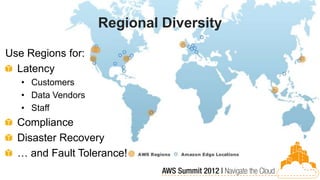
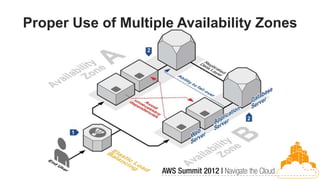
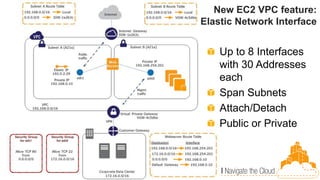
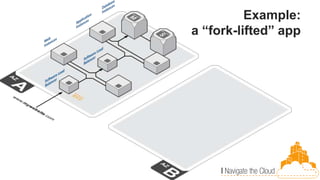
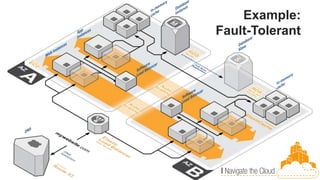
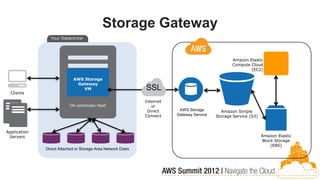
This document discusses building fault-tolerant applications in the cloud using Amazon Web Services (AWS). It outlines that AWS provides many inherently fault-tolerant services like S3, DynamoDB, and Route53 that can be used as building blocks. It also discusses design patterns for fault tolerance like using multiple availability zones, elastic load balancing, auto-scaling, and loose coupling between application components. The document provides examples of how to architect fault-tolerant systems on AWS for both front-end and data tier systems using services like EC2, RDS, DynamoDB, S3, and ElastiCache. It emphasizes testing fault tolerance through the use of tools like Chaos Monkey.