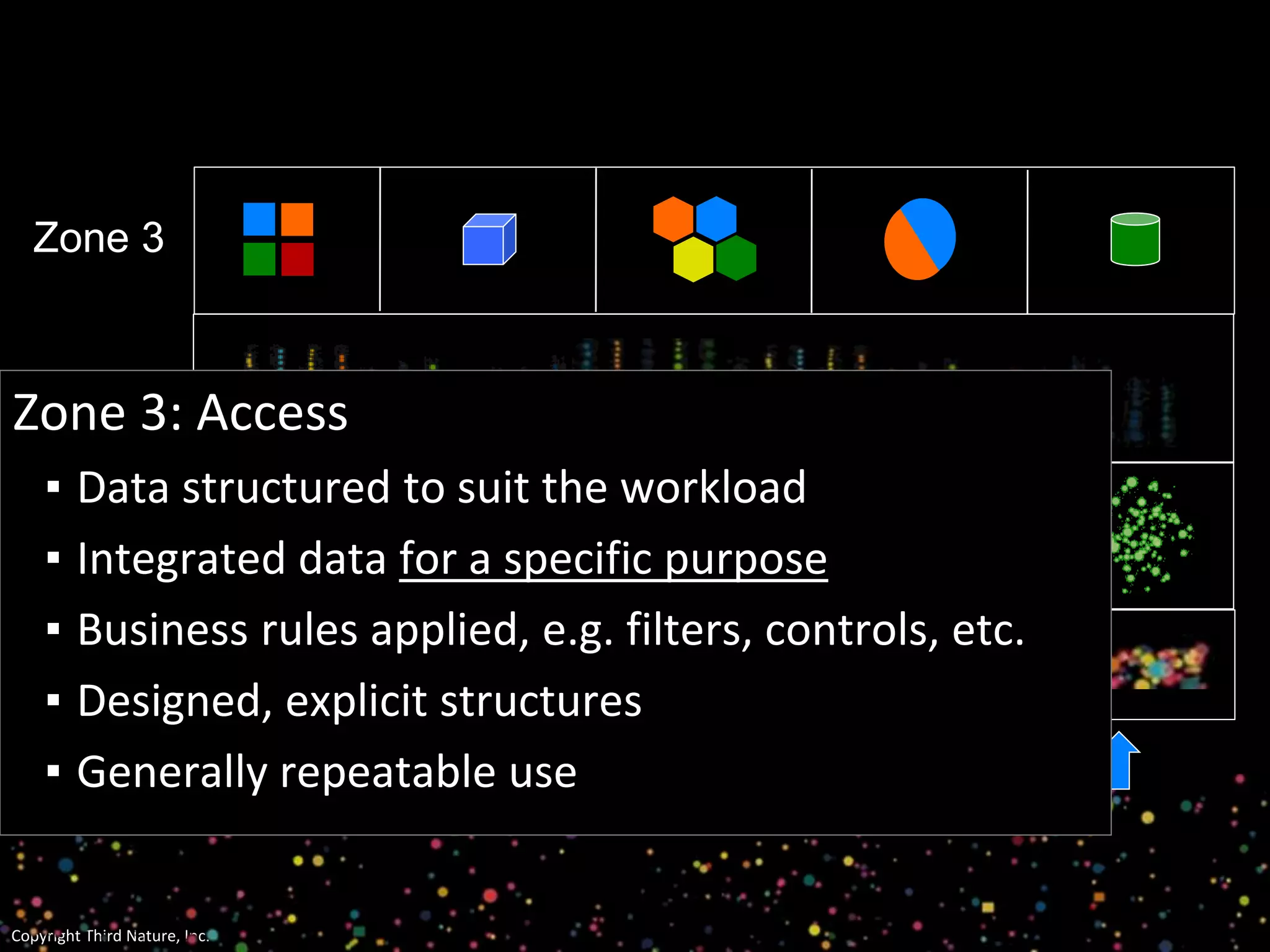
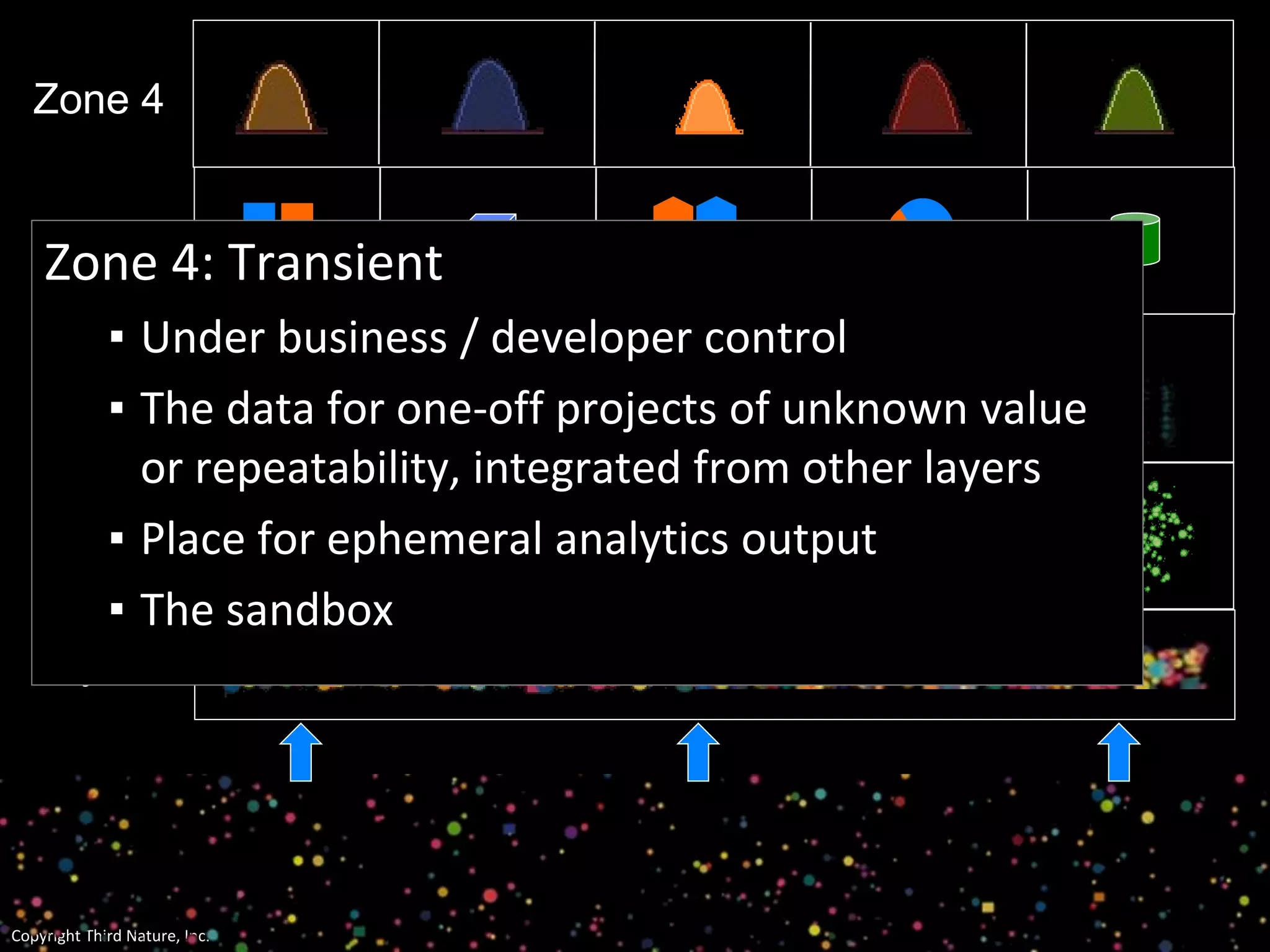
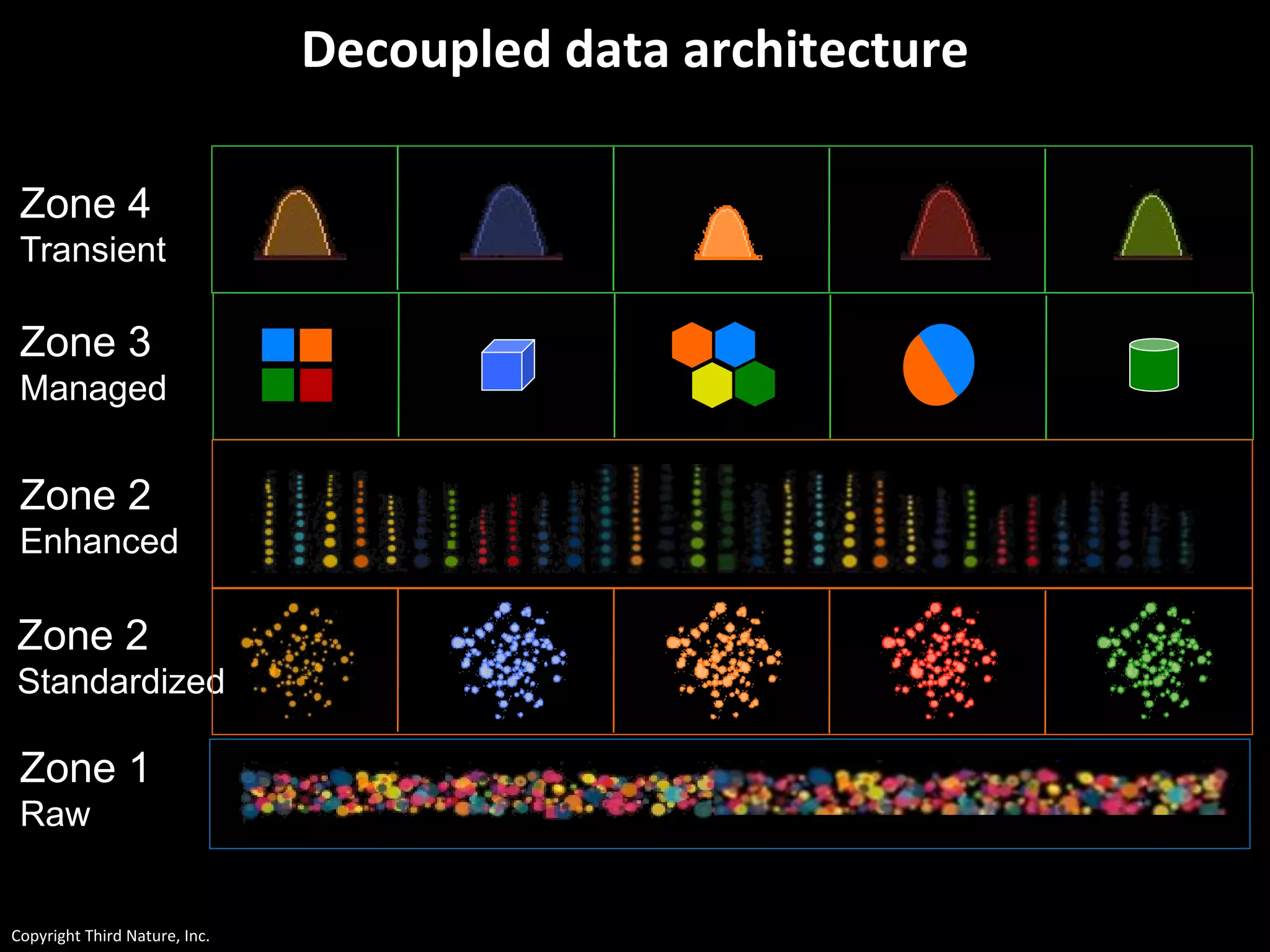

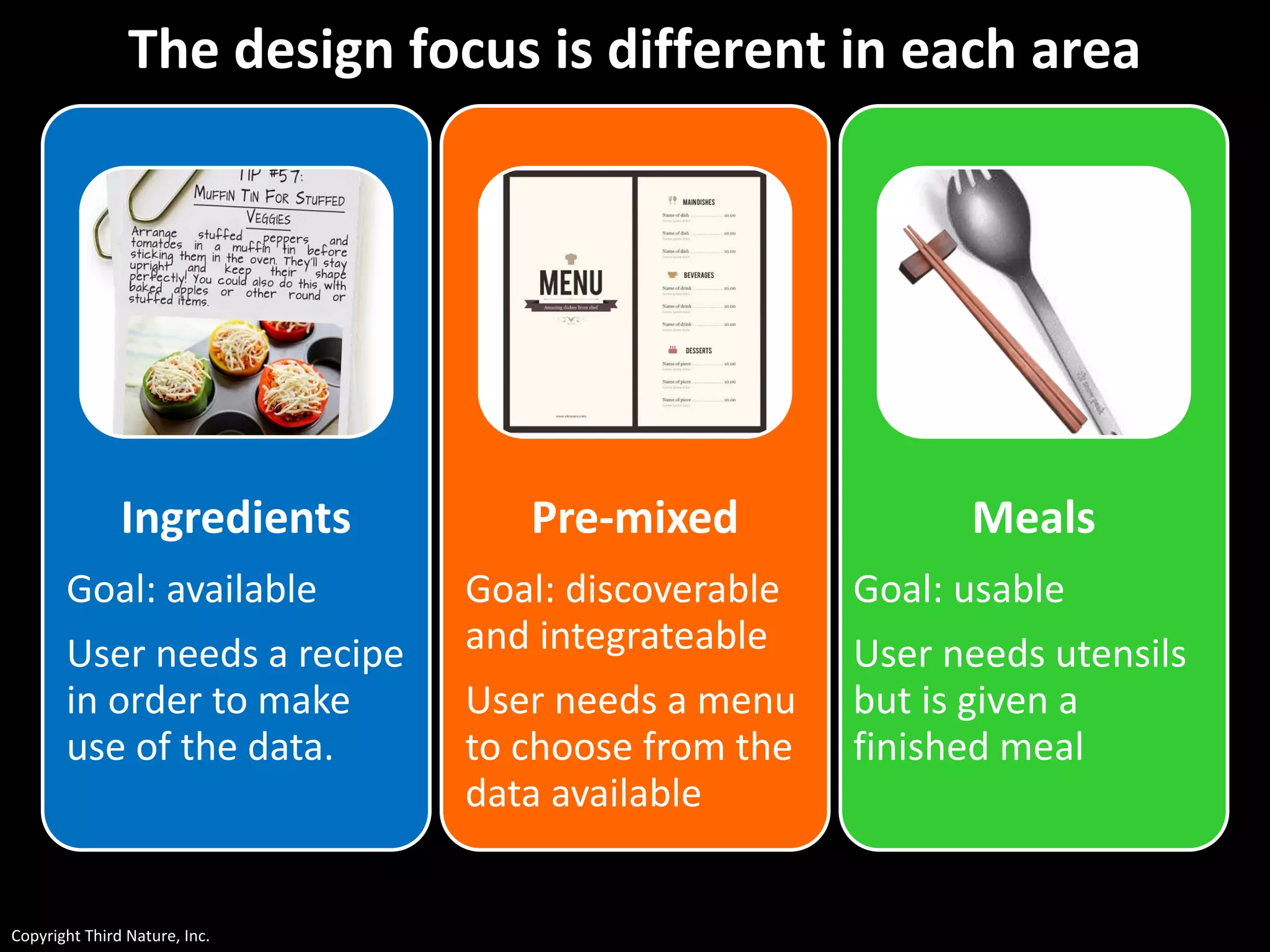
