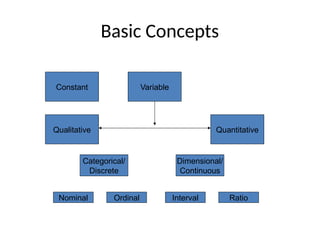
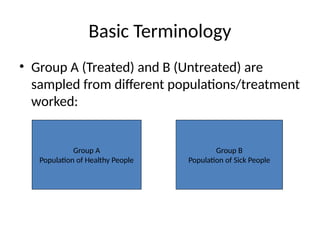
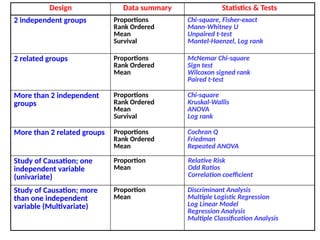
The document provides an overview of basic statistical concepts, distinguishing between descriptive and inferential statistics and explaining key terms such as population, sample, variable, and data. It outlines data collection methods, sampling techniques, and emphasizes the importance of measuring variability and drawing valid inferences from sample data. Additionally, it introduces various statistical measures, including central tendency and dispersion, as well as methods for data representation and hypothesis testing.