Download to read offline






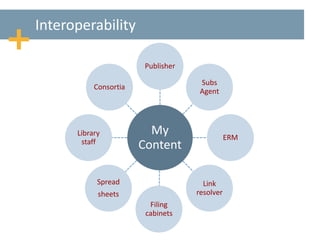





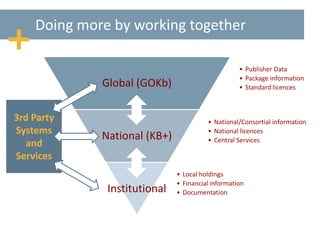
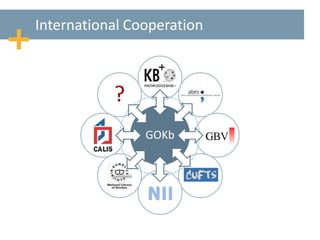








This document discusses maximizing the knowledge base by taking an open and collaborative approach. It proposes sharing publication, package, license, and subscription data openly to improve accuracy, reduce duplicated efforts across systems, and make information available to all. Taking this approach through open data standards, collaborative communities, and enriched shared information can help address issues around data quality and availability, interoperability between systems, and the large amount of duplicated effort currently required to maintain knowledge bases. The document advocates working together internationally and across organizations through collaborative communities and knowledge sharing to maximize the potential of knowledge bases.
















