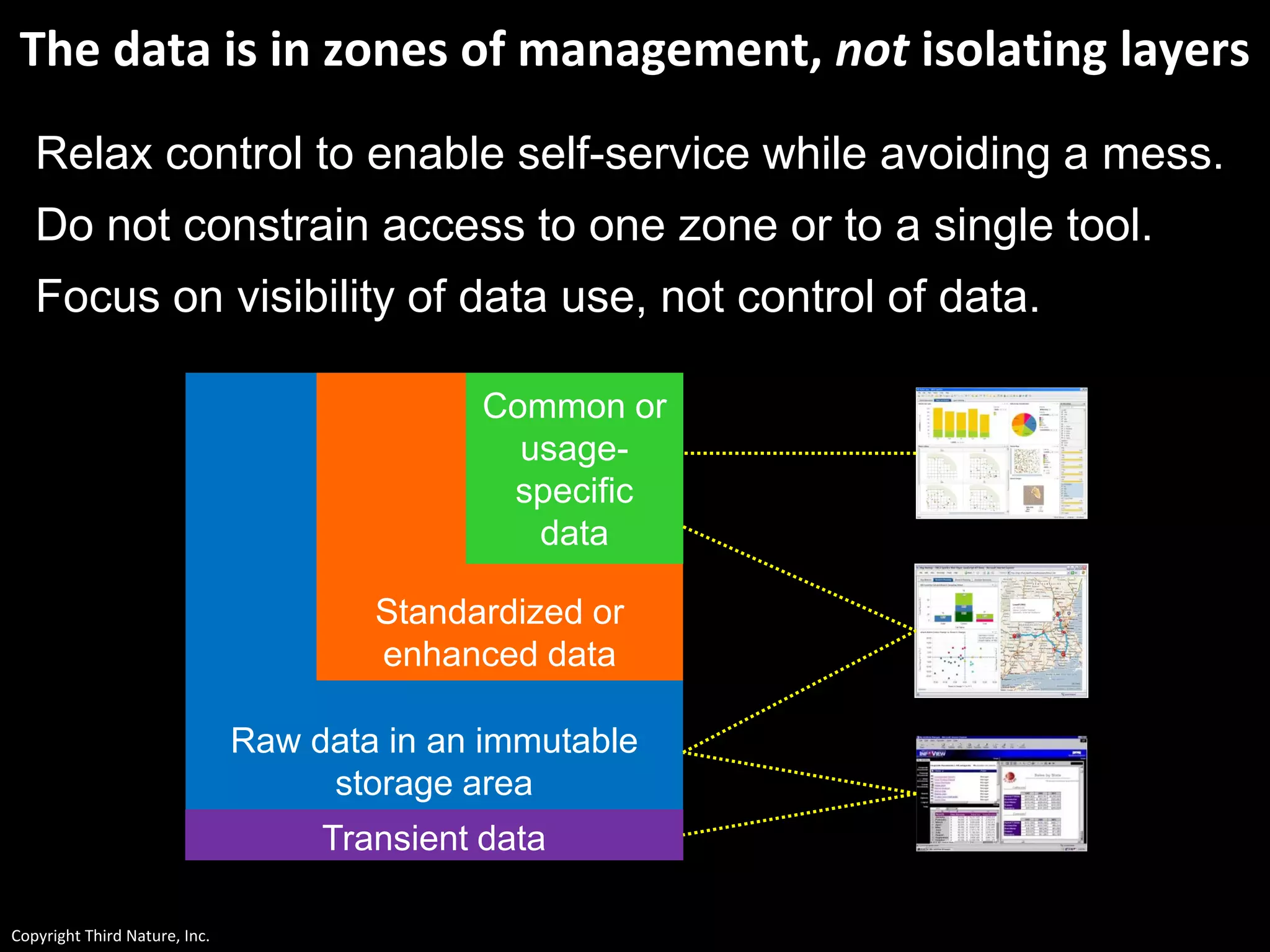
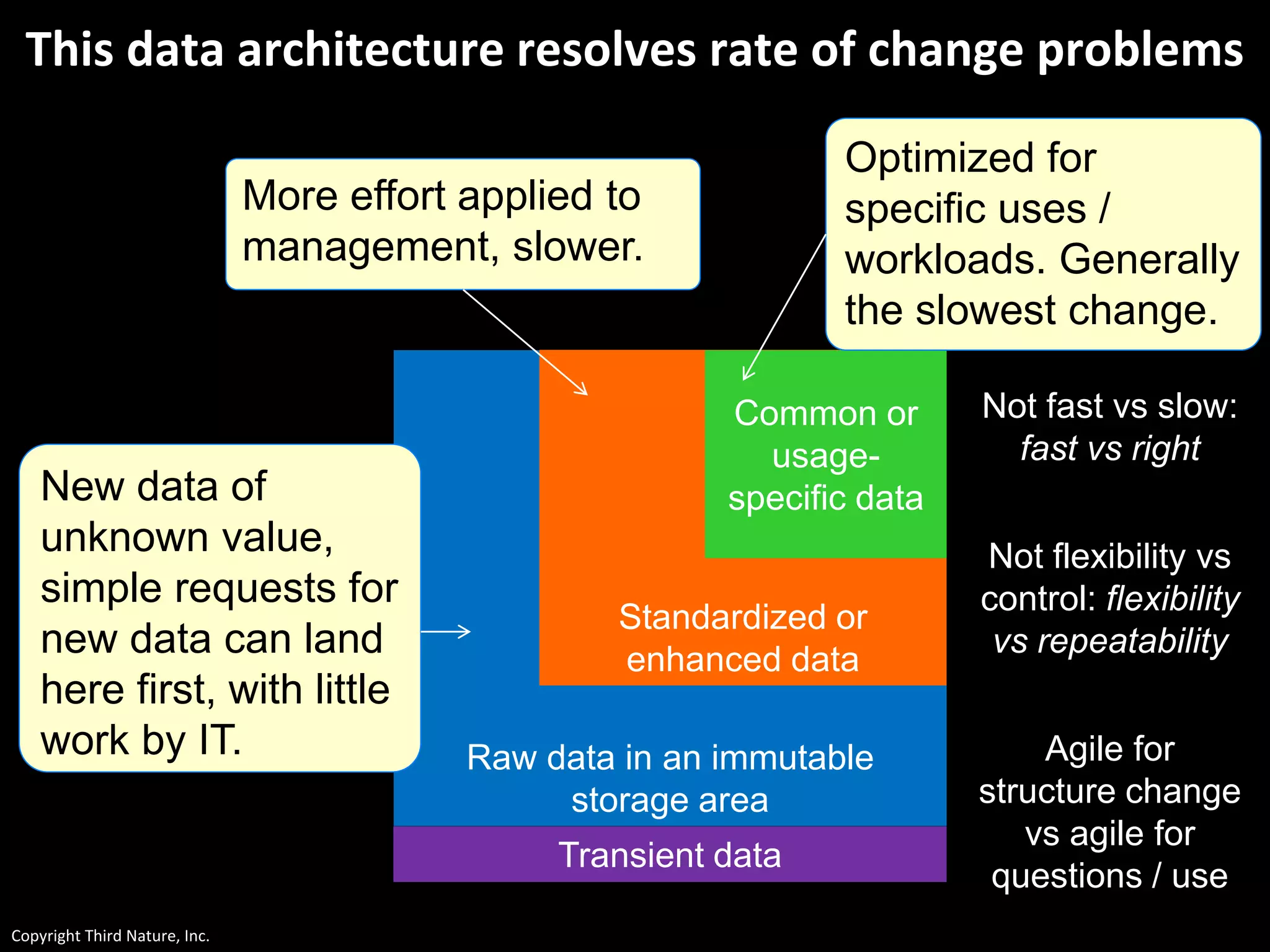
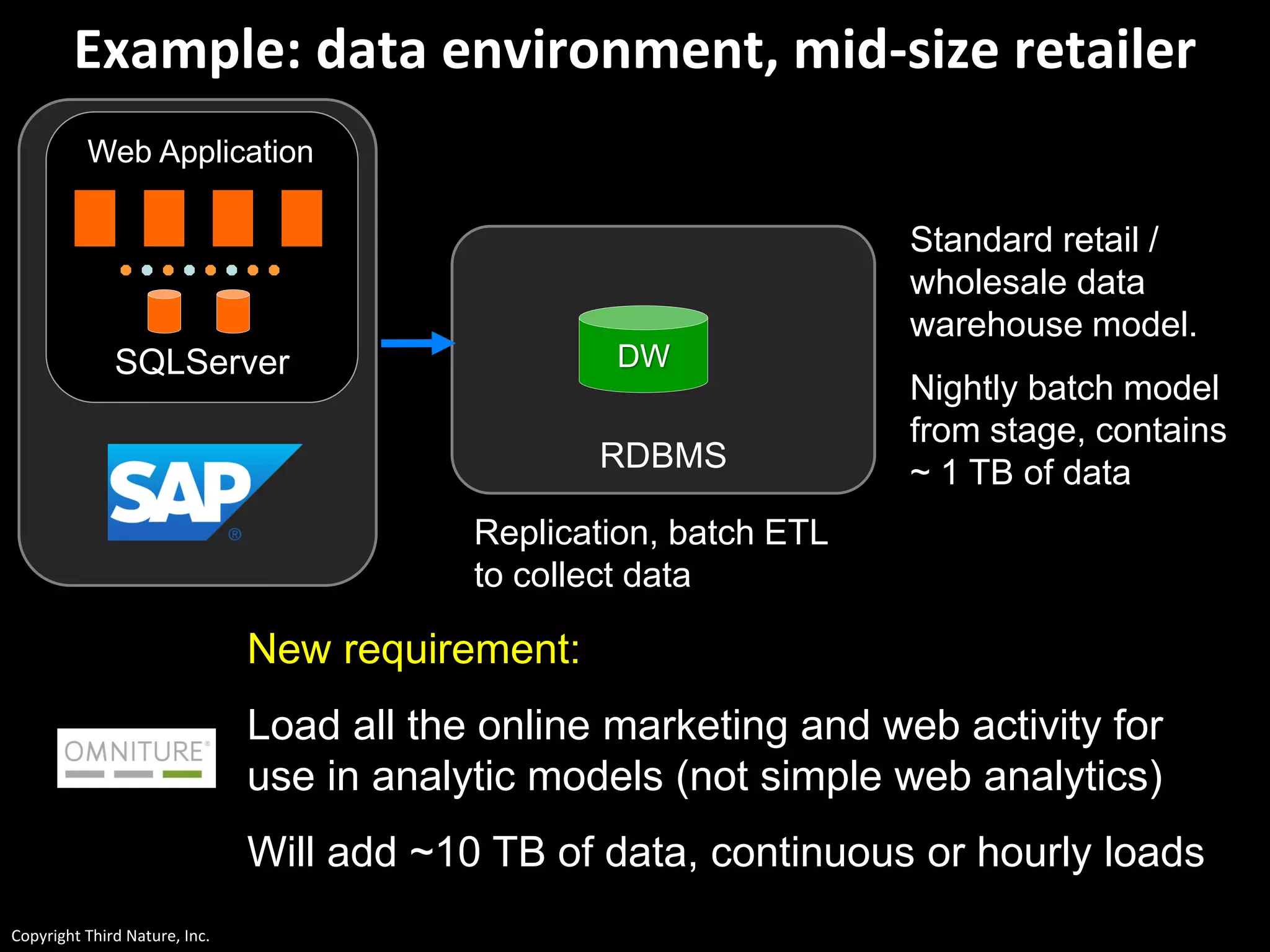
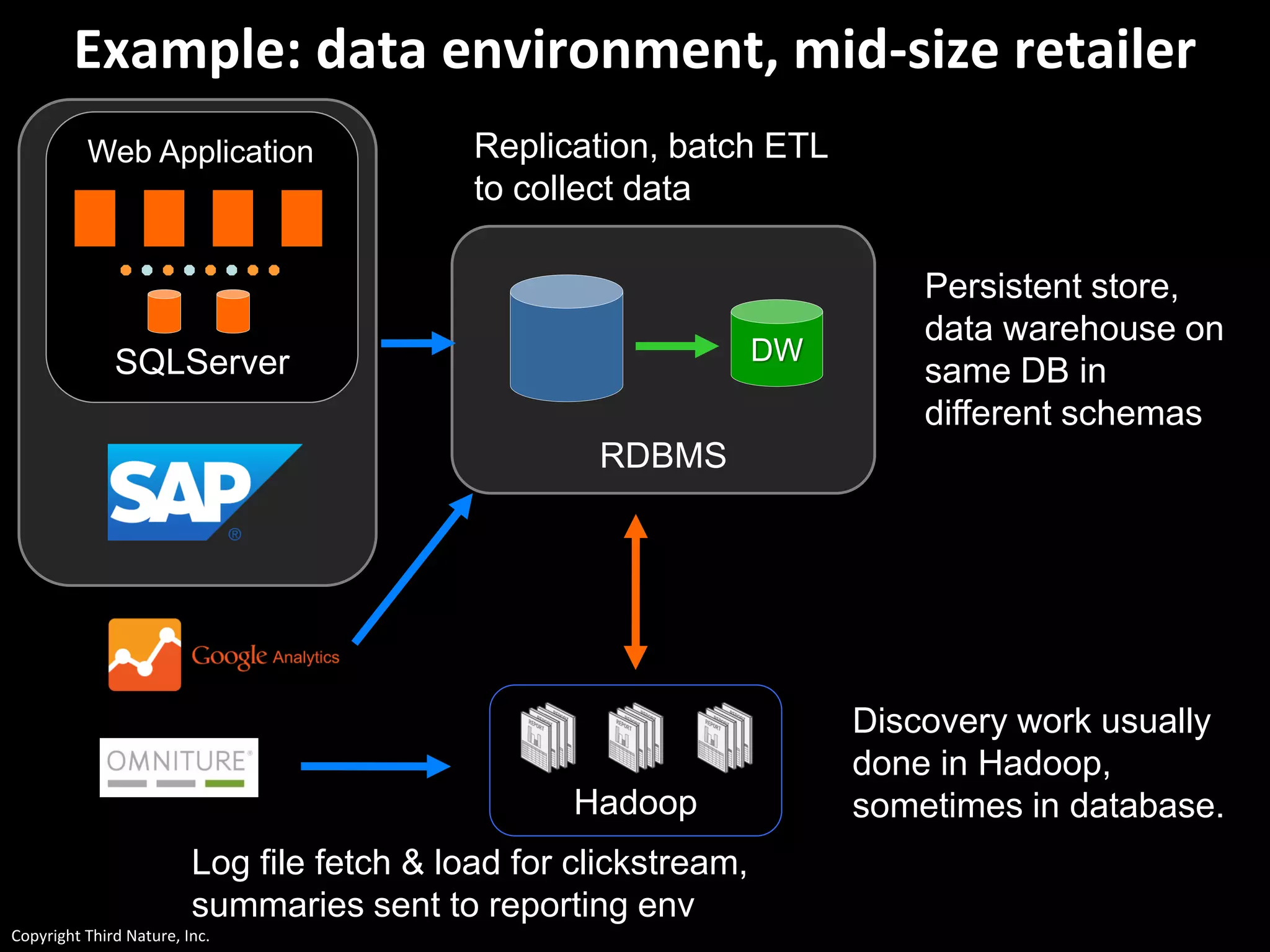
