Downloaded 21 times











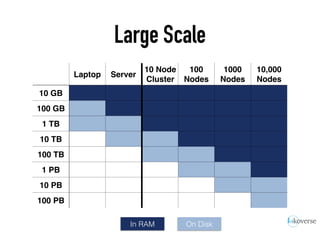
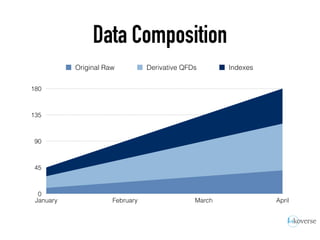

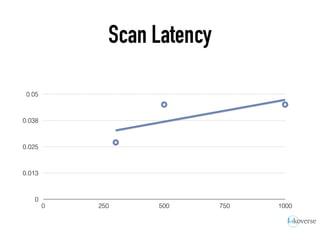
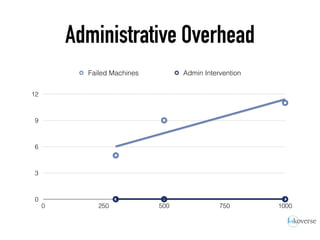

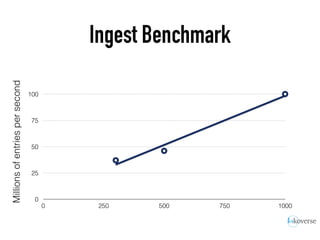











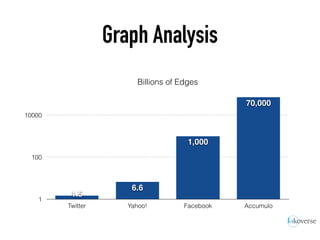













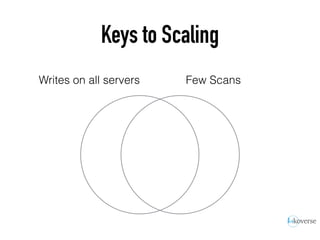
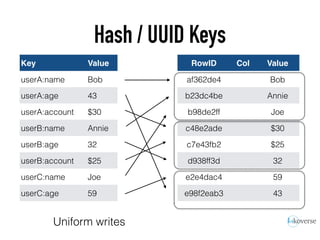
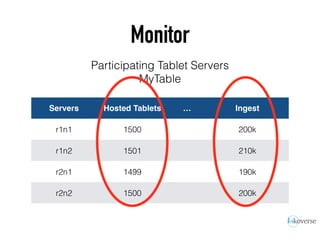
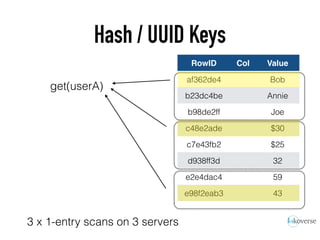
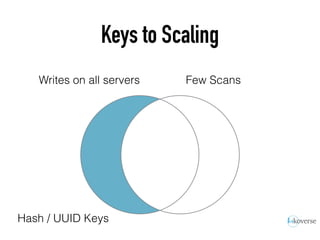
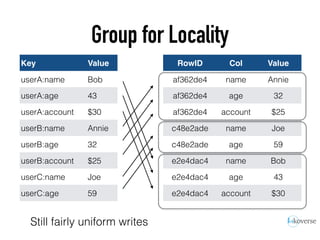
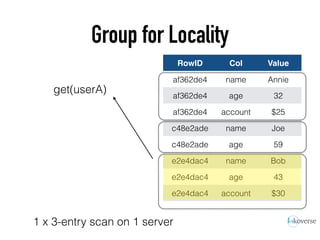
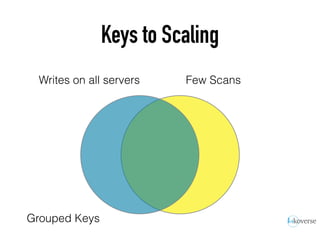
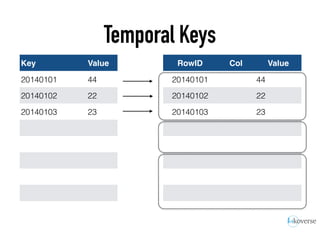
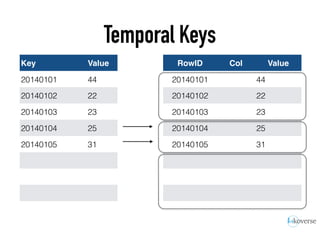



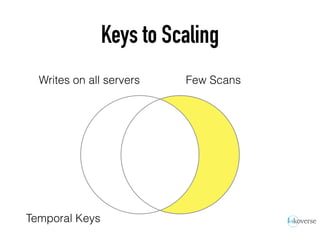
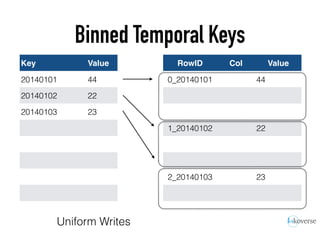


