Downloaded 12 times








![01/09/15
13
Functional Dependencies (Cont.)
• Let R be a relation schema
α ⊆ R and β ⊆ R
• The functional dependency
α → β
holds on R if and only if for any legal relations r(R), whenever
any two tuples t1 and t2 of r agree on the attributes α, they also
agree on the attributes β. That is,
t1[α] = t2 [α] ⇒ t1[β ] = t2 [β ]
• Example: Consider r(A,B ) with the following instance of r.
• On this instance, A → B does NOT hold, but B → A does hold.
1 4
1 5
3 7](https://image.slidesharecdn.com/6-normalization-150109084522-conversion-gate01/85/6-normalization-13-320.jpg)
















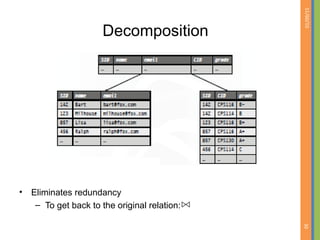











































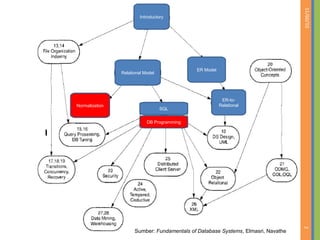
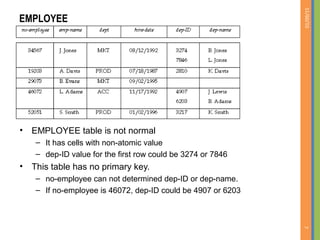
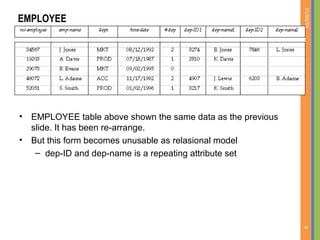
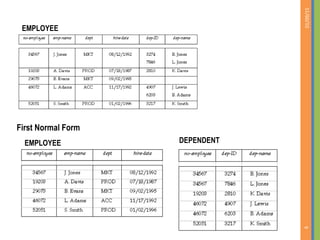
This document discusses database normalization and removing redundancy from database designs. It covers the concepts of functional dependencies, normal forms including first normal form, and decomposition. The key points covered are: - Normalization aims to remove redundancy from database designs to avoid issues like update anomalies. - Functional dependencies specify constraints on attribute values and are used to test for redundancy. - First normal form requires attributes to be atomic and indivisible. - Decomposition can break relations into smaller relations to remove redundancy, but it must be a lossless join decomposition to avoid loss of information.















