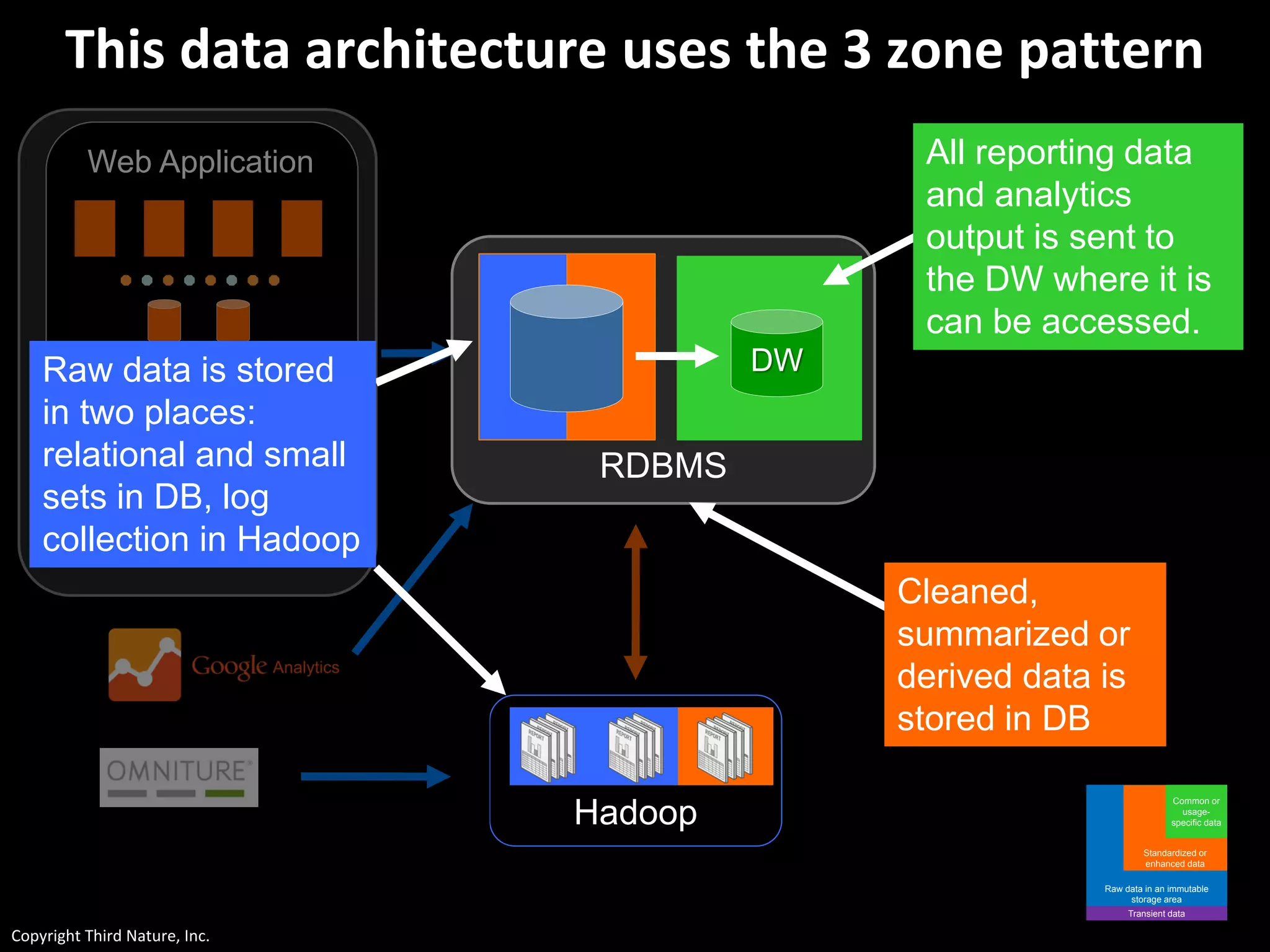
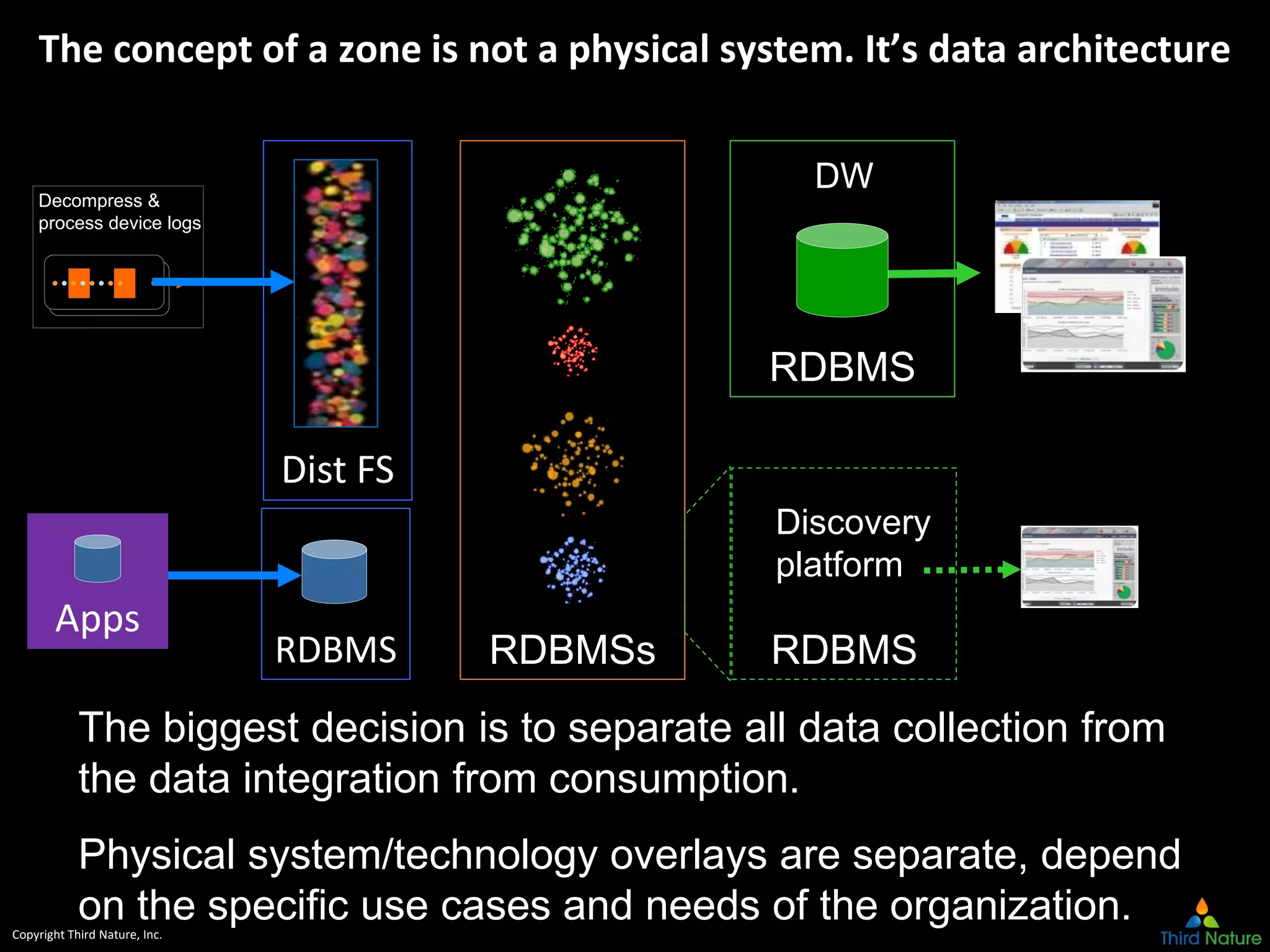

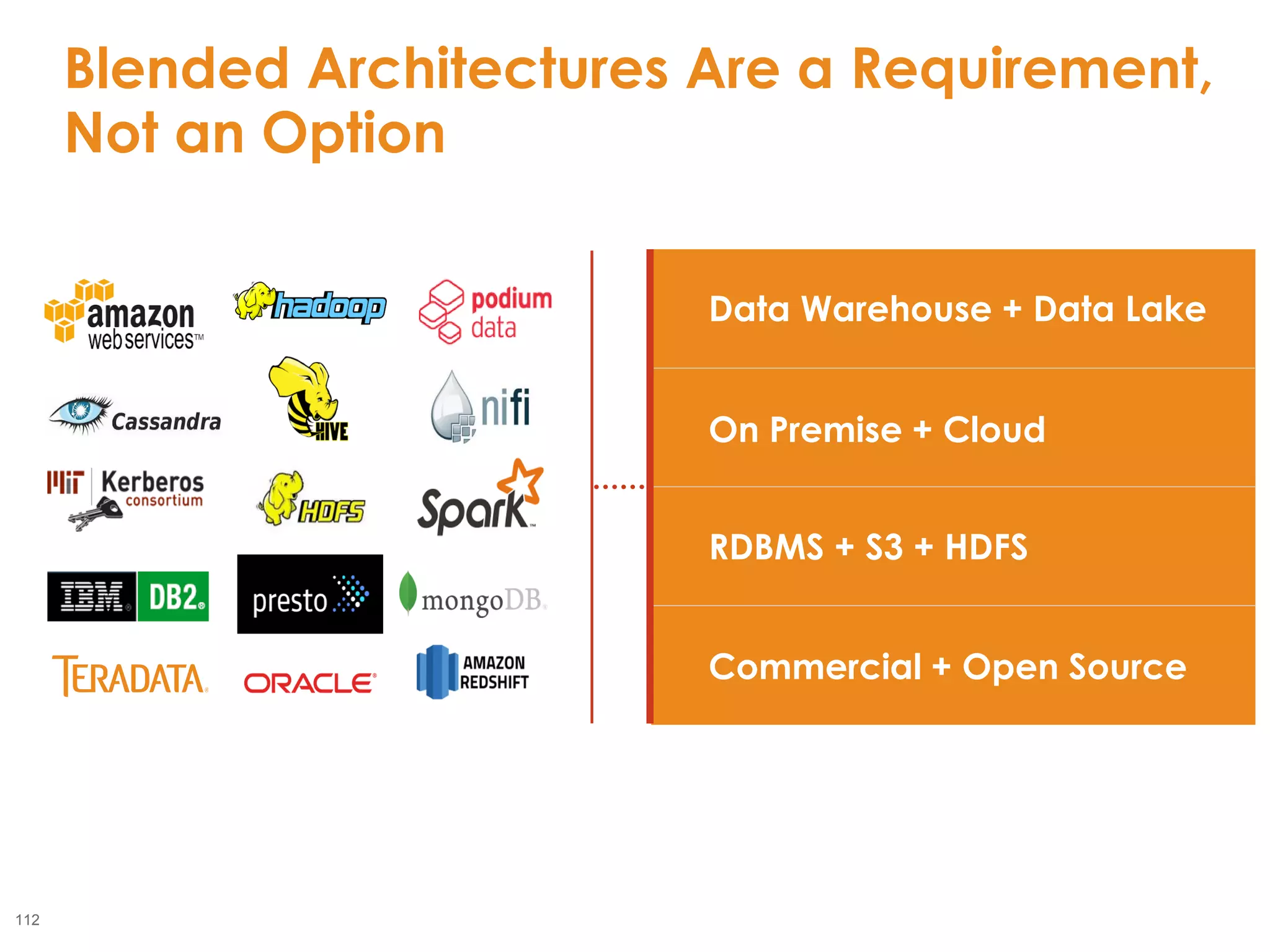


