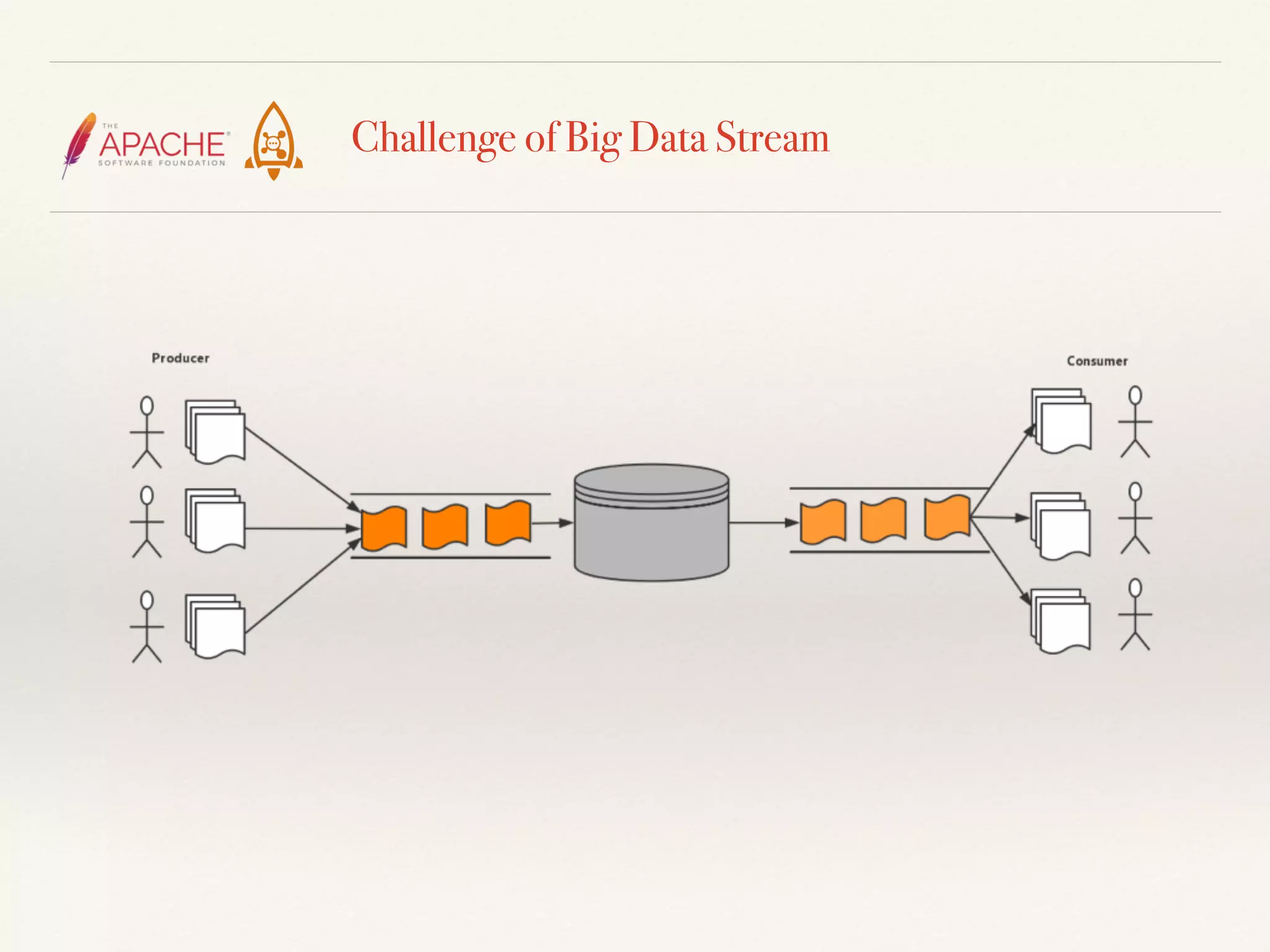
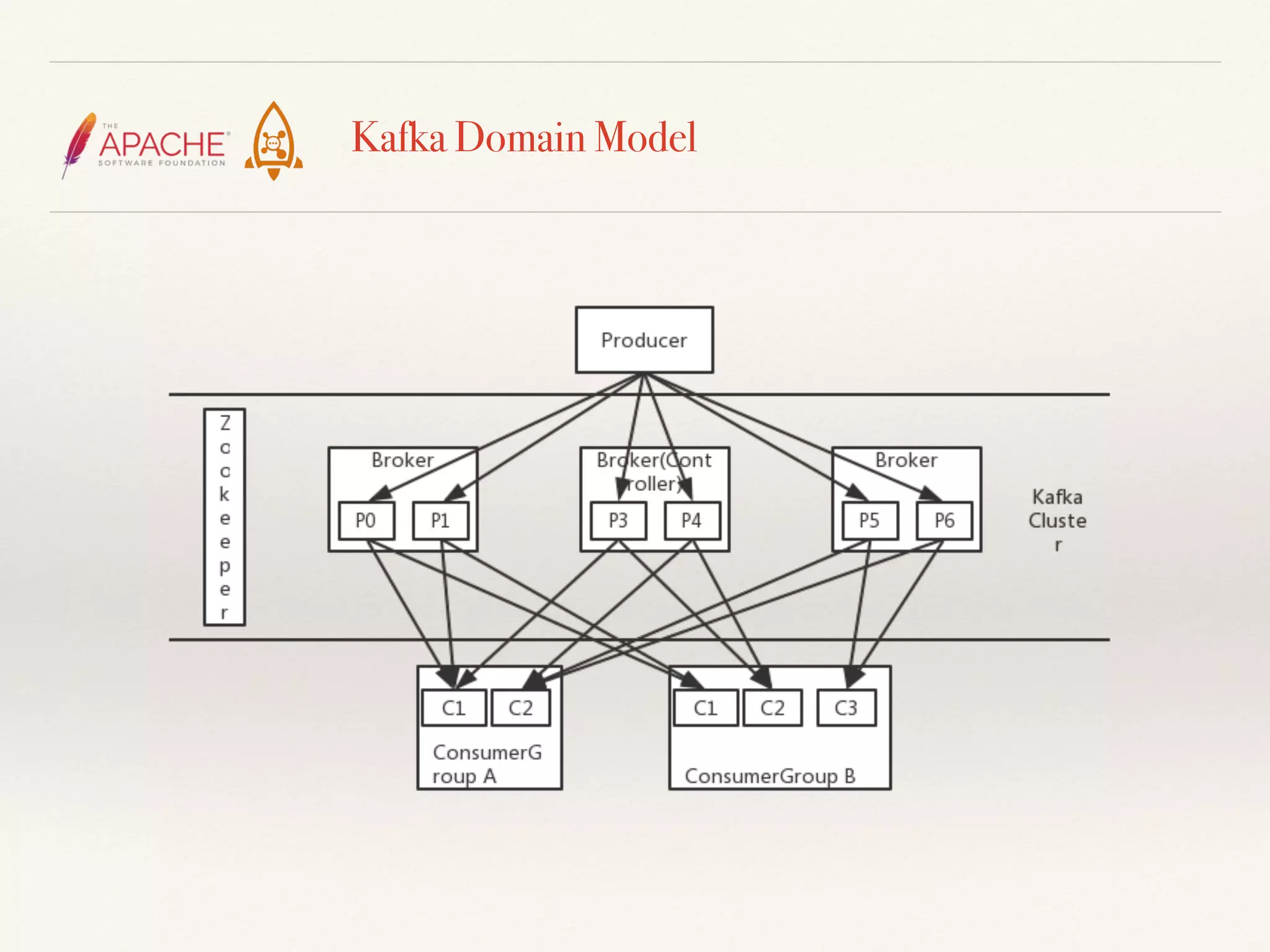
