Download to read offline



















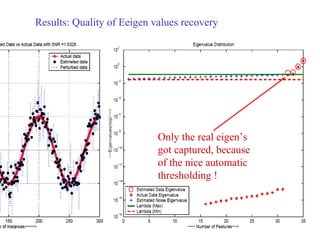




This document summarizes a research paper about random data perturbation techniques used to preserve privacy while still allowing useful data mining. It discusses how simply anonymizing records is not truly private, as the data can be re-identified by linking anonymous records to other publicly available information. The paper presents techniques like adding small random perturbations to the data or distributing the data across parties. It evaluates methods to recover distributions from perturbed data while preventing identification of individual records. Spectral filtering is proposed to separate noise from original data by exploiting properties of random matrices.


































