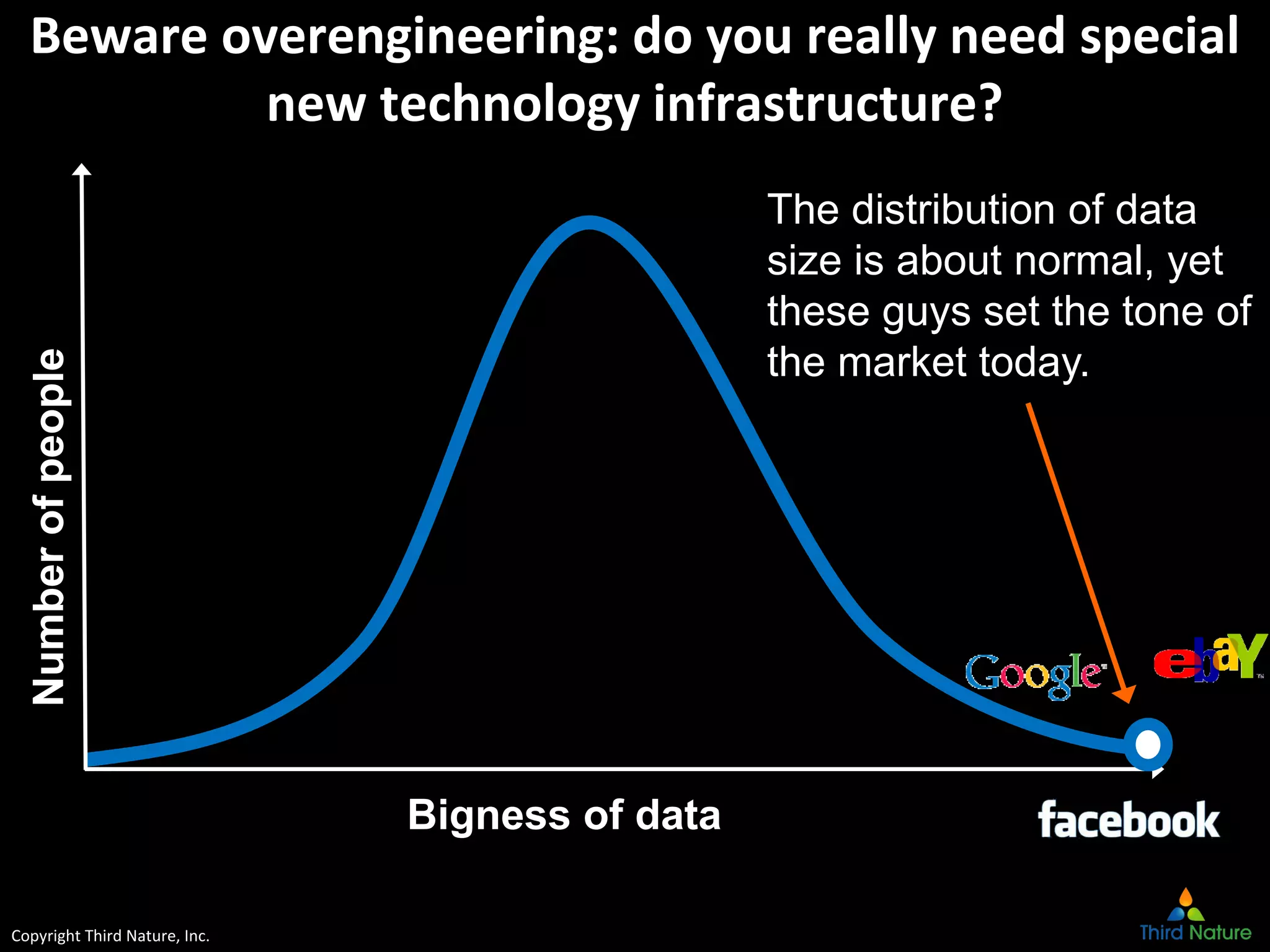
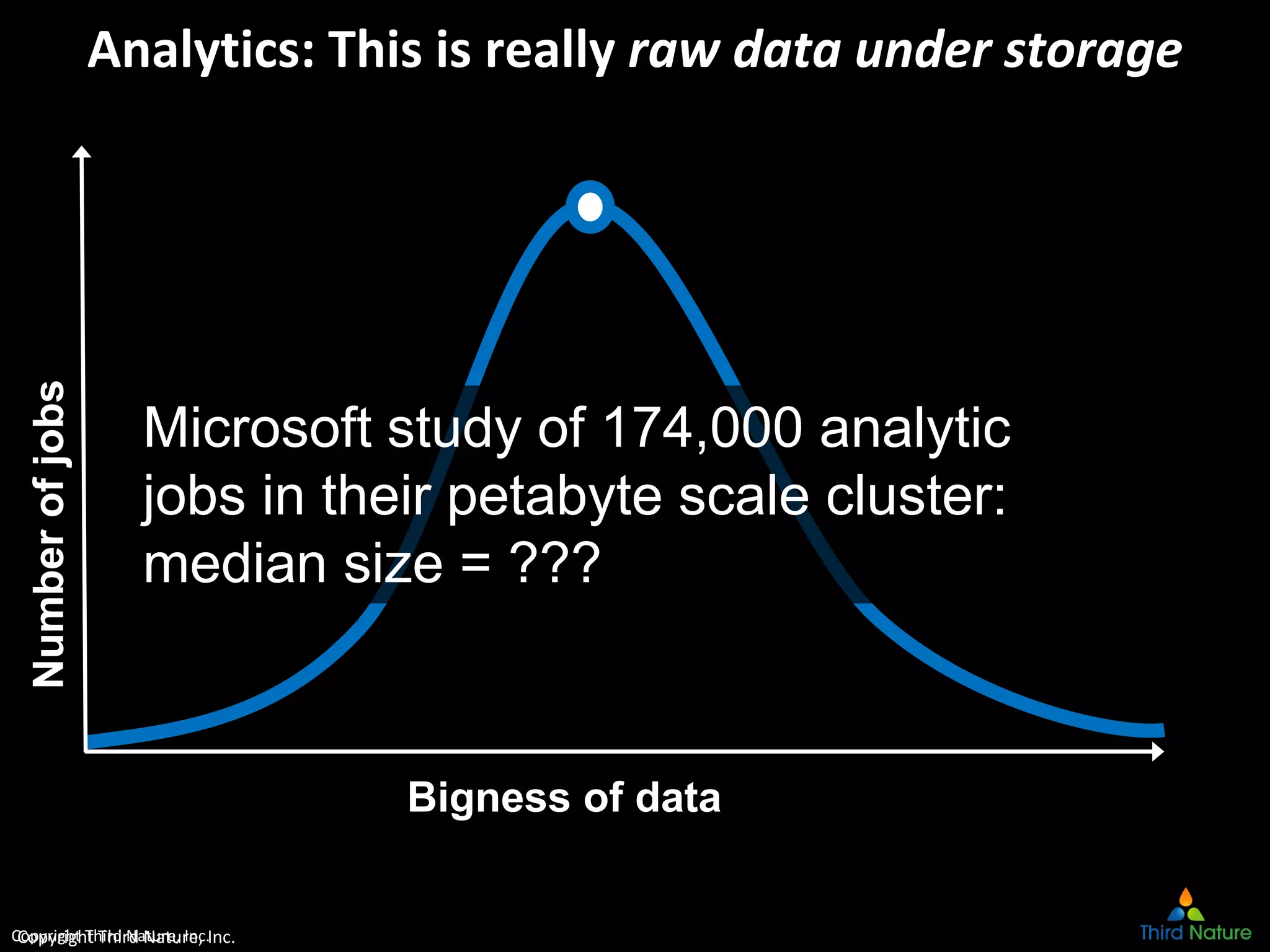
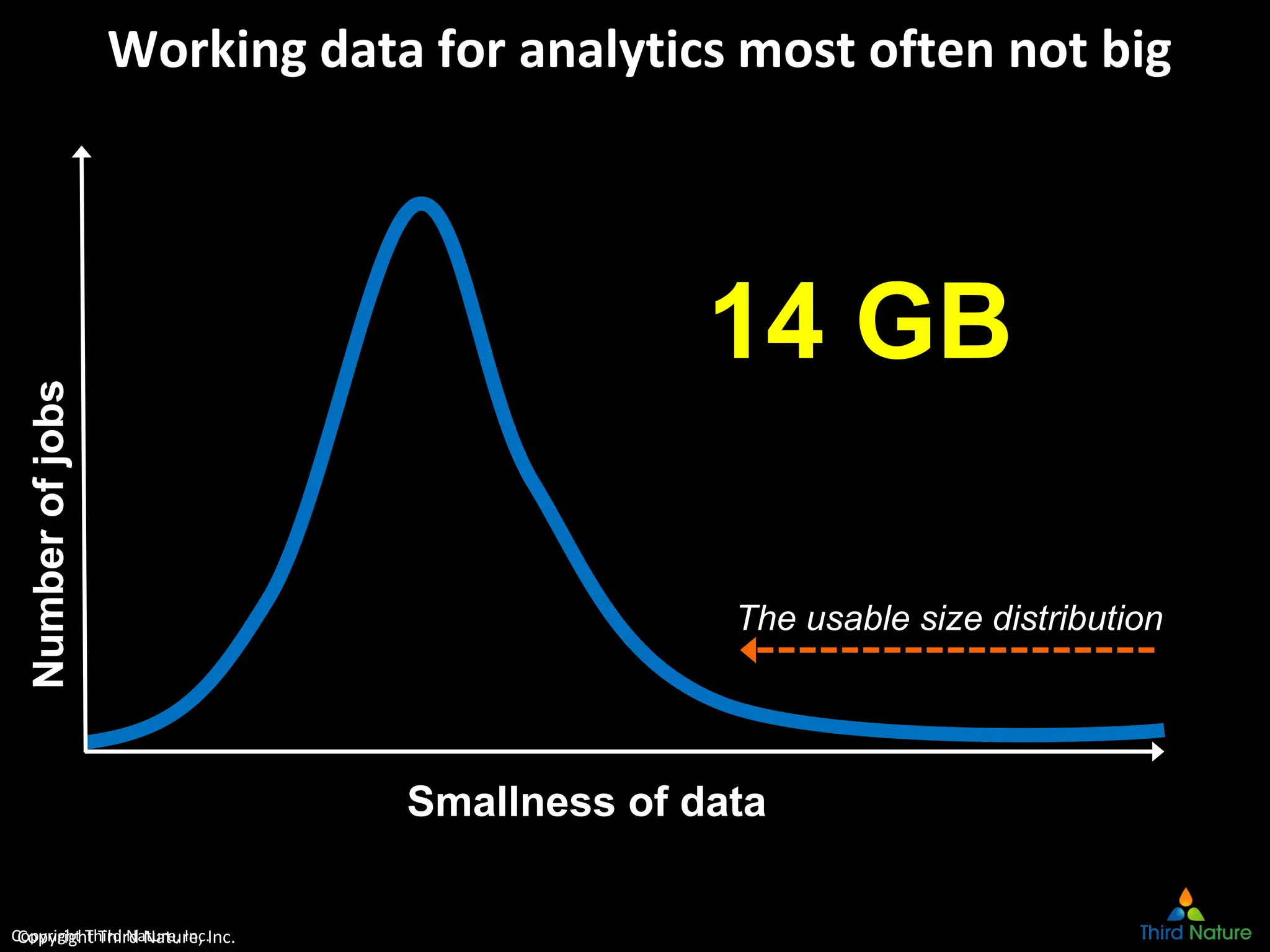







The document outlines the challenges enterprises face in data and analytics, identifying root causes like outdated infrastructure, lack of agility, and inefficient processes. It emphasizes the need for a robust data architecture rather than just technological solutions and stresses the importance of beginning analytics strategies with stakeholder needs. Additionally, it discusses the perspectives of various constituencies involved in analytics, the complexities of managing data, and the necessity of a system of record for operational analytics.






























































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)