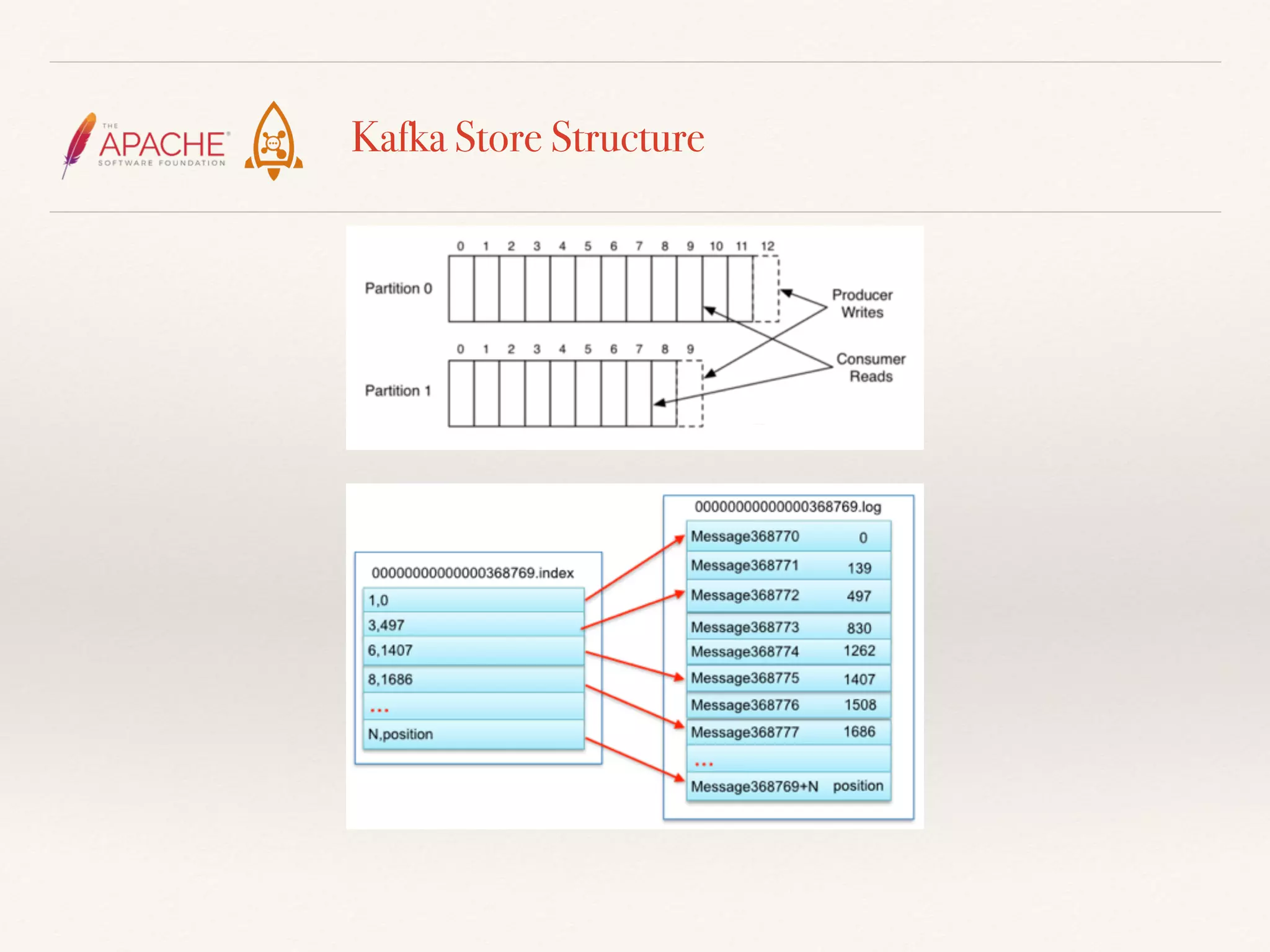
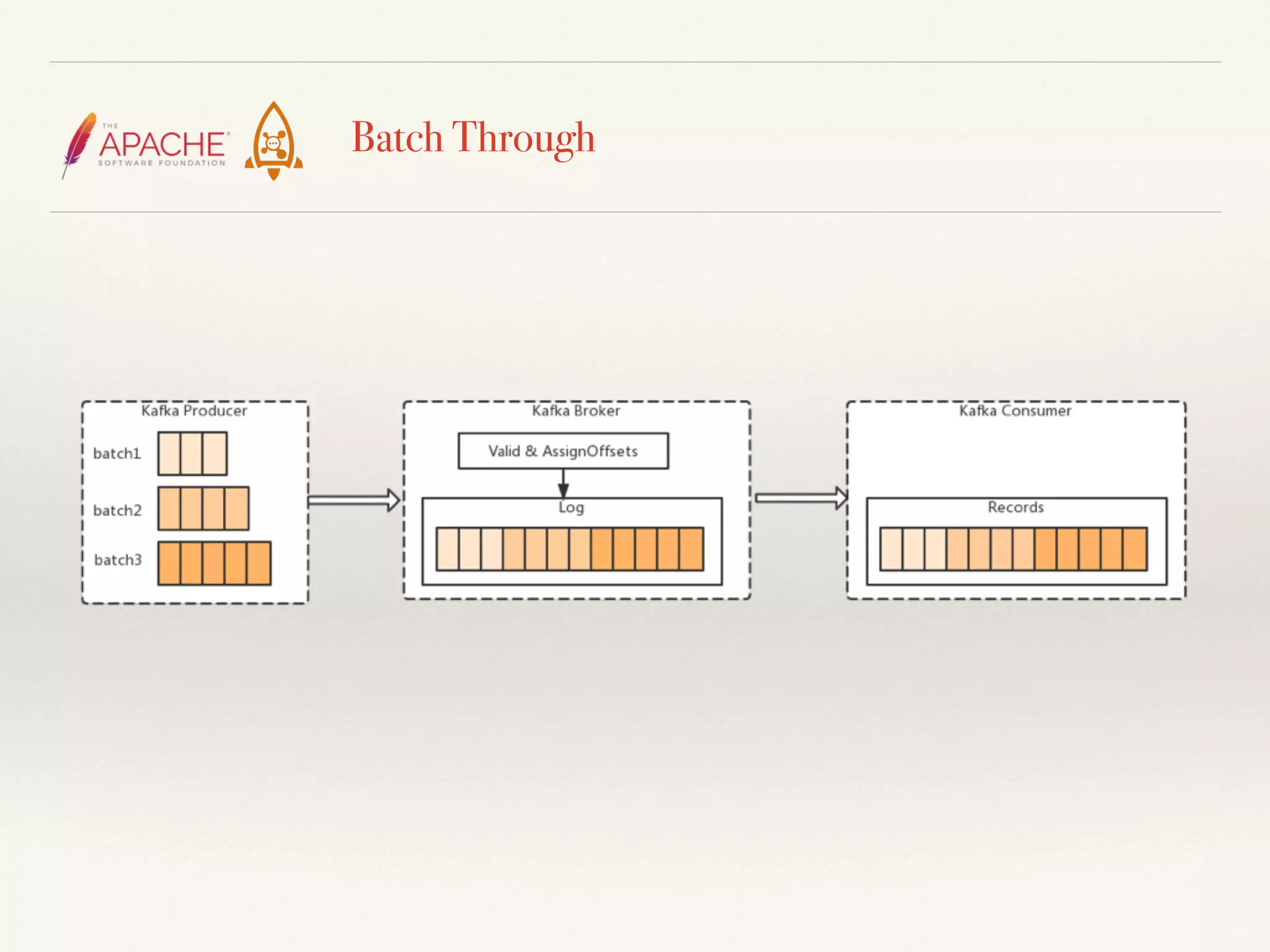
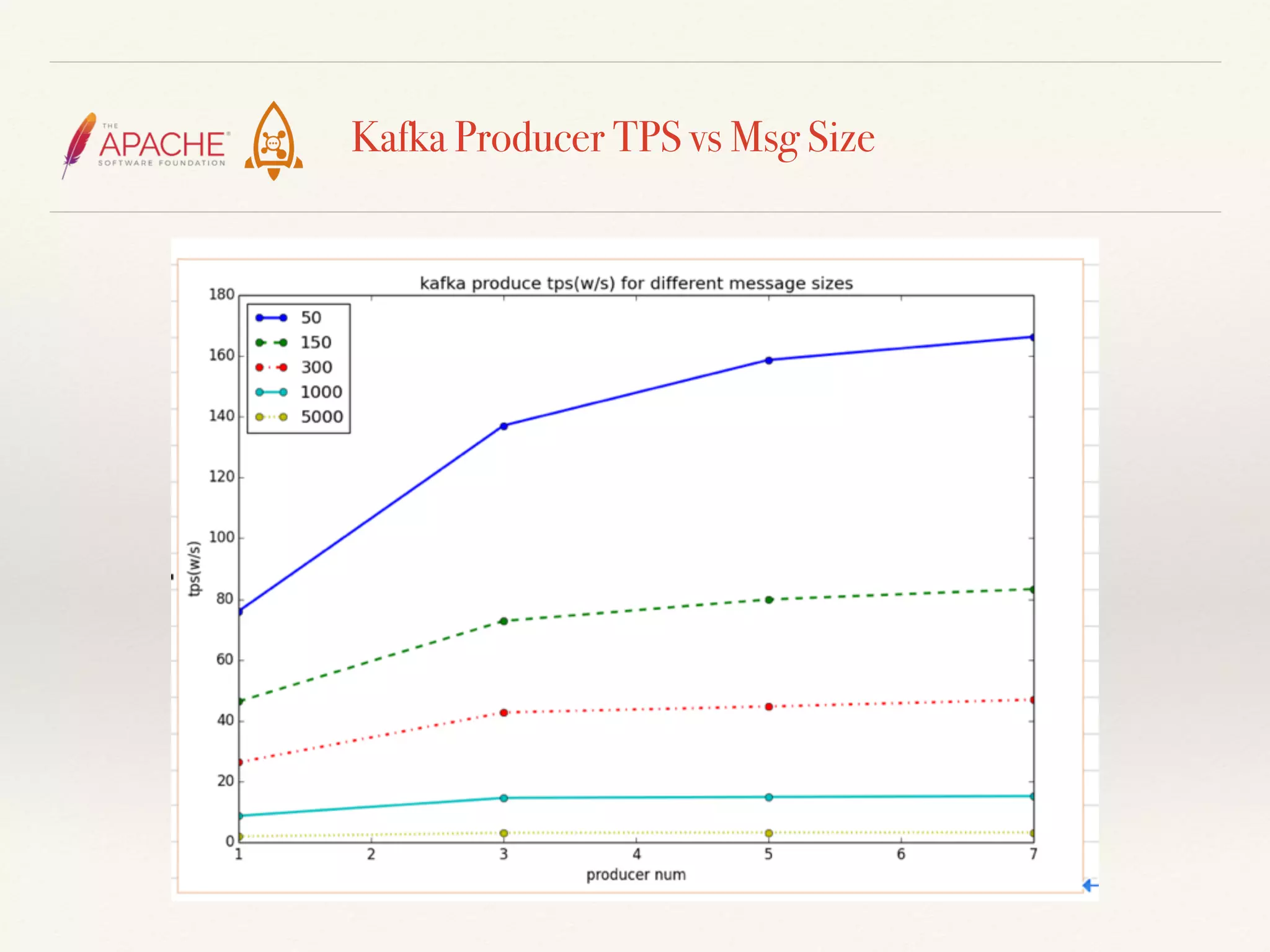
