Download as PDF, PPTX







![Unsupervised learning
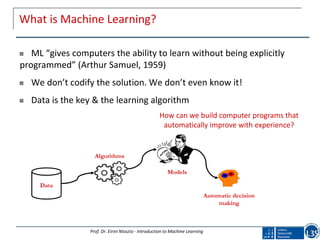
Unsupervised learning/ Descriptive:
Only a description of the instances is available
No feedback/labels are available
The goal is to discover groups of similar instances
Typical examples: clustering, association rules, outlier detection
Prof. Dr. Eirini Ntoutsi - Introduction to Machine Learning
Height[cm]
Width[cm]
Cluster 1Cluster 2
instance width height
1 2,6 4,5
2 3,7 7,3
3 4,1 6,5
4 8,5 8,1
5 9,5 5,5
… … …
nails paper clips](https://image.slidesharecdn.com/presentationeirinintoutsiama-181230141230/85/A-Machine-Learning-Primer-8-320.jpg)
![Supervised learning
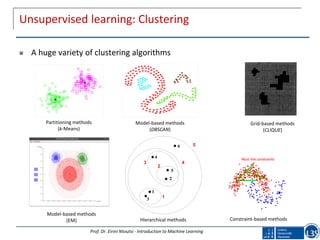
Supervised learning/ Predictive:
A description of the instances and their class labels is available
(training set)
The goal is to learn a mapping from the instances to the class labels,
i.e., given a future unseen instance to predict its class label
Typical examples: classification, regression, outlier detection
Prof. Dr. Eirini Ntoutsi - Introduction to Machine Learning
Screw
Nails
Paper clips
New object
Height[cm]
Width[cm]
New object
instance width height class
1 2,6 4,5 A
2 3,7 7,3 A
3 4,1 6,5 A
4 8,5 8,1 B
5 9,5 5,5 B
… … … …](https://image.slidesharecdn.com/presentationeirinintoutsiama-181230141230/85/A-Machine-Learning-Primer-10-320.jpg)




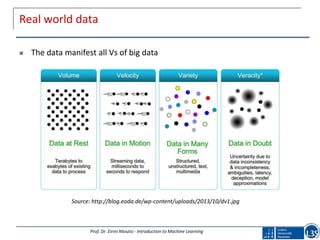

![Tackling the traditional restrictive ML assumptions
The myth: data is stationary
The reality:
Data are collected over time and their characteristics
might change data streams
Goal: maintain valid models of the population
Related ML areas:
stream mining, adaptive ML
Prof. Dr. Eirini Ntoutsi - Introduction to Machine Learning
1
0
1
1
1
0
1
0
0
1
1
[Zhang et al, Journal Neurocomputing 2012]](https://image.slidesharecdn.com/presentationeirinintoutsiama-181230141230/85/A-Machine-Learning-Primer-19-320.jpg)
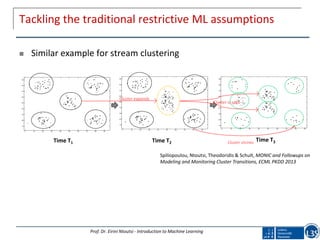



This document provides an introduction to machine learning, including definitions of key concepts like supervised vs. unsupervised learning. It discusses traditional machine learning assumptions like having fully labeled small datasets and stationary data. However, it notes real-world data often has huge amounts of unlabeled or streaming data. It emphasizes tackling these challenges with approaches like semi-supervised learning and stream mining. Overall, the document aims to give an overview of machine learning tasks and algorithms, highlighting the need to select the right methods for problems while working with domain experts on complex real-world data.
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











