Downloaded 22 times
















![16-Marks
1. Explain the Service Characteristics in a Network?
One of the goals of network analysis is to be able to characterize services so that they can be
designed into the network and purchased from vendors and service providers (e.g., via requests
for information [RFI], quote [RFQ], or proposal [RFP], documents used in the procurement
process). Service characteristics are individual network performance and functional parameters
that are used to describe services. These services are offered by the network to the system (the
service offering) or are requested from the network by users, applications, or devices (the
servicerequest). Characteristics of services that are requested from the network can also be
considered requirements for that network. Examples of service characteristics range from
estimates of capacity requirements based on anecdotal or qualitative information about the
network to elaborate listings of various capacity, delay, and RMA requirements, per user,
application, and/or device, along with requirements for security, manageability, usability,
flexibility, and others.
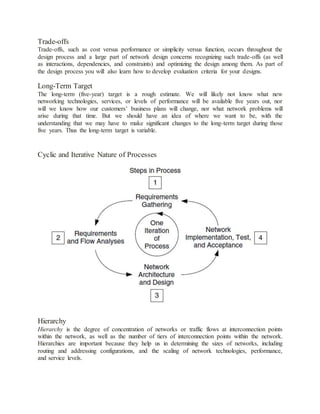
Such requirements are useful in determining the need of the system for services, in providing
input to the network architecture and design, and in configuring services in network devices
(e.g., routers, switches, device operating systems). Measurements of these characteristics in the
network to monitor, verify, and manage nservices are called service metrics. In this book we
focus on developing service requirements for the network and using those characteristics to
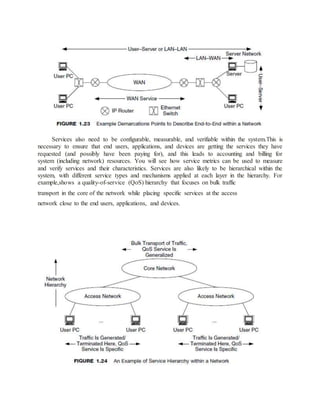
configure, monitor, and verify services within the network. For services to be useful and
effective, they must be described and provisioned end-to-end at all network components between
well-defined demarcation points. “End-to-end” does not necessarily mean only from one user’s
device to another user’s device. It may be defined between networks, from users to servers, or
between specialized devices When services are not provisioned end-to-end, some components
may not be capable of supporting them, and thus the services will fail. The demarcation points
determine where end-to-end is in the network. Determining these demarcation points is an
important part of describing a service.](https://image.slidesharecdn.com/162marksiniunit-150604063736-lva1-app6892/85/16-2-marks-in-i-unit-for-PG-PAWSN-19-320.jpg)























![termed here mission-critical applications.
Capacity:
In terms of capacity, there are some applications that require a predictable, bounded, or high
degree of capacity. Such applications, termed here rate-critical applications, include voice, non-
buffered video, and some “tele∗service” applications (applications that provide a subset of voice,
video, and data together to be delivered concurrently to groups of people at various locations,
e.g., teleconferencing, telemedicine, and teleseminars [thus the tele∗]). Rate-critical applications
may require thresholds, limits, or guarantees on minimum, peak, and/or sustained
capacities.
Note the difference between rate-critical applications and best-effort applicationssuch as
traditional file transfer (where the file transfer application is notwritten to operate only when a
predictable or guaranteed service is available). Infile transfer (such as in FTP running over TCP,
described earlier), the applicationreceives whatever capacity is available from the network, based
on the state of thenetwork at that time as well as interactions between TCP and the lower
layers.While at times there may be a high degree of capacity, it is inconsistent, and there
is no control over the resources in the network to predict or guarantee a specific(usually
minimum) capacity in order to function properly. This can often also betied to the end-to-end
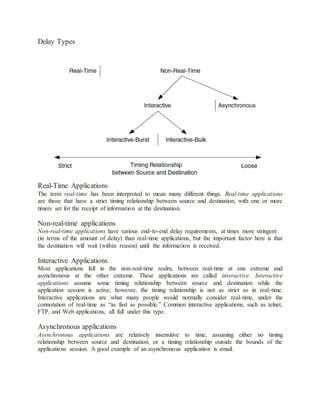
delay of the network, as capacity will impact delay.Delay Increasing interactivity is arguably the
driving force behind the evolution of many applications. Consider the evolutionary path of
information access, from telnet and FTP to Gopher (a menu system that simplifies locating
resources on the Internet) and Archie (a database that consists of hundreds of file directories) to
Mosaic (the precursor to Netscape) and Netscape, made even more interactive with the use of
JAVA and virtual reality markup language (VRML). As we saw in the previous section,
interactivity relies predominantly on the performance characteristic delay. Delay is a measure of
the time differences in the transfer and processing of information. There are many sources of
delay, including propagation, transmission, queuing, processing, and routing. This section
focuses on end-to-end and round trip delays, which encompass all of the delay types mentioned
above. From an application service perspective, optimizing the total, end-to-end, or round-trip
delay is usually more important than focusing on individual sources of delay.
Individual sources of delay become more important as we get into the lower-layer components,
as well as in architecture and design optimizations. Historically, applications used on the Internet
did not have strict delay requirements. They relied on best-effort service from the Internet and
did not request or expect any service guarantees. Other applications, found primarily on private
networks (with proprietary network technologies and protocols), have had more strict delay
requirements (as well as capacity and RMA requirements). Some private networks have been
effective in providing predictable or guaranteed delay, either by over-engineering the network
with substantial spare capacity, or by the trade-offof interoperability with other networks. But we
now find that applications withdelay requirements are migrating to the Internet, often using
VPNs, and applicationspreviously dedicated to a single user or device are now being used across
theInternet, forcing a reevaluation of offering services other than best effort on theInternet. This](https://image.slidesharecdn.com/162marksiniunit-150604063736-lva1-app6892/85/16-2-marks-in-i-unit-for-PG-PAWSN-46-320.jpg)




The document discusses key concepts in network management including network analysis, architecture, design, and requirements analysis. It defines important terms like mission-critical networks, bandwidth, network services, quality of service, and performance characteristics. The document also covers topics like systems methodology, identifying system components, and factors that affect network architecture/design decisions. Overall, the document provides an overview of the fundamental concepts and processes involved in network management.



































