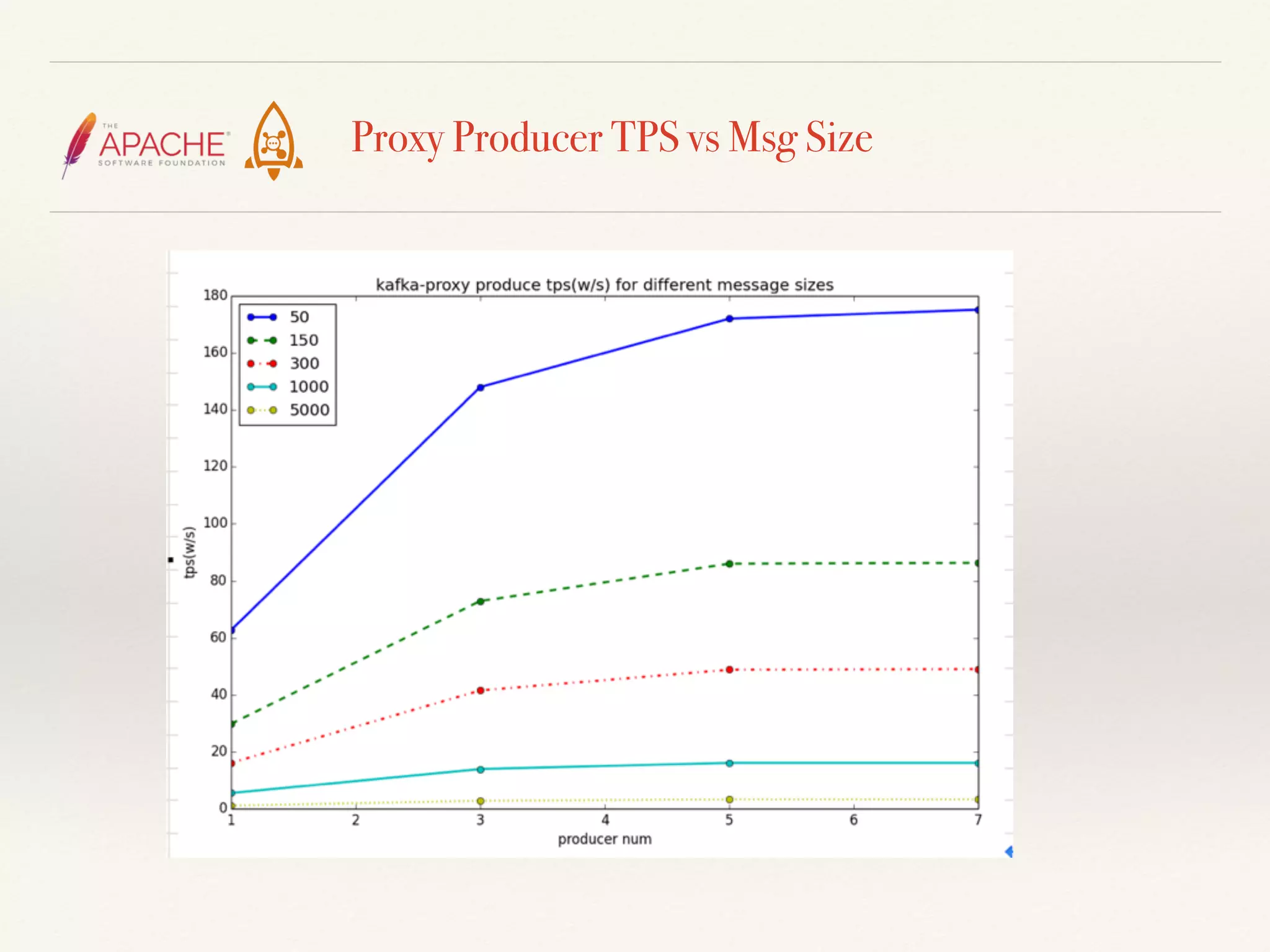
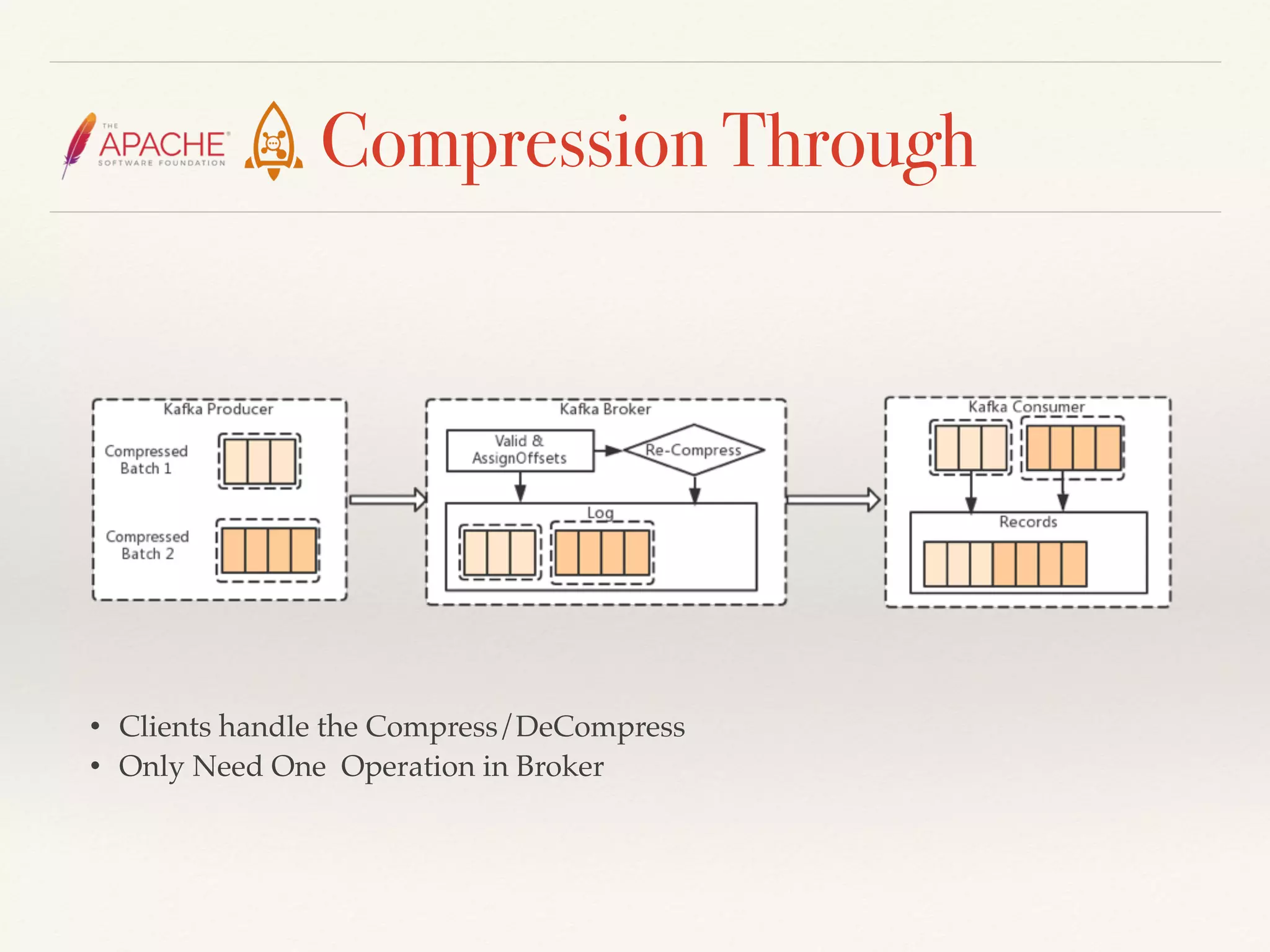
