Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
MasamichiIdeue
PDF, PPTX
5,767 views
月間 250 億 imps 配信するために fluct が考えていること!
VOYAGE GROUP の学生向けインターンシップ Sunrise で使用した資料です。 http://techlog.voyagegroup.com/entry/2016/01/08/160610
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 49
2
/ 49
3
/ 49
4
/ 49
5
/ 49
6
/ 49
7
/ 49
8
/ 49
9
/ 49
10
/ 49
11
/ 49
12
/ 49
13
/ 49
14
/ 49
15
/ 49
16
/ 49
17
/ 49
18
/ 49
19
/ 49
20
/ 49
21
/ 49
22
/ 49
23
/ 49
24
/ 49
25
/ 49
26
/ 49
27
/ 49
28
/ 49
29
/ 49
30
/ 49
31
/ 49
32
/ 49
33
/ 49
34
/ 49
35
/ 49
36
/ 49
37
/ 49
38
/ 49
39
/ 49
40
/ 49
41
/ 49
42
/ 49
43
/ 49
44
/ 49
45
/ 49
46
/ 49
47
/ 49
48
/ 49
49
/ 49
More Related Content
PDF
Movable Type as a Playground
by
Taku AMANO
PDF
DynamoDBを利用したKPI保存システム
by
gree_tech
KEY
Ad tech 20121030
by
ajiyoshi
PPTX
Python Project (3)
by
Tatsuya Nakamura
PDF
Movable Type Meetup JSON - MTDDC Meetup TOKYO 2014
by
bitpart
PPTX
ゲーム特化の BaaS! Unity + PlayFab 入門!
by
YutoNishine
PDF
MT東京-09 Movable Type Meetup JSON
by
bitpart
PPTX
GREE 流!AWS をお得に使う方法
by
gree_tech
Movable Type as a Playground
by
Taku AMANO
DynamoDBを利用したKPI保存システム
by
gree_tech
Ad tech 20121030
by
ajiyoshi
Python Project (3)
by
Tatsuya Nakamura
Movable Type Meetup JSON - MTDDC Meetup TOKYO 2014
by
bitpart
ゲーム特化の BaaS! Unity + PlayFab 入門!
by
YutoNishine
MT東京-09 Movable Type Meetup JSON
by
bitpart
GREE 流!AWS をお得に使う方法
by
gree_tech
What's hot
PDF
これからのインフラエンジニアについて考えていること
by
gree_tech
PDF
Cookpad TechConf 2016 - DWHに必要なこと
by
Minero Aoki
KEY
Rdbms起点で考えると見えない世界 okuyama勉強会
by
Masakazu Muraoka
PDF
クラウド時代だからこそ見直したい PHPアプリケーションのパフォーマンスチューニング
by
Terui Masashi
PDF
JAWS-UG Tokyo SAP
by
Teru Yoshikoshi
PDF
NativeAppに近付ける manifest.json
by
ssuser7cbba6
PPTX
ゲーム特化の BaaS! Unity + PlayFab 入門!
by
YutoNishine
PPTX
高速な広告配信サーバの作り方のコツ
by
Innami Satoshi
PPTX
HTTPプロキシによるゼロダウンタイムなアドサーバー移行
by
Ryo Aita
PPTX
AIやマイクロサービスを活用したDynamoDB節約術
by
gree_tech
PDF
ハイブリッドなサービス統合におけるAzureサービスの活用
by
Tatsuaki Sakai
PDF
Data Engineering at VOYAGE GROUP #jawsdays
by
Kenta Suzuki
PDF
AWSクラウドを使った"落ちない"キャンペーンサイト構築法
by
真吾 吉田
PPTX
Asp.netとbluemixで遊んでみたお話
by
Kazunori Hamamoto
PDF
NuxtJS + REST APIで運用中サービスをNuxtJS + GraphQLに変更したことによる光と影
by
gree_tech
PDF
TB / Day規模のゲーム向けデータパイプラインを開発運用する日々
by
gree_tech
PDF
UXを向上させる サイト高速化テクニック
by
Shohei Tai
PDF
JAWS DAYS 2017 LT 古きを捨て新しきに近づける
by
Tetsuya Mase
PDF
Multi Cloud Design Pattern(Beta)
by
Terui Masashi
PDF
���������������������������������������R○Sに学ぶイマドキのMySQL構築運用
by
Terui Masashi
これからのインフラエンジニアについて考えていること
by
gree_tech
Cookpad TechConf 2016 - DWHに必要なこと
by
Minero Aoki
Rdbms起点で考えると見えない世界 okuyama勉強会
by
Masakazu Muraoka
クラウド時代だからこそ見直したい PHPアプリケーションのパフォーマンスチューニング
by
Terui Masashi
JAWS-UG Tokyo SAP
by
Teru Yoshikoshi
NativeAppに近付ける manifest.json
by
ssuser7cbba6
ゲーム特化の BaaS! Unity + PlayFab 入門!