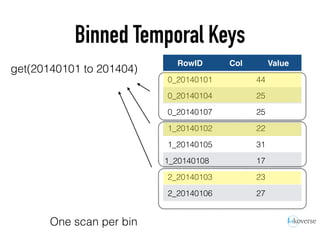
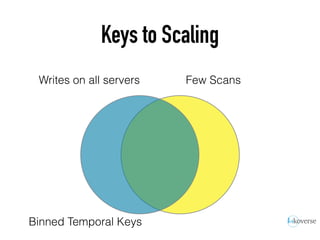












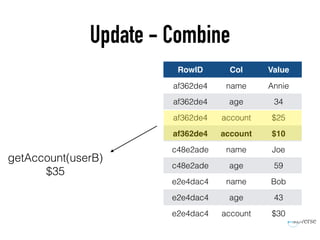
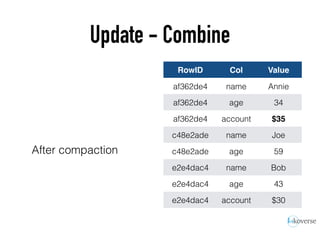




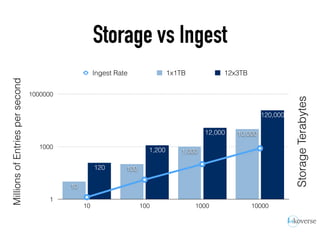


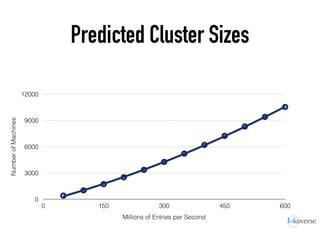





























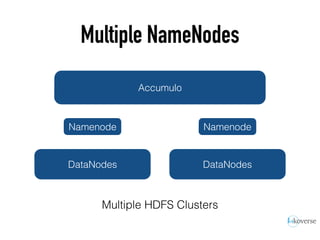






















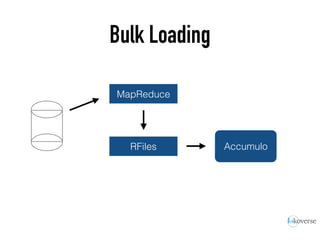




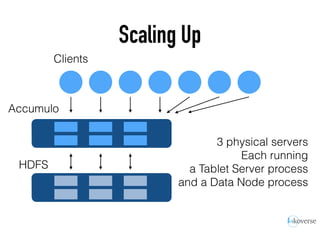
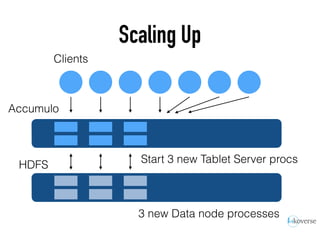
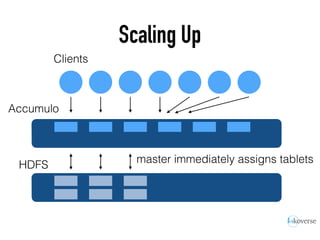
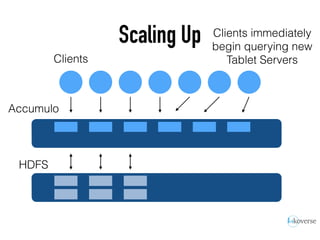
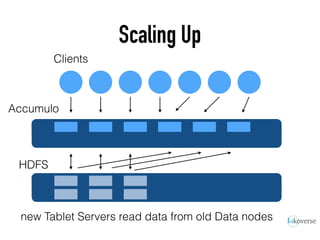
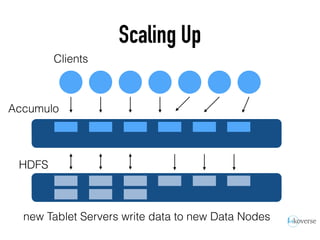

















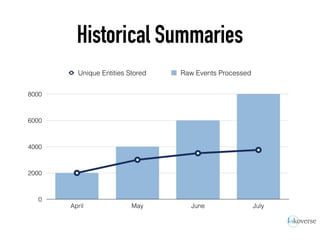








The document discusses the scaling of large-scale Accumulo clusters, detailing performance benchmarks, particular keys to scaling, and guidelines for optimal configuration. It emphasizes the importance of write parallelism, data organization, and effective use of header structures. Additionally, it covers aspects such as hardware requirements, common failure rates, and data management strategies within the infrastructure.









![Accumulo Summit 2015: Tracing in Accumulo and HDFS [Internals]](https://cdn.slidesharecdn.com/ss_thumbnails/tracingaccumulosummit2015final-150501214618-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






![Accumulo Summit 2015: Accumulo In-Depth: Building Bulk Ingest [Sponsored]](https://cdn.slidesharecdn.com/ss_thumbnails/buildingbulkimportas-2015newtoneric-150501214924-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