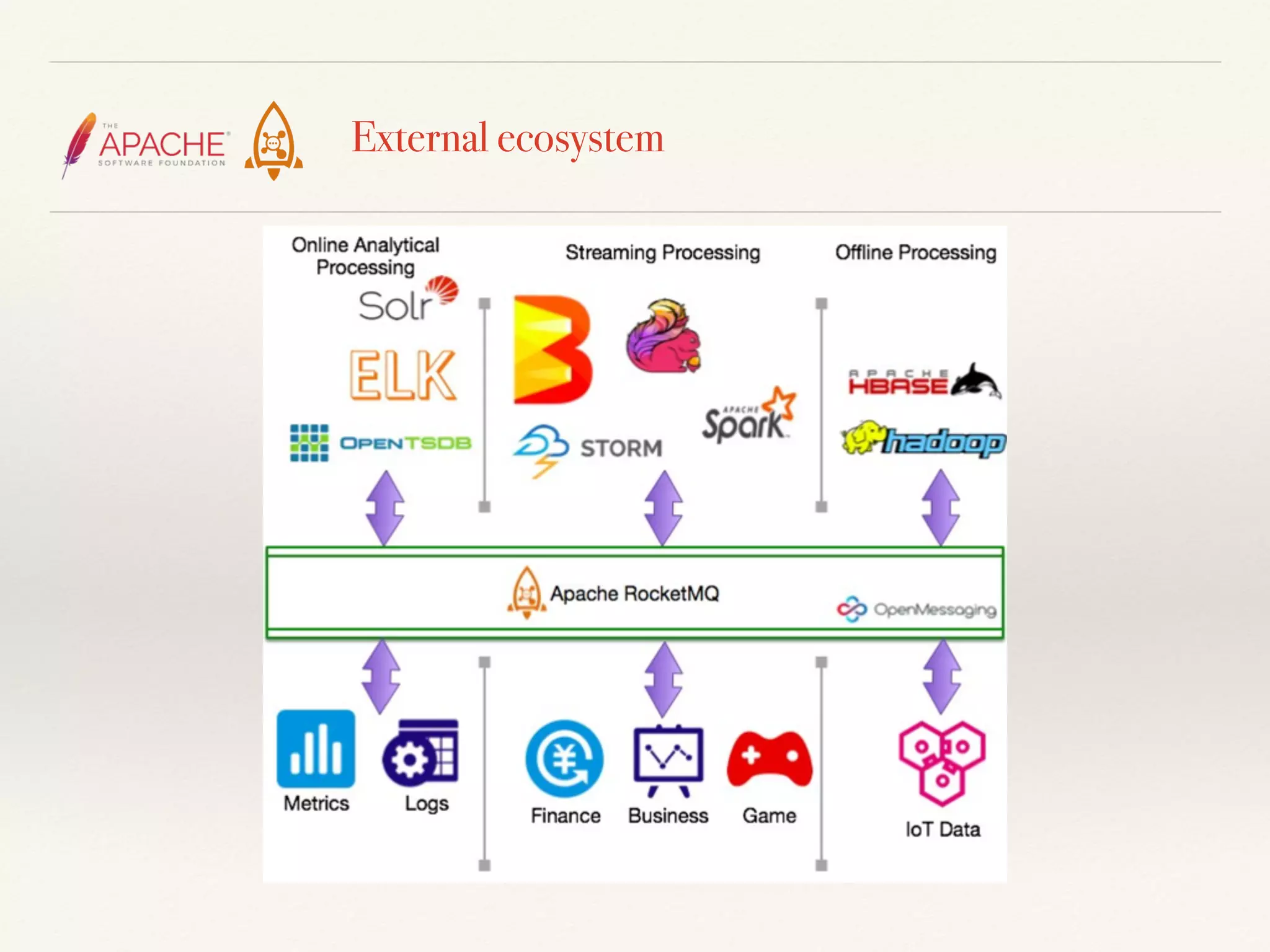
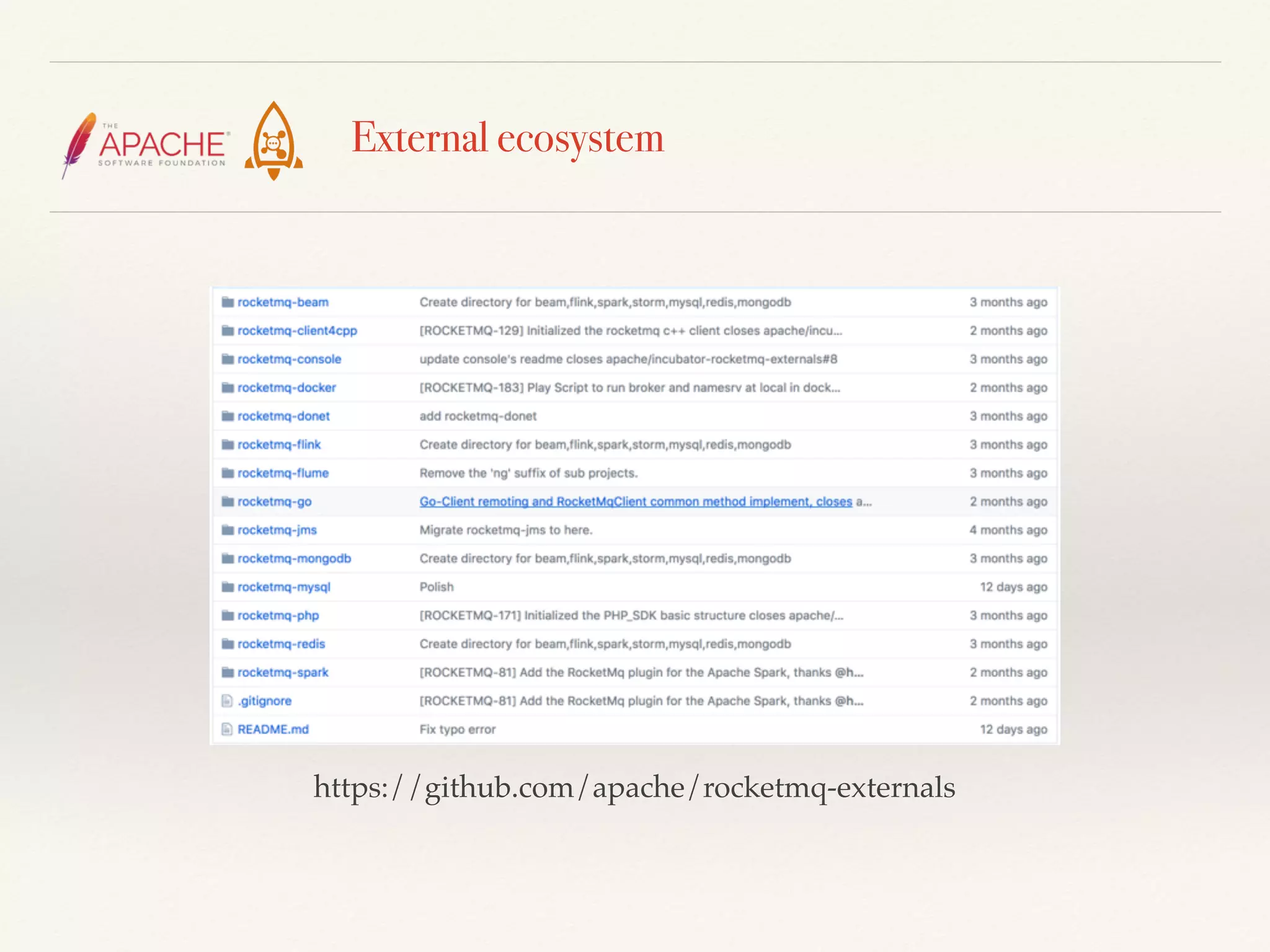
The document discusses challenges and solutions related to big data streams and provides an overview of Kafka, highlighting its integration with various big data technologies. It covers aspects such as batch processing, compression techniques, and structural optimization to improve data handling efficiency. The author emphasizes the significance of high throughput and storage cost in big data ecosystems.