by
YutoNishine
高速な広告配信サーバの作り方のコツ
by
Innami Satoshi
HTTPプロキシによるゼロダウンタイムなアドサーバー移行
by
Ryo Aita
AIやマイクロサービスを活用したDynamoDB節約術
by
gree_tech
ハイブリッドなサービス統合におけるAzureサービスの活用
by
Tatsuaki Sakai
Data Engineering at VOYAGE GROUP #jawsdays
by
Kenta Suzuki
AWSクラウドを使った"落ちない"キャンペーンサイト構築法
by
真吾 吉田
Asp.netとbluemixで遊んでみたお話
by
Kazunori Hamamoto
NuxtJS + REST APIで運用中サービスをNuxtJS + GraphQLに変更したことによる光と影
by
gree_tech
TB / Day規模のゲーム向けデータパイプラインを開発運用する日々
by
gree_tech
UXを向上させる サイト高速化テクニック
by
Shohei Tai
JAWS DAYS 2017 LT 古きを捨て新しきに近づける
by
Tetsuya Mase
Multi Cloud Design Pattern(Beta)
by
Terui Masashi
���������������������������������������R○Sに学ぶイマドキのMySQL構築運用
by
Terui Masashi
Similar to 月間 250 億 imps 配信するために fluct が考えていること!
PPTX
Azure Service Fabric 概要
by
Daiyu Hatakeyama
PDF
[AC07] 米国マイクロソフト本社で体験したノウハウを伝授!マイクロサービス実行基盤Azure Service Fabricの勘所
by
de:code 2017
PDF
クラウド・アプリケーションの作り方
by
Tomoharu ASAMI
PDF
BPStudy20121221
by
Shinichiro Takezaki
PPTX
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
PDF
OpenStackプロジェクトの全体像~詳細編~
by
Masanori Itoh
PDF
Reflex works20120818 1
by
Shinichiro Takezaki
PPTX
非公式PaaS勉強会~新宿d社会議室
by
Daisuke Masubuchi
PPTX
Interactive connection2
by
Takao Tetsuro
PPTX
Introduction to Azure Service Fabric
by
Takekazu Omi
PDF
WindowsAzureの長所を活かすクラウド アプリ開発(PDF版)
by
Shinichiro Isago
PPSX
Fiorano SOA Platfrorm 紹介
by
Shigeru Aoshima
PPTX
Windows Azure Appfabric as "Middleware as a Services"
by
Kazuyuki Nomura
PPTX
祝GA、 Service Fabric 概要
by
Takekazu Omi
PPT
Flume
by
あしたのオープンソース研究所
PDF
20111215 12 aws-meister-sqs_sns_sdb-public
by
Amazon Web Services Japan
PDF
110409 slintky lt
by
Takayoshi Tanaka
PPTX
20170902 kixs azure&azure stack
by
Osamu Takazoe
PPTX
Service Fabric での高密度配置
by
Takekazu Omi
PDF
SimpleDB, SQS, SNS詳細 - AWSマイスターシリーズ
by
SORACOM, INC
Azure Service Fabric 概要
by
Daiyu Hatakeyama
[AC07] 米国マイクロソフト本社で体験したノウハウを伝授!マイクロサービス実行基盤Azure Service Fabricの勘所
by
de:code 2017
クラウド・アプリケーションの作り方
by
Tomoharu ASAMI
BPStudy20121221
by
Shinichiro Takezaki
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
OpenStackプロジェクトの全体像~詳細編~
by
Masanori Itoh
Reflex works20120818 1
by
Shinichiro Takezaki
非公式PaaS勉強会~新宿d社会議室
by
Daisuke Masubuchi
Interactive connection2
by
Takao Tetsuro
Introduction to Azure Service Fabric
by
Takekazu Omi
WindowsAzureの長所を活かすクラウド アプリ開発(PDF版)
by
Shinichiro Isago
Fiorano SOA Platfrorm 紹介
by
Shigeru Aoshima
Windows Azure Appfabric as "Middleware as a Services"
by
Kazuyuki Nomura
祝GA、 Service Fabric 概要
by
Takekazu Omi
Flume
by
あしたのオープンソース研究所
20111215 12 aws-meister-sqs_sns_sdb-public
by
Amazon Web Services Japan
110409 slintky lt
by
Takayoshi Tanaka
20170902 kixs azure&azure stack
by
Osamu Takazoe
Service Fabric での高密度配置
by
Takekazu Omi
SimpleDB, SQS, SNS詳細 - AWSマイスターシリーズ
by
SORACOM, INC
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PPTX
ddevについて .
by
iPride Co., Ltd.
PDF
Drupal Recipes 解説 .
by
iPride Co., Ltd.
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
ddevについて .
by
iPride Co., Ltd.
Drupal Recipes 解説 .
by
iPride Co., Ltd.
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
月間 250 億 imps 配信するために fluct が考えていること!
1.
月間 250 億
imps 配信するために fluct が考えていること! @jewel_x12
2.
誰? • @jewel_x12 • 株式会社
fluct に新卒から入って 3 年目 • 主にプログラマをやっている • 最近はウルトラストリートファイターⅣにハマって ます(めっちゃ弱い) • 大学時代は自然言語処理をやってました
3.
• 月間 250
億 imps 捌く広告配信サービスで必要 なことを主にアプリケーションプログラマ目線で紹 介 • 1人で喋ってるのは寂しいので随時質問ください!
4.
is 何? • Web広告を配信するプラットフォームの中でも、 特に
SSP と呼ばれるもの • 広告枠の販売やメディアの広告収益最大化を支援 • 国内 SSP 売上シェアではナンバーワン • RTB 取引も取り扱っている
5.
用語 • impression (インプレッション) •
広告が表示された回数のこと • 20 回表示されると 20 imps とか言ったりす る
6.
SSPとかRTBってなんじゃ • SSP (Supply
Side Platform) • 広告枠の販売やメディアの広告収益最大化を支援 • RTB (Real Time Bidding) • ある広告インプレッションに対してオークションを行い、 インプレッションと広告主のマッチングを行う 「アドテク勉強会」スライドを借りて説明(13ページ以降) http://www.slideshare.net/shoho/ss-36728773
7.
fluct では月間 250
億 imps 取り扱っている! RTB 配信ではリクエストの裏側で複数DSPに 対してオークションのリクエストが行われる!
8.
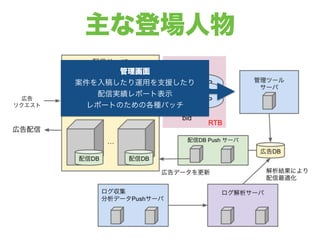
主な登場人物
9.
主な登場人物 管理画面 案件を入稿したり運用を支援したり 配信実績レポート表示 レポートのための各種バッチ
10.
主な登場人物 配信アプリケーション 広告リクエストを捌く RTB を実施する
11.
主な登場人物 広告 DB 管理画面から入力された案件に関する 各種情報や現在配信している imp
数 などが入る
12.
主な登場人物 配信 DB /
Push サーバ 配信に必要なDB(Berkeley DB) 各配信サーバに配布される 各配信サーバへ配布する理由はいくつかあるが、 データに関するサーバが一時的に落ちても スタンドアロンで配信サーバが動く状況を作りたい
13.
主な登場人物 ログ収集・解析 配信実績を取得、その結果を 配信DBへフィードバックする レポート作成 配信の最適化
14.
主な登場人物 その他登場人物 純広告は CDN 経由で配信 管理・監視ツール ネットワーク機器
15.
広告配信システムには全部大切! ! 今回は広告リクエストを捌く 配信部分を中心に話します
16.
fluct の配信システムで 満たすべきどんな要件は何? サービスにはいろいろな要件があり 要件に基いてシステムを構築していく • たとえば •
ちょっぱやなレスポンスがないと価値を届けられないと思う • 信頼できる EC サイトじゃないと買い物したくないよね • ロードでブチブチ切れる動画配信サービスにしたくない • これくらいの 💴 でやっていきたい!
17.
RTB を行う 広告配信システムへの要件 • 広告リクエストに対し高速に応答する •
広告が出ないということを防ぐ • 集計漏れを防ぐ • (+α)成長のための柔軟さ
18.
RTB を行う 広告配信システムへの要件 • 広告リクエストに対し高速に応答する •
広告が表示される前に別ページに移動したりするなどの機会損失が ある • DSP への RTB リクエストは並列に処理する。直列に処理した場 合だと応答に時間がかかりすぎる • 広告が出ないということを防ぐ • ダウンタイムを無くす • せっかくメディアを訪れたユーザが広告を見ないまま終わり、メディ アや SSP の収入に繋がらない
19.
RTB を行う 広告配信システムへの要件 • 集計漏れを防ぐ •
ログが収集できなかったなどで集計漏れ(imps, click, etc…) が起きると、これもメディアや SSP の収入に繋がらない • (+α)成長のための柔軟さ • 業界の状況はめまぐるしく変わる。それに追随し追い越すた め、頑健かつ柔軟なサービスを継続的に提供する必要がある • 要件を満たすためには柔軟さのある設計やスケーラビリティが必要 だが、何よりもこれらを実現するために優秀なチームメンバー・挑 戦できる環境が必要(1人で全部やるのは大変)
20.
どんな人が システム構築に 関わっているの?
21.
チームメンバーを ざっと分ける • 相談に乗ってくれたり人・いい話を持ってくる人 • 営業さん •
運用さん • インフラさん • DevOps を進める人 • アプリケーション開発者さん • 雑用さん(色々できる人) • 分ける必要はないけど、各々がチームの為に必要だと思うことをやっている
22.
要件は簡単に満たせる?
23.
250億 imps /
mon の状況になると何が起こるか • リクエスト処理が詰まる • サーバが増える • サービスが大きいので最悪時の障害も大きい • サービスがもっと成長する可能性がある
24.
250億 imps /
mon の状況になると何が起こるか • リクエスト処理が詰まる • 普通にレスポンスを返すだけでも多い。RTB が設定されているとすると、1 imp 毎に複数 DSP へ RTB リクエストを送ることになる • I/O 等の処理待ちによりいろんなものが枯渇し、リクエストが捌けなくなる • メモリ・スレッド・ネットワーク帯域・etc... • 解決策 1: スイッチングハブを置いて複数のサーバにリクエストを分散させ る • 解決策 2: プログラムをもっと速くする・I/O 多重化等の工夫を頑張る • いろんな策があっていろんな限界があるのでお金とか色んなものと相談
25.
250億 imps /
mon の状況になると何が起こるか • サーバが増える • HDD が壊れたり色々な愉快なことが起こる可能性がアップ↑↑ • 継続して様子を見ていかないといけない • アプリケーションやサーバー設定のリリースに時間がかかる • サービスが大きいので最悪時の障害も大きい • これも様子を見ていかないといけない • 障害の影響を抑えていきたい
26.
250億 imps /
mon の状況になると何が起こるか サービスがもっと成長する可能性がある
27.
事業はスケールさせていきたい! 💰💰💰💰💰💰💰💰💰💰💰💰 💰💰💰💰💰💰💰💰💰💰💰💰
28.
250億 imps /
mon の状況になると何が起こるか • サービスがもっと成長する可能性がある • まだまだ成長盛り • スケールのしやすさを考える必要がある • システムはいろんな所で限界に来る • 異常に優秀な営業問題 • もっとリクエストが少なかった頃は⃝⃝砲が怖かった
29.
月間 250 億
imps の状態で要件を どう満たせばいいのか
30.
多量の imp を安定して捌くことと これからのために考えていること おもに 「障害影響範囲を狭める」 「スケールのしやすさ」
31.
多量の imp を安定して捌くことと これからのために考えていること •
スケールのしやすさ • 疎結合なアプリケーション構成 • オンプレとクラウドの使い分け • 障害影響範囲を狭める • 障害を減らすためのデプロイフロー • クラウドの有効活用 • 監視 • これらの項目は色々考えていることの一部。他にも案件DB や計測系の冗長性確保等がある
32.
疎結合な アプリケーション構成 • 配信アプリケーション・計測・集計の分離 • サーバーレベルで分離 •
負荷高騰等の要因で他のアプリケーションが動 かなくなるようなことをできるだけ防ぐ • 各アプリケーション単位でスケールしやすい
33.
疎結合な アプリケーション構成 • 配信アプリケーション • リクエスト処理・案件選択(PHP,
Perl) • もっと速い言語じゃなくても今のところ大丈夫 • もちろん可能な限り速い方がいいが、言語を使える人やメンテナンス性とのバラ ンスもある • RTB アプリケーション(Erlang) • 軽量プロセス・並列処理が得意 • 「Erlang による SSP 側 RTB」スライド ( http://www.slideshare.net/ajiyoshi/ad-tech- 20121030-14943813 ) • どこかがボトルネックになったらそこを取り替えていく • 例えば案件選択(Perl)がボトルネックになったら、そこだけ Golang 製に取り替え ていくとか • ボトルネック自体はどっかに移るので、全体の様子を見ていかないといけない
34.
もう少し低レイヤーでの構成 ! fluct ではオンプレミスとクラウドの ハイブリッドになってる
35.
ネットワーク構成概要 GSLB エラスティックな ロードバランサ L3SW L2SW LVS (DSR) ! (配信) 配信配信配信 (配! (配信) ! (配信) クラウド DC1 DC2 NIC 多重化等によるネットワーク 冗長性確保やハードウェアレベル での冗長性確保が考えられている (あんまり詳しくない)
36.
オンプレミスと クラウドの良い所 • オンプレミスの良い所 • インフラ・ネットワークの構成をハードウェアレベルで自分たちで組め る(ブラックボックスが少なく、コントローラビリティがある) •
制限が少なく、できることが増える • 買い切りのハードウェアを資産として見ることができる • 色々なサービスを(これからも)運営するので、そちらへまわすこと も可能 • (fluct では) 安い • いろんな観点がある。オンプレミスは初期費用やハードウェア保守な どのコストも掛かるし、マシンリソースに余裕がありすぎると高いし、 n 年後も使い物になるようなマシンが n 年後もちゃんと使用されて いるとかの前提のもとで安い
37.
オンプレミスと クラウドの良い所 • クラウドの良い所 • スケーラビリティ
& サービスリリースのスピード • しっかり用意してあれば急なアクセス数増加にも耐えられる • オートスケールができるような設計が必要 • 予測は難しい。見通しがそんなに立っていなくても、オンデ マンドでスケールアップ・アウトさせながら動き始めること ができるというのは、スピード重視の場合に大事 • 立てたり潰したりを気軽にできるからこそのデプロイフローや 検証環境構築 • インフラ専任のエンジニアがいなくてもいける
38.
fluct がハイブリッドに なってる経緯
39.
サービスの成長によって 要件を満たすための システム構成が変わってくる
40.
fluct がハイブリッドに なってる経緯 • 2010
年、DC のラックで産声をあげる • 順調に成長(サーバーが増えてくる) • 営業さん < imp ドゾー ( ^^) _旦 • 2013 年、imp が捌ききれなくなってくる • 営業さん優秀過ぎ問題 • 次の増設について考え始める
41.
fluct がハイブリッドに なってる経緯 • 増設サーバーを置けるところの空きが無い •
クラウドかぁ… プロビジョニングスクリプトが今の環境向けに書 かれていたりするしコントローラビリティも不安だし、安定して配 信するならやっぱりオンプレミスでやりたいなぁ(別 DC で次の 増設へ動き出す) • 営業さん > imp ドゾー ( ^^) _旦 • 開発 > ちょwww(嬉しい悲鳴) • DC だと次の増設間に合わない → 2013, クラウドへ頑張って移 行(リードタイム短くて◎)
42.
fluct がハイブリッドに なってる経緯 • クラウド使っているとよく分からないところがたまにあるし (暖機運転が必要だったり)、外部サービスにロックインさ れるリスクもあるなぁ •
2014, 別 DC で増設完了 • クラウド環境は緊急避難弁として使用 • デプロイ環境・開発や検証のための便利な環境をクラウドに 作りはじめる(クラウドならではの柔軟性◎) • その後も色々あり現在(2015)へ
43.
障害を減らす 影響範囲を小さくする ための工夫 ダウンタイムをなくしていこう
44.
デプロイによる障害の影響範囲を 小さくしていきたい • デプロイしたら問題が見つかった!による影響を減 らしたい • アプリケーション書く人としてはできるだけ影響範 囲を小さくしていくような機能追加を心掛けたい •
といっても難しいし心配は無限
45.
デプロイによる障害の影響範囲を 小さくしていきたい • デプロイフローを安全安心に • 1
台だけデプロイして様子見 with 監視 • 何かあっても影響範囲は小さい • リリース内容やアプリケーション構成による • すぐに前の状態に戻せること • Git 等の VCS による運用(テストの通った revert commit が便利) • Blue-Green デプロイメント • これらの機能があるとリリース時に安心感を与えてくれるが、リリー スする側もどう戻せるかなどの影響範囲を考えていけると良い
46.
本番に近い状態で開発を • 想定していないリクエストだった(泣)とか開発環境では動いてたの に∼∼∼とかを減らす • 本番と同様なリクエストでテスト •
本番環境のインスタンス1台だけ開発ブランチに切り替え、少量の 本番リクエストを流して試すとか • 最新状態の構成が反映された開発環境で開発 • クラウド上にオンデマンドで構築できる仕組みがあって、負荷試 験とかできる • ネットワークレベルで本番とは分離されているので安心 • クラウドで本番稼働していたり構成管理をしっかりしているおかげで もある
47.
監視をしよう • デプロイ時以外でも障害はもちろん起きる • ピーク時、配信サーバがリクエストを処理しきらな くなる •
ハードウェア障害・クラウドサービスの障害 • たくさんサーバがあるので自動監視をしないと、やば そうになることは気付きにくい • グラフ化されていたり、定期的に見る機会があった りするといい
48.
監視をしよう • 主に何を見ているの • load,
memory, traffic, response time, HDD etc… • リクエストが多いとログに項目足すだけでヤバイデータサイズ になる • imp ごとのログで1文字 (1 byte) 足しても、1日 0.8 GB 増える計算 • 気がついたら HDD 容量が足りなくなったり • もちろんアプリケーションエラーログも見る • たまたまや想定外で監視していなかった部分が問題になること もある。できるだけ E2E でもやって、サービスを正しく提供 できているか見ることが大切 • 応答速度とかもサービスのクオリティに関連する
49.
まとめ • fluct には月間
250 億の impression リクエストがやって来る • 広告配信ならではの要件がいくつかある • 要件達成とこれからの成長のために「障害影響範囲を狭める」と「ス ケールのしやすさ」を念頭に置くことが大事 • 障害影響範囲を狭める • 冗長性の確保 • デプロイフローの改善 • 監視 • スケールのしやすさ • アプリケーションの手の入れやすさ • オンプレミスとクラウドのハイブリッド運用
Download













































































![[AC07] 米国マイクロソフト本社で体験したノウハウを伝授!マイクロサービス実行基盤Azure Service Fabricの勘所](https://cdn.slidesharecdn.com/ss_thumbnails/ac07-170602093741-thumbnail.jpg?width=640&height=640&fit=bounds)


























